Å konvertere komplekse PDF-filer til Markdown kan være utfordrende. Det finnes mange open-source biblioteker tilgjengelig for å hente ut tekst fra PDF, men når det gjelder PDF-er som inneholder komplekse elementer som tabeller og diagrammer, er resultatene ofte utilstrekkelige. Populære store språkmodeller som GPT eller Claude kan håndtere disse oppgavene, men de har en tendens til å være trege og kan noen ganger produsere unøyaktige resultater. Tradisjonelle OCR-verktøy, selv om de er effektive for enklere dokumenter, sliter ofte med å opprettholde den nøyaktige strukturen og den semantiske betydningen av det opprinnelige innholdet. På den annen side kan visjons-språkmodeller noen ganger hallusinere, noe som fører til feilaktige parseresultater. Denne bloggen vil forklare hva "parse" betyr og detaljere resultatene av en sammenlignende analyse av flere modeller ved hjelp av flere metrikker.
Hva betyr parse?
I konteksten av PDF-parsing refererer "parse" til prosessen med å hente ut spesifikke data fra en PDF-fil ved hjelp av spesialisert programvare kjent som en PDF-parser. En PDF-parser analyserer innholdet i et PDF-dokument og identifiserer elementer som tekst, bilder, skrifttyper, oppsett og til og med metadata. De hentede dataene kan deretter organiseres og eksporteres til forskjellige formater som XML, JSON eller Excel/CSV, som kan brukes til ulike formål som dataanalyse, arkivering eller automatisering av arbeidsflyter.
Å forstå hva "parse" betyr er avgjørende for å evaluere effektiviteten av en parser-løsning, spesielt når man sammenligner forskjellige PDF til Markdown-konverteringsverktøy, da PDF-parser involverer mer enn bare enkel tekstuttrekking—det krever gjenkjenning og opprettholdelse av dokumentets semantiske struktur.
Hvordan måler vi kvaliteten på disse parser-løsningene?
Vi har definert en serie ordnivå metrikker for å vurdere ytelsen til forskjellige modeller, med fokus på nøkkelfaktorer som:
-
Presisjon, Tilbakekalling og F-Mål: Evaluering av kvaliteten og fullstendigheten av parsing.
-
BLEU-score og ANLS: Nyttige for å evaluere språk- og oppsettstruktur.
-
Redigeringsavstand, Jensen-Shannon Divergens, og Jaccard Avstand: Metrikker spesifikke for OCR-domenet, spesielt nyttige for å forstå nøyaktigheten av innholdsreproduksjon.
Vår visjons-språkmodell, AnyParser, viser eksepsjonell ytelse, og kombinerer hastighet og nøyaktighet, spesielt på komplekse oppsett med tabeller og semantiske elementer. AnyParser overgår andre løsninger, og tilbyr en 20x hastighetsforbedring over modeller som GPT/Claude samtidig som den oppnår høyere nøyaktighet.
En omfattende sammenligning mot ledende parser-modeller
Statistisk objekt
For virkelig å vise kapasitetene til AnyParser, gjennomførte vi en omfattende sammenligning mot ledende parser-modeller i bransjen og kjente store språkmodeller (LLM). Vår evaluering inkluderte:
1. Store språkmodeller
- AnyParser
- OpenAI's GPT-4o
- Google's Gemini 1.5 Pro
- Anthropic's Claude 3.5 Sonnet
2. OCR-baserte tjenester
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Resultatpresentasjon og analyse
Eksperiment 1
Først gjennomfører vi en serie strenge sammenligninger av ytelsen til forskjellige dokument AI-modeller på over 5 metrikker nedenfor: BLEU, presisjon og tilbakekalling, F-mål og ANLS. Du kan finne den matematiske definisjonen av disse definisjonene i appendikset.
Modellene som ble sammenlignet er: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl, og Azure-DocAl.
