Modelele de Limbaj Vizual (VLM) revoluționează domeniul analizei documentelor, abordând multe dintre limitările inerente sistemelor tradiționale de Recunoaștere Optică a Caracterelor (OCR). Deși OCR a fost o tehnologie de bază pentru digitizarea textului din imagini, se confruntă cu provocări semnificative în scenarii complexe. Acestea includ probleme de precizie cu imagini de calitate scăzută, o înțelegere contextuală limitată, dificultăți cu limbile mixte și incapacitatea de a interpreta elemente vizuale. VLM oferă o soluție promițătoare prin combinarea viziunii computerizate avansate cu capacitățile de procesare a limbajului natural. Acest articol explorează modul în care VLM depășesc neajunsurile OCR, oferind soluții mai robuste și versatile pentru procesarea documentelor în era digitală.
Ce este OCR? Care sunt procesele OCR în analiza documentelor?
Recunoașterea Optică a Caracterelor (OCR) este o tehnologie care permite conversia diferitelor tipuri de documente, cum ar fi documente pe hârtie scanate, fișiere PDF sau imagini capturate de o cameră digitală, în date editabile și căutabile. Acest proces este crucial în procesarea documentelor și extracția de date PDF, permițând mașinilor să recunoască caracterele textului tipărit sau de mână din imaginile digitale.
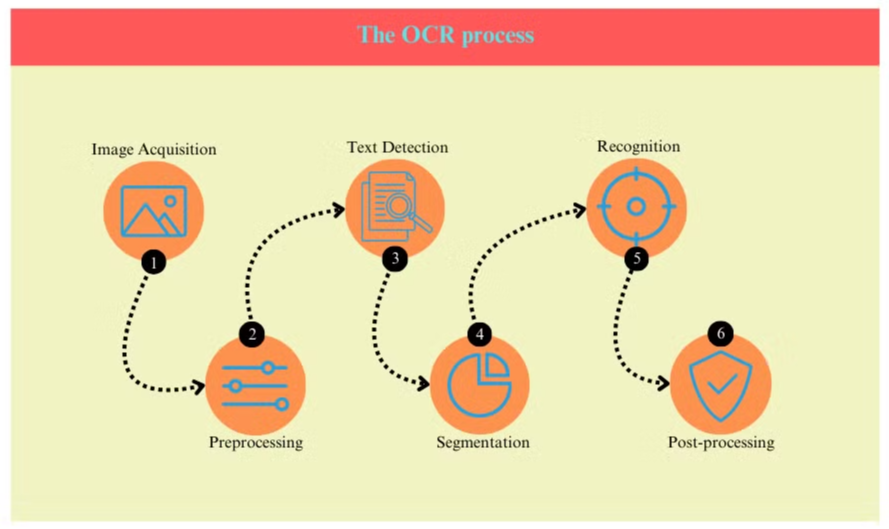
Procesul OCR
Procesul OCR implică de obicei mai mulți pași:
- Achiziția imaginii: Documentul este scanat sau fotografiat pentru a crea o imagine digitală.
- Preprocesare: Imaginea este curățată, eliminând zgomotul și ajustând luminozitatea și contrastul.
- Detectarea textului: Sistemul identifică zonele care conțin text în cadrul imaginii.
- Segmentarea caracterelor: Caracterele individuale sunt izolate în zonele de text.
- Recunoașterea caracterelor: Fiecare caracter este analizat și comparat cu o bază de date de caractere cunoscute.
- Post-procesare: Textul recunoscut este verificat pentru erori folosind informații lingvistice și contextuale.
Deși OCR a îmbunătățit semnificativ capacitățile de analiză a documentelor, se confruntă în continuare cu limitări în gestionarea layout-urilor complexe, imaginilor de calitate scăzută și fonturilor variate. Aici intervin tehnologii avansate precum modelele de limbaj vizual pentru a îmbunătăți precizia și înțelegerea în extragerea datelor din imagini și documente.
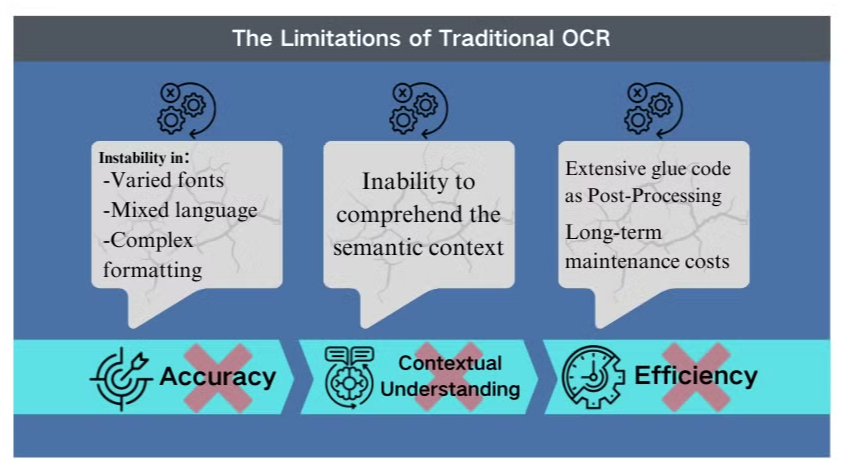
Limitările tehnologiei OCR tradiționale
Provocări de precizie în scenarii complexe
Tehnologia tradițională de recunoaștere optică a caracterelor (OCR), deși benefică pentru extragerea de text de bază, se confruntă cu obstacole semnificative atunci când se confruntă cu layout-uri de documente complexe sau imagini de calitate scăzută. Aceste sisteme adesea au dificultăți în menținerea preciziei atunci când procesează documente cu fonturi variate, limbaje mixte sau formatare complexă. De exemplu, OCR poate eșua atunci când încearcă să extragă date din prezentări bogate în imagini sau PDF-uri dens formatate.
