Você já se perguntou o que significa OCR? O Reconhecimento Óptico de Caracteres é uma tecnologia poderosa que converte imagens de texto em dados legíveis por máquina. Embora o OCR ofereça enormes benefícios para a digitalização de documentos e extração de informações, não está isento de desvantagens. Ao explorar essa tecnologia, é crucial entender tanto suas capacidades quanto suas limitações. Neste artigo, você descobrirá o significado por trás do OCR e se aprofundará em suas possíveis desvantagens. Ao obter uma compreensão abrangente do Reconhecimento Óptico de Caracteres, você estará melhor preparado para determinar se e como implementar essa tecnologia em seus próprios fluxos de trabalho e projetos.
O que significa OCR e o que é um OCR?
O que significa OCR?
OCR significa Reconhecimento Óptico de Caracteres, uma tecnologia que permite que os computadores reconheçam e convertam vários tipos de documentos. Em sua essência, o OCR é o processo de escanear texto impresso ou manuscrito e convertê-lo em texto codificado por máquina. Isso permite que o texto seja pesquisável, editável e transferível com facilidade. Compreender o que significa OCR é essencial para qualquer pessoa que trabalhe com tecnologias de escaneamento de documentos e reconhecimento de texto.
O que é um OCR?
Para aqueles que não estão familiarizados com o termo, "o que é um OCR" é uma pergunta comum, referindo-se ao Reconhecimento Óptico de Caracteres, uma tecnologia que permite que os computadores leiam texto de imagens ou documentos escaneados.
O OCR converte texto impresso ou manuscrito em dados legíveis por máquina, fazendo a ponte entre formatos impressos e digitais. Essa tecnologia emprega algoritmos sofisticados para detectar formas de letras, estruturas de palavras e até mesmo frases inteiras. Ao fazer isso, transforma imagens estáticas em arquivos de texto editáveis e pesquisáveis.
A tecnologia OCR é fundamentalmente baseada em tecnologias de visão computacional e reconhecimento de padrões. OCR refere-se ao trabalho de escanear documentos ou imagens contendo texto e usar algoritmos avançados para identificar e converter o texto em um formato digital e editável. Um dos momentos-chave na história da tecnologia OCR foi em 1974, quando Ray Kurzweil desenvolveu um sistema OCR omni-font que podia reconhecer texto em praticamente qualquer fonte. Ao longo dos anos, o OCR evoluiu de simples correspondência de modelos para sistemas mais sofisticados.
Apesar de suas capacidades, a tecnologia OCR enfrenta atualmente certas limitações. Isso inclui desafios no reconhecimento de texto em imagens de baixa qualidade, dificuldade em lidar com layouts ou fundos complexos e variação na precisão ao lidar com diferentes fontes, idiomas ou caligrafia. Além disso, os sistemas OCR podem ter dificuldades com documentos que possuem fundos coloridos, estão borrados ou inclinados, e com caligrafia cursiva.
Compreendendo o software de Reconhecimento Óptico de Caracteres
O software de Reconhecimento Óptico de Caracteres é uma tecnologia transformadora que converte vários tipos de documentos em dados editáveis e pesquisáveis. Ele desempenha um papel crucial na digitalização do nosso mundo, tornando a informação mais acessível e gerenciável. O software OCR emprega um processo sofisticado para converter imagens de texto em dados legíveis por máquina.
Como o Software OCR Funciona
1. Aquisição de Imagem
A jornada do OCR começa com a captura de uma imagem do documento. Isso pode ser feito através de um scanner ou de uma câmera digital. A imagem é então traduzida em um formato digital que um computador pode processar.
2. Pré-processamento e Melhoria de Imagem
A segunda etapa envolve a melhoria da qualidade da imagem. Uma vez adquirida a imagem, ela passa por um pré-processamento para melhorar sua qualidade para um melhor reconhecimento. Essa etapa pode envolver ajustes no contraste, brilho e nitidez da imagem, além da remoção de qualquer ruído ou elementos irrelevantes. Essa fase de pré-processamento é crucial para alcançar resultados precisos, especialmente ao lidar com digitalizações ou fotografias de baixa qualidade.
