No campo da gestão de dados, parsing envolve converter o conteúdo—como texto, imagens, tabelas e metadados—em um formato utilizável (por exemplo, texto simples, dados estruturados ou imagens) que pode ser processado ou analisado posteriormente. Isso é especialmente evidente no domínio da análise de PDF, onde entra o mundo do parsing, um processo crucial que transforma informações brutas em dados estruturados e utilizáveis. Este guia abrangente explora as complexidades da análise de PDF, elucidando sua definição, o espectro de dados que pode extrair, os obstáculos que enfrenta, suas aplicações multifacetadas e a cornucópia de métodos disponíveis para aproveitar seu pleno potencial. Você explorará vários métodos de parsing, com um foco particular na análise de PDF e como ferramentas como AnyParser se destacam na multidão.
Entendendo o Parser de PDF: O que é Parsing?
O que é parsing: processo meticuloso de captura de dados
Em sua essência, a análise de PDF refere-se ao processo de extrair e interpretar dados de arquivos PDF (Portable Document Format). Como os PDFs são projetados principalmente para exibição em vez de armazenamento de dados estruturados, o parsing envolve a conversão do conteúdo—como texto, imagens, tabelas e metadados—em um formato utilizável (por exemplo, texto simples, dados estruturados ou imagens) que pode ser processado ou analisado posteriormente. O parsing envolve uma análise de alto nível para identificar e recuperar elementos específicos dentro de um PDF, estendendo-se além de meros textos e imagens para abranger fontes, layouts, tabelas e metadados. Este processo não é meramente uma formalidade técnica, mas uma necessidade em indústrias tão diversas quanto finanças, direito, logística e saúde, onde a reutilização de informações é primordial.
Dados que podem ser Extraídos de PDFs
