В современном мире, ориентированном на данные, конвертация сложных документов из формата PDF в CSV является важной задачей для многих специалистов. Если вы сталкиваетесь с банковскими выписками, медицинскими отчетами или накладными в формате PDF, вы, вероятно, ищете эффективное решение.
На помощь приходят языковые модели визуального восприятия (VLM), передовая технология, которая превосходит традиционные методы OCR. Используя как визуальное, так и контекстуальное понимание, VLM предлагают мощный инструмент для преобразования сложных структурированных документов в форматы, пригодные для машинного чтения.
Это руководство проведет вас через процесс использования VLM для конвертации ваших PDF в файлы CSV или Excel с помощью AnyParser, упрощая ваш рабочий процесс и открывая доступ к ценным данным. С AnyParser вы можете легко конвертировать PDF в CSV, PDF в Excel или даже конвертировать Word в CSV всего за несколько кликов на нашей платформе.
Сильные потребности в конвертации PDF в CSV и ограничения традиционных моделей OCR
Растущий спрос на конвертацию PDF в CSV
В современном мире, ориентированном на данные, необходимость конвертировать PDF в CSV становится все более актуальной. Компании и частные лица ищут эффективные способы преобразования статических PDF-документов в динамические, анализируемые таблицы. Этот процесс конвертации необходим для извлечения ценной информации из различных документов, таких как банковские выписки, медицинские отчеты и накладные. Возможность конвертировать Word в Excel или использовать конвертер PDF в CSV может значительно упростить управление данными и процессы анализа.
Недостатки традиционных технологий OCR
Хотя традиционные модели оптического распознавания символов (OCR) долгое время использовались для извлечения текста, они часто не справляются с обработкой сложных документов. Эти ограничения становятся очевидными при попытке конвертировать сложные PDF в Google Sheets или другие форматы таблиц. Системы OCR испытывают трудности с:
- Точным интерпретированием низкокачественных сканов или изображений
- Обработкой многостолбцовых макетов и таблиц
- Распознаванием различных шрифтов и языков
- Сохранением оригинальной структуры документа
Эти проблемы подчеркивают необходимость более продвинутых решений, которые могут без проблем обрабатывать процесс конвертации PDF в CSV, сохраняя как содержание, так и контекст оригинальных документов.
Пошаговое руководство по конвертации PDF-документов с использованием AnyParser
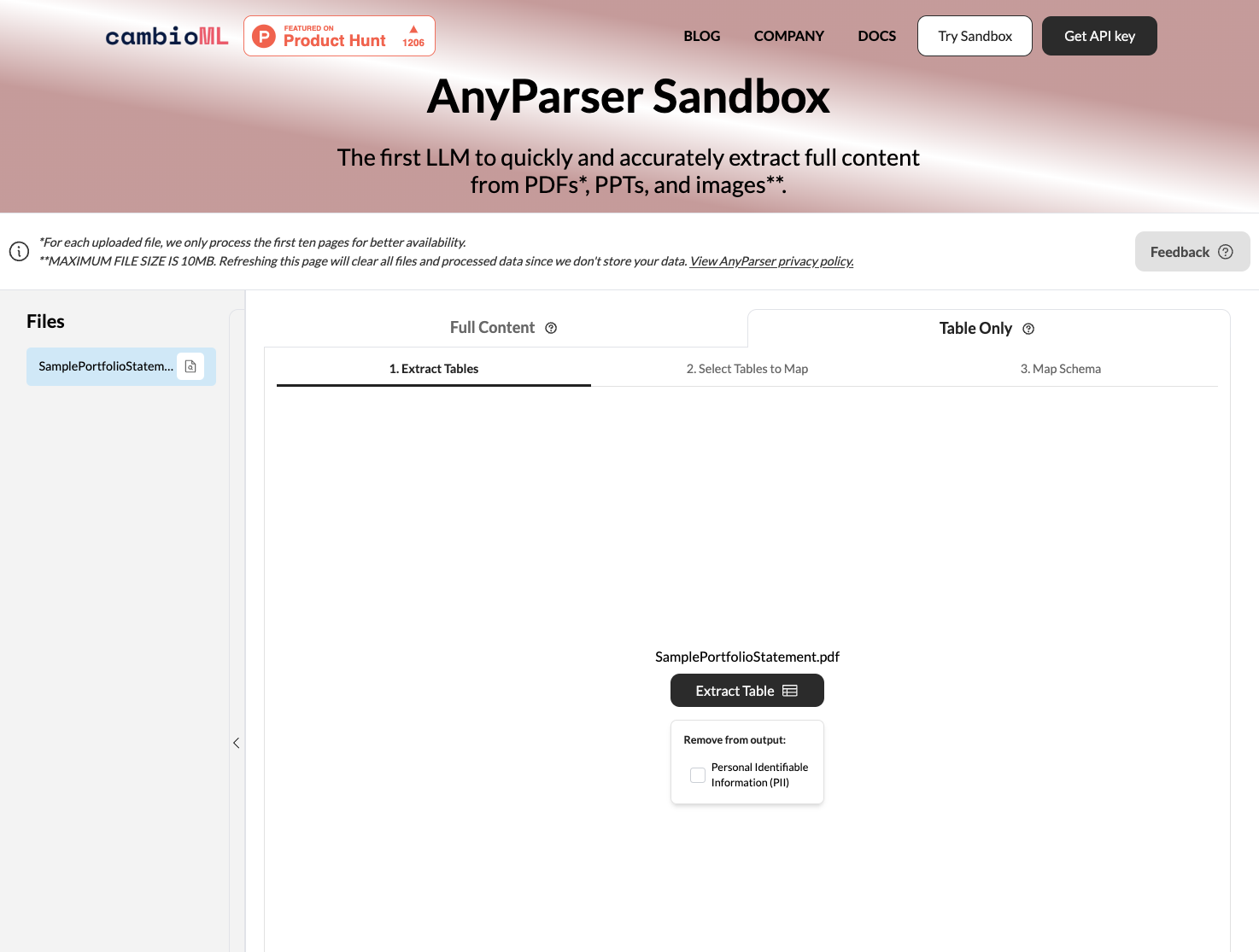
AnyParser — это мощный инструмент для конвертации PDF в CSV, который использует передовые языковые модели визуального восприятия для точного извлечения данных из сложных PDF-документов. Вот основные шаги для использования AnyParser для конвертации ваших PDF-файлов:
-
Загрузите ваш PDF или Word. Просто перетащите ваши PDF-документы в веб-интерфейс AnyParser или вы можете вставить скриншот PDF в интерфейс AnyParser.
-
Выберите "Только таблица" и нажмите "Извлечь". API AnyParser автоматически обнаружит таблицы в PDF и извлечет их с высокой точностью. Извлеченные данные сохраняются в .csv-файле, который вы можете скачать или экспортировать в Google Sheets всего одним кликом.
