Модели языкового восприятия (VLM) революционизируют область анализа документов, устраняя многие ограничения, присущие традиционным системам оптического распознавания символов (OCR). Хотя OCR была основополагающей технологией для цифровизации текста из изображений, она сталкивается с серьезными проблемами в сложных сценариях. К ним относятся проблемы точности при работе с изображениями низкого качества, ограниченное понимание контекста, трудности с смешанными языками и неспособность интерпретировать визуальные элементы. VLM предлагают многообещающее решение, сочетая передовое компьютерное зрение с возможностями обработки естественного языка. В этой статье рассматривается, как VLM преодолевают недостатки OCR, предоставляя более надежные и универсальные решения для обработки документов в цифровую эпоху.
Что такое OCR? Каковы процессы OCR в разборе документов?
Оптическое распознавание символов (OCR) — это технология, позволяющая преобразовывать различные типы документов, такие как отсканированные бумажные документы, PDF-файлы или изображения, захваченные цифровой камерой, в редактируемые и поисковые данные. Этот процесс имеет решающее значение для обработки документов и извлечения данных из PDF, позволяя машинам распознавать печатные или рукописные текстовые символы внутри цифровых изображений.
Процесс OCR
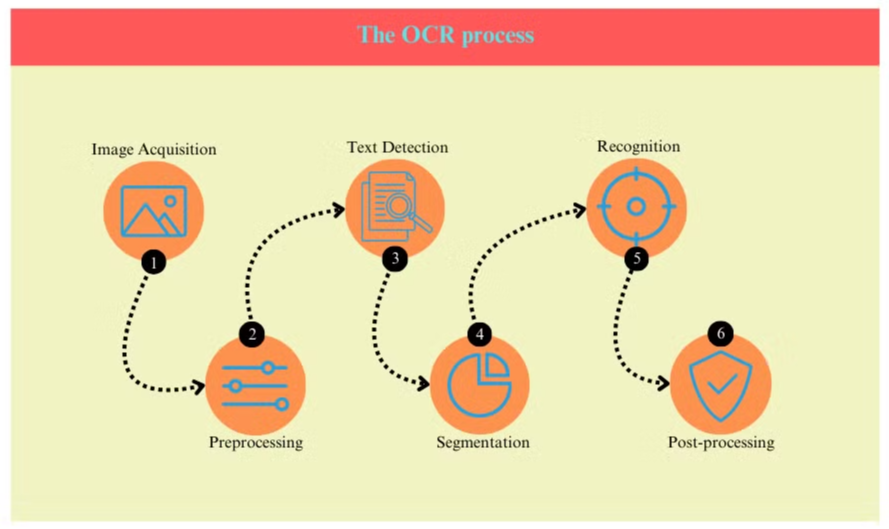
Процесс OCR обычно включает несколько этапов:
- Приобретение изображения: Документ сканируется или фотографируется для создания цифрового изображения.
- Предварительная обработка: Изображение очищается, удаляются шумы и регулируются яркость и контрастность.
- Обнаружение текста: Система идентифицирует области, содержащие текст, в изображении.
- Сегментация символов: Отдельные символы изолируются в текстовых областях.
- Распознавание символов: Каждый символ анализируется и сравнивается с базой данных известных символов.
- Постобработка: Распознанный текст проверяется на наличие ошибок с использованием лингвистической и контекстуальной информации.
Хотя OCR значительно улучшила возможности разбора документов, она по-прежнему сталкивается с ограничениями при работе со сложными макетами, изображениями низкого качества и разнообразными шрифтами. Здесь на помощь приходят такие передовые технологии, как модели языкового восприятия, которые улучшают точность и понимание при извлечении данных из изображений и документов.
Ограничения традиционной технологии OCR
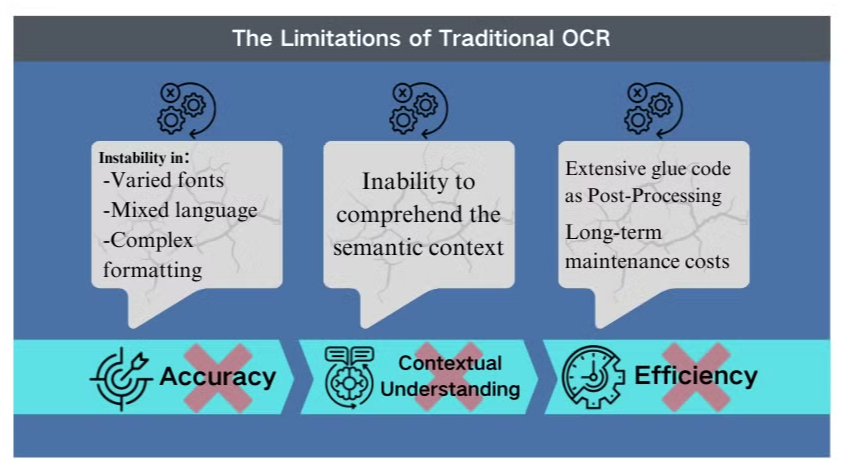
Проблемы точности в сложных сценариях
Традиционная технология оптического распознавания символов (OCR), хотя и полезная для базового извлечения текста, сталкивается с серьезными препятствиями при работе со сложными макетами документов или изображениями низкого качества. Эти системы часто испытывают трудности с поддержанием точности при обработке документов с разнообразными шрифтами, смешанными языками или сложным форматированием. Например, OCR может не справиться с извлечением данных из презентаций с большим количеством изображений или плотно отформатированных PDF-документов.
