 Métricas de Avaliação dos Ragas
Métricas de Avaliação dos Ragas
No cenário atual orientado por dados, indústrias como serviços financeiros dependem fortemente da extração precisa e eficiente de informações de documentos, especialmente aqueles que contêm texto não estruturado e dados estruturados, como tabelas e gráficos. Modelos tradicionais de Reconhecimento Óptico de Caracteres (OCR), apesar de seu uso generalizado, muitas vezes falham em lidar com formatos de documentos complexos, levando a um desempenho subótimo em aplicações avançadas de IA. Reconhecendo essa lacuna, a CambioML e a Epsilla introduziram um sistema de recuperação de conhecimento de ponta que promete melhorar significativamente a precisão e a recuperação em tarefas de extração de dados.
Introdução: Superando as Limitações do OCR
Modelos baseados em OCR, embora eficazes na detecção de texto, têm dificuldade em extrair informações de layout e em puxar dados com precisão de tabelas e gráficos. Essas limitações se tornam particularmente evidentes em indústrias onde a precisão é fundamental, como finanças e saúde. Para abordar esses desafios, a CambioML e a Epsilla desenvolveram uma abordagem inovadora que integra modelos de extração de tabelas de última geração com técnicas de Geração Aumentada por Recuperação (RAG). Este novo sistema alcança até 2x de precisão e 2,5x de recuperação em comparação com sistemas RAG convencionais, estabelecendo um novo padrão para perguntas e respostas sobre documentos.
AnyParser: Revolucionando a Extração de Tabelas
No cerne dessa inovação está o AnyParser, um modelo alimentado por avançados modelos de linguagem visual (VLMs) que se destaca na extração de informações de diversas fontes de dados. Ao contrário dos modelos tradicionais que dependem fortemente do OCR, o AnyParser utiliza uma combinação de codificadores visuais e baseados em texto para capturar até os menores detalhes dos documentos, garantindo que nenhum dado crítico seja perdido. Essa abordagem é particularmente benéfica na extração de dados de alta resolução de documentos financeiros e médicos, onde a precisão é crítica.
Epsilla: Uma Plataforma RAG Flexível
Complementando o AnyParser está a Epsilla, uma plataforma RAG-as-a-Service sem código projetada para otimizar diversos pipelines RAG. A Epsilla aprimora o processo de recuperação de conhecimento por meio de técnicas avançadas de fragmentação, indexação e refinamento de consultas. Ao integrar métodos de busca baseados em palavras-chave e semântica, a Epsilla oferece resultados altamente precisos e contextualmente relevantes, tornando-se uma solução ideal para aplicações de modelos de linguagem de grande escala (LLM).
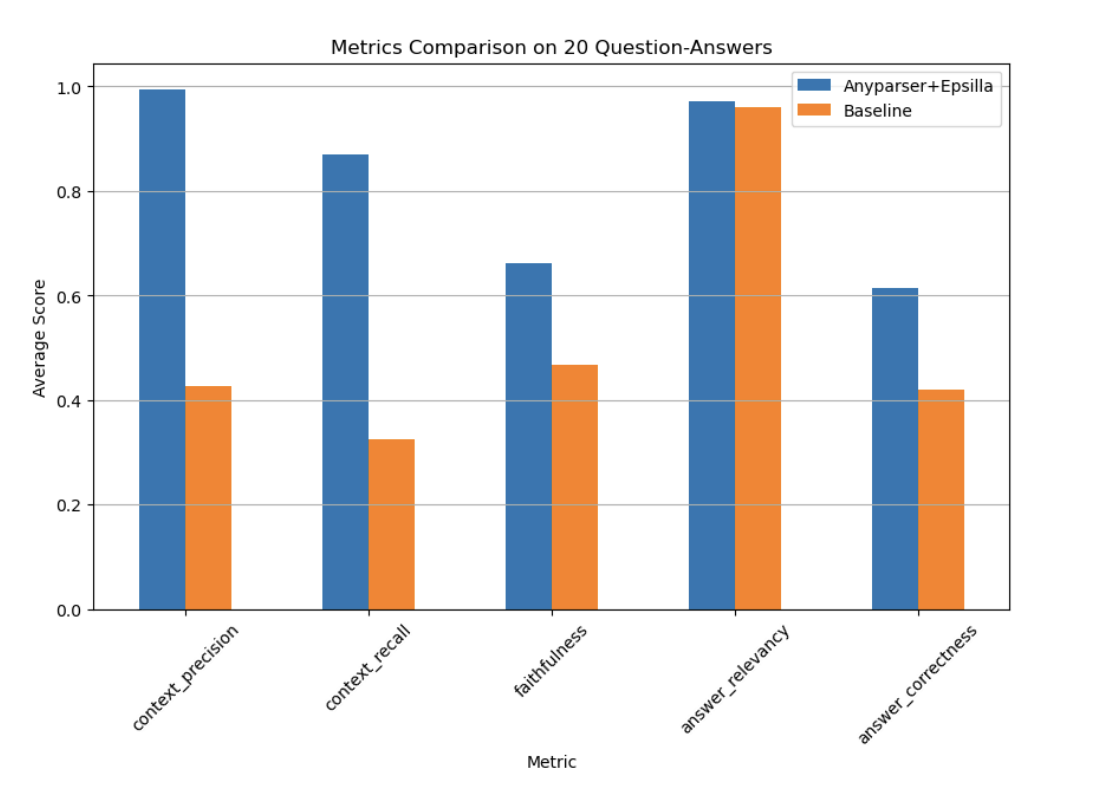
Experimento e Avaliação: Impacto no Mundo Real
Métricas de Avaliação dos Ragas
Para validar a eficácia do AnyParser e da Epsilla, o sistema foi testado em documentos financeiros 10-K de empresas como Apple e Meta. Os resultados foram impressionantes, com o sistema demonstrando um desempenho significativamente superior em todas as principais métricas de avaliação, incluindo precisão contextual, recuperação, fidelidade e correção das respostas. Em alguns casos, o sistema superou os sistemas RAG tradicionais em até 2,7x, destacando sua superioridade em lidar com tarefas complexas de extração de dados.
Casos de Uso Comuns e Principais Benefícios
-
Precisão: Alta precisão na conversão de dados estruturados e não estruturados em formatos utilizáveis.
-
Privacidade: A capacidade de implantar o sistema dentro do data center do cliente garante total segurança dos dados.
-
Escalabilidade: Processamento rápido de grandes volumes de documentos, permitindo uma tomada de decisão mais ágil.
Conclusão: Uma Nova Era na Recuperação de Conhecimento
A introdução do AnyParser e da Epsilla marca um avanço significativo na tecnologia de recuperação de conhecimento. Ao combinar modelos de extração avançados com uma infraestrutura RAG robusta, essa solução integrada não apenas melhora a precisão e a eficiência, mas também oferece a flexibilidade e a privacidade que as empresas modernas exigem. À medida que a tecnologia continua a evoluir, as aplicações e benefícios deste sistema são vastos e promissores, tornando-o um divisor de águas para indústrias que dependem da extração precisa de dados.
Para o whitepaper completo e detalhado, confira este link.