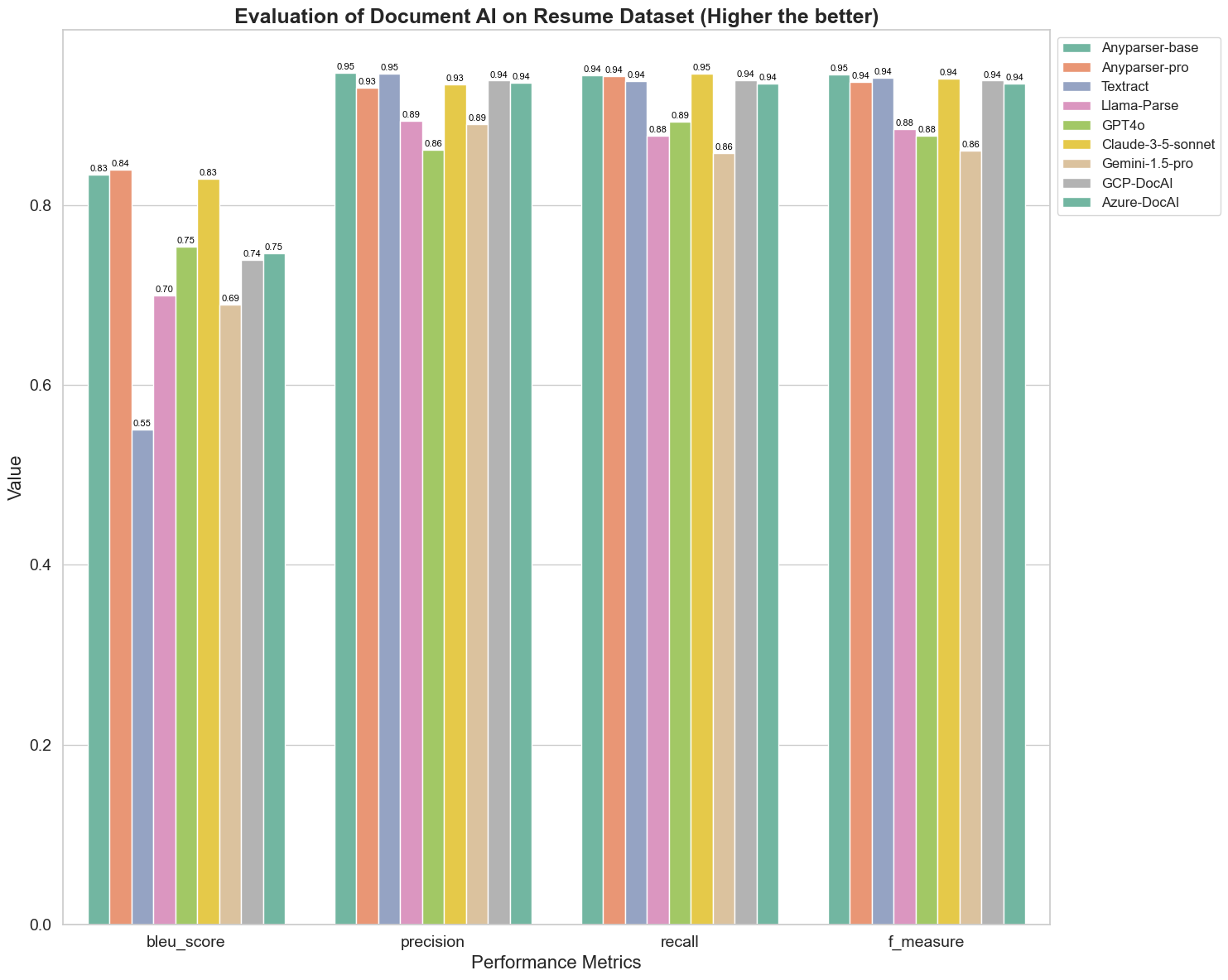
BLEU brukes som en vurdering av kvaliteten på tospråklig tolkning for å teste kvaliteten på modellene i behandlingen av ytringer. Ved å sammenligne resultatene av disse parser-modellene under BLEU-vurderingsmetoden, finner vi at: poengene til AnyParser-base og AnyParser-pro er betydelig høyere enn poengene til de andre modellene, Amazon Textract scorer lavest, og resultatene av poengene til de andre modellene ligger på et relativt gjennomsnittlig nivå.