Отсутствие контекстуального понимания
Одним из самых очевидных ограничений традиционного OCR является его неспособность понимать семантический контекст обрабатываемого текста. Этот недостаток особенно проявляется в сценариях, требующих тонкой интерпретации, таких как юридические контракты или медицинские отчеты. Ориентация OCR на распознавание символов без учета контекста может привести к критическим ошибкам интерпретации, особенно при работе с неоднозначными символами или терминологией, специфичной для отрасли.
Неэффективности в постобработке
Ограничения OCR часто требуют значительных усилий в постобработке. Этот дополнительный этап может значительно увеличить время и ресурсы, необходимые для обработки документов. Более того, традиционные системы OCR обычно не справляются с извлечением информации из графиков, таблиц или других не текстовых элементов, что еще больше усложняет процесс извлечения документов. Эти неэффективности подчеркивают необходимость более продвинутых решений, таких как модели языкового восприятия, которые предлагают более комплексный подход к анализу документов и извлечению данных.
Что такое модели языкового восприятия и как они улучшают OCR
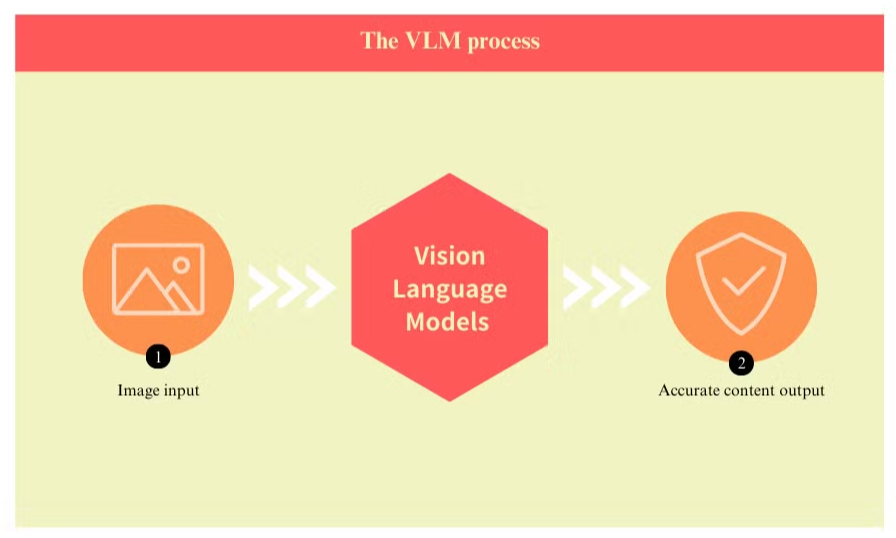
Модели языкового восприятия представляют собой значительный шаг вперед в технологии обработки документов, устраняя многие ограничения, присущие традиционным системам оптического распознавания символов (OCR). Эти передовые модели объединяют компьютерное зрение с обработкой естественного языка, чтобы одновременно понимать как визуальные, так и текстовые элементы документов.
Повышенная точность и понимание контекста
В отличие от OCR, которая испытывает трудности с изображениями низкого качества и сложными макетами, модели языкового восприятия превосходно справляются с интерпретацией различных форматов документов. Они могут точно извлекать данные из изображений, PDF и другого визуального контента, даже сталкиваясь со сложными сценариями. Эта улучшенная точность обусловлена их способностью учитывать весь контекст документа, а не сосредотачиваться исключительно на отдельных символах или словах.
Комплексное извлечение данных
Модели языкового восприятия выходят за рамки простого распознавания текста, предлагая комплексные возможности извлечения данных из PDF. Они могут идентифицировать и интерпретировать таблицы, графики и рисунки в документах, сохраняя целостность сложных макетов. Этот целостный подход к анализу документов позволяет более тонко и полно извлекать информацию, значительно повышая полезность извлеченных данных для последующих приложений.