Os dados extraíveis de PDFs são variados e extensos, incluindo:
-
Parágrafos de Texto: Sequências de palavras e caracteres.
-
Campos de Dados Únicos: Elementos individuais como datas, números de rastreamento e nomes.
-
Dados Tabulares: Informações organizadas em tabelas e listas.
-
Imagens: Conteúdo gráfico incorporado dentro do PDF.
-
Elementos Avançados: Cabeçalhos, objetos, tabelas de referência cruzada, trailers e metadados, que exigem ferramentas de parsing mais sofisticadas.
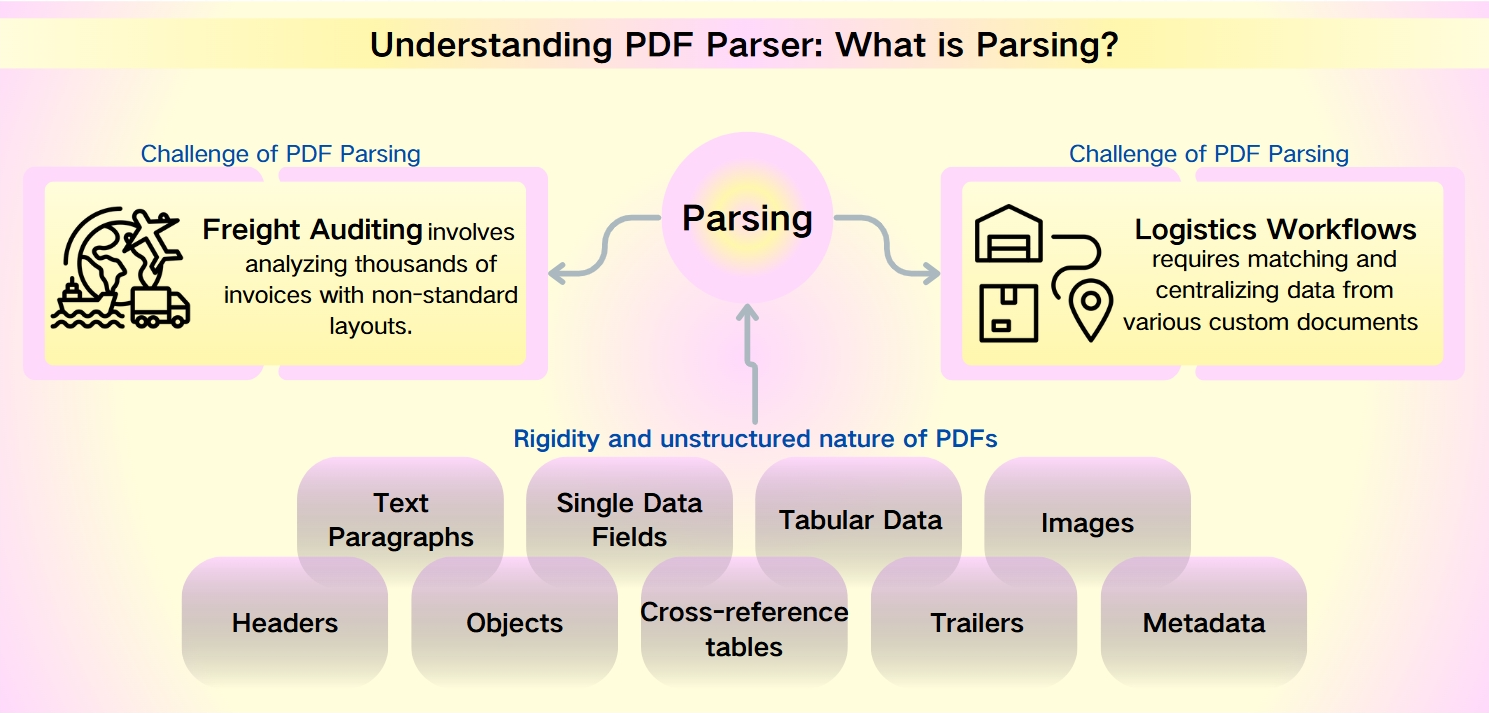
Desafios da Análise de PDF: natureza não estruturada dos metadados de PDF
Apesar da robustez dos PDFs—caracterizados por sua segurança, compatibilidade com dispositivos e tamanhos de arquivo compactos— a extração de dados deles representa um desafio formidável. A rigidez e a natureza não estruturada dos PDFs dificultam a análise rápida e a recuperação de informações. Isso é particularmente pronunciado em cenários como auditoria de frete e fluxos de trabalho logísticos, onde layouts não padronizados e conjuntos de dados volumosos aumentam a complexidade.
A Auditoria de Frete envolve a análise de milhares de faturas com layouts não padronizados. Os Fluxos de Trabalho Logísticos exigem a correspondência e centralização de dados de vários documentos personalizados, como listas de embalagem, faturas comerciais e conhecimentos de embarque.
A Importância do Parsing
O parsing desempenha um papel vital em vários campos, desde desenvolvimento web até captura de dados. Ele permite que as empresas extraíam insights valiosos de fontes de dados não estruturadas, como documentos PDF, arquivos HTML e dados XML. O parsing facilita:
-
Melhoria na tomada de decisões através de insights baseados em dados.
-
Aumento da precisão e consistência dos dados.
-
Processamento e análise de dados mais eficientes.
-
Recuperação e armazenamento de informações eficazes.
