Что такое структурированные и неструктурированные данные
В эпоху цифровой информации данные генерируются в любое время, и предприятия создают ценность через анализ и обработку данных. Поэтому сбор и запись данных, а также их обработка и анализ стали двумя важными задачами в бизнесе. В процессе сбора данных чаще всего встречаются неструктурированные данные, источники и формы которых разнообразны, и их трудно классифицировать или просто искать. Эффективный ввод данных имеет решающее значение для организаций, чтобы эффективно преобразовывать сырые данные в действенные инсайты. В процессе обработки данных чаще встречаются структурированные данные, которые имеют четкую структуру, хорошо определенную информацию и могут быть легко организованы, найдены и проанализированы. Поэтому преобразование неструктурированных данных в структурированные данные является важным шагом для предприятий, чтобы использовать ценность данных.
Структурированные данные
Структурированные данные — это данные, которые вписываются в заранее определенную модель данных или схему. Они особенно полезны для работы с дискретными, числовыми данными, такими как финансовые операции, данные о продажах и маркетинге, а также научное моделирование.
Структурированные данные обычно количественные и организованы таким образом, что их легко искать. Они включают в себя общие типы, такие как имена, адреса, номера кредитных карт, телефонные номера, звездные рейтинги, банковская информация и другие данные, которые можно легко запрашивать с помощью SQL в реляционных базах данных.
Примеры структурированных данных в реальных приложениях включают данные о рейсах и бронировании при покупке билета, а также поведение и предпочтения клиентов в системах CRM, таких как Salesforce. Они лучше всего подходят для связанных коллекций дискретных, коротких, непрерывных числовых и текстовых значений и используются для контроля запасов, систем CRM и ERP-систем.
Структурированные данные хранятся в реляционных базах данных, графовых базах данных, пространственных базах данных, OLAP-кубах и других. Их главное преимущество заключается в том, что их легче организовать, очистить, искать и анализировать, но основная проблема заключается в том, что все данные должны вписываться в предписанную модель данных.
Неструктурированные данные
Неструктурированные данные — это данные без подлежащей модели для различения атрибутов. Они используются, когда данные не могут быть вписаны в структурированный формат, такие как видеонаблюдение, корпоративные документы и сообщения в социальных сетях.
Примеры неструктурированных данных включают в себя различные форматы, такие как электронные письма, изображения, видеозаписи, аудиофайлы, сообщения в социальных сетях, PDF-файлы и многое другое. Примерно 80-90% данных являются неструктурированными, что означает, что они имеют огромный потенциал для конкурентного преимущества, если компании смогут их использовать.
Примеры неструктурированных данных в реальных приложениях включают чат-ботов, выполняющих текстовый анализ для ответа на вопросы клиентов и предоставления информации, а также данные, используемые для прогнозирования изменений на фондовом рынке для инвестиционных решений. Неструктурированные данные лучше всего подходят для связанных коллекций данных, объектов или файлов, где атрибуты меняются или неизвестны, и они используются с программным обеспечением для презентаций или обработки текста и инструментами для просмотра или редактирования медиа. Неструктурированные дополнительные сервисные данные, такие как сообщения в социальных сетях и отзывы клиентов, могут предоставить ценные инсайты при преобразовании в структурированные форматы.
Они обычно хранятся в дата-озерах, NoSQL базах данных, хранилищах данных и приложениях. Главное преимущество неструктурированных данных заключается в их способности анализировать данные, которые трудно преобразовать в структурированные, но основная проблема заключается в том, что их может быть трудно анализировать. Основная техника анализа неструктурированных данных варьируется в зависимости от контекста и используемых инструментов.
Разница между структурированными и неструктурированными данными
Преимущества структурированных данных и недостатки неструктурированных данных
Структурированные данные предлагают преимущество легкости поиска и использования для алгоритмов машинного обучения, что делает их доступными для бизнеса и организаций для интерпретации данных. Также доступно больше инструментов для анализа структурированных данных, чем для неструктурированных. С другой стороны, неструктурированные данные требуют от специалистов по данным экспертизы в подготовке и анализе данных, что может ограничить доступ других сотрудников в организации. Кроме того, для работы с неструктурированными данными требуются специальные инструменты, что дополнительно способствует их недоступности.