-
Предварительный просмотр и сравнение. Просмотрите извлеченные данные в предварительном просмотре, чтобы убедиться, что они соответствуют вашим ожиданиям. Просмотрите начальное извлечение AnyParser и сравните его бок о бок в интерфейсе.
-
Экспорт в CSV или Excel. Как только вы будете удовлетворены извлечением, скачайте .csv-файл, чтобы использовать данные в своих приложениях и системах. Извлеченные данные можно легко импортировать в таблицы и базы данных для дальнейшего анализа.
Следуя этим простым шагам и используя мощь языковых моделей визуального восприятия, AnyParser позволяет вам эффективно конвертировать даже самые сложные PDF-документы в структурированные, редактируемые CSV-файлы, которые вы можете анализировать и интегрировать в свои рабочие процессы.
Посмотрите это видео, чтобы увидеть пошаговую демонстрацию!
Применение VLM для конвертации PDF в CSV/Excel в реальном мире
Языковые модели визуального восприятия (VLM) революционизируют способ, которым мы конвертируем PDF в CSV и Excel, предлагая мощные решения для различных отраслей. Используя эти продвинутые модели, вы можете эффективно преобразовывать сложные документы в структурированные, пригодные для машинного чтения данные.
Обработка финансовых документов
В банковском секторе VLM отлично справляются с конвертацией PDF в CSV для банковских выписок. Эти модели могут точно извлекать детали транзакций, номера счетов и информацию о балансе, даже из документов со сложными макетами или несколькими валютами. Эта возможность упрощает процессы финансового анализа и сверки.
Управление медицинскими записями
Для медицинских работников VLM предоставляют бесценный инструмент для конвертации Word в Excel для медицинских отчетов. Точно интерпретируя сложную медицинскую терминологию и сохраняя структуру лабораторных результатов, VLM способствуют созданию комплексных баз данных пациентов. Эта трансформация позволяет легче проводить анализ тенденций и улучшать уход за пациентами.
Оптимизация логистики и цепочки поставок
В логистической отрасли VLM выделяются при конвертации накладных из PDF в Google Sheets. Эти модели могут извлекать важную информацию, такую как адреса доставки, описания товаров и номера отслеживания, сохраняя целостность табличных данных. Эта конвертация позволяет эффективно управлять запасами и оптимизировать маршруты.
Используя конвертер PDF в CSV на базе VLM, вы можете значительно повысить эффективность обработки данных в различных секторах. Эти продвинутые модели предлагают непревзойденную точность в обработке многоязычных документов, сложных макетов и даже низкокачественных сканов, что делает их незаменимым инструментом для современных компаний.
Как языковые модели визуального восприятия преодолевают проблемы OCR
Языковые модели визуального восприятия (VLM) революционизируют способ, которым мы конвертируем PDF в CSV и преобразуем сложные документы в форматы, пригодные для машинного чтения. В отличие от традиционного OCR, VLM используют как визуальное, так и лингвистическое понимание для решения самых сложных аспектов конвертации документов.
