Конвертация сложных PDF в Markdown может быть сложной задачей. Существует множество библиотек с открытым исходным кодом для извлечения текста из PDF, но когда дело доходит до PDF с такими сложными элементами, как таблицы и графики, результаты часто оказываются неудовлетворительными. Популярные большие языковые модели, такие как GPT или Claude, могут справляться с этими задачами, но, как правило, работают медленно и иногда выдают неточные результаты. Традиционные инструменты OCR, хотя и эффективны для более простых документов, часто испытывают трудности с сохранением точной структуры и семантического значения оригинального контента. С другой стороны, модели, работающие с визуальным языком, иногда выдают ошибочные результаты. Этот блог объяснит, что такое парсинг, и подробно расскажет о результатах сравнительного анализа нескольких моделей с использованием различных метрик.
Что такое парсинг?
В контексте парсинга PDF "парсинг" относится к процессу извлечения конкретных данных из PDF-файла с использованием специализированного программного обеспечения, известного как парсер PDF. Парсер PDF анализирует содержимое PDF-документа и определяет такие элементы, как текст, изображения, шрифты, макеты и даже метаданные. Извлеченные данные затем могут быть организованы и экспортированы в различные форматы, такие как XML, JSON или Excel/CSV, которые могут использоваться для различных целей, таких как анализ данных, ведение записей или автоматизация рабочих процессов.
Понимание того, что такое парсинг, имеет решающее значение для оценки эффективности решения для парсинга, особенно при сравнении различных инструментов конвертации PDF в Markdown, поскольку парсер PDF включает в себя не только простое извлечение текста — он требует распознавания и сохранения семантической структуры документа.
Как мы измеряем качество этих решений для парсинга?
Мы определили ряд метрик на уровне слов для оценки производительности различных моделей, сосредоточив внимание на ключевых факторах, таких как:
-
Точность, полнота и F-меры: Оценка качества и полноты парсинга.
-
Баллы BLEU и ANLS: Полезны для оценки языковой и структурной организации.
-
Расстояние редактирования, дивергенция Дженсена-Шеннона и расстояние Жаккара: Метрики, специфичные для области OCR, особенно полезные для понимания точности воспроизведения контента.
Наша модель, работающая с визуальным языком, AnyParser, демонстрирует исключительную производительность, сочетая скорость и точность, особенно на сложных макетах с таблицами и семантическими элементами. AnyParser превосходит другие решения, обеспечивая улучшение скорости в 20 раз по сравнению с моделями, такими как GPT/Claude, при этом достигая более высокой точности.
Обширный сравнительный анализ с ведущими моделями парсинга
Статистический объект
Чтобы наглядно продемонстрировать возможности AnyParser, мы провели обширное сравнение с ведущими моделями парсинга в отрасли и известными большими языковыми моделями (LLMs). Наша оценка включала:
1. Большие языковые модели
- AnyParser
- GPT-4o от OpenAI
- Gemini 1.5 Pro от Google
- Claude 3.5 Sonnet от Anthropic
2. Сервисы на основе OCR
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Презентация и анализ результатов
Эксперимент 1
Сначала мы провели серию строгих сравнений производительности различных моделей AI для документов по более чем 5 метрикам: BLEU, точность и полнота, F-меры и ANLS. Вы можете найти математическое определение этих метрик в приложении.
Сравниваемые модели: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl и Azure-DocAl.
