Modelos de Linguagem Visual (VLMs) estão revolucionando o campo da análise de documentos, abordando muitas das limitações inerentes aos sistemas tradicionais de Reconhecimento Óptico de Caracteres (OCR). Embora o OCR tenha sido uma tecnologia fundamental para a digitalização de texto a partir de imagens, enfrenta desafios significativos em cenários complexos. Esses desafios incluem problemas de precisão com imagens de baixa qualidade, compreensão contextual limitada, dificuldades com idiomas mistos e incapacidade de interpretar elementos visuais. Os VLMs oferecem uma solução promissora ao combinar visão computacional avançada com capacidades de processamento de linguagem natural. Este artigo explora como os VLMs estão superando as deficiências do OCR, proporcionando soluções mais robustas e versáteis para o processamento de documentos na era digital.
O que é OCR? Quais são os processos de OCR na análise de documentos?
O Reconhecimento Óptico de Caracteres (OCR) é uma tecnologia que permite a conversão de diferentes tipos de documentos, como documentos em papel digitalizados, arquivos PDF ou imagens capturadas por uma câmera digital, em dados editáveis e pesquisáveis. Este processo é crucial no processamento de documentos e na extração de dados de PDF, permitindo que máquinas reconheçam caracteres de texto impressos ou manuscritos dentro de imagens digitais.
O Processo de OCR
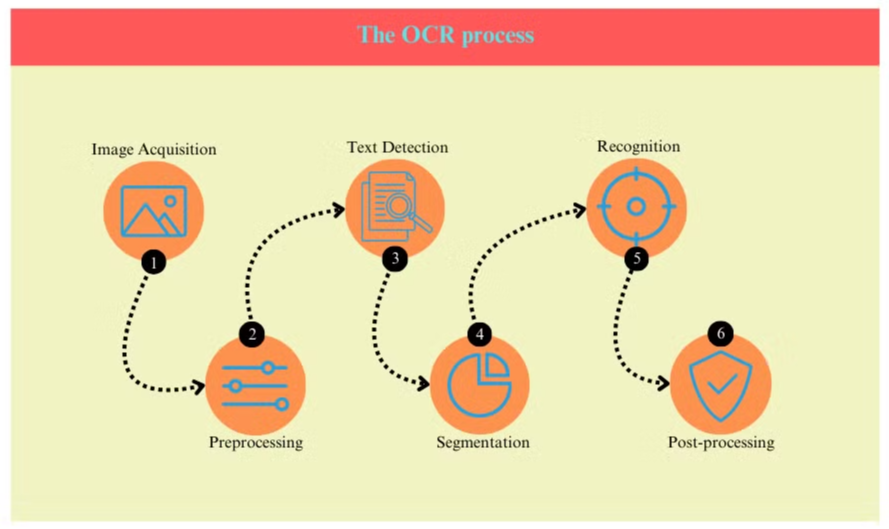
O processo de OCR geralmente envolve várias etapas:
- Aquisição de Imagem: O documento é digitalizado ou fotografado para criar uma imagem digital.
- Pré-processamento: A imagem é limpa, removendo ruídos e ajustando brilho e contraste.
- Detecção de Texto: O sistema identifica áreas contendo texto dentro da imagem.
- Segmentação de Caracteres: Caracteres individuais são isolados dentro das áreas de texto.
- Reconhecimento de Caracteres: Cada caractere é analisado e comparado a um banco de dados de caracteres conhecidos.
- Pós-processamento: O texto reconhecido é verificado quanto a erros usando informações linguísticas e contextuais.
Embora o OCR tenha melhorado significativamente as capacidades de análise de documentos, ainda enfrenta limitações ao lidar com layouts complexos, imagens de baixa qualidade e fontes variadas. É aqui que tecnologias avançadas como os modelos de linguagem visual estão entrando para melhorar a precisão e a compreensão na extração de dados de imagens e documentos.
