In het digitale tijdperk van vandaag is gegevensbeveiliging een cruciale zorg geworden, vooral met het toenemende gebruik van AI en automatisering in documentverwerking. Documentparsering, een essentieel onderdeel van gegevensextractie, stelt bedrijven in staat om efficiënt om te gaan met en gebruik te maken van enorme hoeveelheden informatie.
IDP (intelligente documentverwerking) revolutioneert de manier waarop bedrijven gegevensuitwisseling uit documenten afhandelen. Het antwoord op de vraag wat intelligente documentverwerking is, is dat IDP een geavanceerde technologie is die de extractie en classificatie van gegevens uit documenten automatiseert. IDP-technologie is onmisbaar geworden voor bedrijven die hun documentparsering willen automatiseren en beveiligen.

Gevoelige Gegevens Begrijpen in Documentparsering
Gevoelige gegevens in documentparsering verwijzen naar informatie die individuen zou kunnen identificeren, persoonlijke kenmerken zou kunnen onthullen of schade zou kunnen veroorzaken als deze verkeerd wordt gebruikt of zonder toestemming wordt onthuld. Dit omvat een breed scala aan gegevenstypen, elk met unieke implicaties voor privacy en beveiliging. De adoptie van IDP-technologie is cruciaal voor het handhaven van de vertrouwelijkheid en integriteit van gevoelige gegevens.
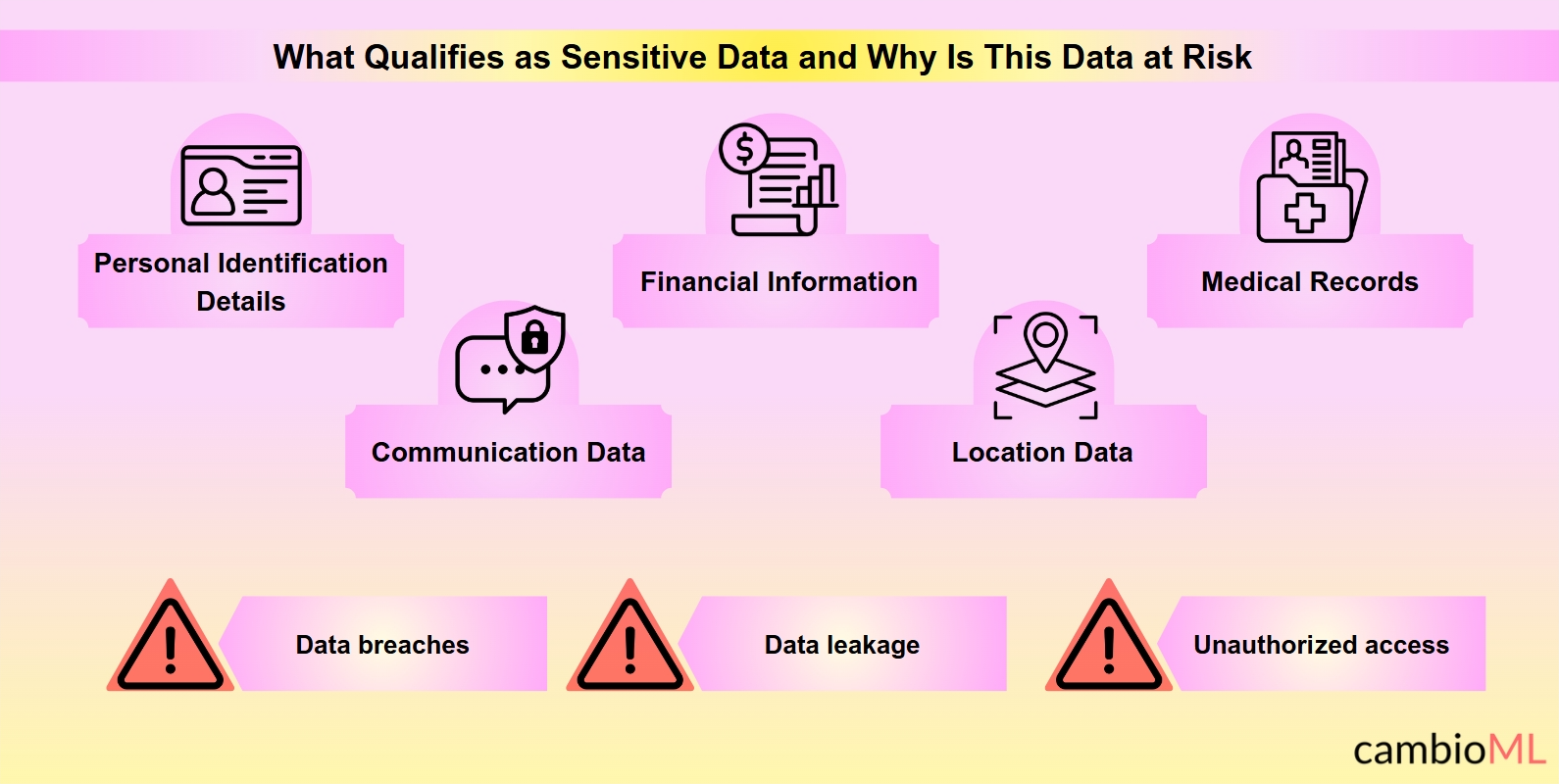
Wat Kwalificeert als Gevoelige Gegevens?
