Conversia PDF-urilor complexe în Markdown poate fi o provocare. Există multe biblioteci open-source disponibile pentru a extrage text din PDF, dar atunci când vine vorba de PDF-uri care conțin elemente complexe, cum ar fi tabele și grafice, rezultatele sunt adesea nesatisfăcătoare. Modelele populare de limbaj mare, cum ar fi GPT sau Claude, pot gestiona aceste sarcini, dar tind să fie lente și uneori produc rezultate inexacte. Instrumentele OCR tradiționale, deși eficiente pentru documente mai simple, se luptă adesea să mențină structura exactă și semnificația semantică a conținutului original. Pe de altă parte, modelele de limbaj vizual uneori halucinează, ducând la rezultate de analiză eronate. Acest blog va explica ce înseamnă analiza și va detalia rezultatele unei analize comparative a mai multor modele folosind multiple metrici.
Ce înseamnă analiza?
În contextul analizei PDF, "analiza" se referă la procesul de extragere a datelor specifice dintr-un fișier PDF folosind software specializat cunoscut sub numele de parser PDF. Un parser PDF analizează conținutul unui document PDF și identifică elemente precum text, imagini, fonturi, layout-uri și chiar metadate. Datele extrase pot fi apoi organizate și exportate în diferite formate, cum ar fi XML, JSON sau Excel/CSV, care pot fi utilizate pentru diverse scopuri, cum ar fi analiza datelor, păstrarea înregistrărilor sau automatizarea fluxurilor de lucru.
Înțelegerea a ceea ce înseamnă analiza este esențială pentru evaluarea eficienței unei soluții de analiză, în special atunci când comparăm diferite instrumente de conversie PDF în Markdown, deoarece parserul PDF implică mai mult decât simpla extragere de text—este necesară recunoașterea și menținerea structurii semantice a documentului.
Cum măsurăm calitatea acestor soluții de analiză?
Am definit o serie de metrici la nivel de cuvânt pentru a evalua performanța diferitelor modele, concentrându-ne pe factori cheie precum:
-
Precizie, Recall și F-Measure: Evaluarea calității și completitudinii analizei.
-
Scor BLEU și ANLS: Utile pentru evaluarea limbii și structurii layout-ului.
-
Distanța de editare, Divergența Jensen-Shannon și Distanța Jaccard: Metrici specifice domeniului OCR, utile în special pentru înțelegerea exactității reproducerii conținutului.
Modelul nostru de limbaj vizual, AnyParser, demonstrează o performanță excepțională, combinând viteză și acuratețe, în special pe layout-uri complexe cu tabele și elemente semantice. AnyParser depășește alte soluții, oferind o îmbunătățire de 20 de ori a vitezei față de modele precum GPT/Claude, în timp ce atinge o acuratețe mai mare.
O comparație extinsă a rezultatelor împotriva modelelor de analiză de vârf
Obiect statistic
Pentru a evidenția cu adevărat capabilitățile AnyParser, am realizat o comparație extinsă împotriva modelelor de analiză de vârf din industrie și a modelelor de limbaj mare bine cunoscute (LLM-uri). Evaluarea noastră a inclus:
1. Modele de limbaj mare
- AnyParser
- GPT-4o de la OpenAI
- Gemini 1.5 Pro de la Google
- Claude 3.5 Sonnet de la Anthropic
2. Servicii bazate pe OCR
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Prezentarea și analiza rezultatelor
Experimentul 1
În primul rând, am desfășurat o serie de comparații riguroase ale performanței diferitelor modele AI pentru documente pe peste 5 metrici: BLEU, Precizie și recall, F-Measure și ANLS. Puteți găsi definiția matematică a acestor metrici în anexă.
Modelele comparate sunt: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl și Azure-DocAl.
