Introdução
Tabelas são uma pedra angular da representação de dados estruturados, amplamente utilizadas em indústrias como finanças, saúde e pesquisa. No entanto, extrair informações tabulares de formatos como PDFs, documentos digitalizados ou imagens continua sendo um desafio devido a layouts variados e complexidades.
A inteligência artificial (IA) revolucionou a análise de documentos, permitindo soluções precisas e eficientes para problemas como como extrair uma tabela de um PDF ou converter um PNG de tabela em dados estruturados. Ao aproveitar técnicas avançadas de IA, as empresas agora podem transformar facilmente visuais não estruturados em insights acionáveis, incluindo a conversão de uma imagem em uma tabela para integração perfeita em fluxos de trabalho.
Este blog explora como a extração de tabelas com IA capacita indústrias, destaca as tecnologias subjacentes e demonstra seu potencial para simplificar tarefas complexas de processamento de documentos.

Desafios na Extração Tradicional de Tabelas
Extrair manualmente dados tabulares de documentos como PDFs ou imagens é tedioso, propenso a erros e ineficiente. Abaixo estão alguns dos desafios comuns enfrentados com métodos tradicionais:
-
Estruturas de Tabela Complexas: As tabelas frequentemente possuem layouts irregulares, como células aninhadas, cabeçalhos de várias linhas ou linhas mescladas, que são difíceis de interpretar. Ferramentas tradicionais falham em extrair com precisão tabelas de PDFs em tais cenários.
-
Formatos Diversos: As tabelas aparecem em uma ampla gama de formatos, incluindo documentos digitalizados, arquivos PNG de tabelas e PDFs. Extrair dados desses requer técnicas de reconhecimento avançadas que vão além do simples OCR.
-
Contexto e Significado: Sistemas tradicionais têm dificuldade em preservar as relações entre linhas e colunas, o que é crucial ao converter uma imagem em tabela ou processar grandes conjuntos de dados.
Esses desafios enfatizam a necessidade de soluções inteligentes como a extração de tabelas com IA, que pode lidar com layouts complexos e formatos diversos, garantindo alta precisão.
O Que É Extração de Tabelas com IA?
A extração de tabelas com IA é a aplicação de técnicas de análise inteligente de documentos adaptadas para identificar, extrair e organizar dados estruturados de tabelas em vários formatos de documentos. Ao contrário dos métodos tradicionais baseados em regras, as abordagens impulsionadas por IA utilizam tecnologias avançadas para enfrentar desafios complexos, como layouts não padronizados, células mescladas e cabeçalhos de várias linhas.
Um avanço chave neste campo é o uso de Modelos de Visão-Linguagem (VLMs). Os VLMs combinam as forças da visão computacional e da compreensão da linguagem natural, permitindo que interpretem elementos visuais e textuais dentro de um documento. Essa capacidade dupla permite que os VLMs:
- Identifiquem estruturas de tabela visualmente, mesmo quando não possuem formatação explícita.
- Compreendam contextual e semanticamente o conteúdo, como distinguir entre cabeçalhos, dados e notas.
- Se adaptem a vários tipos de documentos, incluindo imagens digitalizadas, PDFs e anotações manuscritas.
Ao aproveitar os VLMs, a extração de tabelas com IA se tornou mais precisa e versátil, capaz de lidar com documentos multilíngues e extrair relações entre pontos de dados que os métodos tradicionais frequentemente perdem.
Tecnologias Chave por Trás da Extração de Tabelas com IA
A extração de tabelas com IA depende de um conjunto de tecnologias avançadas que trabalham em harmonia para superar os desafios tradicionais. Entre elas, os Modelos de Visão-Linguagem (VLMs) se destacam como uma inovação transformadora. Abaixo está uma descrição das tecnologias-chave e o papel fundamental dos VLMs:
-
Reconhecimento Óptico de Caracteres (OCR): Extrai texto de imagens ou documentos digitalizados. Quando combinado com VLMs, os resultados do OCR são aprimorados porque os modelos entendem tanto a estrutura visual quanto o significado textual.
-
Modelos de Visão-Linguagem (VLMs): Os VLMs revolucionam a extração de tabelas ao integrar o processamento de dados visuais e linguísticos. Eles se destacam em:
- Reconhecer layouts de tabelas complexas e limites irregulares.
- Interpretar relações entre linhas, colunas e cabeçalhos.
- Lidar com tabelas em formatos diversos, incluindo imagens e PDFs, com suporte multilíngue. Os VLMs permitem uma compreensão contextual mais profunda, garantindo que os dados extraídos mantenham seu significado e estrutura originais.