Gjenkjenningsnøyaktighet representeres vanligvis av presisjon og tilbakekalling, hvor presisjon representerer prosentandelen av virkelig korrekte resultater blant resultatene vurdert som korrekte av modellen, og tilbakekalling representerer prosentandelen av virkelig korrekt vurderte resultater av modellen blant alle faktisk korrekte resultater. Ved å sammenligne presisjon og tilbakekalling av disse parser-modellene, finner vi at: bortsett fra Llama-Parse, GPT4o og Gemini-1.5-pro, er alle andre modeller på et høyt nivå. Blant dem er AnyParser og Amazon Textract mer fremtredende i presisjon, mens AnyParser-base og AnyParser-pro er mer fremtredende i tilbakekalling. Den høyere poengsummen til modellen på presisjon indikerer at modellen gir mer korrekt informasjon i produksjonsresultatene, og den høyere poengsummen på tilbakekalling indikerer at modellen er mer i stand til å hente korrekt informasjon fra prøven. Resultatene viser at AnyParser har en klar fordel når det gjelder gjenkjenningsnøyaktighet for å hente ut tekst fra PDF.
F-mål er en omfattende evalueringsindeks for presisjon og tilbakekalling på disse to indikatorene. Ved å sammenligne poengene til disse parser-modellene under F-mål, kan vi se mer intuitivt at de fem modellene, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI og Azure-DocAI, har en bedre styrke når det gjelder gjenkjenningsnøyaktighet sammenlignet med andre modeller. Vi kan se mer intuitivt at de fem modellene har mer styrke i gjenkjenningsnøyaktighet enn de andre modellene, og AnyParser har den høyeste poengsummen under F-mål, noe som ytterligere illustrerer den åpenbare fordelen til AnyParser i gjenkjenningsnøyaktighet for å hente ut tekst fra PDF.