3. Detecção de Texto
O software OCR analisa a imagem pré-processada para detectar áreas que contêm texto. Ele faz isso procurando padrões e formas que são características do texto, como linhas de diferentes espessuras e alturas.
4. Segmentação de Caracteres
Uma vez detectadas as áreas de texto, o software divide o texto em unidades menores, como blocos, linhas, palavras ou até mesmo caracteres individuais. O software OCR analisa a imagem pixel a pixel para identificar padrões que formam caracteres. Ele divide a imagem em segmentos menores, isolando cada caractere.
5. Reconhecimento e Extração de Texto
O software então compara essas formas isoladas com um vasto banco de dados de padrões de caracteres conhecidos para determinar o que cada caractere é. O software extrai características dos caracteres, como o número de linhas, curvas ou ângulos. Essas características ajudam o OCR a reconhecer e distinguir entre diferentes caracteres.
6. Pós-processamento
Após a identificação dos caracteres, o sistema OCR passa por uma fase de pós-processamento onde corrige quaisquer erros potenciais e formata o texto para saída. O texto corrigido é então exportado para o formato desejado, como um documento Word ou um PDF pesquisável.
Casos de Uso com Software de Reconhecimento Óptico de Caracteres
O OCR se tornou uma ferramenta essencial na transformação digital de muitas indústrias, otimizando processos e melhorando a acessibilidade e precisão dos dados. Você pode encontrar o OCR mais frequentemente do que imagina. Desde a digitalização de cartões de visita até a digitalização de livros antigos, o OCR desempenha um papel crucial em várias indústrias. A tecnologia OCR possui uma ampla gama de aplicações:
-
Digitalização de Documentos: O OCR é usado para converter materiais impressos, como livros antigos, jornais e documentos históricos, em formatos digitais, tornando-os pesquisáveis e preservando-os para futuras gerações.
-
Processamento de Formulários: As empresas utilizam o OCR para extrair automaticamente dados de formulários, o que reduz a entrada manual de dados e aumenta a eficiência em vários setores, como finanças e saúde.
-
Processamento de Faturas: A tecnologia OCR pode ler texto em faturas e inserir automaticamente os dados em sistemas financeiros, otimizando processos contábeis e de escrituração.
-
Acessibilidade: O OCR permite a funcionalidade de texto para fala, criando versões em áudio de textos para indivíduos com deficiência visual, tornando assim os materiais impressos mais acessíveis.
-
Aplicativos Móveis: O OCR é integrado a aplicativos para tarefas como escanear cartões de visita, reconhecer texto em fotos e facilitar traduções em tempo real.
-
Pesquisabilidade: O OCR melhora a pesquisabilidade de documentos escaneados ao extrair texto de imagens ou PDFs, permitindo fácil busca e recuperação de informações.
-
Reconhecimento de Placas de Veículos: Usado para gerenciamento de estacionamento e tráfego, o OCR pode reconhecer placas de veículos, permitindo monitoramento e fiscalização eficientes.
-
Operações Comerciais: O OCR otimiza processos empresariais ao automatizar a entrada de dados de documentos como faturas, recibos e pedidos de compra, além de acelerar o recrutamento ao escanear e processar candidaturas e currículos.
-
Setores Jurídico e de Saúde: Escritórios de advocacia usam OCR para digitalizar arquivos de casos e documentos legais para facilitar a recuperação de informações, enquanto prestadores de saúde utilizam para converter registros de pacientes e formulários médicos em registros eletrônicos de saúde (EHRs), melhorando a gestão de dados e o atendimento ao paciente.
-
Educação: Em ambientes educacionais, o OCR é usado para criar livros didáticos digitais e materiais de aprendizagem, melhorando a acessibilidade para estudantes com necessidades diversas e apoiando um ambiente de aprendizado inclusivo.
