Вы когда-нибудь задумывались, что означает OCR? Оптическое распознавание символов — это мощная технология, которая преобразует изображения текста в данные, читаемые машиной. Хотя OCR предлагает огромные преимущества для цифровизации документов и извлечения информации, у него есть и недостатки. Изучая эту технологию, важно понимать как ее возможности, так и ограничения. В этой статье вы узнаете значение OCR и погрузитесь в его потенциальные недостатки. Получив полное представление об оптическом распознавании символов, вы сможете лучше определить, стоит ли и как внедрять эту технологию в ваши рабочие процессы и проекты.
Что означает OCR и что такое OCR?
Что означает OCR?
OCR расшифровывается как оптическое распознавание символов — это технология, которая позволяет компьютерам распознавать и преобразовывать различные типы документов. В своей основе OCR — это процесс сканирования напечатанного или рукописного текста и преобразования его в текст, закодированный для машинного восприятия. Это позволяет тексту быть легко доступным для поиска, редактирования и передачи. Понимание того, что означает OCR, имеет важное значение для всех, кто работает с технологиями сканирования документов и распознавания текста.
Что такое OCR?
Для тех, кто не знаком с этим термином, "что такое OCR" — это распространенный вопрос, относящийся к оптическому распознаванию символов, технологии, которая позволяет компьютерам читать текст с изображений или отсканированных документов.
OCR преобразует напечатанный или рукописный текст в данные, читаемые машиной, соединяя бумажные и цифровые форматы. Эта технология использует сложные алгоритмы для определения форм букв, структур слов и даже целых предложений. Таким образом, она преобразует статические изображения в редактируемые и поисковые текстовые файлы.
Технология OCR в основном основана на технологиях компьютерного зрения и распознавания образов. OCR работает, сканируя документы или изображения, содержащие текст, и используя продвинутые алгоритмы для идентификации и преобразования текста в цифровой, редактируемый формат. Одним из ключевых моментов в истории технологии OCR стало 1974 года, когда Рэй Курцвейл разработал систему omni-font OCR, способную распознавать текст практически в любом шрифте. С течением времени OCR эволюционировал от простого сопоставления шаблонов к более сложным системам.
Несмотря на свои возможности, технология OCR в настоящее время сталкивается с определенными ограничениями. К ним относятся трудности в распознавании текста на изображениях низкого качества, сложности в работе с комплексными макетами или фонами и различная точность при работе с разными шрифтами, языками или рукописями. Кроме того, системы OCR могут испытывать трудности с документами, имеющими цветные фоны, размытыми или наклонными изображениями, а также с курсивным почерком.
Понимание программного обеспечения для оптического распознавания символов
Программное обеспечение для оптического распознавания символов — это трансформирующая технология, которая преобразует различные типы документов в редактируемые и поисковые данные. Она играет ключевую роль в цифровизации нашего мира, делая информацию более доступной и управляемой. Программное обеспечение OCR использует сложный процесс для преобразования изображений текста в данные, читаемые машиной.
Как работает программное обеспечение OCR
1. Захват изображения
Путь OCR начинается с захвата изображения документа. Это можно сделать с помощью сканера или цифровой камеры. Затем изображение переводится в цифровой формат, который может обрабатывать компьютер.
2. Предобработка и улучшение изображения
Второй этап включает в себя улучшение качества изображения. После захвата изображение проходит предобработку для улучшения его качества для лучшего распознавания. Этот этап может включать в себя настройку контраста, яркости и четкости изображения, а также удаление шума или несущественных элементов. Эта стадия предобработки имеет решающее значение для достижения точных результатов, особенно при работе с низкокачественными сканами или фотографиями.
3. Обнаружение текста
Программное обеспечение OCR анализирует предобработанное изображение для обнаружения областей, содержащих текст. Оно делает это, ища паттерны и формы, характерные для текста, такие как линии различной толщины и высоты.