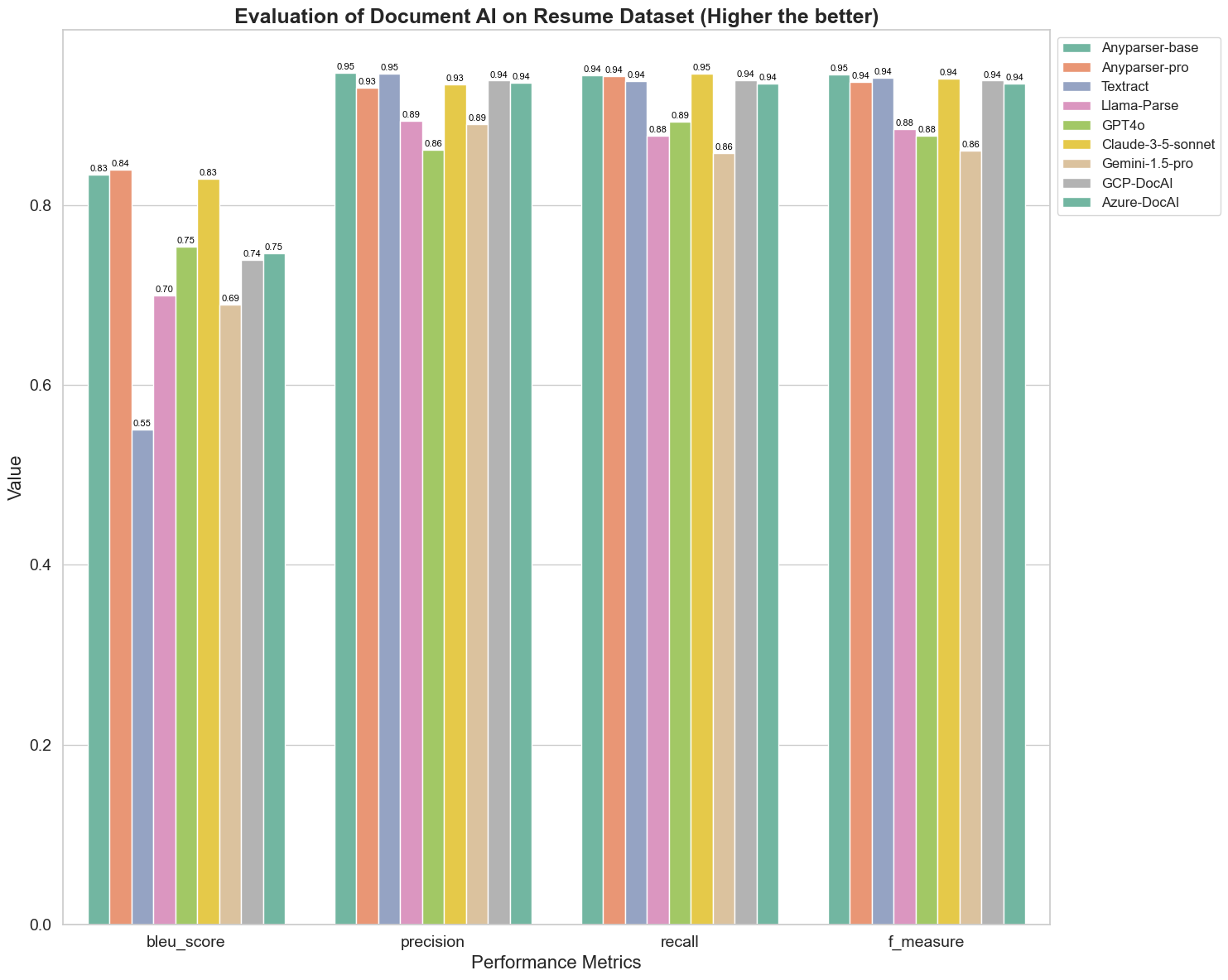
Scorul BLEU este utilizat ca o evaluare a calității interpretării bilingve pentru a testa calitatea modelelor în procesarea enunțurilor. Comparând rezultatele acestor modele de analiză sub metoda de evaluare BLEU, descoperim că: scorurile AnyParser-base și AnyParser-pro sunt semnificativ mai mari decât scorurile celorlalte modele, Amazon Textract obținând cele mai mici scoruri, iar rezultatele celorlalte modele se află la un nivel relativ mediu.