-
Processamento de Linguagem Natural (NLP): Analisa e organiza os dados extraídos, garantindo coerência semântica. Os VLMs aprimoram ainda mais o NLP ao fornecer pistas contextuais a partir de padrões visuais.
-
Algoritmos de Aprendizado Profundo: Treinam modelos para detectar limites de tabelas, hierarquias de células e padrões em documentos não estruturados. Quando enriquecidos pelos VLMs, esses algoritmos alcançam maior precisão e adaptabilidade.
Ao enfatizar os VLMs, a extração de tabelas com IA passou de uma tarefa de simples recuperação de dados para uma de compreensão contextualizada, tornando-se inestimável para indústrias onde precisão e nuance são fundamentais.
Casos de Uso da Extração de Tabelas com IA
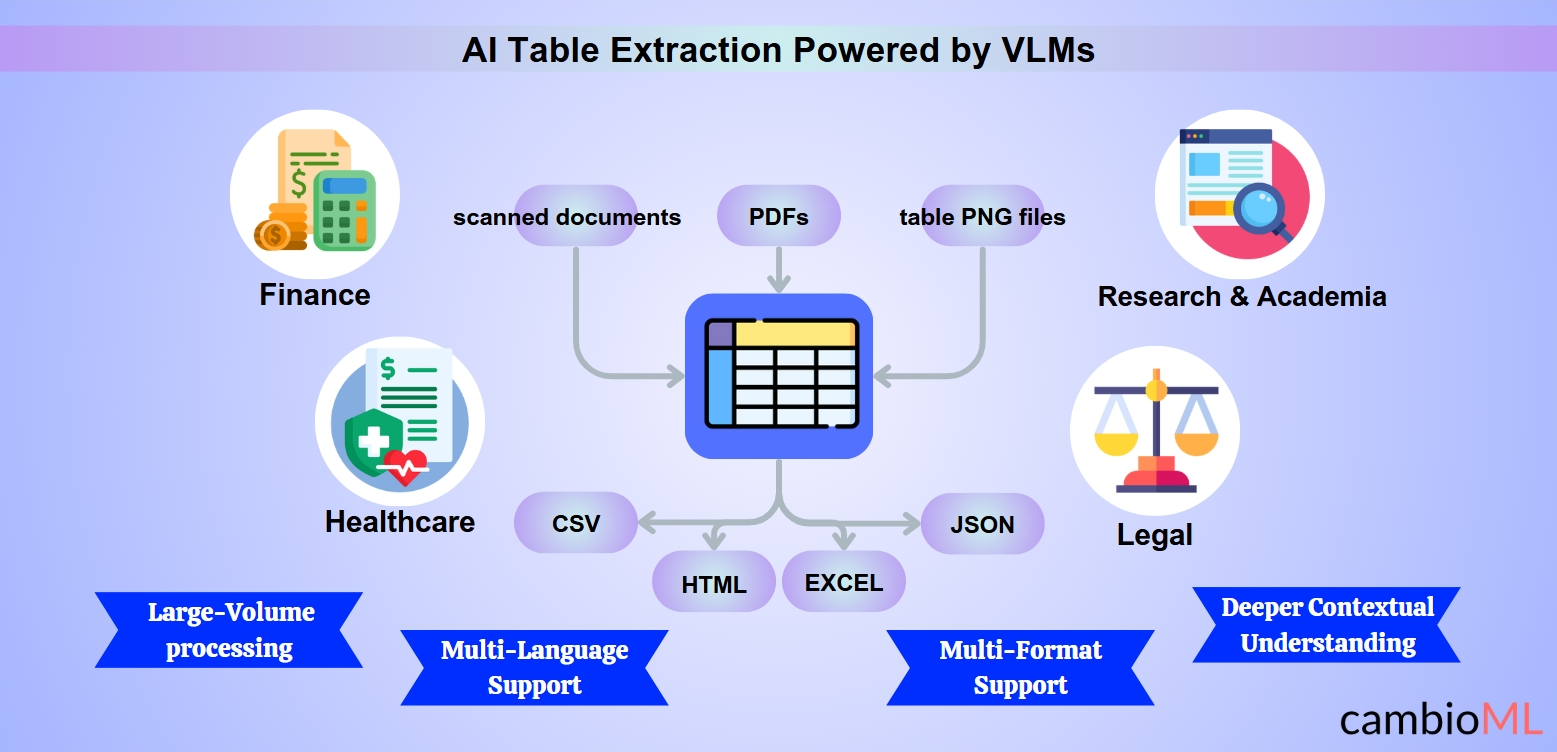
A extração de tabelas impulsionada por IA está transformando indústrias ao automatizar o processo de extração e organização de dados tabulares de vários formatos de documentos. Abaixo estão alguns casos de uso notáveis onde a extração inteligente de tabelas se mostrou inestimável:
-
Finanças: Extrair dados estruturados de demonstrações financeiras, faturas e relatórios é frequentemente uma tarefa trabalhosa. A IA torna fácil copiar uma tabela de PDF para Excel, permitindo uma reconciliação, análise e relatórios mais rápidos.