4. Сегментация символов
После обнаружения текстовых областей программное обеспечение разбивает текст на более мелкие единицы, такие как блоки, строки, слова или даже отдельные символы. Программное обеспечение OCR анализирует изображение пиксель за пикселем, чтобы идентифицировать паттерны, формирующие символы. Оно разбивает изображение на более мелкие сегменты, изолируя каждый символ.
5. Распознавание и извлечение текста
Затем программное обеспечение сравнивает эти изолированные формы с обширной базой данных известных паттернов символов, чтобы определить, что представляет собой каждый символ. Программное обеспечение извлекает характеристики символов, такие как количество линий, изгибов или углов. Эти характеристики помогают OCR распознавать и различать разные символы.
6. Постобработка
После идентификации символов система OCR проходит через стадию постобработки, на которой исправляет любые потенциальные ошибки и форматирует текст для вывода. Исправленный текст затем экспортируется в нужный формат, такой как документ Word или поисковый PDF.
Примеры использования программного обеспечения для оптического распознавания символов
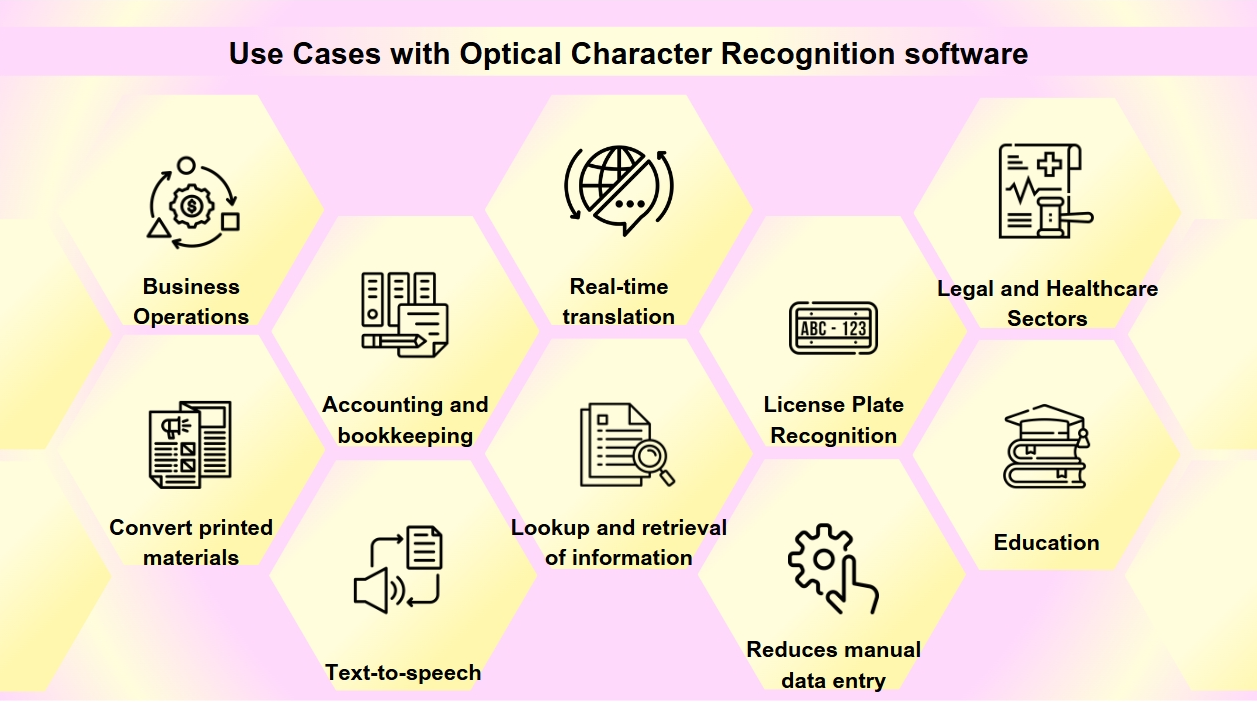
OCR стал незаменимым инструментом в цифровой трансформации многих отраслей, упрощая процессы и улучшая доступность и точность данных. Вы можете столкнуться с OCR чаще, чем думаете. От сканирования визиток до цифровизации старых книг — OCR играет ключевую роль в различных отраслях. Технология OCR имеет широкий спектр применения:
-
Цифровизация документов: OCR используется для преобразования печатных материалов, таких как старые книги, газеты и исторические документы, в цифровые форматы, делая их доступными для поиска и сохраняя их для будущих поколений.