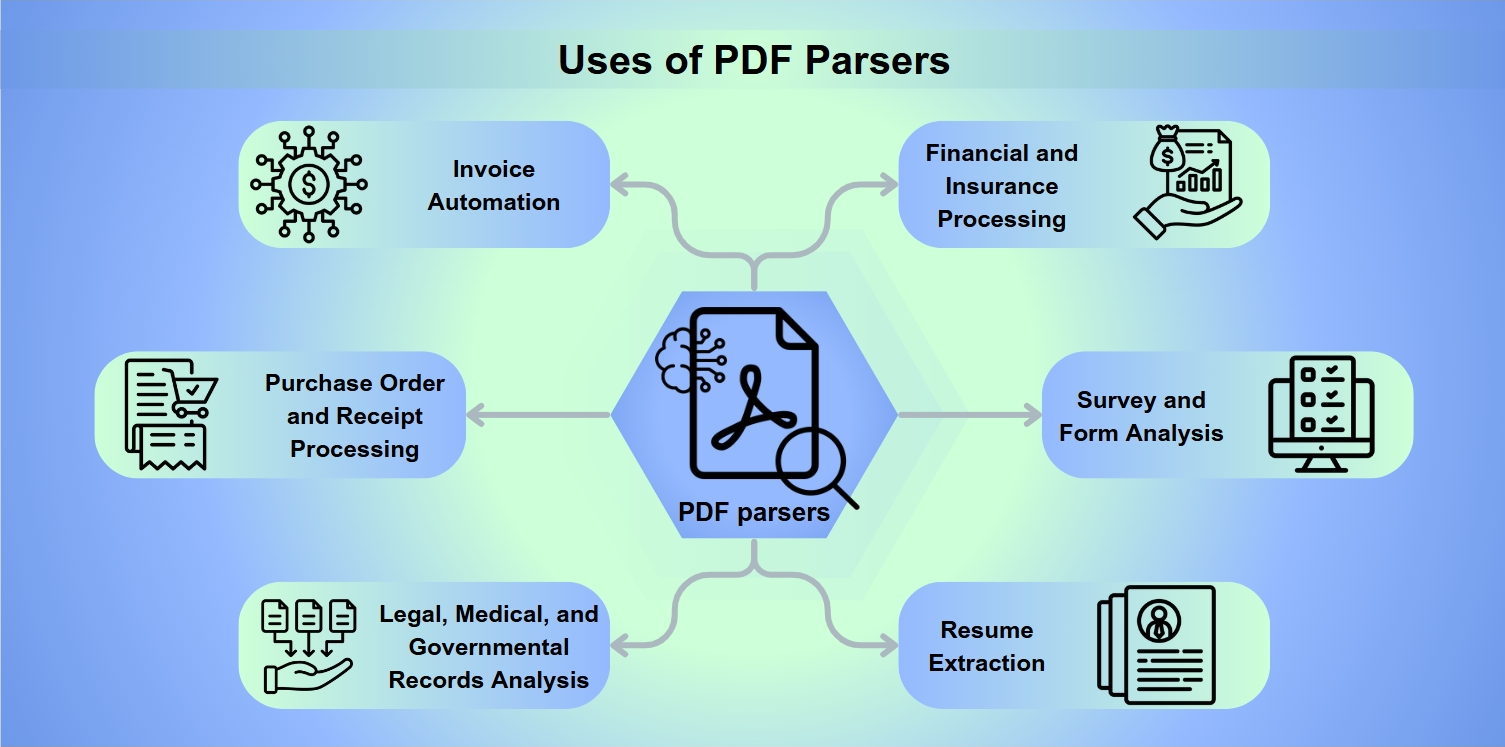
Usos dos Parsers de PDF
Os parsers de PDF são ferramentas indispensáveis em uma gama de aplicações, incluindo:
-
Automação de Faturas: Agilizando o processamento e pagamento de faturas.
-
Processamento de Pedidos de Compra e Recibos: Facilitando reembolsos e reembolsos.
-
Análise de Registros Legais, Médicos e Governamentais: Permitindo extração de dados aprofundada para análise.
-
Processamento Financeiro e de Seguros: Avaliando riscos e analisando balanços.
-
Análise de Pesquisas e Formulários: Coletando e interpretando respostas de formulários.
-
Extração de Currículos: Ajudando recrutadores na seleção de candidatos.
Comparação de Diferentes Métodos de Parsing
Os métodos de parsing de dados evoluíram significativamente ao longo do tempo. Abordagens tradicionais de captura de dados muitas vezes dependem de expressões regulares (regex) para extrair padrões específicos do texto. Embora poderosas, as regex podem se tornar complexas e difíceis de manter para tarefas de parsing intrincadas. Outra técnica comum é a manipulação de strings, que envolve dividir e processar texto com base em delimitadores ou caracteres específicos. Esses métodos, embora ainda úteis em certos cenários, podem ter dificuldades com formatos de dados não estruturados ou inconsistentes.