-
Persoonlijke Identificatiegegevens: Dit omvat sociale zekerheidsnummers, rijbewijsnummers, paspoortnummers en andere unieke identificatoren die een individu specifiek kunnen identificeren. Documenten die persoonlijke identificatiegegevens bevatten, vereisen zorgvuldige behandeling om identiteitsdiefstal en fraude te voorkomen.
-
Financiële Informatie: Deze categorie omvat bankrekeningnummers, creditcardgegevens en transactiegegevens. Blootstelling van dergelijke gegevens kan leiden tot financiële verliezen en misbruik van fondsen, wat de noodzaak van strenge beveiligingsmaatregelen tijdens parseringsprocessen benadrukt.
-
Medische Dossiers: Beschermde gezondheidsinformatie (PHI), zoals patiëntgeschiedenissen, diagnoses en behandelplannen, valt onder deze categorie. Onjuiste behandeling van medische dossiers kan leiden tot schendingen van de vertrouwelijkheid en privacy van patiënten, met ernstige ethische en juridische gevolgen.
-
Communicatiegegevens: Dit omvat persoonlijke correspondentie die vertrouwelijke zakelijke onderhandelingen of gevoelige persoonlijke discussies kan onthullen. De parsering van e-mails of berichttranscripten moet ervoor zorgen dat dergelijke gegevens niet worden blootgesteld of verkeerd worden behandeld.
-
Locatiegegevens: Geolocatie-informatie die de bewegingen of woonplaats van een individu kan pinpointen, vooral wanneer deze wordt gecombineerd met andere gegevens, kan gevoelig zijn. De parsering van documenten die reisroutes of huisadressen bevatten, vereist bijzondere aandacht voor privacykwesties.
Waarom Is Deze Gegevens in Risico?
Een IDP-oplossing biedt een uitgebreide benadering van het beheren van de complexiteit van documentparsering. Begrijpen wat intelligente documentverwerking is, is essentieel voor bedrijven die hun gegevensverwerkingscapaciteiten willen verbeteren. Gevoelige gegevens lopen risico tijdens documentparsering vanwege verschillende kwetsbaarheden:
- Gegevensinbreuken: Ongeautoriseerde toegang tot gevoelige informatie kan optreden als beveiligingsmaatregelen onvoldoende zijn.
- Gegevenslekken: Gevoelige informatie kan per ongeluk worden blootgesteld tijdens de extractie- of verwerkingsfasen.
- Ongeautoriseerde toegang: Zonder juiste toegangscontroles kan gevoelige data worden benaderd door onbetrouwbare partijen.
Belangrijke Privacy- en Beveiligingsuitdagingen in Documentparsering
Documentparsering omvat het extraheren van gestructureerde gegevens uit ongestructureerde of semi-gestructureerde documenten, wat gevoelige informatie aan verschillende risico's kan blootstellen als het niet veilig wordt behandeld. Met een IDP-oplossing kunnen organisaties de risico's die gepaard gaan met gevoelige gegevensinbreuken verminderen. Het gebruik van tools voor intelligente documentverwerking kan het risico op gegevenslekken en ongeautoriseerde toegang aanzienlijk verminderen.
Risico's van Gegevensextractie
Een van de belangrijkste uitdagingen is het risico op gegevenslekken tijdens het extractieproces. Gevoelige gegevens kunnen per ongeluk worden blootgesteld als documenten niet goed worden gesaneerd of als extractietools de noodzakelijke beveiligingsmaatregelen missen. Bijvoorbeeld, parseringstools die persoonlijke identificatiegegevens niet redigeren voordat ze worden verwerkt, kunnen leiden tot onopzettelijke onthulling van sociale zekerheidsnummers of financiële informatie.