ANLS, som er en vanlig brukt evalueringsindeks når det gjelder å måle nøyaktighet og likhet mellom den opprinnelige teksten og målteksten på tegnnivå, er også veldig informativ for å måle parser-nivået til modellene. De høyere poengsummene til AnyParser-base, AnyParser-pro og Azure-DocAI reflekterer det høyere parser-nivået til disse modellene sammenlignet med de andre modellene.
Totalt sett overgår AnyParser-base og AnyParser-pro de andre modellene.
Eksperiment 2
Vi sammenligner også ytelsen til forskjellige dokument AI-modeller på tre forskjellige metrikker: Redigeringsavstand, Jensen-Shannon Divergens, og Jaccard Avstand. Metrikkene brukes til å måle likheten mellom utdataene fra modellene og et referansedokument. Lavere verdier indikerer bedre ytelse.
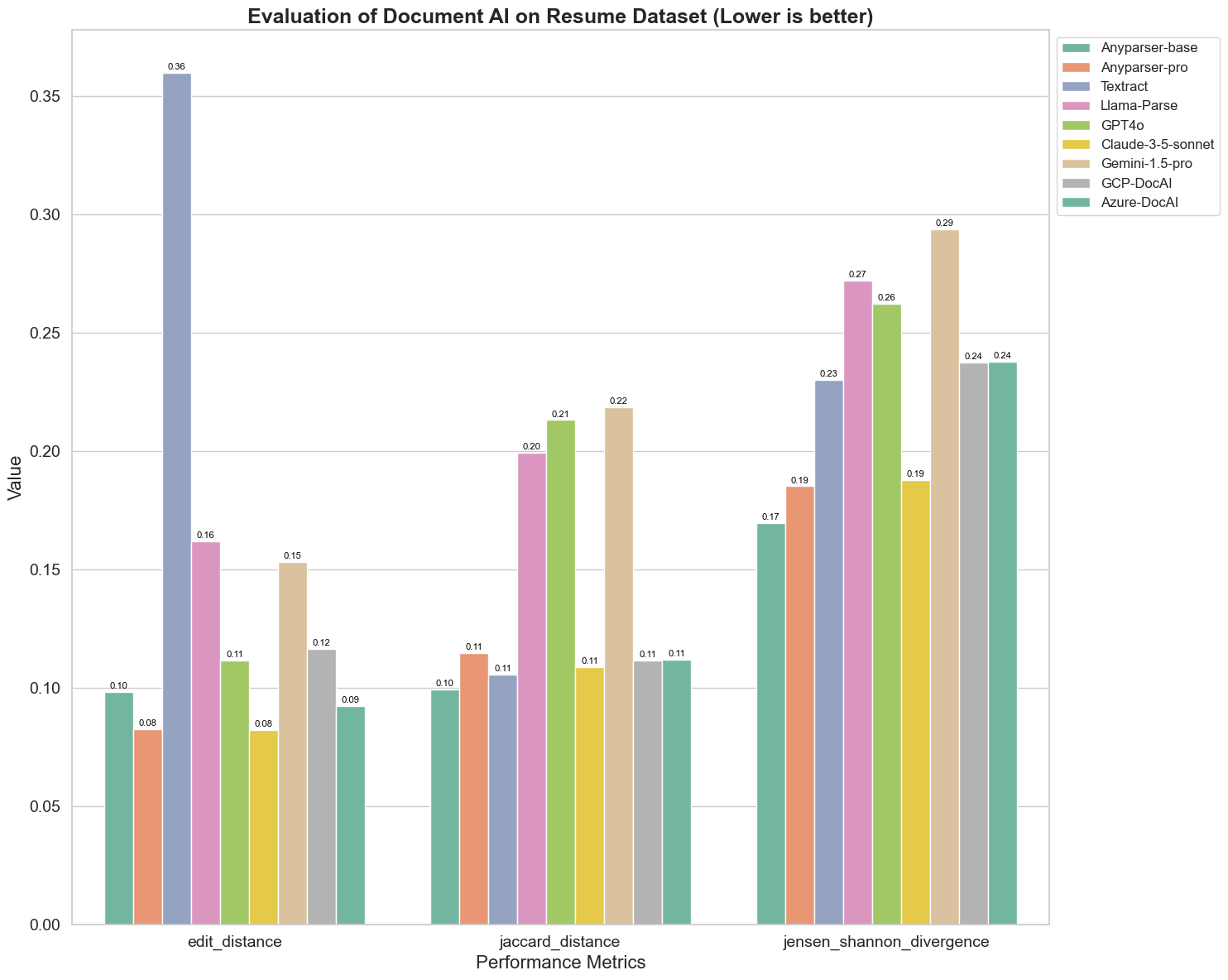
Her er noen viktige observasjoner fra diagrammet:
-
Redigeringsavstand: Modellene AnyParser-base og AnyParser-pro presterer best med den laveste redigeringsavstanden, noe som antyder at utdataene deres var nærmest referansedokumentet.
-
Jensen-Shannon Divergens: Modellene AnyParser-base og AnyParser-pro har den laveste divergensen, noe som antyder at utdataene deres er mest like referansedokumentet når det gjelder ordfordeling.
-
Jaccard Avstand: Bortsett fra Llama-parse, GPT4O, Gemini-1.5, presterer alle de andre modellene anstendig med den laveste Jaccard-avstanden, noe som indikerer at utdataene deres har den høyeste overlappen med referansedokumentet når det gjelder settet av ord som brukes.
Konklusjon
Totalt sett antyder våre strenge tester at AnyParser-base og AnyParser-pro generelt presterer godt på tvers av ulike metrikker, noe som indikerer potensialet for nøyaktig dokumentbehandling. Fra diagrammene kan vi se at tradisjonelle OCR-modeller som den kjente Amazon Textract scorer mye lavere enn visjons-språkmodeller. Imidlertid varierer ytelsen til forskjellige modeller avhengig av metrikken som brukes, noe som fremhever viktigheten av å vurdere flere evalueringskriterier når man sammenligner AI-modeller.