-
Обработка форм: Компании используют OCR для автоматического извлечения данных из форм, что снижает ручной ввод данных и повышает эффективность в различных секторах, таких как финансы и здравоохранение.
-
Обработка счетов: Технология OCR может читать текст на счетах и автоматически вводить данные в финансовые системы, упрощая бухгалтерский и учетный процессы.
-
Доступность: OCR позволяет реализовать функциональность преобразования текста в речь, создавая аудиоверсии текста для людей с нарушениями зрения, тем самым делая печатные материалы более доступными.
-
Мобильные приложения: OCR интегрирован в приложения для выполнения задач, таких как сканирование визиток, распознавание текста на фотографиях и облегчение перевода в реальном времени.
-
Поисковая способность: OCR улучшает поисковую способность отсканированных документов, извлекая текст из изображений или PDF-файлов, что позволяет легко находить и извлекать информацию.
-
Распознавание номерных знаков: Используется для управления парковкой и дорожным движением, OCR может распознавать номерные знаки, обеспечивая эффективный мониторинг и соблюдение правил.
-
Бизнес-операции: OCR упрощает бизнес-процессы, автоматизируя ввод данных из документов, таких как счета, квитанции и заказы на покупку, а также ускоряя набор персонала, сканируя и обрабатывая заявки на работу и резюме.
-
Юридический и медицинский сектора: Юридические фирмы используют OCR для цифровизации дел и юридических документов для облегчения поиска информации, в то время как медицинские учреждения используют его для преобразования медицинских записей и форм в электронные медицинские записи (EMR), улучшая управление данными и уход за пациентами.
-
Образование: В образовательных учреждениях OCR используется для создания цифровых учебников и учебных материалов, улучшая доступность для студентов с различными потребностями и поддерживая инклюзивную образовательную среду.
По мере развития технологии OCR она продолжает играть жизненно важную роль в упрощении доступа к информации и ее эффективному управлению в цифровую эпоху.
Недостатки OCR: Ограничения и недостатки
Проблемы точности
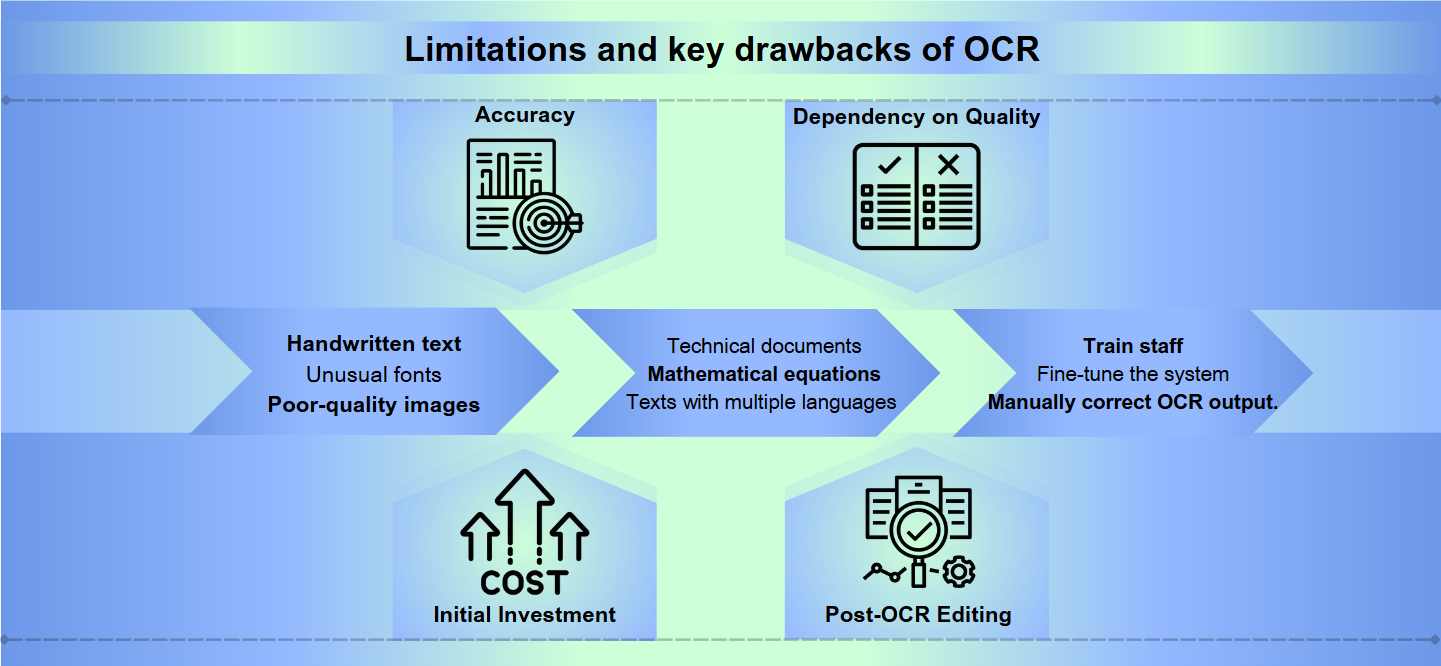