Opslag en Toegangsbeheer
Gevoelige gegevens die uit documenten zijn geparsed, moeten vaak worden opgeslagen voor verdere analyse of archivering. Onjuiste opslagpraktijken, zoals onvoldoende versleuteling of onvoldoende toegangscontroles, kunnen leiden tot ongeautoriseerde toegang. Als geparsed gegevens bijvoorbeeld in een database worden opgeslagen zonder juiste versleuteling, kan dit kwetsbaar zijn voor inbreuken, waardoor gevoelige financiële of medische dossiers kunnen worden blootgesteld.
Juridische Naleving
Regelgeving zoals GDPR en HIPAA stelt strikte eisen aan hoe gevoelige gegevens moeten worden behandeld, ook tijdens documentparsering. Niet-naleving kan leiden tot aanzienlijke juridische en financiële sancties. Onder GDPR moeten organisaties ervoor zorgen dat persoonlijke gegevens op een manier worden verwerkt die passende beveiliging waarborgt, inclusief bescherming tegen ongeautoriseerde of onwettige verwerking en tegen onopzettelijk verlies, vernietiging of schade.
Essentiële Privacy- en Beveiligingsbest Practices in Documentparsering
Om de uitdagingen die gepaard gaan met documentparsering te verminderen, is het cruciaal om best practices te implementeren die privacy en beveiliging prioriteit geven. IDP-technologie, met zijn geavanceerde functies, speelt een cruciale rol in het waarborgen van de privacy en beveiliging van documentparsering. De nauwkeurigheid van VLM is dramatisch verbeterd in vergelijking met OCR-factuurverwerking, waardoor de behoefte aan handmatige gegevensinvoer wordt verminderd.
Gegevensversleuteling
Versleuteling is een kritische maatregel om gevoelige gegevens zowel tijdens verzending als in rust te beschermen. Door IDP (intelligente documentverwerking) te implementeren, kunnen bedrijven hun operaties stroomlijnen en de gegevensnauwkeurigheid verbeteren. Het gebruik van een Python PDF-parser kan het proces van documentparsering stroomlijnen, waardoor snellere en nauwkeurigere gegevensextractie mogelijk is.
Anonimisering en Pseudonimisering
Anonimisering houdt in dat alle identificeerbare informatie uit gegevens wordt verwijderd, waardoor het onmogelijk wordt om deze terug te traceren naar een individu. Pseudonimisering vervangt identificatoren door kunstmatige, waardoor het risico op heridentificatie wordt verminderd. Deze technieken zijn essentieel bij het parseren van documenten die persoonlijke gegevens bevatten om te voldoen aan privacyregelgeving zoals GDPR, die het principe van gegevensminimalisatie benadrukt.
Toegangscontroles en Auditlogs
Het implementeren van strikte toegangscontroles en het bijhouden van auditlogs zijn essentieel voor het beheren van wie toegang heeft tot gevoelige gegevens. Toegang moet worden verleend op basis van behoefte aan kennis, en alle toegang moet worden gelogd en gecontroleerd. Bijvoorbeeld, rolgebaseerde toegangscontrole (RBAC) kan ervoor zorgen dat alleen geautoriseerd personeel toegang heeft tot gevoelige gegevens, en auditlogs kunnen helpen bij het volgen van ongeautoriseerde toegangspogingen.
Regelmatige Beveiligingsaudits
Regelmatige beveiligingsaudits kunnen helpen kwetsbaarheden in het documentparseringsproces te identificeren. Deze audits moeten penetratietests, codebeoordelingen en kwetsbaarheidsbeoordelingen omvatten. Het inschakelen van een derde partij om een red-teaming oefening uit te voeren, kan helpen potentiële zwaktes in het parseringssysteem te onthullen die door aanvallers kunnen worden uitgebuit. Door deze best practices te implementeren, kunnen organisaties het risico op gegevensinbreuken aanzienlijk verminderen en voldoen aan de regelgeving voor gegevensbescherming, waardoor zowel hun operaties als de privacy van de individuen wiens gegevens zij verwerken, worden beschermd.
AnyParser in Documentparsering: Privacy en Beveiliging Verbeteren
Intelligente documentverwerkingstools zijn ontworpen om gegevens met hoge precisie te extraheren, analyseren en beheren. AnyParser, ontwikkeld door het CambioML-team, steekt bovenuit als een robuuste documentparseringstool die de belangrijkste privacy- en beveiligingsuitdagingen in documentparsering aanpakt met zijn unieke set functies en mogelijkheden.
