Converter PDFs complexos em Markdown pode ser desafiador. Existem muitas bibliotecas de código aberto disponíveis para extrair texto de PDFs, mas quando se trata de PDFs que contêm elementos complexos, como tabelas e gráficos, os resultados muitas vezes ficam aquém. Modelos de linguagem de grande porte, como GPT ou Claude, podem lidar com essas tarefas, mas tendem a ser lentos e, às vezes, produzem saídas imprecisas. Ferramentas tradicionais de OCR, embora eficazes para documentos mais simples, frequentemente têm dificuldades em manter a estrutura exata e o significado semântico do conteúdo original. Por outro lado, modelos de linguagem visual às vezes alucinam, levando a resultados de análise errôneos. Este blog explicará o que significa analisar e detalhará os resultados de uma análise comparativa de vários modelos usando várias métricas.
O que significa analisar?
No contexto da análise de PDF, "analisar" refere-se ao processo de extração de dados específicos de um arquivo PDF usando software especializado conhecido como analisador de PDF. Um analisador de PDF analisa o conteúdo de um documento PDF e identifica elementos como texto, imagens, fontes, layouts e até mesmo metadados. Os dados extraídos podem ser organizados e exportados para diferentes formatos, como XML, JSON ou Excel/CSV, que podem ser usados para vários propósitos, como análise de dados, manutenção de registros ou automação de fluxos de trabalho.
Entender o que significa analisar é essencial para avaliar a eficácia de uma solução de análise, especialmente ao comparar diferentes ferramentas de conversão de PDF para Markdown, já que o analisador de PDF envolve mais do que apenas a extração simples de texto — requer o reconhecimento e a manutenção da estrutura semântica do documento.
Como medimos a qualidade dessas soluções de análise?
Definimos uma série de métricas em nível de palavra para avaliar o desempenho de diferentes modelos, focando em fatores-chave como:
-
Precisão, Recall e F-Measure: Avaliando a qualidade e a completude da análise.
-
Score BLEU e ANLS: Útil para avaliar a linguagem e a estrutura do layout.
-
Distância de Edição, Divergência de Jensen-Shannon e Distância de Jaccard: Métricas específicas para o domínio de OCR, particularmente úteis para entender a exatidão da reprodução do conteúdo.
Nosso modelo de linguagem visual, AnyParser, demonstra desempenho excepcional, combinando velocidade e precisão, especialmente em layouts complexos com tabelas e elementos semânticos. AnyParser supera outras soluções, oferecendo uma melhoria de 20x em velocidade em relação a modelos como GPT/Claude, enquanto alcança maior precisão.
Um extenso resultado de comparação contra modelos de análise líderes
Objeto estatístico
Para realmente mostrar as capacidades do AnyParser, realizamos uma comparação extensa contra modelos de análise líderes na indústria e modelos de linguagem de grande porte (LLMs) bem conhecidos. Nossa avaliação incluiu:
1. Modelos de Linguagem de Grande Porte
- AnyParser
- GPT-4o da OpenAI
- Gemini 1.5 Pro do Google
- Claude 3.5 Sonnet da Anthropic
2. Serviços Baseados em OCR
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Apresentação e análise dos resultados
Experimento 1
Primeiro, realizamos uma série de comparações rigorosas do desempenho de diferentes modelos de IA de documentos em mais de 5 métricas abaixo: BLEU, Precisão e Recall, F-Measure e ANLS. Você pode encontrar a definição matemática dessas métricas no apêndice.
Os modelos comparados são: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl e Azure-DocAl.