Многоязычная и многоформатная компетентность
Одним из ключевых преимуществ моделей языкового восприятия является их гибкость в обработке нескольких языков и форматов документов. В отличие от систем OCR, которые могут испытывать трудности с нелатинскими шрифтами или смешанными языковыми документами, эти модели могут без проблем обрабатывать контент на различных языках и шрифтах, что делает их незаменимыми для глобальных потребностей в обработке документов.
Ключевые преимущества моделей языкового восприятия для понимания документов
Модели языкового восприятия предлагают значительные преимущества по сравнению с традиционным OCR для обработки документов и извлечения данных. Эти системы на основе ИИ объединяют визуальное и текстовое понимание, чтобы предоставить превосходные результаты для различных типов документов.
Повышенная точность и контекстуальное понимание
Модели языкового восприятия превосходно справляются со сложными макетами, изображениями низкого качества и разнообразными шрифтами. В отличие от OCR, которая испытывает трудности с неоднозначными символами, эти модели используют контекстуальные подсказки для точной интерпретации текста. Эта способность значительно улучшает точность извлечения данных из PDF, особенно для документов со сложными структурами или плохим качеством изображения.
Комплексный захват информации
В то время как OCR сосредоточена исключительно на распознавании текста, модели языкового восприятия могут извлекать данные из изображений, таблиц и графиков. Этот целостный подход гарантирует, что критически важная информация не будет упущена в процессе обработки документов. Захватывая как текстовые, так и визуальные элементы, эти модели обеспечивают более полное понимание содержания документов.
Многоязычная и многоформатная компетентность
Модели языкового восприятия демонстрируют замечательную гибкость в обработке документов на различных языках и в различных форматах. Они могут без проблем обрабатывать смешанные языковые документы и нелатинские шрифты, преодолевая значительное ограничение традиционных систем OCR. Эта универсальность делает их незаменимыми для глобальных предприятий, работающих с разнообразными типами и языками документов.
Применение в реальном мире, которое обеспечивают VLM, где OCR потерпел неудачу
Модели языкового восприятия революционизируют обработку документов в финансах, управлении человеческими ресурсами и других секторах, устраняя критические ограничения традиционных систем OCR. Эти передовые модели ИИ трансформируют усилия по цифровой трансформации в различных отраслях, предлагая превосходную точность и понимание контекста.
Революция в обработке финансовых документов
Модели языкового восприятия трансформируют обработку документов в финансах, преодолевая ограничения традиционного OCR. Эти передовые модели превосходно извлекают данные из сложных финансовых отчетов, счетов и квитанций с запутанными макетами. В отличие от OCR, они могут понимать контекст, точно интерпретируя неоднозначные символы (например, различать ноль и букву O) и смешанные языки, часто присутствующие в глобальных финансовых документах.
Улучшение операций HR с помощью интеллектуального анализа документов
В секторе HR модели языкового восприятия оказываются незаменимыми для извлечения данных из резюме, кадровых документов и оценок производительности. Эти модели могут понимать семантическую структуру документов, что позволяет более точно извлекать и анализировать информацию. Эта способность значительно упрощает процессы найма и управления данными сотрудников, задачи, в которых OCR часто испытывает трудности с разнообразными форматами и рукописными заметками.
Улучшение соблюдения норм и управления рисками
Модели языкового восприятия особенно эффективны в соблюдении норм и управлении рисками как в финансах, так и в HR. Они могут извлекать и интерпретировать критически важную информацию из нормативных документов, контрактов и политик с большей точностью, чем OCR. Эта улучшенная способность обработки документов обеспечивает лучшее соблюдение юридических требований и более эффективные процедуры оценки рисков.
Заключение
В заключение, модели языкового восприятия представляют собой значительный шаг вперед в технологии обработки документов, устраняя многие присущие ограничения традиционных систем OCR. Объединяя визуальное и текстовое понимание, эти передовые модели предлагают превосходные результаты в широком диапазоне сложных сценариев, от сложных макетов до смешанных языков и изображений низкого качества. По мере того как организации продолжают цифровизировать свои операции и искать более эффективные способы извлечения ценности из своих репозиториев документов, модели языкового восприятия становятся мощным инструментом как для разработчиков, так и для руководителей инженерных команд. Их способность понимать контекст, обрабатывать разнообразные форматы и предоставлять более точные результаты позиционирует их как ключевой фактор для сложных RAG-пайплайнов и возможностей поиска на уровне предприятия, в конечном итоге поднимая инициативы цифровой трансформации на новые высоты.