As Limitações da Tecnologia Tradicional de OCR
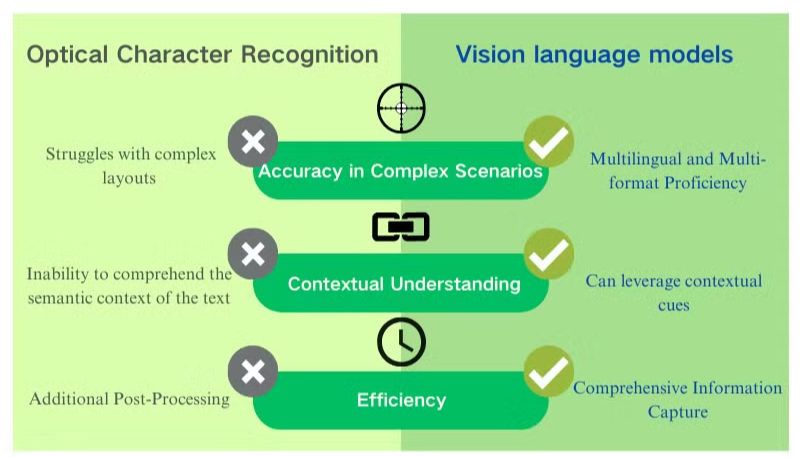
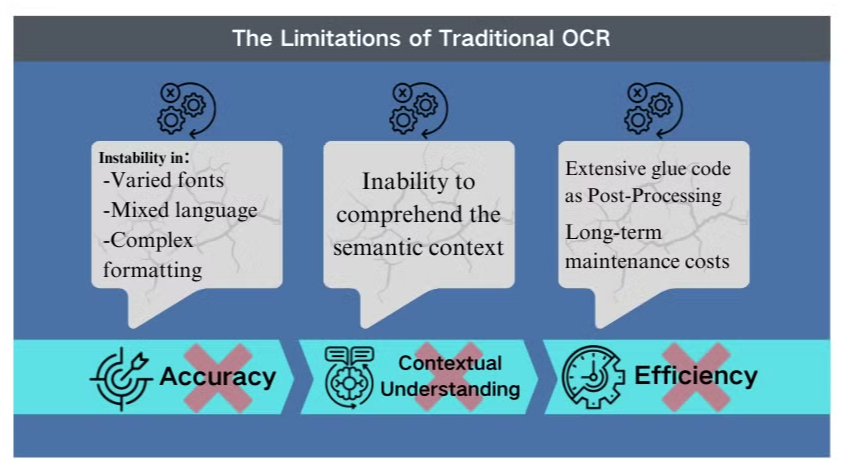
Desafios de Precisão em Cenários Complexos
A tecnologia tradicional de reconhecimento óptico de caracteres (OCR), embora benéfica para a extração básica de texto, enfrenta obstáculos significativos quando confrontada com layouts de documentos intrincados ou imagens de baixa qualidade. Esses sistemas frequentemente lutam para manter a precisão ao processar documentos com fontes variadas, idiomas mistos ou formatação complexa. Por exemplo, o OCR pode falhar ao tentar extrair dados de apresentações ricas em imagens ou PDFs densamente formatados.
Falta de Compreensão Contextual
Uma das limitações mais evidentes do OCR convencional é sua incapacidade de compreender o contexto semântico do texto que processa. Essa deficiência se torna particularmente evidente em cenários que exigem interpretação sutil, como contratos legais ou relatórios médicos. O foco do OCR no reconhecimento de caracteres, sem consciência contextual, pode levar a interpretações críticas equivocadas, especialmente ao lidar com caracteres ambíguos ou terminologia específica de setores.
Ineficiências no Pós-processamento
As limitações do OCR frequentemente exigem extensos esforços de pós-processamento. Essa etapa adicional pode aumentar significativamente o tempo e os recursos necessários para o processamento de documentos. Além disso, os sistemas tradicionais de OCR geralmente ficam aquém quando encarregados de extrair informações de gráficos, tabelas ou outros elementos não textuais, complicando ainda mais o processo de extração de documentos. Essas ineficiências ressaltam a necessidade de soluções mais avançadas, como os modelos de linguagem visual, que oferecem uma abordagem mais abrangente para a análise de documentos e extração de dados.