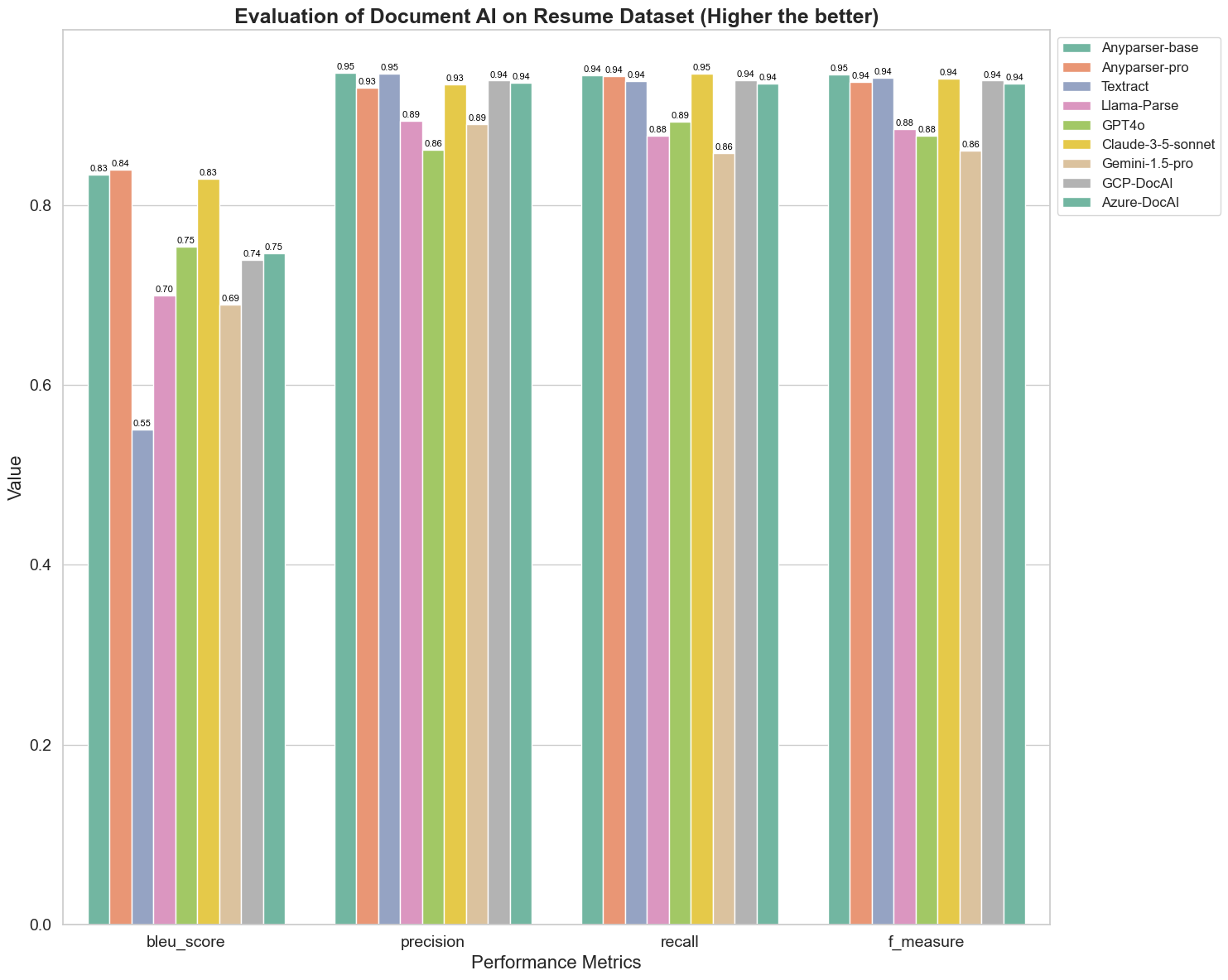
O BLEU é usado como uma avaliação da qualidade da interpretação bilíngue para testar a qualidade dos modelos no processamento de enunciados. Ao comparar os resultados desses modelos de análise sob o método de avaliação BLEU, descobrimos que: os scores de AnyParser-base e AnyParser-pro são significativamente mais altos do que os scores dos outros modelos, o Amazon Textract obteve a pontuação mais baixa, e os resultados dos outros modelos estão em um nível médio relativamente.