Acuratețea recunoașterii este de obicei reprezentată prin precizie și recall, unde precizia reprezintă procentul de rezultate corecte reale dintre rezultatele judecate ca fiind corecte de model, iar recall-ul reprezintă procentul de rezultate judecate corecte de model dintre toate rezultatele reale corecte. Comparând precizia și recall-ul acestor modele de analiză, descoperim că: cu excepția Llama-Parse, GPT4o și Gemini-1.5-pro, toate celelalte modele sunt la un nivel înalt. Dintre acestea, AnyParser și Amazon Textract sunt mai proeminente în precizie, iar AnyParser-base și AnyParser-pro sunt mai proeminente în recall. Scorul mai mare al modelului pe Precizie indică faptul că modelul produce mai multe informații corecte în rezultatele sale, iar scorul mai mare pe recall indică faptul că modelul este mai capabil să obțină informații corecte din eșantion. Rezultatele scorurilor arată că AnyParser are un avantaj clar în ceea ce privește acuratețea recunoașterii pentru a extrage text din PDF.
F-Measure este un indice de evaluare cuprinzător al preciziei și recall-ului pe aceste două indicatori. Comparând scorurile acestor modele de analiză sub F-Measure, putem observa mai intuitiv că cele cinci modele, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI și Azure-DocAI, au o putere mai bună în ceea ce privește acuratețea recunoașterii comparativ cu celelalte modele. Putem observa mai intuitiv că cele cinci modele au mai multă putere în acuratețea recunoașterii decât celelalte modele, iar AnyParser are cel mai mare scor sub F-Measure, ceea ce ilustrează în continuare avantajul evident al AnyParser în acuratețea recunoașterii pentru a extrage text din PDF.
ANLS, ca un indice de evaluare utilizat frecvent atunci când vine vorba de măsurarea acurateței și similarității între textul original și textul țintă la nivel de caracter, este de asemenea foarte informativ pentru măsurarea nivelului de analiză al modelelor. Scorurile mai mari ale AnyParser-base, AnyParser-pro și Azure-DocAI reflectă nivelul mai ridicat de analiză al acestor modele comparativ cu celelalte modele.
