Введение
Таблицы являются краеугольным камнем представления структурированных данных и широко используются в таких отраслях, как финансы, здравоохранение и исследования. Тем не менее, извлечение табличной информации из форматов, таких как PDF, отсканированные документы или изображения, остается сложной задачей из-за разнообразия макетов и сложностей.
Искусственный интеллект (ИИ) произвел революцию в парсинге документов, обеспечивая точные и эффективные решения для таких задач, как извлечение таблицы из PDF или преобразование таблицы в формате PNG в структурированные данные. Используя передовые методы ИИ, компании теперь могут легко преобразовывать неструктурированные визуальные данные в практические инсайты, включая преобразование изображения в таблицу для бесшовной интеграции в рабочие процессы.
В этом блоге рассматривается, как извлечение таблиц с помощью ИИ помогает отраслям, подчеркиваются основные технологии и демонстрируется его потенциал для упрощения сложных задач обработки документов.

Проблемы традиционного извлечения таблиц
Ручное извлечение табличных данных из документов, таких как PDF или изображения, является утомительным, подверженным ошибкам и неэффективным процессом. Ниже приведены некоторые распространенные проблемы, с которыми сталкиваются традиционные методы:
-
Сложные структуры таблиц: Таблицы часто имеют неправильные макеты, такие как вложенные ячейки, многострочные заголовки или объединенные строки, которые трудно интерпретировать. Традиционные инструменты не могут точно извлечь таблицу из PDF в таких сценариях.
-
Разнообразные форматы: Таблицы встречаются в широком диапазоне форматов, включая отсканированные документы, файлы таблиц в формате PNG и PDF. Извлечение данных из них требует передовых методов распознавания, которые выходят за рамки простого OCR.
-
Контекст и значение: Традиционные системы сталкиваются с трудностями в сохранении отношений между строками и столбцами, что имеет решающее значение при преобразовании изображения в таблицу или обработке больших наборов данных.
Эти проблемы подчеркивают необходимость в интеллектуальных решениях, таких как извлечение таблиц с помощью ИИ, которые могут справляться со сложными макетами и разнообразными форматами, обеспечивая при этом высокую точность.
Что такое извлечение таблиц с помощью ИИ?
Извлечение таблиц с помощью ИИ — это применение технологий интеллектуального парсинга документов, предназначенных для идентификации, извлечения и организации структурированных данных из таблиц в различных форматах документов. В отличие от традиционных методов, основанных на правилах, подходы, управляемые ИИ, используют передовые технологии для решения сложных задач, таких как нестандартные макеты, объединенные ячейки и многострочные заголовки.
Ключевым достижением в этой области является использование моделей "Язык-Зрение" (VLM). Модели VLM объединяют сильные стороны компьютерного зрения и понимания естественного языка, позволяя им интерпретировать как визуальные, так и текстовые элементы в документе. Эта двойная способность позволяет моделям VLM:
- Визуально идентифицировать структуры таблиц, даже когда они не имеют явного форматирования.
- Контекстуально понимать содержание, например, различать заголовки, данные и примечания.
- Адаптироваться к различным типам документов, включая отсканированные изображения, PDF и рукописные заметки.
Используя модели VLM, извлечение таблиц с помощью ИИ стало более точным и универсальным, способным обрабатывать многоязычные документы и извлекать отношения между данными, которые традиционные методы часто упускают.
Ключевые технологии, лежащие в основе извлечения таблиц с помощью ИИ
Извлечение таблиц с помощью ИИ опирается на набор передовых технологий, которые работают в гармонии для преодоления традиционных проблем. Среди них модели "Язык-Зрение" (VLM) выделяются как трансформационная инновация. Ниже приведен обзор ключевых технологий и важной роли моделей VLM:
-
Оптическое распознавание символов (OCR): Извлекает текст из изображений или отсканированных документов. В сочетании с моделями VLM результаты OCR улучшаются, поскольку модели понимают как визуальную структуру, так и текстовое значение.
-
Модели "Язык-Зрение" (VLM): Модели VLM революционизируют извлечение таблиц, интегрируя визуальную и лингвистическую обработку данных. Они превосходят в:
- Распознавании сложных макетов таблиц и неправильных границ.
- Интерпретации отношений между строками, столбцами и заголовками.