-
Saúde: Organizar resultados de ensaios clínicos, registros de pacientes ou dados de pesquisa médica é simplificado. Por exemplo, os provedores de saúde podem facilmente copiar uma tabela de um PDF para Excel, garantindo que os dados estejam prontos para integração em sistemas de registro eletrônico de saúde (EHR).
-
Jurídico: Analisar contratos e extrair cláusulas estruturadas de tabelas aninhadas ajuda as equipes jurídicas a trabalharem de forma mais eficiente. Modelos de IA tornam simples copiar uma tabela de PDF para Excel, economizando tempo em verificações de conformidade e pesquisa de litígios.
-
Pesquisa e Academia: Pesquisadores podem rapidamente extrair dados de artigos acadêmicos, simplificando a tarefa de transferir métricas-chave usando ferramentas para copiar tabelas de PDF para Excel, tornando conjuntos de dados prontos para análise estatística.
A capacidade da extração de tabelas com IA de processar com precisão formatos de documentos diversos está revolucionando fluxos de trabalho, facilitando a cópia, organização e análise de dados tabulares em planilhas do Excel.
Benefícios da Extração Inteligente de Tabelas
A extração de tabelas com IA oferece uma série de benefícios, especialmente na melhoria da eficiência, precisão e escalabilidade. Ao aproveitar tecnologias avançadas, incluindo Modelos de Visão-Linguagem (VLMs), as empresas podem superar os desafios tradicionais na extração de tabelas:
-
Automação e Economia de Tempo: Tarefas repetitivas, como copiar manualmente tabelas de PDF para Excel, são eliminadas, permitindo que os funcionários se concentrem em atividades de maior valor.
-
Precisão Aprimorada: Modelos de IA reduzem significativamente os erros que são comuns quando os usuários copiam manualmente tabelas de PDF para Excel ou dependem de ferramentas básicas. Esses modelos garantem que os dados mantenham sua estrutura e significado.
-
Escalabilidade para Processamento de Grande Volume: Ferramentas de IA são projetadas para lidar com extração de dados em massa. Seja para registros financeiros, documentos de pesquisa ou arquivos de conformidade, elas simplificam o processo de extração e organização de dados no Excel.
-
Suporte a Múltiplos Formatos e Idiomas: Sistemas inteligentes podem processar documentos em vários formatos e idiomas, permitindo a extração perfeita e a cópia de tabelas de PDF para Excel, mesmo em contextos multilíngues complexos.
A extração de tabelas com IA não apenas agiliza fluxos de trabalho, mas também garante a integridade contextual dos dados, transformando a forma como as indústrias lidam com informações tabulares. Essa eficiência é crítica no mundo orientado por dados de hoje, onde o processamento rápido e preciso de dados tabulares é uma vantagem competitiva.
Abordando Desafios de Múltiplos Formatos e Idiomas
Soluções modernas de IA se destacam em enfrentar a variabilidade de formatos e idiomas, garantindo precisão e eficiência consistentes em conjuntos de dados diversos:
-
Capacidades de Múltiplos Formatos: Ferramentas impulsionadas por IA podem processar facilmente PDFs, documentos digitalizados e arquivos de imagem como PNG de tabelas. Essa versatilidade é especialmente crítica quando os usuários precisam extrair tabelas de PDFs ou converter uma imagem em tabela para análise e relatórios.
-
Suporte a Múltiplos Idiomas: Modelos de IA são treinados em conjuntos de dados multilíngues, permitindo que lidem com documentos em vários idiomas. Esse recurso é inestimável para indústrias globais que lidam com documentação internacional.
-
Preservação das Relações de Dados: Seja processando uma imagem em tabela ou extraindo uma estrutura complexa de um PDF, sistemas de IA garantem que cabeçalhos, linhas e colunas sejam preservados, mantendo a integridade dos dados.