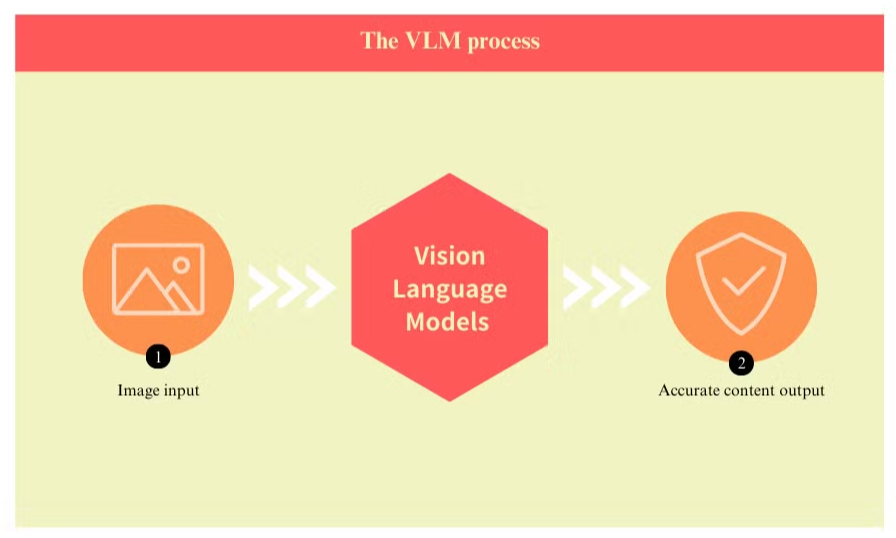
O que são Modelos de Linguagem Visual e como Melhoram o OCR
Os modelos de linguagem visual representam um avanço significativo na tecnologia de processamento de documentos, abordando muitas das limitações inerentes aos sistemas tradicionais de reconhecimento óptico de caracteres (OCR). Esses modelos avançados combinam visão computacional com processamento de linguagem natural para compreender simultaneamente os elementos visuais e textuais dos documentos.
Precisão Aprimorada e Compreensão Contextual
Ao contrário do OCR, que enfrenta dificuldades com imagens de baixa qualidade e layouts complexos, os modelos de linguagem visual se destacam na interpretação de diversos formatos de documentos. Eles podem extrair dados com precisão de imagens, PDFs e outros conteúdos visuais, mesmo quando confrontados com cenários desafiadores. Essa precisão aprimorada decorre de sua capacidade de considerar todo o contexto de um documento, em vez de se concentrar apenas em caracteres ou palavras individuais.
Extração Abrangente de Dados
Os modelos de linguagem visual vão além do simples reconhecimento de texto, oferecendo capacidades abrangentes de extração de dados de PDF. Eles podem identificar e interpretar tabelas, gráficos e figuras dentro de documentos, preservando a integridade de layouts complexos. Essa abordagem holística para a análise de documentos permite uma recuperação de informações mais sutil e completa, aumentando significativamente a utilidade dos dados extraídos para aplicações subsequentes.
Proficiência Multilíngue e Multi-formato
Uma das principais vantagens dos modelos de linguagem visual é sua flexibilidade em lidar com múltiplos idiomas e formatos de documentos. Ao contrário dos sistemas de OCR que podem ter dificuldades com scripts não latinos ou documentos em idiomas mistos, esses modelos podem processar conteúdo de forma contínua em várias línguas e scripts, tornando-os inestimáveis para necessidades globais de processamento de documentos.
Principais Benefícios dos Modelos de Linguagem Visual para Compreensão de Documentos
Os modelos de linguagem visual oferecem vantagens significativas em relação ao OCR tradicional para processamento de documentos e extração de dados. Esses sistemas impulsionados por IA combinam compreensão visual e textual para fornecer resultados superiores em vários tipos de documentos.