A precisão de reconhecimento é geralmente representada pela precisão e recall, onde a precisão representa a porcentagem de resultados realmente corretos entre os resultados julgados como corretos pelo modelo, e o recall representa a porcentagem de resultados realmente corretos julgados pelo modelo entre todos os resultados realmente corretos. Ao comparar a precisão e o recall desses modelos de análise, descobrimos que: exceto por Llama-Parse, GPT4o e Gemini-1.5-pro, todos os outros modelos estão em um nível alto. Dentre eles, AnyParser e Amazon Textract se destacam mais em precisão, e AnyParser-base e AnyParser-pro se destacam mais em recall. A pontuação mais alta do modelo em Precisão indica que o modelo gera mais informações corretas nos resultados produzidos, e a pontuação mais alta em recall indica que o modelo é mais capaz de obter informações corretas da amostra. Os resultados das pontuações mostram que AnyParser tem uma clara vantagem em termos de precisão de reconhecimento para extrair texto de PDFs.
O F-Measure é um índice de avaliação abrangente da precisão e recall em relação a esses dois indicadores. Ao comparar as pontuações desses modelos de análise sob o F-Measure, podemos ver de forma mais intuitiva que os cinco modelos, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI e Azure-DocAI, têm uma melhor força em termos de precisão de reconhecimento em comparação com outros modelos. Podemos ver de forma mais intuitiva que os cinco modelos têm mais força em precisão de reconhecimento do que os outros modelos, e AnyParser tem a maior pontuação sob o F-Measure, o que ilustra ainda mais a óbvia vantagem do AnyParser em precisão de reconhecimento para extrair texto de PDFs.
O ANLS, como um índice de avaliação comumente usado ao medir a precisão e a similaridade entre o texto original e o texto alvo no nível de caracteres, também é muito informativo para medir o nível de análise dos modelos. As pontuações mais altas de AnyParser-base, AnyParser-pro e Azure-DocAI refletem o nível de análise mais alto desses modelos em comparação com os outros modelos.