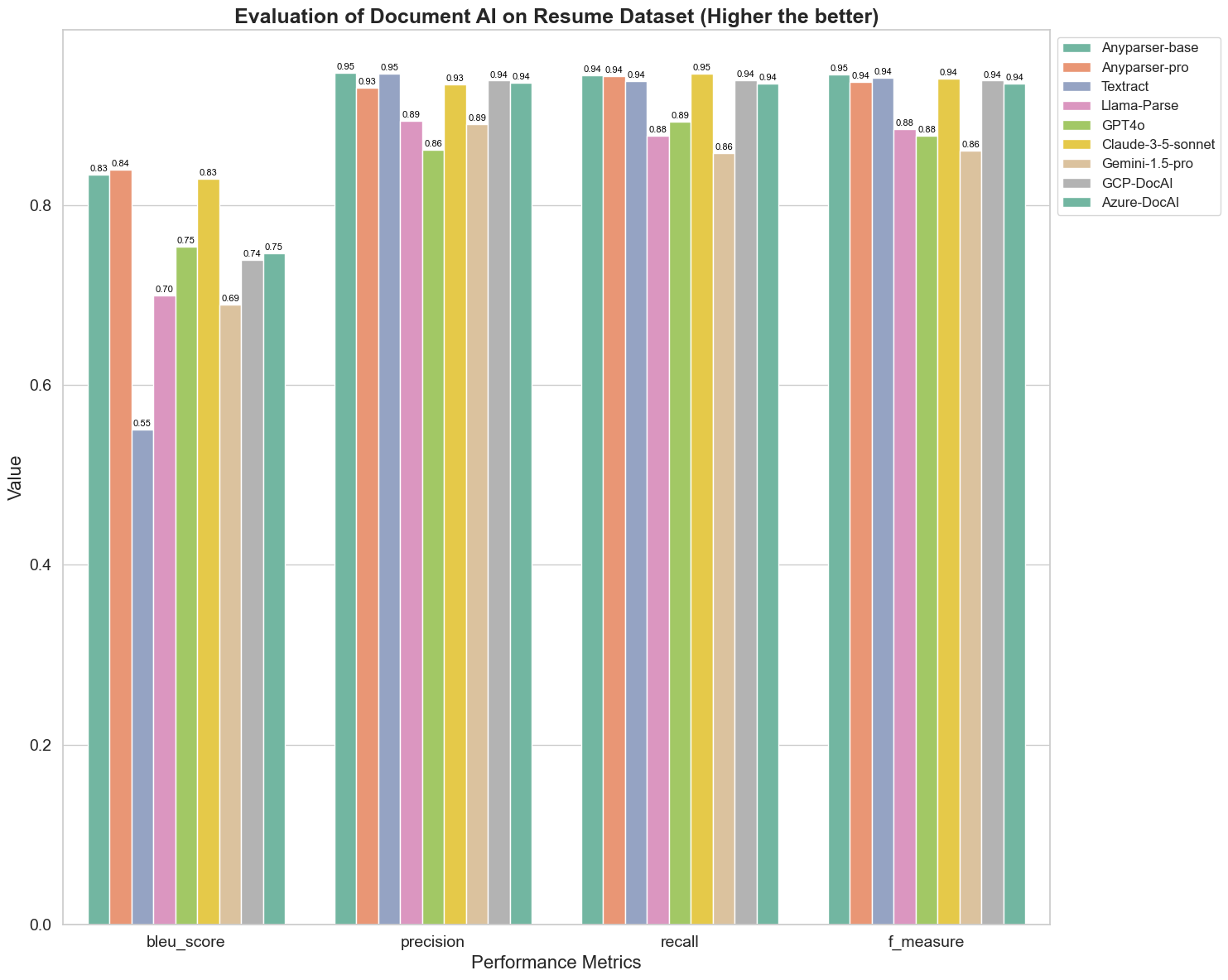
BLEU используется как оценка качества двуязычного перевода для проверки качества моделей в обработке высказываний. Сравнивая результаты этих моделей парсинга по методу оценки BLEU, мы обнаруживаем, что: баллы AnyParser-base и AnyParser-pro значительно выше баллов других моделей, Amazon Textract имеет самый низкий балл, а результаты других моделей находятся на среднем уровне.
Точность распознавания обычно представляется через точность и полноту, где точность представляет собой процент действительно правильных результатов среди результатов, оцененных моделью как правильные, а полнота представляет собой процент действительно правильно оцененных результатов моделью среди всех фактически правильных результатов. Сравнивая точность и полноту этих моделей парсинга, мы обнаруживаем, что: за исключением Llama-Parse, GPT4o и Gemini-1.5-pro, все остальные модели находятся на высоком уровне. Среди них AnyParser и Amazon Textract выделяются по точности, а AnyParser-base и AnyParser-pro выделяются по полноте. Более высокий балл модели по точности указывает на то, что модель выдает больше правильной информации в своих результатах, а более высокий балл по полноте указывает на то, что модель более способна извлекать правильную информацию из образца. Результаты показывают, что AnyParser имеет явное преимущество в точности распознавания для извлечения текста из PDF.
F-меры — это комплексный индекс оценки точности и полноты по этим двум показателям. Сравнивая баллы этих моделей парсинга по F-мере, мы можем более наглядно увидеть, что пять моделей: AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI и Azure-DocAI, имеют лучшие показатели по точности распознавания по сравнению с другими моделями. Мы можем более наглядно увидеть, что пять моделей имеют большее преимущество в точности распознавания, чем другие модели, и AnyParser имеет самый высокий балл по F-мере, что еще раз подчеркивает очевидное преимущество AnyParser в точности распознавания для извлечения текста из PDF.
ANLS, как общепринятый индекс оценки при измерении точности и сходства между оригинальным текстом и целевым текстом на уровне символов, также очень информативен для измерения уровня парсинга моделей. Более высокие баллы AnyParser-base, AnyParser-pro и Azure-DocAI отражают более высокий уровень парсинга этих моделей по сравнению с другими моделями.
В целом, AnyParser-base и AnyParser-pro превосходят другие модели.