Аналитика структурированных данных против аналитики неструктурированных данных
Аналитика структурированных данных обычно более проста, поскольку данные строго отформатированы, что позволяет использовать программную логику для поиска и нахождения конкретных записей, а также для создания, удаления или редактирования записей. Это делает автоматизацию управления данными и анализа структурированных данных более эффективной. В отличие от этого, аналитика неструктурированных данных не имеет предопределенных атрибутов, что делает ее более сложной для поиска и организации. Аналитика неструктурированных данных часто требует сложных алгоритмов для предварительной обработки, манипуляции и анализа, что представляет собой большую проблему в процессе анализа. Анализ неструктурированных дополнительных сервисных данных часто требует продвинутых техник парсинга для извлечения значимой информации.
Управление структурированными данными против управления неструктурированными данными
Управление структурированными данными, как правило, более эффективно благодаря их организованной и предсказуемой природе. Компьютеры, структуры данных и языки программирования могут легче понимать структурированные данные, что приводит к минимальным проблемам в их использовании. Напротив, управление неструктурированными данными представляет собой две значительные проблемы: хранение, так как управление неструктурированными данными, как правило, сталкивается с большими объемами обработки, чем управление структурированными данными, и анализ, так как управление неструктурированными данными не так просто, как анализ структурированных данных. Чтобы понять и управлять неструктурированными данными, компьютерные системы сначала должны разбить их на понятные компоненты, что является более сложным процессом.
Резюме различий между структурированными и неструктурированными данными
Структурированные данные определены и поддаются поиску, включая такие данные, как даты, номера телефонов и SKU продуктов. Это делает их легче организовать, очистить, искать и анализировать по сравнению с неструктурированными данными, которые охватывают все остальное, что труднее классифицировать или искать, такие как фотографии, видео, подкасты, сообщения в социальных сетях и электронные письма. Одно предложение, чтобы объяснить разницу между структурированными и неструктурированными данными: Большая часть данных в мире является неструктурированной, но легкость управления и анализа структурированных данных дает им значительное преимущество в приложениях, где данные могут быть аккуратно организованы и быстро доступны.
Примеры структурированных и неструктурированных данных