No geral, AnyParser-base e AnyParser-pro superam os outros modelos.
Experimento 2
Também comparamos o desempenho de diferentes modelos de IA de documentos em três métricas diferentes: Distância de Edição, Divergência de Jensen-Shannon e Distância de Jaccard. As métricas são usadas para medir a similaridade entre a saída dos modelos e um documento de referência. Valores mais baixos indicam melhor desempenho.
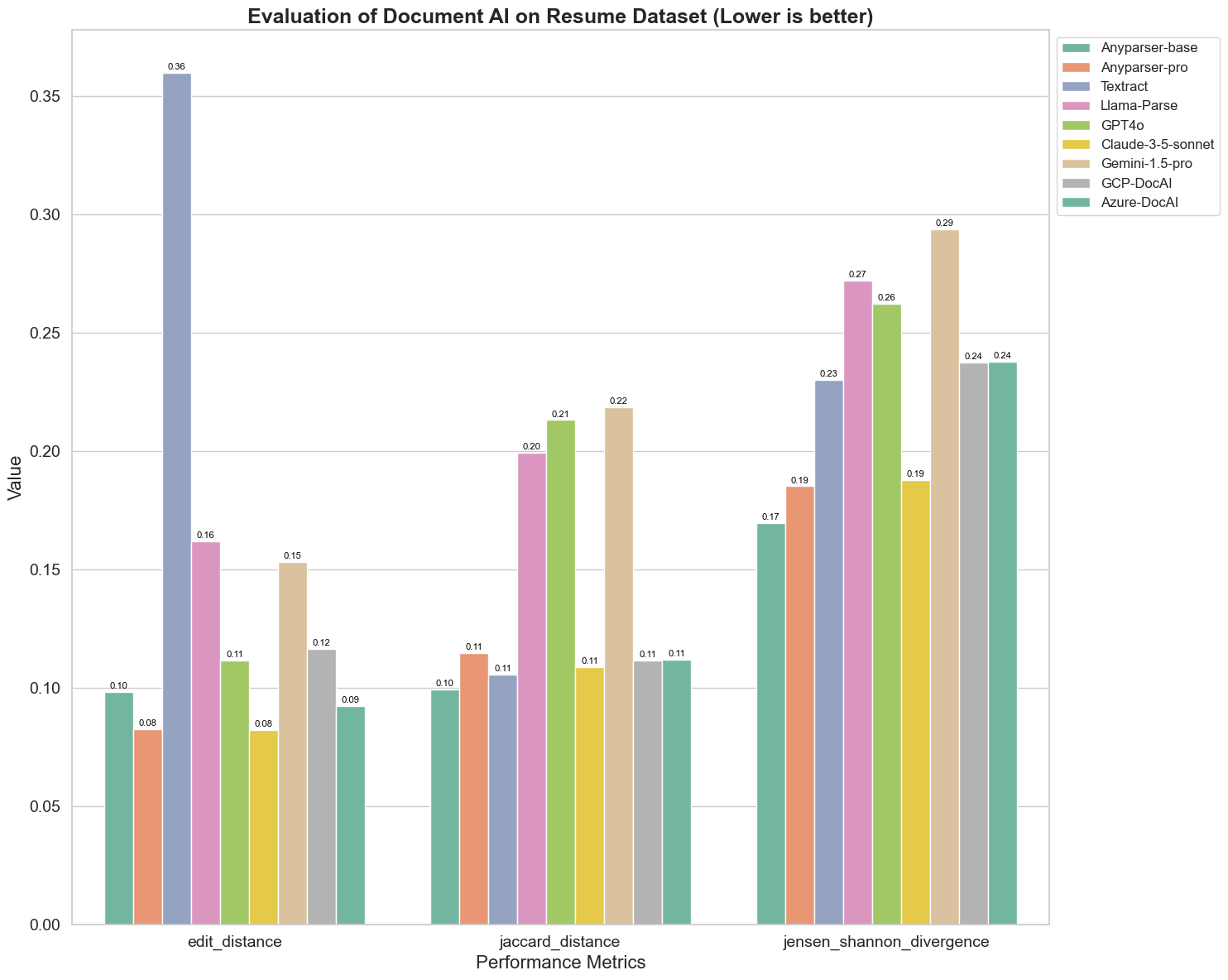
Aqui estão algumas observações-chave do gráfico:
-
Distância de Edição: Os modelos AnyParser-base e AnyParser-pro apresentam o melhor desempenho com a menor distância de edição, sugerindo que suas saídas estavam mais próximas do documento de referência.
-
Divergência de Jensen-Shannon: Os modelos AnyParser-base e AnyParser-pro têm a menor divergência, implicando que suas saídas são as mais semelhantes ao documento de referência em termos de distribuição de palavras.
-
Distância de Jaccard: Além de Llama-parse, GPT4O, Gemini-1.5, todos os outros modelos apresentam um desempenho decente com a menor distância de Jaccard, indicando que suas saídas têm a maior sobreposição com o documento de referência em termos do conjunto de palavras usadas.
Conclusão
No geral, nossos testes rigorosos sugerem que AnyParser-base e AnyParser-pro geralmente apresentam um bom desempenho em várias métricas, indicando seu potencial para processamento preciso de documentos. A partir dos gráficos, podemos ver que modelos tradicionais de OCR, como o famoso Amazon Textract, pontuam muito abaixo dos modelos de linguagem visual. No entanto, o desempenho de diferentes modelos varia dependendo da métrica utilizada, destacando a importância de considerar múltiplos critérios de avaliação ao comparar modelos de IA.