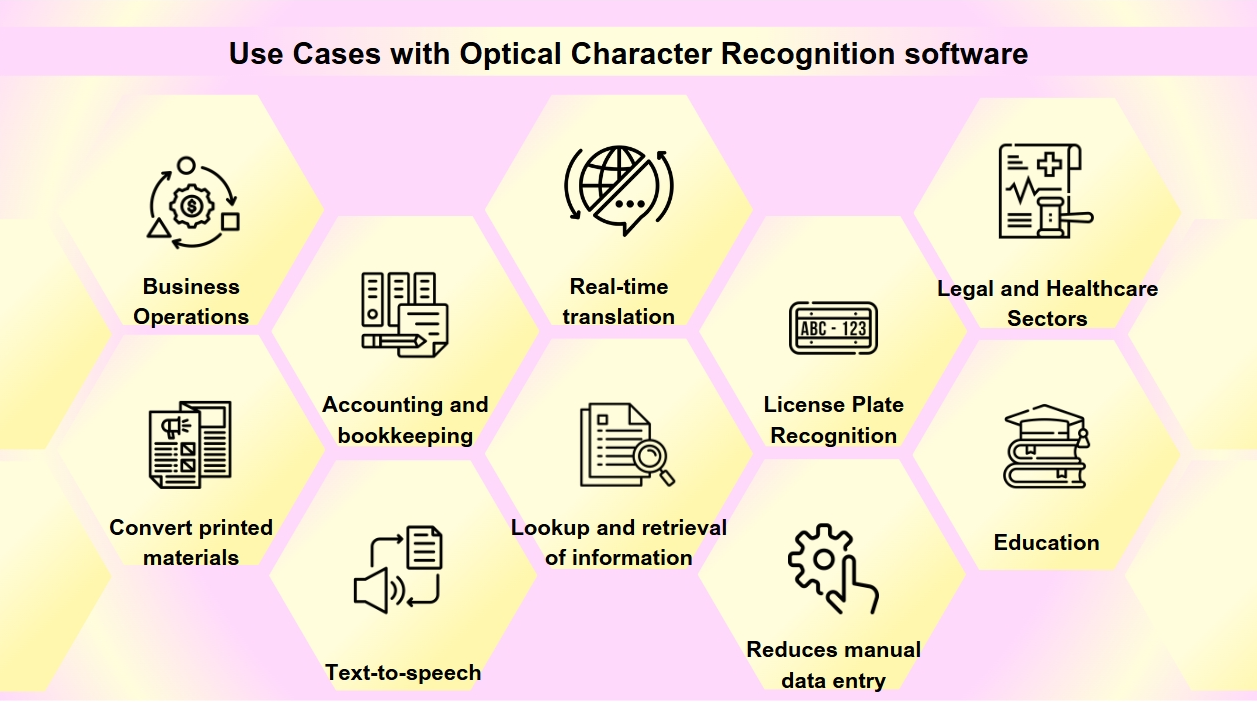
À medida que a tecnologia OCR avança, ela continua a desempenhar um papel vital em tornar a informação mais acessível e eficiente de ser manipulada na era digital.
A Desvantagem do OCR: Limitações e Desvantagens
Desafios de Precisão
Embora a tecnologia de Reconhecimento Óptico de Caracteres (OCR) tenha avançado muito, ainda enfrenta obstáculos significativos para alcançar precisão perfeita. Texto manuscrito, fontes incomuns ou imagens de baixa qualidade podem levar a interpretações erradas e erros. Mesmo pequenas variações nas formas ou tamanhos dos caracteres podem confundir os sistemas OCR, resultando em saídas embaralhadas que requerem correção manual.
Restrições de Idioma e Formato
A maioria das soluções OCR se destaca com idiomas e formatos padrão, mas enfrenta dificuldades com conteúdo especializado. Documentos técnicos, equações matemáticas ou textos com múltiplos idiomas podem representar desafios significativos. Além disso, o OCR pode falhar quando confrontado com layouts complexos, tabelas ou documentos com formatação intrincada, potencialmente perdendo informações estruturais cruciais.
Intensidade de Recursos
Implementar e manter um sistema OCR eficaz pode ser intensivo em recursos. Software OCR de alta qualidade muitas vezes vem com um preço elevado, e o hardware necessário para processar grandes volumes de documentos pode ser caro. Além disso, o tempo e o esforço necessários para treinar a equipe, ajustar o sistema e revisar manualmente a saída do OCR podem sobrecarregar os recursos organizacionais.