- Обработке таблиц в различных форматах, включая изображения и PDF, с поддержкой многоязычности. Модели VLM обеспечивают более глубокое контекстуальное понимание, гарантируя, что извлеченные данные сохраняют свое оригинальное значение и структуру.
-
Обработка естественного языка (NLP): Анализирует и организует извлеченные данные, обеспечивая семантическую согласованность. Модели VLM дополнительно улучшают NLP, предоставляя контекстуальные подсказки из визуальных паттернов.
-
Алгоритмы глубокого обучения: Обучают модели распознавать границы таблиц, иерархии ячеек и паттерны в неструктурированных документах. Обогащенные моделями VLM, эти алгоритмы достигают большей точности и адаптивности.
Подчеркивая модели VLM, извлечение таблиц с помощью ИИ перешло от простой задачи извлечения данных к задаче контекстуального понимания, что делает его незаменимым для отраслей, где точность и нюансы имеют первостепенное значение.
Примеры использования извлечения таблиц с помощью ИИ
Извлечение таблиц с помощью ИИ трансформирует отрасли, автоматизируя процесс извлечения и организации табличных данных из различных форматов документов. Ниже приведены некоторые примечательные примеры использования, где интеллектуальное извлечение таблиц оказалось неоценимым:
-
Финансы: Извлечение структурированных данных из финансовых отчетов, счетов и отчетов часто является трудоемкой задачей. ИИ делает процесс копирования таблицы из PDF в Excel бесшовным, позволяя быстрее проводить сверку, анализ и отчетность.
-
Здравоохранение: Организация результатов клинических испытаний, медицинских записей или данных медицинских исследований упрощается. Например, медицинские учреждения могут легко копировать таблицы из PDF в Excel, обеспечивая готовность данных для интеграции в системы электронных медицинских записей (EHR).
-
Юридическая сфера: Анализ контрактов и извлечение структурированных пунктов из вложенных таблиц помогает юридическим командам работать более эффективно. Модели ИИ упрощают процесс копирования таблицы из PDF в Excel, экономя время на проверках соответствия и исследовании судебных дел.
-
Научные исследования и академия: Исследователи могут быстро извлекать данные из научных статей, упрощая задачу передачи ключевых метрик с помощью инструментов для копирования таблиц из PDF в Excel, подготавливая наборы данных для статистического анализа.
Способность извлечения таблиц с помощью ИИ точно обрабатывать разнообразные форматы документов революционизирует рабочие процессы, упрощая копирование, организацию и анализ табличных данных в листах Excel.
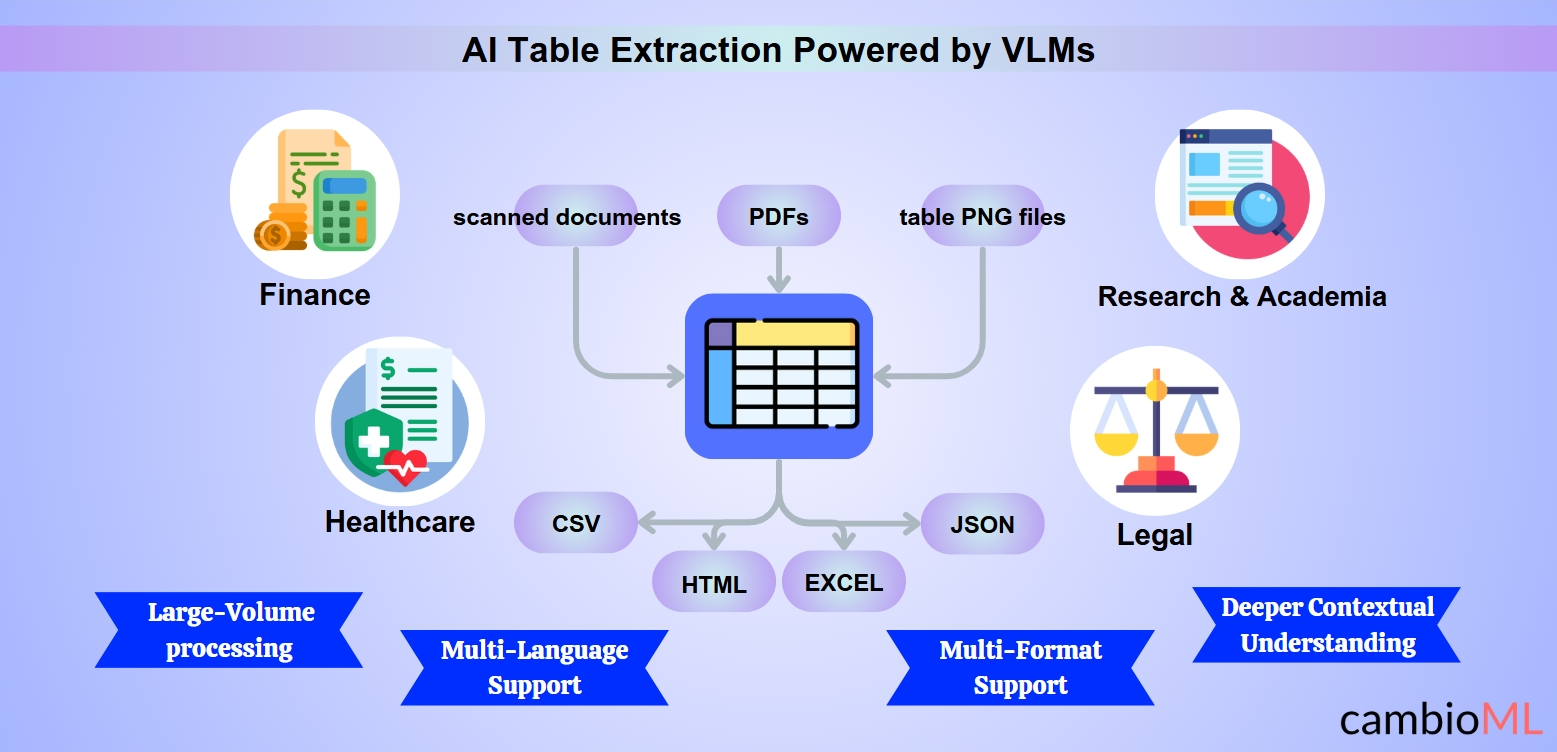
Преимущества интеллектуального извлечения таблиц