Lipsa înțelegerii contextuale
Una dintre cele mai evidente limitări ale OCR-ului convențional este incapacitatea sa de a înțelege contextul semantic al textului pe care îl procesează. Această deficiență devine deosebit de evidentă în scenarii care necesită interpretare nuanțată, cum ar fi contractele legale sau rapoartele medicale. Focalizarea OCR-ului pe recunoașterea caracterelor fără o conștientizare contextuală poate duce la interpretări critice greșite, mai ales atunci când se lucrează cu caractere ambigue sau terminologie specifică industriei.
Ineficiențe în post-procesare
Limitările OCR necesită adesea eforturi extinse de post-procesare. Acest pas suplimentar poate crește semnificativ timpul și resursele necesare pentru procesarea documentelor. În plus, sistemele OCR tradiționale de obicei nu reușesc să extragă informații din grafice, tabele sau alte elemente non-textuale, complicând și mai mult procesul de extracție a documentelor. Aceste ineficiențe subliniază necesitatea unor soluții mai avansate, cum ar fi modelele de limbaj vizual, care oferă o abordare mai cuprinzătoare pentru analiza documentelor și extracția de date.
Ce sunt Modelele de Limbaj Vizual și cum îmbunătățesc OCR
Modelele de limbaj vizual reprezintă un salt semnificativ în tehnologia de procesare a documentelor, abordând multe dintre limitările inerente sistemelor tradiționale de recunoaștere optică a caracterelor (OCR). Aceste modele avansate combină viziunea computerizată cu procesarea limbajului natural pentru a înțelege simultan atât elementele vizuale, cât și cele textuale ale documentelor.
Precizie îmbunătățită și înțelegere contextuală
Spre deosebire de OCR, care se confruntă cu imagini de calitate scăzută și layout-uri complexe, modelele de limbaj vizual excelează în interpretarea diverselor formate de documente. Ele pot extrage cu precizie date din imagini, PDF-uri și alte conținuturi vizuale, chiar și în fața unor scenarii provocatoare. Această precizie îmbunătățită provine din capacitatea lor de a considera întregul context al unui document, mai degrabă decât de a se concentra exclusiv pe caractere sau cuvinte individuale.
Extracție cuprinzătoare de date
Modelele de limbaj vizual depășesc simpla recunoaștere a textului, oferind capacități cuprinzătoare de extracție de date PDF. Ele pot identifica și interpreta tabele, grafice și figuri din documente, păstrând integritatea layout-urilor complexe. Această abordare holistică a analizei documentelor permite o recuperare a informațiilor mai nuanțată și completă, îmbunătățind semnificativ utilitatea datelor extrase pentru aplicațiile ulterioare.
Proficiență multilingvă și multi-format
Unul dintre principalele avantaje ale modelelor de limbaj vizual este flexibilitatea lor în gestionarea mai multor limbi și formate de documente. Spre deosebire de sistemele OCR care pot avea dificultăți cu scripturi non-latine sau documente în limbi mixte, aceste modele pot procesa fără probleme conținutul din diverse limbi și scripturi, făcându-le indispensabile pentru nevoile globale de procesare a documentelor.
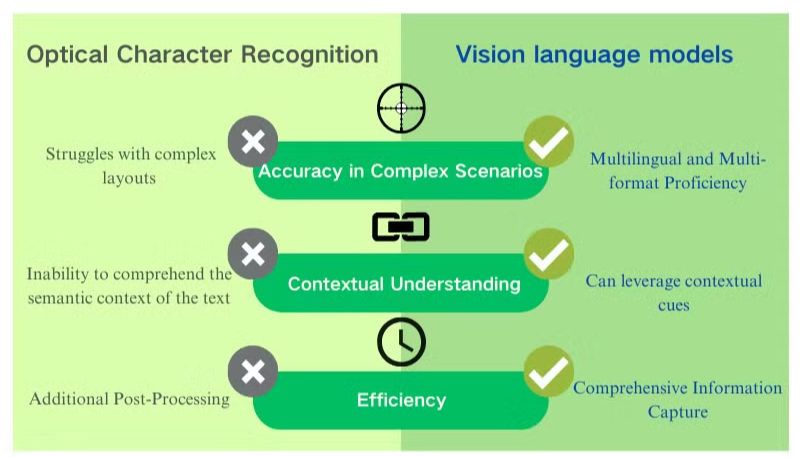
Beneficiile cheie ale modelelor de limbaj vizual pentru înțelegerea documentelor
Modelele de limbaj vizual oferă avantaje semnificative față de OCR-ul tradițional pentru procesarea documentelor și extracția de date. Aceste sisteme alimentate de AI combină înțelegerea vizuală și textuală pentru a oferi rezultate superioare în diverse tipuri de documente.