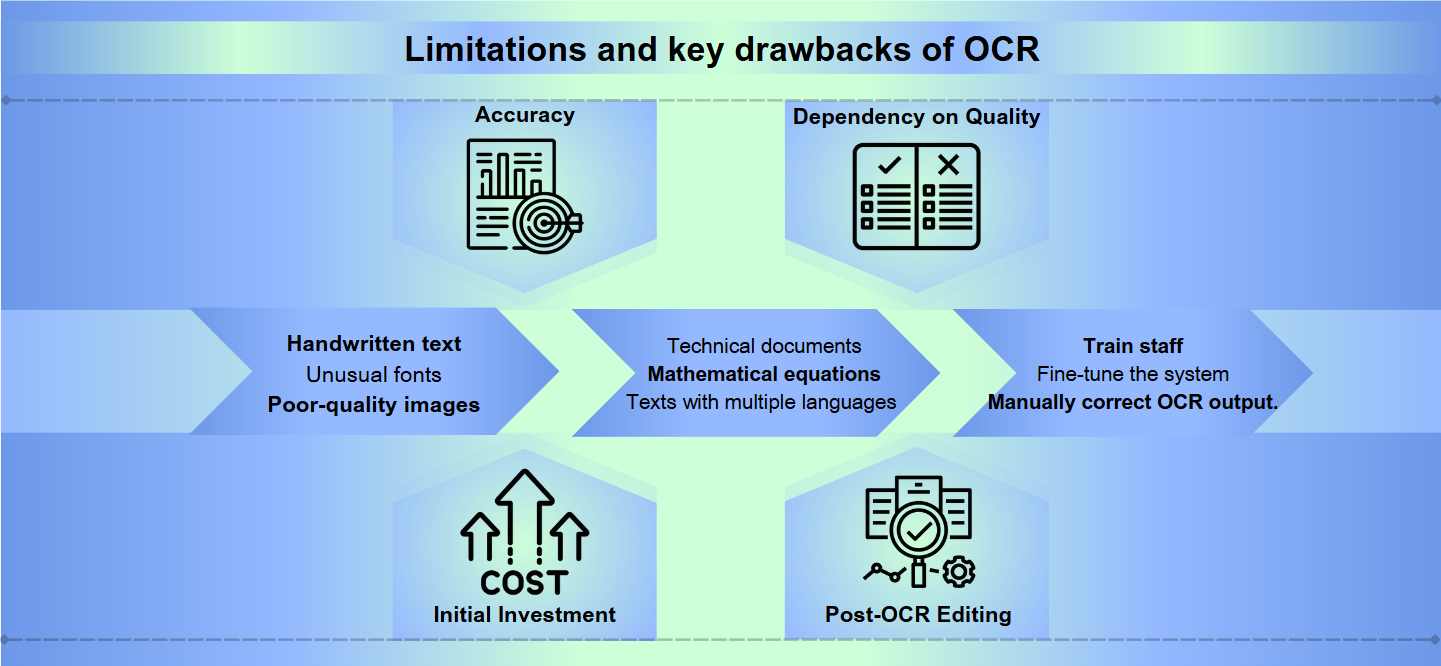
Principais desvantagens do OCR
-
Precisão: O software OCR pode ter dificuldades com precisão, especialmente ao lidar com imagens de baixa qualidade, layouts complexos ou texto manuscrito. Os erros podem variar de leitura incorreta de caracteres a pular seções inteiras de texto.
-
Dependência da Qualidade: A eficácia do OCR depende fortemente da qualidade do documento original. Tinta desbotada, borrões ou papel amassado podem levar a traduções imprecisas.
-
Investimento Inicial: Configurar um sistema OCR pode exigir um custo inicial significativo, incluindo não apenas o software, mas também hardware compatível, como scanners.
-
Edição Pós-OCR: Muitas vezes, a saída dos processos de OCR requer revisão e correção manual, o que pode ser demorado.