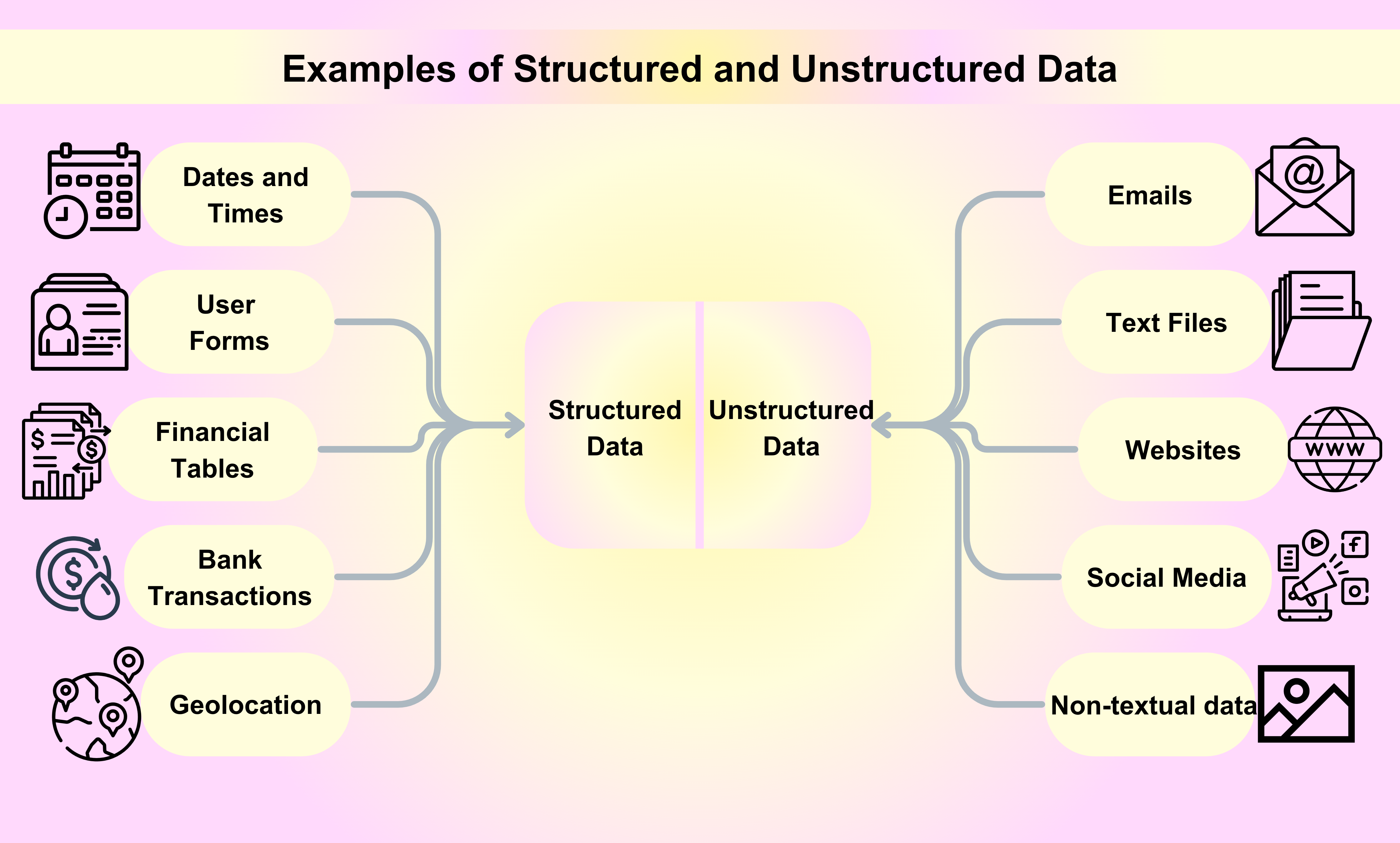
Примеры структурированных данных
-
Даты и Время: Даты и время следуют определенному формату, что облегчает их чтение и анализ машинами. Например, дату можно структурировать как YYYY-MM-DD, а время как HH:MM:SS.
-
Имена клиентов и контактная информация: Когда вы подписываетесь на услугу или покупаете продукт онлайн, ваше имя, адрес электронной почты, номер телефона и другая контактная информация собираются и хранятся в структурированном виде.
-
Финансовые транзакции: Финансовые транзакции, такие как транзакции по кредитным картам, банковские депозиты и денежные переводы, являются примерами структурированных данных. Каждая транзакция имеет конкретную информацию в виде серийного номера, даты транзакции, суммы и участвующих сторон.
-
Информация о акциях: Информация о акциях, такая как цены на акции, объемы торгов и рыночная капитализация, является еще одним примером структурированных данных. Эта информация систематически организована и обновляется в реальном времени.
-
Геолокация: Данные геолокации, включая GPS-координаты и IP-адреса, часто используются в различных приложениях, от навигационных систем до маркетинговых кампаний на основе местоположения.
Примеры неструктурированных данных
-
Электронные письма: Электронные письма являются одним из самых популярных примеров неструктурированных данных, которые мы используем каждый день для бизнеса или личных целей.
-
Текстовые файлы: Примеры неструктурированных данных включают файлы обработки текста, электронные таблицы, PDF-файлы, отчеты и презентации.
-
Веб-сайты: Содержимое веб-сайтов, таких как YouTube, Instagram и Flickr, считается примером неструктурированных данных.
-
Социальные медиа: Данные, генерируемые на платформах социальных медиа, таких как Facebook, Twitter и LinkedIn, являются примером неструктурированных данных.
-
Медиа: Цифровые изображения, аудиозаписи и видео представляют собой огромное количество нетекстовых данных в неструктурированном виде, которые можно рассматривать как примеры неструктурированных данных.
Техники анализа структурированных данных
-
SQL-запросы: Структурированные данные можно эффективно запрашивать с помощью SQL (Structured Query Language), что позволяет быстро извлекать и манипулировать данными, хранящимися в реляционных базах данных.
-
Хранилища данных: Структурированные данные могут храниться в хранилищах данных, которые интегрируют данные из нескольких источников и поддерживают сложные запросы и анализ.
-
Алгоритмы машинного обучения: Алгоритмы могут легко обрабатывать структурированные данные для выявления паттернов и прогнозирования.