Хотя технология оптического распознавания символов (OCR) достигла значительного прогресса, она все еще сталкивается с серьезными препятствиями на пути к достижению идеальной точности. Рукописный текст, необычные шрифты или изображения низкого качества могут привести к неправильной интерпретации и ошибкам. Даже незначительные вариации в формах или размерах символов могут запутать системы OCR, что приводит к искаженным результатам, требующим ручной коррекции.
Ограничения языков и форматов
Большинство решений OCR отлично работают со стандартными языками и форматами, но испытывают трудности с специализированным контентом. Технические документы, математические уравнения или тексты на нескольких языках могут представлять собой значительные проблемы. Кроме того, OCR может не справляться с комплексными макетами, таблицами или документами с замысловатым форматированием, что может привести к потере важной структурной информации.
Интенсивность ресурсов
Внедрение и поддержание эффективной системы OCR может требовать значительных ресурсов. Высококачественное программное обеспечение OCR часто имеет высокую цену, а оборудование, необходимое для обработки больших объемов документов, может быть дорогостоящим. Более того, время и усилия, необходимые для обучения персонала, настройки системы и ручного просмотра и исправления результатов OCR, могут создать нагрузку на организационные ресурсы.
Основные недостатки OCR
-
Точность: Программное обеспечение OCR может испытывать трудности с точностью, особенно при работе с изображениями низкого качества, сложными макетами или рукописным текстом. Ошибки могут варьироваться от неправильного считывания символов до пропуска целых разделов текста.
-
Зависимость от качества: Эффективность OCR сильно зависит от качества оригинального документа. Иссохшие чернила, размазывания или смятые бумаги могут привести к неточным переводам.
-
Начальные инвестиции: Настройка системы OCR может потребовать значительных первоначальных затрат, включая не только программное обеспечение, но и совместимое оборудование, такое как сканеры.
-
Редактирование после OCR: Часто результаты процессов OCR требуют ручного просмотра и исправления, что может занять много времени.