Эксперимент 2
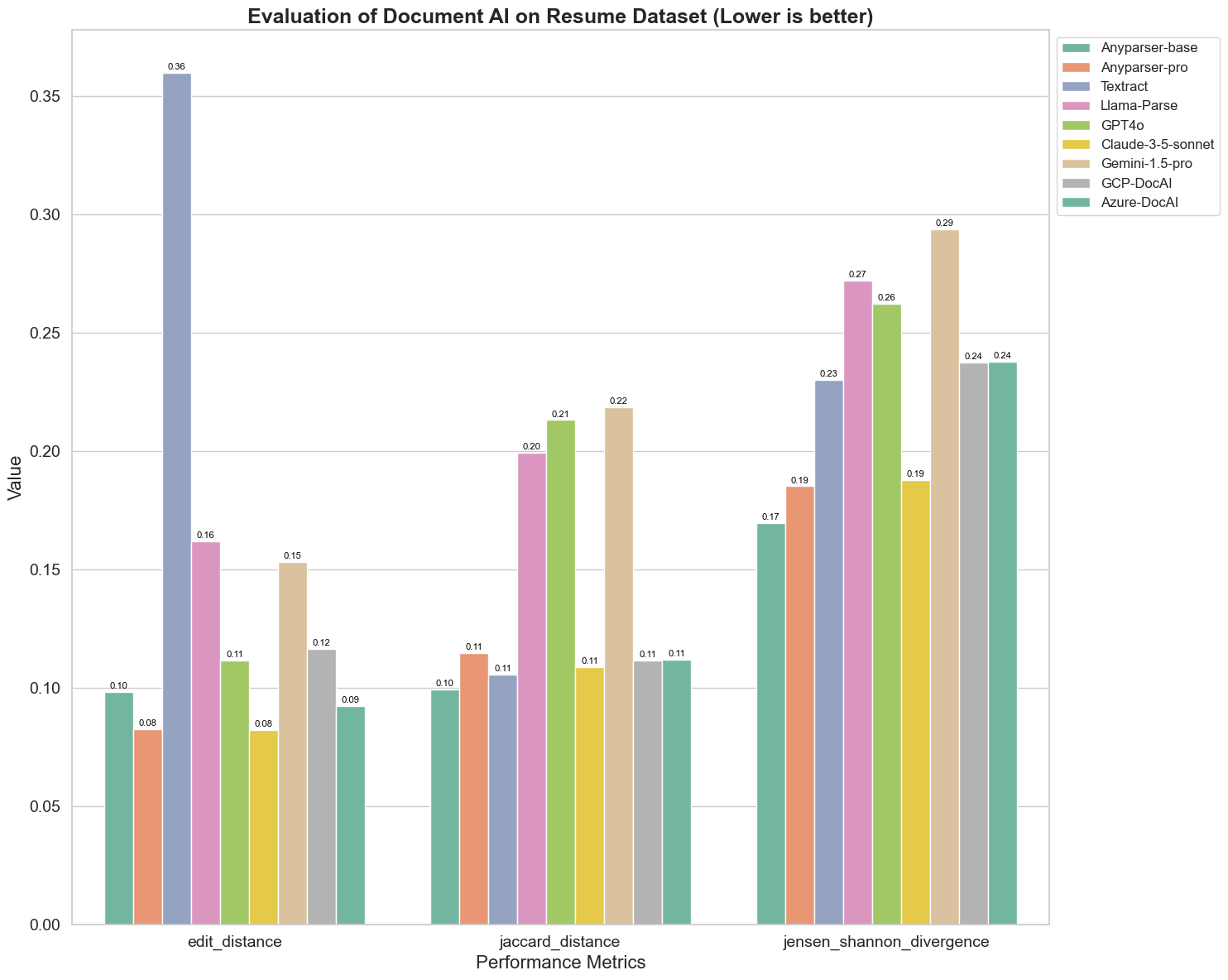
Мы также сравнили производительность различных моделей AI для документов по трем различным метрикам: расстояние редактирования, дивергенция Дженсена-Шеннона и расстояние Жаккара. Метрики используются для измерения сходства между выводами моделей и эталонным документом. Более низкие значения указывают на лучшую производительность.
Вот некоторые ключевые наблюдения из графика:
-
Расстояние редактирования: Модели AnyParser-base и AnyParser-pro показывают лучшие результаты с наименьшим расстоянием редактирования, что указывает на то, что их выводы ближе всего к эталонному документу.
-
Дивергенция Дженсена-Шеннона: Модели AnyParser-base и AnyParser-pro имеют наименьшую дивергенцию, что подразумевает, что их выводы наиболее схожи с эталонным документом по распределению слов.