O cenário da análise de PDF é atendido por uma variedade de métodos, cada um com seus méritos e desvantagens únicos:
-
Conversores/Parsers de PDF Online: Como Zamzar e Smallpdf, oferecem conveniência e velocidade, mas são limitados em funcionalidade e potencialmente inseguros.
-
Adobe Acrobat: Preserva a estrutura e formatação, mas pode exigir ajustes manuais após a conversão.
-
Copiar e Colar: Oferece controle total, mas é trabalhoso e propenso a erros.
-
Plataformas Automatizadas: Tecnologias modernas de parsing como AnyParser aproveitam aprendizado de máquina e processamento de linguagem natural (NLP) para lidar com estruturas de dados mais complexas.
Essas abordagens impulsionadas por IA podem entender contexto e semântica, tornando-as particularmente eficazes para parsing de texto não estruturado ou documentos com formatos variados. Alguns parsers avançados utilizam modelos de aprendizado profundo para identificar e extrair informações relevantes com alta precisão, mesmo de layouts de documentos previamente não vistos.
Como Realizar a Análise de PDF: O Melhor Parser de PDF Gratuito para Extração de Metadados de PDF
Entendendo os Metadados de PDF
Os metadados de PDF contêm informações cruciais sobre um documento, incluindo seu título, autor, data de criação e palavras-chave. Extrair esses metadados de forma eficiente é essencial para organizar, pesquisar e gerenciar grandes coleções de arquivos PDF. Um parser de PDF robusto pode agilizar esse processo, economizando tempo e melhorando a produtividade do fluxo de trabalho.
Principais Recursos dos Melhores Parsers de PDF
Os melhores parsers de PDF gratuitos oferecem uma combinação de precisão, velocidade e versatilidade. Eles devem ser capazes de lidar com vários formatos de PDF, incluindo documentos digitalizados e aqueles com layouts complexos. Procure parsers que possam extrair não apenas metadados básicos, mas também campos personalizados e informações ocultas. Além disso, parsers de primeira linha frequentemente oferecem opções para extratores de dados de PDF para processamento em lote e integração com outros sistemas de software.
Recursos do AnyParser
AnyParser, desenvolvido pela CambioML, é particularmente notável devido à sua precisão, privacidade e configurabilidade. A capacidade do AnyParser de lidar com múltiplos formatos de arquivo, sua interface amigável e sua escalabilidade o tornam uma excelente escolha para empresas de todos os tamanhos. Além disso, sua API permite uma integração perfeita em fluxos de trabalho existentes, melhorando a eficiência geral da gestão de documentos. Aqui estão alguns dos principais recursos que fazem do AnyParser uma excelente escolha para análise de PDF:
-
Precisão: O AnyParser é projetado para extrair com precisão texto, números e símbolos, mantendo o layout e formato originais. Ele utiliza modelos de linguagem avançados para aprimorar a compreensão de documentos e a extração de informações, apresentando uma taxa de precisão até 2x maior em comparação com modelos tradicionais de OCR.
-
Privacidade: Suporta tanto parsing de dados em nuvem quanto local, garantindo que informações sensíveis permaneçam privadas e seguras.
-
Configurabilidade: Os usuários podem personalizar regras de extração e formatos de saída para atender a necessidades específicas.
-
Suporte a Múltiplas Fontes: O AnyParser suporta uma variedade de tipos de documentos, incluindo PDFs, imagens e gráficos.
-
Saída Estruturada: As informações extraídas podem ser convertidas em formatos estruturados como Markdown, Excel ou JSON, facilitando processamento e análise adicionais.
-
Opções de Implantação Baseadas em Nuvem: O SDK do AnyParser pode ser implantado na nuvem, em data centers ou de forma privada, oferecendo flexibilidade e escalabilidade.
-
Interface Amigável: A ferramenta oferece uma API simples que permite que tarefas complexas de parsing de documentos sejam realizadas com apenas algumas linhas de código.
-
Alto Desempenho: Algoritmos otimizados garantem processamento rápido de um grande número de documentos, 5X mais rápido do que LLMs generalizados como o GPT-4.