Извлечение таблиц с помощью ИИ предлагает множество преимуществ, особенно в улучшении эффективности, точности и масштабируемости. Используя передовые технологии, включая модели "Язык-Зрение" (VLM), компании могут преодолевать традиционные проблемы в извлечении таблиц:
-
Автоматизация и экономия времени: Повторяющиеся задачи, такие как ручное копирование таблиц из PDF в Excel, исключаются, позволяя сотрудникам сосредоточиться на более ценных задачах.
-
Улучшенная точность: Модели ИИ значительно снижают количество ошибок, которые часто возникают, когда пользователи вручную копируют таблицы из PDF в Excel или полагаются на базовые инструменты. Эти модели гарантируют, что данные сохраняют свою структуру и значение.
-
Масштабируемость для обработки больших объемов данных: Инструменты ИИ предназначены для обработки массового извлечения данных. Будь то финансовые записи, исследовательские документы или файлы для соблюдения норм, они упрощают процесс извлечения и организации данных в Excel.
-
Поддержка многоформатности и многоязычности: Интеллектуальные системы могут обрабатывать документы в различных форматах и языках, обеспечивая бесшовное извлечение и копирование таблиц из PDF в Excel даже в сложных многоязычных контекстах.
Извлечение таблиц с помощью ИИ не только оптимизирует рабочие процессы, но и обеспечивает целостность контекста данных, трансформируя подход к обработке табличной информации в отраслях. Эта эффективность имеет критическое значение в современном мире, ориентированном на данные, где быстрая и точная обработка табличных данных является конкурентным преимуществом.
Решение проблем многоформатности и многоязычности
Современные решения на основе ИИ превосходно справляются с изменчивостью форматов и языков, обеспечивая постоянную точность и эффективность при работе с разнообразными наборами данных:
-
Возможности многоформатности: Инструменты, основанные на ИИ, могут без труда обрабатывать PDF, отсканированные документы и файлы изображений, такие как таблицы в формате PNG. Эта универсальность особенно критична, когда пользователям необходимо извлечь таблицу из PDF или преобразовать изображение в таблицу для анализа и отчетности.
-
Поддержка многоязычности: Модели ИИ обучены на многоязычных наборах данных, что позволяет им обрабатывать документы на различных языках. Эта функция незаменима для глобальных отраслей, работающих с международной документацией.
-
Сохранение отношений данных: Независимо от того, обрабатывается ли изображение в таблицу или извлекается сложная структура из PDF, системы ИИ гарантируют, что заголовки, строки и столбцы сохраняются, поддерживая целостность данных.