-
Расстояние Жаккара: За исключением Llama-parse, GPT4O, Gemini-1.5, все остальные модели показывают достойные результаты с наименьшим расстоянием Жаккара, что указывает на то, что их выводы имеют наибольшее совпадение с эталонным документом по набору используемых слов.
Заключение
В целом, наши строгие испытания показывают, что AnyParser-base и AnyParser-pro в целом хорошо работают по различным метрикам, что указывает на их потенциал для точной обработки документов. Из графиков видно, что традиционные модели OCR, такие как известный Amazon Textract, набирают значительно меньше баллов, чем модели визуального языка. Однако производительность различных моделей варьируется в зависимости от используемой метрики, что подчеркивает важность учета нескольких критериев оценки при сравнении моделей AI.
Представляем нашу открытую оценочную платформу
Чтобы упростить оценки, мы создали оценочную платформу, которая предоставляет стандартный метод для сравнения моделей парсинга. В нашем примере мы демонстрируем ее использование в области HR, где парсинг резюме является распространенной практикой. Мы создали разнообразный синтетический набор данных из 128 резюме, сгенерированных с использованием парных файлов изображений и Markdown. Используя GPT-4, мы сгенерировали HTML-контент, отобразили его в виде изображений и использовали извлеченный текст в качестве эталона для сравнения.
И вот лучшая часть: мы открыли этот оценочный фреймворк на GitHub! Независимо от того, являетесь ли вы разработчиком или бизнес-пользователем, наша платформа позволяет вам оценивать и сравнивать качество парсинга различных моделей на вашем собственном наборе данных.
Найдите руководство по быстрому старту в репозитории GitHub и посмотрите, как разные модели парсинга сравниваются друг с другом. Мы верим, что, демонстрируя силу нашей модели открыто, мы можем привлечь больше пользователей, которые хотят надежные, быстрые и точные возможности парсинга.
Приложение - Метрики
1. Точность
Точность измеряет правильность извлеченного контента, показывая, сколько из извлеченных элементов были правильными. В парсинге это доля правильно извлеченных слов из всех извлеченных слов.
Точность = Истинные положительные (TP) / (Истинные положительные (TP) + Ложные положительные (FP))
- Истинные положительные (TP): Слова, правильно определенные парсером.
- Ложные положительные (FP): Слова, неправильно определенные парсером.
2. Полнота
Полнота указывает на полноту парсинга или на то, сколько релевантных слов из оригинального документа было извлечено.
Полнота = Истинные положительные (TP) / (Истинные положительные (TP) + Ложные отрицательные (FN))
- Ложные отрицательные (FN): Слова в оригинальном документе, которые были пропущены парсером.
3. F-меры (F1 Score)
F1 Score — это гармоническое среднее точности и полноты, балансирующее обе метрики для получения общего показателя качества парсинга.
F1 Score = 2 × (Точность × Полнота) / (Точность + Полнота)
4. Балл BLEU (Оценка двуязычного перевода)
Баллы BLEU измеряют сходство между извлеченным контентом и оригинальным текстом, придавая особое значение порядку слов. Это особенно полезно для оценки языковой и структурной согласованности в извлеченных документах, так как он штрафует выводы, которые отличаются по последовательности от оригинала.
5. ANLS (Средняя нормализованная схожесть Левенштейна)
ANLS количественно оценивает сходство между извлеченным контентом и оригиналом, используя нормализованное расстояние редактирования. Он рассчитывается путем усреднения нормализованной схожести Левенштейна (NLS) для каждой пары слов в извлеченных и эталонных текстах. NLS вычисляется следующим образом:
NLS = 1 - (Расстояние Левенштейна (LD)(извлеченное слово, оригинальное слово)) / max(Длина извлеченного слова, Длина оригинального слова)
Затем ANLS — это среднее значение NLS по всем парам слов:
ANLS = (1/N) × Σ(NLS_i) для i=1 до N
6. Расстояние редактирования
Расстояние редактирования вычисляет количество операций на уровне слов (вставок, удалений, замен), необходимых для преобразования извлеченного текста в оригинал.
7. Дивергенция Дженсена-Шеннона
Дивергенция Дженсена-Шеннона измеряет сходство между дискретными распределениями вероятностей извлеченных и оригинальных подсчетов слов, подчеркивая различия в частоте слов.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
где M = (1/2)(P + Q), и KL(P || Q) — это дивергенция Кульбака-Лейблера
8. Расстояние Жаккара
Расстояние Жаккара измеряет несходство между наборами слов в извлеченном и оригинальном контенте, полезно для оценки перекрытия слов.
Расстояние Жаккара = 1 - |A ∩ B| / |A ∪ B|
где |A ∩ B| — это количество общих элементов между A и B,
а |A ∪ B| — общее количество уникальных элементов в обоих наборах.