Introduksjon av vår open-source evalueringspipeline
For å strømlinjeforme evalueringene har vi opprettet en evalueringspipeline som gir en bransjestandardmetode for sammenligning av parser-modeller. I vårt eksempel demonstrerer vi bruken i HR-domenet, hvor CV-parsing er vanlig. Vi bygde et variert syntetisk datasett med 128 CV-er, generert ved hjelp av parrede bilde-Markdown-filer. Ved å bruke GPT-4 genererte vi HTML-innhold, gjengav det til bilder, og brukte den hentede teksten som sannhetsgrunnlag for sammenligning.
Og her er den beste delen: vi har open-sourcet denne evalueringsrammen på GitHub! Enten du er utvikler eller forretningsbruker, gjør vår pipeline det mulig for deg å evaluere og sammenligne parserkvaliteten til forskjellige modeller på ditt eget datasett.
Finn hurtigstartguiden i Github-repoet og se hvordan forskjellige parser-modeller står opp mot hverandre. Vi tror at ved å vise styrken til modellen vår åpent, kan vi tiltrekke flere brukere som ønsker pålitelige, raske og nøyaktige parserkapabiliteter.
Appendiks - Metrikker
1. Presisjon
Presisjon måler nøyaktigheten til det parserte innholdet, og viser hvor mange av de hentede elementene som var korrekte. I parsing er det andelen korrekt hentede ord av alle ord som er hentet.
Presisjon = Sanne Positiver (TP) / (Sanne Positiver (TP) + Falske Positiver (FP))
- Sanne Positiver (TP): Ord som er korrekt identifisert av parseren.
- Falske Positiver (FP): Ord som er feilaktig identifisert av parseren.
2. Tilbakekalling
Tilbakekalling indikerer fullstendigheten av parsing, eller hvor mange relevante ord fra det opprinnelige dokumentet som ble hentet.
Tilbakekalling = Sanne Positiver (TP) / (Sanne Positiver (TP) + Falske Negativer (FN))
- Falske Negativer (FN): Ord i det opprinnelige dokumentet som ble oversett av parseren.
3. F-mål (F1-score)
F1-score er det harmoniske gjennomsnittet av presisjon og tilbakekalling, som balanserer begge metrikker for å gi et samlet mål på parsingkvalitet.
F1-score = 2 × (Presisjon × Tilbakekalling) / (Presisjon + Tilbakekalling)
4. BLEU-score (Bilingual Evaluation Understudy)
BLEU-scoren måler likheten mellom det parserte innholdet og den opprinnelige teksten, med særlig vekt på rekkefølgen av ord. Den er spesielt nyttig for å evaluere språk- og strukturkonsistens i parserte dokumenter, da den straffer utdata som avviker i rekkefølge fra den opprinnelige.
5. ANLS (Gjennomsnittlig Normalisert Levenshtein Likhet)
ANLS kvantifiserer likheten mellom det parserte innholdet og den opprinnelige, ved å bruke normalisert redigeringsavstand. Den beregnes ved å ta gjennomsnittet av Normalisert Levenshtein Likhet (NLS) for hvert ordpar i de parserte og referansetekstene. NLS beregnes som følger:
NLS = 1 - (Levenshtein Avstand (LD)(parserte ord, opprinnelige ord)) / max(Lengde av parserte ord, Lengde av opprinnelige ord)
Deretter er ANLS gjennomsnittet av NLS over alle ordpar:
ANLS = (1/N) × Σ(NLS_i) for i=1 til N
6. Redigeringsavstand
Redigeringsavstand beregner antall ordnivåoperasjoner (innsettinger, slettinger, substitusjoner) som kreves for å konvertere den parserte teksten til den opprinnelige.
7. Jensen-Shannon Divergens
Jensen-Shannon Divergens måler likheten mellom diskrete sannsynlighetsfordelinger av parserte og originale ordteller, og fremhever forskjeller i ordhyppighet.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
hvor M = (1/2)(P + Q), og KL(P || Q) er Kullback-Leibler-divergens
8. Jaccard Avstand
Jaccard Avstand måler ulikheten mellom sett av ord i parserte og originale innhold, nyttig for å vurdere ordoverlapp.
Jaccard Avstand = 1 - |A ∩ B| / |A ∪ B|
hvor |A ∩ B| er antallet felles elementer mellom A og B,
og |A ∪ B| er det totale antallet unike elementer i begge sett.