Модель визуального языка, преодолевающая ограничения OCR
С развитием технологий появляются инновационные решения, направленные на устранение недостатков традиционного оптического распознавания символов (OCR). Одним из таких прорывов является Модель визуального языка (VLM), которая сочетает в себе компьютерное зрение и обработку естественного языка для революционизации извлечения и понимания текста.
Улучшенное контекстуальное понимание
VLM превосходят в понимании контекста, окружающего текст, в отличие от изолированного распознавания символов OCR. Анализируя визуальные элементы наряду с текстом, эти модели могут интерпретировать сложные макеты, рукописные заметки и даже частично закрытый текст с замечательной точностью.
Многоязычные и мультимодальные возможности
В то время как OCR часто испытывает трудности с разнообразными языками и шрифтами, VLM демонстрируют впечатляющую универсальность. Они могут без проблем обрабатывать несколько языков и даже интерпретировать визуальный контент, такой как диаграммы или графики, предоставляя более полное понимание документов.
Адаптивное обучение и постоянное улучшение
В отличие от статических систем OCR, VLM используют машинное обучение для адаптации и улучшения со временем. По мере того как они сталкиваются с новыми данными и сценариями, эти модели совершенствуют свою производительность, становясь все более способными обрабатывать различные типы и форматы документов.
Преодолевая ограничения OCR, Модели визуального языка прокладывают путь к более точной, эффективной и интеллектуальной обработке документов в различных отраслях.
Выбор Модели визуального языка: Попробуйте AnyParser
Основываясь на достижениях Моделей визуального языка (VLM), AnyParser выступает как сложное решение, которое превосходит ограничения традиционной технологии OCR. Разработанный командой CambioML, AnyParser — это мощный инструмент для парсинга документов, который использует точный и настраиваемый API для извлечения информации из различных неструктурированных источников данных, таких как PDF, изображения и графики, преобразуя их в структурированные форматы.
Техническая основа и возможности
AnyParser основан на надежной основе крупных языковых моделей (LLM), обеспечивая высокую точность извлечения текста, таблиц, графиков и макетов из документов. Он выделяется своей способностью сохранять оригинальный макет и формат, что особенно полезно для документов со сложными макетами или требующих сохранения оригинальной эстетики.
Конфиденциальность и безопасность
Подчеркивая конфиденциальность пользователей, AnyParser обрабатывает данные локально, тем самым защищая чувствительную информацию. Эта функция является значительным преимуществом для предприятий и частных лиц, работающих с конфиденциальными данными.
Настраиваемость и гибкость
Предлагая высокий уровень настраиваемости, AnyParser позволяет пользователям устанавливать собственные правила извлечения и определять форматы вывода, которые соответствуют их конкретным потребностям. Эта адаптивность делает его идеальным инструментом для широкого спектра приложений, от AI-инжиниринга до финансового анализа.
Заключение
Как вы узнали, технология OCR предлагает мощные возможности для цифровизации текста, но не без ограничений. Хотя оптическое распознавание символов может значительно повысить эффективность, вы должны тщательно взвесить потенциальные недостатки. Учитывайте проблемы точности, сложности форматирования и требования к ресурсам перед внедрением решения OCR. В конечном итоге решение о использовании OCR зависит от ваших конкретных нужд и обстоятельств. Понимая как преимущества, так и недостатки, вы сможете сделать обоснованный выбор о том, подходит ли OCR для вашей организации. По мере того как OCR продолжает развиваться, следите за новыми разработками, которые могут устранить текущие недостатки и открыть еще больший потенциал этой трансформирующей технологии.
Призыв к действию
Используйте возможности Моделей визуального языка, попробовав AnyParser бесплатно для преобразования ваших PDF в Google Sheets по адресу https://www.cambioml.com/sandbox. Получите бесплатную консультацию о том, как VLM могут улучшить ваш рабочий процесс извлечения данных.