Precizie îmbunătățită și înțelegere contextuală
Modelele de limbaj vizual excelează în gestionarea layout-urilor complexe, imaginilor de calitate scăzută și fonturilor diverse. Spre deosebire de OCR, care se confruntă cu caractere ambigue, aceste modele valorifică indicii contextuale pentru a interpreta cu precizie textul. Această capacitate îmbunătățește dramatic precizia extracției de date PDF, în special pentru documentele cu structuri complexe sau calitate slabă a imaginii.
Capturarea cuprinzătoare a informațiilor
În timp ce OCR se concentrează exclusiv pe recunoașterea textului, modelele de limbaj vizual pot extrage date din imagini, tabele și grafice. Această abordare holistică asigură că informațiile critice nu sunt omise în timpul procesării documentelor. Prin capturarea atât a elementelor textuale, cât și a celor vizuale, aceste modele oferă o înțelegere mai completă a conținutului documentului.
Proficiență multilingvă și multi-format
Modelele de limbaj vizual demonstrează o flexibilitate remarcabilă în procesarea documentelor din diverse limbi și formate. Ele pot gestiona fără probleme documente în limbi mixte și scripturi non-latine, depășind o limitare semnificativă a sistemelor OCR tradiționale. Această versatilitate le face indispensabile pentru întreprinderile globale care se ocupă cu diverse tipuri de documente și limbi.
Aplicații din lumea reală activate de VLM care au eșuat OCR
Modelele de limbaj vizual revoluționează procesarea documentelor în finanțe, resurse umane și alte sectoare, abordând limitările critice ale sistemelor tradiționale OCR. Aceste modele avansate de AI transformă eforturile de transformare digitală în diverse industrii prin oferirea unei precizii superioare și a unei înțelegeri contextuale.
Revoluționarea procesării documentelor financiare
Modelele de limbaj vizual transformă procesarea documentelor în domeniul financiar, depășind limitările OCR tradițional. Aceste modele avansate excelează în extragerea datelor din declarații financiare complexe, facturi și chitanțe cu layout-uri intricate. Spre deosebire de OCR, ele pot înțelege contextul, interpretând cu precizie caracterele ambigue (de exemplu, diferențierea între un zero și litera O) și limbile mixte adesea prezente în documentele financiare globale.
Îmbunătățirea operațiunilor HR prin analiza inteligentă a documentelor
În sectorul resurselor umane, modelele de limbaj vizual se dovedesc a fi indispensabile pentru extracția de date PDF din CV-uri, dosare de angajați și evaluări ale performanței. Aceste modele pot înțelege structura semantică a documentelor, permițând o recuperare și analiză mai precisă a informațiilor. Această capacitate streamlinează semnificativ procesele de angajare și gestionarea datelor angajaților, sarcini la care OCR adesea se confruntă cu formate variate și note de mână.
Îmbunătățirea conformității și gestionării riscurilor
Modelele de limbaj vizual sunt deosebit de eficiente în conformitate și gestionarea riscurilor atât în domeniul financiar, cât și în HR. Ele pot extrage și interpreta informații critice din documente de reglementare, contracte și politici cu o precizie mai mare decât OCR. Această capacitate îmbunătățită de procesare a documentelor asigură o mai bună conformitate cu cerințele legale și proceduri de evaluare a riscurilor mai eficiente.
Concluzie
În concluzie, modelele de limbaj vizual reprezintă un salt semnificativ în tehnologia de procesare a documentelor, abordând multe dintre limitările inerente sistemelor tradiționale OCR. Prin combinarea înțelegerii vizuale și textuale, aceste modele avansate oferă performanțe superioare în diverse scenarii provocatoare, de la layout-uri complexe la limbaje mixte și imagini de calitate scăzută. Pe măsură ce organizațiile continuă să își digitizeze operațiunile și să caute modalități mai eficiente de a extrage valoare din repositoarele lor de documente, modelele de limbaj vizual apar ca un instrument puternic pentru dezvoltatori și lideri de inginerie deopotrivă. Capacitatea lor de a înțelege contextul, de a gestiona formate diverse și de a oferi rezultate mai precise le poziționează ca un factor cheie pentru pipeline-urile RAG sofisticate și capacitățile de căutare la nivel de întreprindere, conducând în cele din urmă inițiativele de transformare digitală către noi culmi.