Modelo de Linguagem Visual superando as limitações do OCR
À medida que a tecnologia avança, soluções inovadoras estão surgindo para abordar as deficiências do Reconhecimento Óptico de Caracteres (OCR) tradicional. Uma dessas inovações é o Modelo de Linguagem Visual (VLM), que combina visão computacional e processamento de linguagem natural para revolucionar a extração e compreensão de texto.
Compreensão contextual aprimorada
Os VLMs se destacam na compreensão do contexto que envolve o texto, ao contrário do reconhecimento isolado de caracteres do OCR. Ao analisar elementos visuais juntamente com o texto, esses modelos podem interpretar layouts complexos, anotações manuscritas e até mesmo texto parcialmente oculto com notável precisão.
Capacidades multilíngues e multimodais
Enquanto o OCR frequentemente enfrenta dificuldades com idiomas e scripts diversos, os VLMs demonstram uma versatilidade impressionante. Eles podem processar vários idiomas de forma contínua e até interpretar conteúdo visual como diagramas ou gráficos, proporcionando uma compreensão mais abrangente dos documentos.
Aprendizado adaptativo e melhoria contínua
Ao contrário dos sistemas OCR estáticos, os VLMs utilizam aprendizado de máquina para se adaptar e melhorar ao longo do tempo. À medida que encontram novos dados e cenários, esses modelos refinam seu desempenho, tornando-se cada vez mais aptos a lidar com vários tipos e formatos de documentos.
Ao superar as limitações do OCR, os Modelos de Linguagem Visual estão abrindo caminho para um processamento de documentos mais preciso, eficiente e inteligente em diversas indústrias.
Escolha o Modelo de Linguagem Visual: Experimente o AnyParser
Baseando-se nos avanços dos Modelos de Linguagem Visual (VLM), o AnyParser surge como uma solução sofisticada que transcende as limitações da tecnologia OCR tradicional. Desenvolvido pela equipe da CambioML, o AnyParser é uma poderosa ferramenta de extração de documentos que utiliza uma API precisa e configurável para extrair informações de várias fontes de dados não estruturados, como PDFs, imagens e gráficos, convertendo-os em formatos estruturados.
Fundação Técnica e Capacidades
O AnyParser é ancorado na robusta fundação de grandes modelos de linguagem (LLMs), garantindo alta precisão na extração de texto, tabelas, gráficos e layouts de documentos. Ele se destaca por sua capacidade de manter o layout e formato originais, um recurso particularmente benéfico para documentos com layouts complexos ou que exigem a preservação da estética original.
Privacidade e Segurança
Enfatizando a privacidade do usuário, o AnyParser processa dados localmente, protegendo assim informações sensíveis. Esse recurso é uma vantagem significativa para empresas e indivíduos que lidam com dados confidenciais.
Personalização e Flexibilidade
Oferecendo um alto grau de configurabilidade, o AnyParser permite que os usuários definam regras de extração personalizadas e formatos de saída que atendam às suas necessidades específicas. Essa adaptabilidade torna-o uma ferramenta ideal para uma ampla gama de aplicações, desde engenharia de IA até análise financeira.
Conclusão
Como você aprendeu, a tecnologia OCR oferece capacidades poderosas para digitalizar texto, mas não está isenta de limitações. Embora o reconhecimento óptico de caracteres possa melhorar dramaticamente a eficiência, você deve ponderar cuidadosamente as possíveis desvantagens. Considere os problemas de precisão, os desafios de formatação e os requisitos de recursos antes de implementar uma solução OCR. Em última análise, a decisão de utilizar OCR depende de suas necessidades e circunstâncias específicas. Ao entender tanto os benefícios quanto as desvantagens, você pode tomar uma decisão informada sobre se o OCR é adequado para sua organização. À medida que o OCR continua a evoluir, mantenha-se atualizado sobre novos desenvolvimentos que possam abordar as deficiências atuais e desbloquear um potencial ainda maior para essa tecnologia transformadora.
Chamada à Ação
Aproveite o poder dos Modelos de Linguagem Visual experimentando o AnyParser gratuitamente para converter seus PDFs em Google Sheets em https://www.cambioml.com/sandbox. Obtenha uma consulta gratuita sobre como os VLMs podem aprimorar seu fluxo de trabalho de extração de dados.