Precisão Aprimorada e Compreensão Contextual
Os modelos de linguagem visual se destacam em lidar com layouts complexos, imagens de baixa qualidade e fontes diversas. Ao contrário do OCR, que enfrenta dificuldades com caracteres ambíguos, esses modelos aproveitam pistas contextuais para interpretar o texto com precisão. Essa capacidade melhora dramaticamente a precisão da extração de dados de PDF, especialmente para documentos com estruturas intrincadas ou qualidade de imagem deficiente.
Captura Abrangente de Informações
Enquanto o OCR se concentra exclusivamente no reconhecimento de texto, os modelos de linguagem visual podem extrair dados de imagens, tabelas e gráficos. Essa abordagem holística garante que informações críticas não sejam negligenciadas durante a fase de processamento de documentos. Ao capturar tanto elementos textuais quanto visuais, esses modelos fornecem uma compreensão mais completa do conteúdo dos documentos.
Proficiência Multilíngue e Multi-formato
Os modelos de linguagem visual demonstram notável flexibilidade no processamento de documentos em várias línguas e formatos. Eles podem lidar de forma contínua com documentos em idiomas mistos e scripts não latinos, superando uma limitação significativa dos sistemas tradicionais de OCR. Essa versatilidade os torna inestimáveis para empresas globais que lidam com diversos tipos de documentos e idiomas.
Aplicações do Mundo Real Possibilitadas por VLM que o OCR Falhou
Os modelos de linguagem visual estão revolucionando o processamento de documentos em finanças, recursos humanos e outros setores, abordando limitações críticas dos sistemas tradicionais de OCR. Esses modelos avançados de IA estão transformando os esforços de transformação digital em várias indústrias, oferecendo precisão superior e compreensão contextual.
Revolucionando o Processamento de Documentos Financeiros
Os modelos de linguagem visual estão transformando o processamento de documentos em finanças, superando limitações do OCR tradicional. Esses modelos avançados se destacam na extração de dados de demonstrações financeiras complexas, faturas e recibos com layouts intrincados. Ao contrário do OCR, eles podem entender o contexto, interpretando com precisão caracteres ambíguos (por exemplo, diferenciando entre um zero e a letra O) e idiomas mistos frequentemente presentes em documentos financeiros globais.
Melhorando as Operações de RH por meio de Análise Inteligente de Documentos
No setor de RH, os modelos de linguagem visual estão se mostrando inestimáveis para a extração de dados de PDF de currículos, registros de funcionários e avaliações de desempenho. Esses modelos podem compreender a estrutura semântica dos documentos, permitindo uma recuperação e análise de informações mais precisas. Essa capacidade agiliza significativamente os processos de contratação e gestão de dados de funcionários, tarefas em que o OCR frequentemente enfrenta dificuldades com formatos variados e anotações manuscritas.
Melhorando a Conformidade e Gestão de Risco
Os modelos de linguagem visual são particularmente eficazes em conformidade e gestão de risco tanto em finanças quanto em RH. Eles podem extrair e interpretar informações críticas de documentos regulatórios, contratos e políticas com maior precisão do que o OCR. Essa capacidade aprimorada de processamento de documentos garante melhor aderência aos requisitos legais e procedimentos de avaliação de risco mais eficientes.
Conclusão
Em conclusão, os modelos de linguagem visual representam um avanço significativo na tecnologia de processamento de documentos, abordando muitas das limitações inerentes aos sistemas tradicionais de OCR. Ao combinar compreensão visual e textual, esses modelos avançados oferecem desempenho superior em uma ampla gama de cenários desafiadores, desde layouts complexos até idiomas mistos e imagens de baixa qualidade. À medida que as organizações continuam a digitalizar suas operações e buscam maneiras mais eficientes de extrair valor de seus repositórios de documentos, os modelos de linguagem visual emergem como uma ferramenta poderosa para desenvolvedores e líderes de engenharia. Sua capacidade de compreender o contexto, lidar com formatos diversos e fornecer resultados mais precisos os posiciona como um facilitador chave para pipelines sofisticados de RAG e capacidades de busca em toda a empresa, impulsionando, em última análise, as iniciativas de transformação digital a novos patamares.