În general, AnyParser-base și AnyParser-pro depășesc celelalte modele.
Experimentul 2
De asemenea, comparăm performanța diferitelor modele AI pentru documente pe trei metrici diferite: Distanța de editare, Divergența Jensen-Shannon și Distanța Jaccard. Metricile sunt utilizate pentru a măsura similaritatea între output-ul modelelor și un document de referință. Valorile mai mici indică o performanță mai bună.
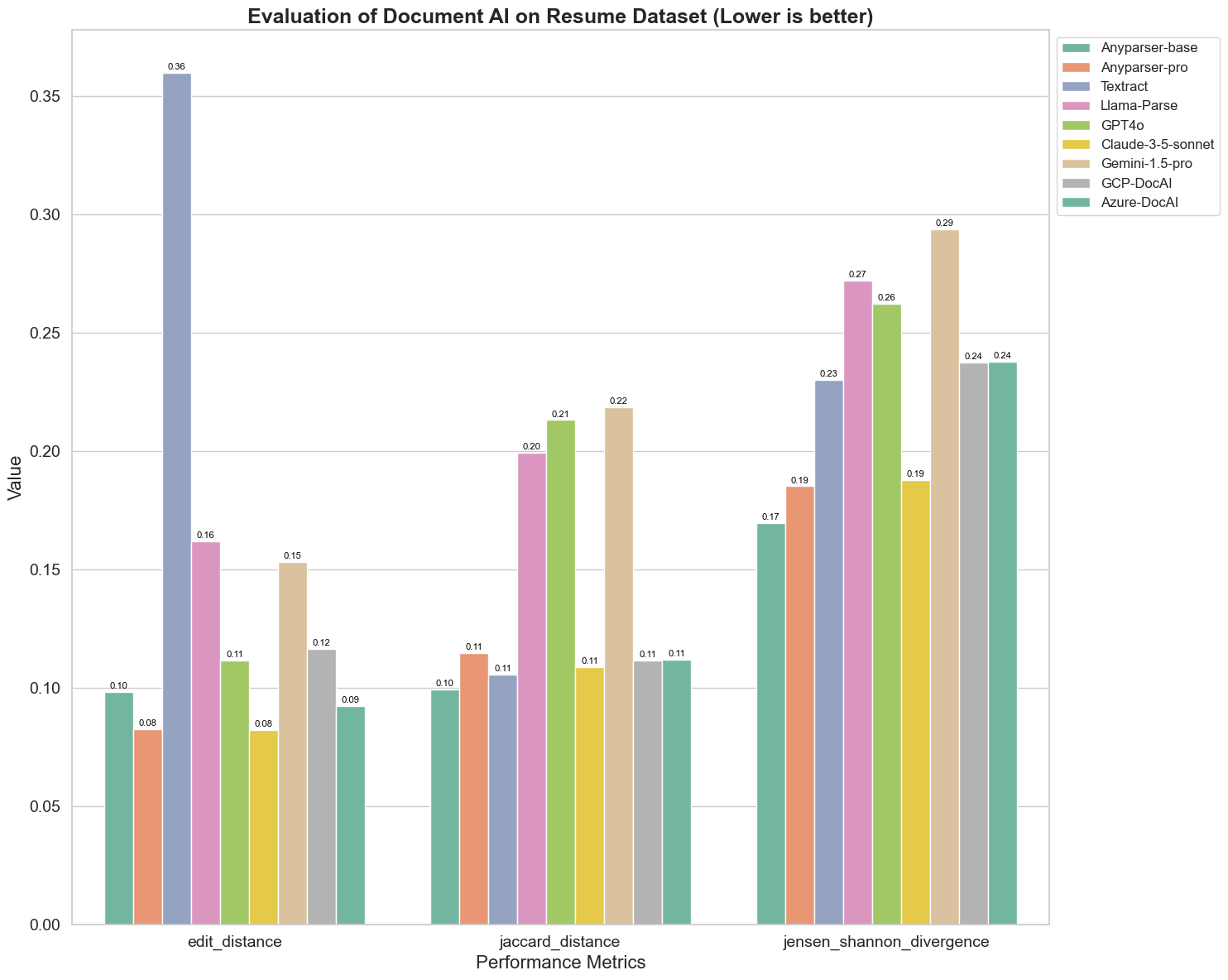
Iată câteva observații cheie din grafic:
-
Distanța de editare: Modelele AnyParser-base și AnyParser-pro au cele mai bune rezultate cu cea mai mică distanță de editare, sugerând că output-urile lor au fost cele mai apropiate de documentul de referință.
-
Divergența Jensen-Shannon: Modelele AnyParser-base și AnyParser-pro au cea mai mică divergență, ceea ce implică faptul că output-urile lor sunt cele mai similare cu documentul de referință în ceea ce privește distribuția cuvintelor.
-
Distanța Jaccard: În afară de Llama-parse, GPT4O, Gemini-1.5, toate celelalte modele au performanțe decente cu cea mai mică distanță Jaccard, indicând că output-urile lor au cea mai mare suprapunere cu documentul de referință în ceea ce privește setul de cuvinte utilizate.
Concluzie
În general, testarea noastră riguroasă sugerează că AnyParser-base și AnyParser-pro performează bine în general pe diverse metrici, indicând potențialul său pentru procesarea precisă a documentelor. Din grafice, putem observa că modelele OCR tradiționale, cum ar fi celebrul Amazon Textract, obțin scoruri mult mai mici decât modelele de limbaj vizual. Cu toate acestea, performanța diferitelor modele variază în funcție de metricile utilizate, subliniind importanța de a lua în considerare multiple criterii de evaluare atunci când comparăm modelele AI.