Apresentando Nosso Pipeline de Avaliação de Código Aberto
Para simplificar as avaliações, criamos um pipeline de avaliação que fornece um método padrão da indústria para comparar modelos de análise. Em nosso exemplo, demonstramos seu uso no domínio de RH, onde a análise de currículos é comum. Construímos um conjunto de dados sintético diversificado de 128 currículos, gerados usando arquivos de imagem-Markdown emparelhados. Usando GPT-4, geramos conteúdo HTML, renderizamos em imagens e usamos o texto extraído como verdade de referência para comparação.
E aqui está a melhor parte: tornamos esse framework de avaliação de código aberto no GitHub! Seja você um desenvolvedor ou um usuário empresarial, nosso pipeline permite que você avalie e compare a qualidade da análise de diferentes modelos em seu próprio conjunto de dados.
Encontre o guia de início rápido no repositório do Github e veja como diferentes modelos de análise se comparam entre si. Acreditamos que, ao mostrar a força do nosso modelo de forma aberta, podemos atrair mais usuários que desejam capacidades de análise confiáveis, rápidas e precisas.
Apêndice - Métricas
1. Precisão
A precisão mede a exatidão do conteúdo analisado, mostrando quantos dos elementos recuperados estavam corretos. Na análise, é a proporção de palavras corretamente extraídas em relação a todas as palavras extraídas.
Precisão = Verdadeiros Positivos (TP) / (Verdadeiros Positivos (TP) + Falsos Positivos (FP))
- Verdadeiros Positivos (TP): Palavras corretamente identificadas pelo analisador.
- Falsos Positivos (FP): Palavras incorretamente identificadas pelo analisador.
2. Recall
O recall indica a completude da análise, ou quantas palavras relevantes do documento original foram recuperadas.
Recall = Verdadeiros Positivos (TP) / (Verdadeiros Positivos (TP) + Falsos Negativos (FN))
- Falsos Negativos (FN): Palavras no documento original que foram perdidas pelo analisador.
3. F-Measure (Score F1)
O Score F1 é a média harmônica da Precisão e do Recall, equilibrando ambas as métricas para fornecer uma medida geral da qualidade da análise.
Score F1 = 2 × (Precisão × Recall) / (Precisão + Recall)
4. Score BLEU (Bilingual Evaluation Understudy)
O score BLEU mede a similaridade entre o conteúdo analisado e o texto original, colocando ênfase especial na ordem das palavras. É particularmente útil para avaliar a consistência de linguagem e estrutura em documentos analisados, pois penaliza saídas que diferem na sequência do original.
5. ANLS (Average Normalized Levenshtein Similarity)
O ANLS quantifica a similaridade entre o conteúdo analisado e o original, usando distância de edição normalizada. É calculado pela média da Similaridade de Levenshtein Normalizada (NLS) para cada par de palavras nos textos analisados e de referência. A NLS é computada da seguinte forma:
NLS = 1 - (Distância de Levenshtein (LD)(palavra analisada, palavra original)) / max(Comprimento da palavra analisada, Comprimento da palavra original)
Então, o ANLS é a média de NLS em todos os pares de palavras:
ANLS = (1/N) × Σ(NLS_i) para i=1 até N
6. Distância de Edição
A Distância de Edição calcula o número de operações em nível de palavra (inserções, deleções, substituições) necessárias para converter o texto analisado no original.
7. Divergência de Jensen-Shannon
A Divergência de Jensen-Shannon mede a similaridade entre distribuições de probabilidade discretas das contagens de palavras analisadas e originais, destacando diferenças na frequência das palavras.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
onde M = (1/2)(P + Q), e KL(P || Q) é a divergência de Kullback-Leibler
8. Distância de Jaccard
A Distância de Jaccard mede a dessemelhança entre conjuntos de palavras no conteúdo analisado e original, útil para avaliar a sobreposição de palavras.
Distância de Jaccard = 1 - |A ∩ B| / |A ∪ B|
onde |A ∩ B| é o número de elementos comuns entre A e B,
e |A ∪ B| é o número total de elementos únicos em ambos os conjuntos.