Gestructureerde Output en Lokale Verwerking
AnyParser converteert geëxtraheerde informatie naar gestructureerde formaten zoals Markdown, wat verdere gegevensverwerking en -analyse vergemakkelijkt. De lokale verwerkingsfunctie zorgt ervoor dat gevoelige gegevens nooit de locatie van de gebruiker verlaten, waardoor het risico op gegevensinbreuken aanzienlijk wordt verminderd. Een Python PDF-parser is een essentieel hulpmiddel voor ontwikkelaars die de extractie van gegevens uit PDF-documenten willen automatiseren.
Technologische Voordelen
AnyParser maakt gebruik van grote taalmodellen (LLM) voor documentbegrip en informatie-extractie, wat niet alleen de nauwkeurigheid verbetert, maar ook de beveiliging verhoogt door de noodzaak voor handmatige gegevensverwerking te verminderen. Het modulaire ontwerp maakt eenvoudige uitbreiding en aanpassing mogelijk, zodat het kan voldoen aan de evoluerende zakelijke vereisten.
AI en ML in Documentbeveiliging
Kunstmatige Intelligentie (AI) en Machine Learning (ML) kunnen de beveiliging van documentparsering verbeteren door compliance-controles te automatiseren en potentiële gegevensinbreuken te identificeren. Deze technologieën kunnen enorme hoeveelheden gegevens snel en nauwkeurig analyseren, waardoor gevoelige informatie wordt beschermd. Bijvoorbeeld, VLM-factuurverwerking, die beter is dan OCR-factuurverwerking, is een belangrijk onderdeel van intelligente documentverwerking, waardoor de automatische extractie van factuurgegevens mogelijk is.
Regelgevende Naleving en de Rol ervan in Gegevensbeveiliging
Overzicht van Belangrijke Regelgeving
Belangrijke regelgeving zoals GDPR en HIPAA stelt strikte eisen aan de omgang met gevoelige gegevens. GDPR richt zich op de bescherming van persoonlijke gegevens binnen de Europese Unie, terwijl HIPAA normen stelt voor de bescherming van gezondheidsinformatie in de Verenigde Staten.
Gevolgen voor Bedrijven
Niet-naleving van deze regelgeving kan leiden tot hoge boetes en juridische acties. Daarom moeten bedrijven veilige documentparsering prioriteit geven om ervoor te zorgen dat ze aan alle wettelijke vereisten voldoen en de gegevens van hun klanten beschermen. De integratie van IDP (intelligente documentverwerking) tools zorgt voor naleving van gegevensbeschermingsregelgeving.
Toekomstige Trends in Privacy en Beveiliging voor Documentparsering
Vooruitgang in AI en Veilige Gegevensverwerking
Toekomstige trends omvatten vooruitgang in AI en veilige gegevensverwerkingstechnologieën, zoals kwantumversleuteling en privacy-versterkende technologieën (PET's). Deze innovaties beloven nog sterkere beveiligingsmaatregelen te bieden voor het beschermen van gevoelige gegevens. Voor bedrijven die grote hoeveelheden PDF-documenten verwerken, biedt een Python PDF-parser een schaalbare oplossing voor documentverwerking. Intelligente documentverwerkingstools, zoals AnyParser, staan aan de voorhoede van innovatie op het gebied van gegevensprivacy en -beveiliging.
Continue Aanpassing aan Evoluerende Bedreigingen
Het landschap van cyberbedreigingen evolueert voortdurend. Bedrijven moeten op de hoogte blijven van nieuwe beveiligingspraktijken en zich voortdurend aanpassen aan opkomende bedreigingen om de voortdurende bescherming van gevoelige gegevens te waarborgen.
Conclusie
Het beschermen van gevoelige gegevens in documentparsering is van het grootste belang. Door best practices aan te nemen, geavanceerde technologieën te benutten en te zorgen voor naleving van regelgeving, kunnen bedrijven hun gegevens beschermen en het vertrouwen van hun klanten behouden. Prioriteit geven aan gegevensbeveiliging beschermt niet alleen het bedrijf, maar waarborgt ook de privacy en veiligheid van individuen wiens gegevens worden verwerkt.
Oproep tot Actie: Omarm AnyParser voor Veilige Documentparsering
Om gevoelige gegevens te beschermen en uw documentparseringsprocessen te stroomlijnen, overweeg dan om AnyParser te adopteren. Deze krachtige tool biedt een uitgebreide suite van functies die zijn ontworpen om zowel de beveiliging als de efficiëntie van uw gegevensverwerkingspraktijken te verbeteren. Bezoek AnyParser's sandbox om de mogelijkheden GRATIS te testen en te ontdekken hoe het uw organisatie kan helpen. Zet vandaag de eerste stap naar een veiligere en compliant documentparseringsstrategie.