Introducerea pipeline-ului nostru de evaluare open-source
Pentru a simplifica evaluările, am creat un pipeline de evaluare care oferă o metodă standardizată în industrie pentru compararea modelelor de analiză. În exemplul nostru, demonstrăm utilizarea sa în domeniul resurselor umane, unde analiza CV-urilor este comună. Am construit un set de date sintetic diversificat de 128 de CV-uri, generate folosind fișiere imagine-Markdown pereche. Folosind GPT-4, am generat conținut HTML, l-am redat în imagini și am folosit textul extras ca adevăr de bază pentru comparație.
Și iată partea cea mai bună: am open-sourced acest cadru de evaluare pe GitHub! Indiferent dacă sunteți dezvoltator sau utilizator de afaceri, pipeline-ul nostru vă permite să evaluați și să comparați calitatea analizei diferitelor modele pe propriul set de date.
Găsiți ghidul de început rapid în repo-ul GitHub și vedeți cum se compară diferitele modele de analiză între ele. Credem că, prin evidențierea puterii modelului nostru în mod deschis, putem atrage mai mulți utilizatori care doresc capacități de analiză fiabile, rapide și precise.
Anexă - Metrici
1. Precizie
Precizia măsoară acuratețea conținutului analizat, arătând câte dintre elementele recuperate au fost corecte. În analiză, este proporția cuvintelor corect extrase din toate cuvintele extrase.
Precizie = Adevărate Pozitive (TP) / (Adevărate Pozitive (TP) + False Pozitive (FP))
- Adevărate Pozitive (TP): Cuvinte corect identificate de parser.
- False Pozitive (FP): Cuvinte incorect identificate de parser.
2. Recall
Recall indică completitudinea analizei, sau câte cuvinte relevante din documentul original au fost recuperate.
Recall = Adevărate Pozitive (TP) / (Adevărate Pozitive (TP) + False Negative (FN))
- False Negative (FN): Cuvinte din documentul original care au fost omise de parser.
3. F-Measure (Scor F1)
Scorul F1 este media armonică a Preciziei și Recall-ului, echilibrând ambele metrici pentru a oferi o măsură generală a calității analizei.
Scor F1 = 2 × (Precizie × Recall) / (Precizie + Recall)
4. Scor BLEU (Evaluarea Bilingvă Substituentă)
Scorul BLEU măsoară similaritatea între conținutul analizat și textul original, punând accent special pe ordinea cuvintelor. Este deosebit de util pentru evaluarea consistenței limbii și structurii în documentele analizate, deoarece penalizează output-urile care diferă în secvență de original.
5. ANLS (Similaritatea Levenshtein Normalizată Medie)
ANLS cuantifică similaritatea între conținutul analizat și original, folosind distanța de editare normalizată. Este calculată prin medierea Similarității Levenshtein Normalizate (NLS) pentru fiecare pereche de cuvinte în textele analizate și de referință. NLS este calculată astfel:
NLS = 1 - (Distanța Levenshtein (LD)(cuvânt analizat, cuvânt original)) / max(Lungimea cuvântului analizat, Lungimea cuvântului original)
Apoi, ANLS este media NLS pe toate perechile de cuvinte:
ANLS = (1/N) × Σ(NLS_i) pentru i=1 la N
6. Distanța de editare
Distanța de editare calculează numărul de operațiuni la nivel de cuvânt (inserții, ștergeri, substituții) necesare pentru a converti textul analizat în original.
7. Divergența Jensen-Shannon
Divergența Jensen-Shannon măsoară similaritatea între distribuțiile de probabilitate discrete ale numărului de cuvinte analizate și originale, evidențiind diferențele în frecvența cuvintelor.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
unde M = (1/2)(P + Q), și KL(P || Q) este divergența Kullback-Leibler
8. Distanța Jaccard
Distanța Jaccard măsoară disimilitudinea între seturile de cuvinte în conținutul analizat și original, utilă pentru evaluarea suprapunerii cuvintelor.
Distanța Jaccard = 1 - |A ∩ B| / |A ∪ B|
unde |A ∩ B| este numărul de elemente comune între A și B,
și |A ∪ B| este numărul total de elemente unice în ambele seturi.