Решая эти проблемы, решения на основе ИИ зарекомендовали себя как незаменимые инструменты для организаций, работающих с документацией в больших масштабах, многоязычной и многоформатной.
Будущее ИИ в извлечении таблиц
Будущее извлечения таблиц с помощью ИИ выглядит многообещающим, с ожидаемыми достижениями, которые еще больше улучшат его возможности:
-
Улучшенные модели "Язык-Зрение" (VLM): Новые технологии VLM предоставят еще более сложные способы извлечения таблиц из PDF и преобразования сложных форматов таблиц в PNG в структурированные данные. Эти модели соединят визуальные элементы и текстовое понимание.
-
Интеграция с генеративным ИИ: Интеграция генеративного ИИ позволит будущим решениям не только извлекать таблицы из PDF или изображений, но и анализировать извлеченные данные для получения инсайтов, резюме и рекомендаций.
-
Автоматизация от начала до конца: Инструменты на основе ИИ упростят рабочие процессы, автоматически преобразуя файлы, такие как преобразование изображения в таблицу, классифицируя данные и передавая их непосредственно в аналитические потоки.
-
Широкая доступность: Системы ИИ станут более удобными и доступными, позволяя даже не техническим пользователям без труда обрабатывать файлы таблиц в формате PNG или извлекать данные.
Извлечение таблиц с помощью ИИ готово переопределить обработку документов, делая извлечение данных более быстрым, умным и адаптируемым к меняющимся потребностям отрасли. Компании, которые примут эти решения, получат конкурентное преимущество в управлении и использовании своих данных.
AnyParser: Революционное решение в парсинге документов и извлечении таблиц
AnyParser находится на переднем крае интеллектуального парсинга документов, предлагая компаниям эффективный и надежный способ извлечения данных даже из самых сложных документов. Его передовые возможности особенно очевидны в извлечении таблиц, обеспечивая точное и масштабируемое захватывание данных для различных отраслей.
Ключевые преимущества AnyParser для извлечения таблиц
-
Всеобъемлющая поддержка форматов: Независимо от того, работаете ли вы с PDF, изображениями или другими типами файлов, AnyParser упрощает захват данных, точно извлекая табличную информацию независимо от формата.
-
Высокая точность и контекстуальное понимание: В отличие от традиционных инструментов, AnyParser сохраняет структуру, отношения и контекст табличных данных, предоставляя результаты, готовые к анализу и интеграции.
-
Эффективность на основе ИИ: Благодаря моделям "Язык-Зрение" (VLM) AnyParser превосходит в многоязычных и многоформатных средах, обеспечивая бесшовный захват данных в больших масштабах.
-
Настраиваемые рабочие процессы: Платформа адаптируется к вашим уникальным потребностям, будь то извлечение финансовых таблиц, медицинских записей или исследовательских данных.
С помощью AnyParser компании могут оптимизировать свои процессы, минимизировать ошибки и экономить время, автоматизируя сложную задачу извлечения таблиц для структурированного захвата данных.
Заключение
Извлечение таблиц с помощью ИИ переопределило, как компании обрабатывают и используют структурированные данные. Будь то задача извлечения таблиц из PDF, обработки изображений или достижения точного захвата данных, такие инструменты, как AnyParser, делают этот процесс проще, чем когда-либо, превращая неструктурированные документы в практические инсайты. AnyParser — это ваше надежное решение для упрощения парсинга документов, обеспечивая непревзойденную точность и эффективность. Благодаря своей способности обрабатывать разнообразные форматы и контексты AnyParser дает возможность организациям автоматизировать свои рабочие процессы и раскрыть полный потенциал своих данных.
Призыв к действию
Зачем ждать, чтобы испытать следующий уровень парсинга документов? Раскройте весь потенциал AnyParser, попробовав его функции в практической среде!
Нажмите на ссылку ниже, чтобы войти в Песочницу, где вы можете узнать, как он упрощает:
- Точный захват данных из PDF и изображений.
- Бесшовное извлечение таблиц для интеграции в аналитические инструменты.
- Надежную работу с комплексными и большими наборами данных.
Испытайте AnyParser в Песочнице сейчас
Не упустите возможность увидеть, как AnyParser может революционизировать ваши рабочие процессы. Протестируйте его сегодня и узнайте, насколько простым может быть парсинг документов и извлечение таблиц!