Интерпретация сложных макетов
VLM отлично справляются с расшифровкой сложных структур документов, что делает их идеальными для конвертации Word в Excel или обработки банковских выписок с различными форматами. Анализируя пространственные отношения между текстовыми элементами, VLM могут точно восстанавливать таблицы и сохранять целостность макета. Например, VLM могут правильно интерпретировать PDF с накладной, содержащей несколько таблиц с разным количеством столбцов и строк, в то время как традиционный OCR может перепутать строки и столбцы.
Контекстуальное понимание
Одним из ключевых преимуществ VLM является их способность улавливать семантическое значение содержания документа. Это контекстуальное осознание позволяет более точно извлекать данные при использовании конвертера PDF в CSV, особенно для документов, специфичных для определенной области, таких как медицинские отчеты CBC или накладные по логистике. Например, VLM могут правильно классифицировать медицинские отчеты по специальности на основе их содержания и даже понять, что "количество лейкоцитов" — это "количество белых кровяных клеток (WBC)"!
Многоязычные возможности
VLM преодолевают языковые барьеры, без проблем обрабатывая несколько скриптов и языков в одном документе. Это делает их особенно полезными для международных компаний, работающих с разнообразными типами документов. Например, VLM могут извлекать данные из PDF, содержащего текст как на английском, так и на французском языках.
Снижение шума
Низкокачественные сканы или изображения часто представляют собой проблемы для традиционных систем OCR. Однако VLM могут эффективно фильтровать шум и сосредотачиваться на релевантной информации, обеспечивая высокое качество вывода при конвертации документов в Google Sheets или другие форматы. Например, VLM могут точно извлекать данные из размытых или выцветших PDF-документов.
Часто задаваемые вопросы о конвертации PDF в CSV с использованием языковых моделей визуального восприятия
Чем отличается конвертация на основе VLM от традиционного OCR?
Языковые модели визуального восприятия (VLM) предлагают значительные преимущества по сравнению с традиционным OCR при конвертации PDF в CSV или Excel. В отличие от OCR, VLM могут точно интерпретировать сложные макеты, понимать контекст и без проблем обрабатывать несколько языков. Это делает их идеальными для конвертации банковских выписок, медицинских отчетов CBC и накладных по логистике в форматы, пригодные для машинного чтения.
Какие типы документов лучше всего подходят для конвертации VLM?
VLM отлично справляются с конвертацией структурированных документов с таблицами, графиками и смешанным содержанием. Они особенно эффективны для финансовых отчетов, медицинских отчетов и накладных. Конвертер PDF в CSV на базе VLM может сохранить целостность таблиц и извлекать данные даже из низкокачественных сканов или сложных многоязычных документов.
Насколько точна конвертация на основе VLM по сравнению с ручным вводом данных?
Решения на основе VLM, такие как AnyParser, могут значительно повысить точность по сравнению с ручным вводом данных или традиционным OCR. Используя как визуальное, так и контекстуальное понимание, эти инструменты могут сократить количество ошибок при конвертации Word в Excel или PDF в Google Sheets до 50%. Эта точность имеет решающее значение для поддержания целостности данных в финансовых, медицинских и логистических приложениях.
Могут ли VLM обрабатывать различные форматы файлов помимо PDF?
Да, продвинутые инструменты на основе VLM могут обрабатывать различные форматы файлов. Хотя конвертация PDF в CSV является распространенной, эти модели также могут извлекать данные из изображений, документов Word, презентаций PowerPoint и сканированных документов. Эта универсальность делает VLM мощным решением для комплексных потребностей в обработке документов в различных отраслях.
Заключение
Когда вы начинаете использовать языковые модели визуального восприятия для конвертации PDF в CSV, помните, что успех заключается в хорошо структурированном подходе. Реализуя надежную предварительную обработку, точную классификацию документов и тщательную постобработку, вы можете использовать весь потенциал VLM для ваших потребностей в извлечении данных. Независимо от того, работаете ли вы со сложными банковскими выписками, запутанными медицинскими отчетами или детализированными накладными, VLM предлагают мощное решение для преобразования неструктурированных данных в действенные инсайты. Используйте эту передовую технологию, чтобы оптимизировать ваши рабочие процессы, повысить точность данных и открыть новые возможности в обработке документов. С VLM под рукой вы хорошо подготовлены к эффективному и результативному решению даже самых сложных задач конвертации PDF.
Призыв к действию
Давайте двигаться вперед, внедряя эти идеи. Рассмотрите возможность обращения к экспертам в области языковых моделей визуального восприятия, таким как команда AnyParser, чтобы:
- Попробовать AnyParser бесплатно для конвертации вашего PDF в CSV на https://www.cambioml.com/sandbox
- Если вы предпочитаете работу без кода для преобразования большого объема PDF в Excel, посетите https://www.energent.ai
- Получить бесплатную консультацию о том, как VLM могут улучшить ваш рабочий процесс извлечения данных
Использование всей мощи языковых моделей визуального восприятия требует привлечения опыта и лучших практик специалистов по конвертации. Сделайте следующий шаг, связавшись с лидерами отрасли, чтобы ускорить ваш переход к более автоматизированному, точному и информативному процессу извлечения данных.