Ao abordar esses desafios, soluções de IA se estabeleceram como ferramentas indispensáveis para organizações que lidam com documentação em grande escala, multilíngue e em múltiplos formatos.
O Futuro da IA na Extração de Tabelas
O futuro da extração de tabelas com IA é promissor, com avanços que devem aprimorar ainda mais suas capacidades:
-
Modelos de Visão-Linguagem (VLMs) Aprimorados: Tecnologias emergentes de VLM fornecerão maneiras ainda mais sofisticadas de extrair tabelas de PDFs e converter formatos complexos de PNG de tabelas em dados estruturados. Esses modelos irão preencher a lacuna entre elementos visuais e compreensão textual.
-
Integração com IA Generativa: Ao integrar IA generativa, soluções futuras podem não apenas extrair tabelas de PDFs ou imagens, mas também analisar os dados extraídos em busca de insights, resumos e recomendações.
-
Automação de Ponta a Ponta: Ferramentas impulsionadas por IA irão simplificar fluxos de trabalho ao converter automaticamente arquivos, como transformar uma imagem em tabela, categorizar os dados e alimentá-los diretamente em pipelines de análise.
-
Acessibilidade Ampliada: Sistemas de IA se tornarão mais amigáveis e acessíveis, permitindo que até mesmo usuários não técnicos processem arquivos PNG de tabelas ou extraiam dados sem esforço.
A extração de tabelas com IA está pronta para redefinir o processamento de documentos, tornando a extração de dados mais rápida, inteligente e adaptável às necessidades em evolução da indústria. Empresas que adotarem essas soluções ganharão uma vantagem competitiva na gestão e utilização eficaz de seus dados.
AnyParser: Um Transformador na Análise de Documentos e Extração de Tabelas
AnyParser está na vanguarda da análise inteligente de documentos, oferecendo às empresas uma maneira eficiente e confiável de extrair dados até mesmo dos documentos mais complexos. Suas capacidades avançadas são especialmente evidentes quando se trata de extração de tabelas, garantindo captura de dados precisa e escalável para várias indústrias.
Principais Vantagens do AnyParser para Extração de Tabelas
-
Suporte Abrangente a Formatos: Seja lidando com PDFs, imagens ou outros tipos de arquivos, o AnyParser simplifica a captura de dados ao extrair informações tabulares com precisão, independentemente do formato.
-
Alta Precisão e Compreensão Contextual: Ao contrário das ferramentas tradicionais, o AnyParser preserva a estrutura, relações e contexto dos dados tabulares, entregando resultados prontos para análise e integração.
-
Eficiência Impulsionada por IA: Alimentado por Modelos de Visão-Linguagem (VLMs), o AnyParser se destaca em ambientes multilíngues e de múltiplos formatos, garantindo captura de dados perfeita em escala.
-
Fluxos de Trabalho Personalizáveis: A plataforma se adapta às suas necessidades únicas, seja você extraindo tabelas financeiras, registros de saúde ou dados de pesquisa.
Com o AnyParser, as empresas podem otimizar seus processos, minimizar erros e economizar tempo ao automatizar a tarefa complexa de extrair tabelas para captura de dados estruturados.
Conclusão
A extração de tabelas impulsionada por IA redefiniu a forma como as empresas processam e utilizam dados estruturados. Seja a tarefa de extrair tabelas de PDFs, processar imagens ou alcançar captura de dados precisa, ferramentas como o AnyParser tornam mais fácil do que nunca transformar documentos não estruturados em insights acionáveis. O AnyParser é sua solução confiável para simplificar a análise de documentos, oferecendo precisão e eficiência incomparáveis. Com sua capacidade de lidar com formatos e contextos diversos, o AnyParser capacita as organizações a automatizar seus fluxos de trabalho e desbloquear todo o potencial de seus dados.
Chamada à Ação
Por que esperar para experimentar o próximo nível de análise de documentos? Desbloqueie todo o potencial do AnyParser testando suas funcionalidades em um ambiente prático!
Clique no link abaixo para entrar no Sandbox, onde você pode explorar como ele simplifica:
- Captura precisa de dados de PDFs e imagens.
- Extração perfeita de tabelas para integração em ferramentas de análise.
- Desempenho confiável em conjuntos de dados complexos e grandes.
Experimente o AnyParser no Sandbox Agora
Não perca a chance de ver como o AnyParser pode revolucionar seus fluxos de trabalho. Teste hoje e descubra como a análise de documentos e a extração de tabelas podem ser descomplicadas!