-
Suporte da Comunidade: Como um projeto de código aberto, o AnyParser se beneficia de uma comunidade ativa e acolhe contribuições.
-
Cota de Uso Gratuita: O AnyParser oferece uma cota de uso gratuita com cada conta, permitindo que os usuários testem as capacidades da ferramenta antes de se comprometerem com um plano pago.
-
Feedback dos Clientes: Os usuários elogiaram o AnyParser por sua alta precisão, preservação da privacidade e eficiência na extração de dados, com estudos de caso mostrando economias significativas de tempo e melhoria na qualidade dos dados.
Essas vantagens tornam o AnyParser um valioso extrator de dados de PDF para análise de documentos e extração de informações, especialmente para usuários empresariais que exigem alta precisão e segurança. Com os avanços tecnológicos contínuos e o engajamento ativo da comunidade, o AnyParser está preparado para desempenhar um papel cada vez mais vital no campo da análise de documentos e extração de informações.
Explicação Técnica dos Parsers de PDF
A análise de PDF compartilha fundamentos conceituais com scraping web, mas carece da hierarquia estruturada do HTML. Enquanto documentos web são analisados através de tags HTML acessíveis, PDFs apresentam um array plano de caracteres e pixels, exigindo algoritmos e bibliotecas mais sofisticados para extração de dados.
Parser de PDF vs Parser de PDF em Python: Principais Diferenças
Um parser de PDF é frequentemente uma ferramenta autônoma como um extrator de dados de PDF ou biblioteca projetada especificamente para extrair dados de arquivos PDF. Esses parsers geralmente oferecem interfaces amigáveis e requerem conhecimento mínimo de programação. Por outro lado, parsers de PDF em Python são módulos ou bibliotecas que se integram a scripts Python, oferecendo mais flexibilidade, mas exigindo expertise em programação.
Os desenvolvedores podem ajustar o processo de parsing, implementar análises de texto avançadas e integrar perfeitamente a extração de dados de PDF em aplicações Python mais amplas. Parsers de PDF, embora mais limitados em personalização do que parsers de PDF em Python, frequentemente oferecem recursos pré-construídos para casos de uso comuns, tornando-os ideais para usuários que precisam de resultados rápidos sem extensa programação.
Vantagens do AnyParser com VLM para Análise de Dados
-
Alta Precisão: Os VLMs do AnyParser garantem que a extração de dados mantenha alta fidelidade, mesmo com layouts de documentos complexos.
-
Velocidade: Ele lidera em velocidade de conversão, aumentando a produtividade ao reduzir o tempo necessário para processar documentos.
-
Amigável ao Usuário: O AnyParser oferece uma interface direta, tornando-o acessível para usuários de todos os níveis.
-
Versatilidade: Além de PDFs, o AnyParser serve como um poderoso conversor de imagem para Excel, suportando diversos tipos de documentos.
Conclusão
A análise de PDF é mais do que um processo técnico; é uma porta de entrada para transformar a forma como as empresas lidam com dados. Apesar dos desafios, a evolução das soluções de software tornou-a mais acessível do que nunca. Seja lidando com processamento de faturas ou análise de dados complexos, escolher o parser de PDF certo é essencial. Trata-se de encontrar a ferramenta que oferece o equilíbrio perfeito entre precisão, segurança e eficiência para capacitar suas iniciativas orientadas por dados.
Comece Seu Teste Gratuito Hoje
Pronto para revolucionar seu processamento de documentos? Experimente o AnyParser GRÁTIS, sem necessidade de cartão de crédito, em https://www.cambioml.com/sandbox. O teste gratuito permite que você processe até 10 páginas por documento, com um tamanho máximo de arquivo de 10MB. Experimente em primeira mão como o parser de PDF do AnyParser pode transformar sua abordagem em dados não estruturados e extração de documentos. Não perca esta oportunidade de aprimorar suas capacidades de análise de dados e agilizar seu fluxo de trabalho com tecnologia de IA de ponta.