Структурированные данные легко понимать и манипулировать, что делает их доступными для широкого круга пользователей. Структурированные данные позволяют эффективно хранить, извлекать и анализировать, что ускоряет процессы принятия решений. Системы структурированных данных могут масштабироваться для обработки больших объемов данных, обеспечивая высокую производительность по мере роста данных.
Техники анализа неструктурированных данных
-
Обработка естественного языка (NLP): Техники NLP используются для анализа текстовых данных, извлекая значимую информацию и инсайты из больших объемов неструктурированного текста.
-
Машинное обучение: Алгоритмы машинного обучения могут быть обучены распознавать паттерны в неструктурированных данных, таких как изображения или аудиофайлы.
-
Дата-озера: Неструктурированные данные могут храниться в дата-озерах, которые позволяют хранить сырые данные в их исходном формате до тех пор, пока они не понадобятся для анализа.
Из примера техник анализа неструктурированных данных видно, что анализ неструктурированных данных более сложен и требует специализированных инструментов и техник. Обработка неструктурированных данных часто требует значительных вычислительных ресурсов и емкости для хранения. Неструктурированные данные могут содержать несоответствия, ошибки или неуместную информацию, что делает сложным обеспечение качества данных. Оптимизация ввода данных может значительно улучшить способность организации управлять и анализировать большие объемы данных.
Примеры необходимости преобразования неструктурированных данных в структурированные данные
-
Анализ отзывов клиентов: Преобразование отзывов и комментариев клиентов из неструктурированного текста в структурированные данные позволяет компаниям проводить анализ настроений и выявлять тенденции в удовлетворенности клиентов.
-
Медицинские записи: Структурирование неструктурированных медицинских записей, таких как заметки врачей и отчеты по изображениям, позволяет лучше интегрироваться с системами электронных медицинских записей (EHR) и улучшает качество обслуживания пациентов.
-
Соблюдение норм и отчетность: Процесс ввода данных включает извлечение, загрузку и преобразование данных из различных источников в формат, подходящий для анализа. Организациям может потребоваться преобразовать неструктурированные данные в структурированные форматы для соблюдения нормативных требований и облегчения точной отчетности.
-
Маркетинговые исследования: Преобразование неструктурированных данных из опросов и фокус-групп в структурированные данные помогает в анализе рыночных тенденций и поведения потребителей.
Как AnyParser может парсить неструктурированные данные в структурированные данные
AnyParser, разработанный CambioML, является мощным инструментом парсинга документов, предназначенным для извлечения информации из различных источников неструктурированных данных, таких как PDF-файлы, изображения и диаграммы, и преобразования их в структурированные форматы. Он использует передовые модели языкового зрения (VLM) для достижения высокой точности и эффективности в извлечении данных.
Ключевые особенности
-
Точность: Точно извлекает текст, числа и символы, сохраняя оригинальную компоновку и формат.
-
Конфиденциальность: Обрабатывает данные локально, чтобы обеспечить защиту конфиденциальности пользователей и чувствительной информации.
-
Настраиваемость: Позволяет пользователям определять собственные правила извлечения и форматы вывода.
-
Поддержка нескольких источников: Поддерживает извлечение из различных источников неструктурированных данных, включая PDF-файлы, изображения и диаграммы.
-
Структурированный вывод: Преобразует извлеченную информацию в структурированные форматы, такие как Markdown, CSV или JSON.
Шаги для парсинга неструктурированных данных с помощью AnyParser
-
Загрузите ваш документ: Начните с загрузки вашего файла неструктурированных данных (например, PDF, изображение) в веб-интерфейс AnyParser. Вы можете перетащить файл или вставить скриншот для быстрого процесса.
-
Выберите параметры извлечения: Выберите тип данных, которые вы хотите извлечь. Например, если вам нужно извлечь таблицы из PDF, выберите опцию "Только таблица".
-
Обработайте документ: API-движок AnyParser обработает документ, точно определяя и извлекая необходимую информацию. Инструмент использует передовые техники VLM для выявления релевантных точек данных и преобразования их в структурированный формат.
-
Предварительный просмотр и проверка: Просмотрите извлеченные данные с помощью функции предварительного просмотра AnyParser. Сравните первоначальное извлечение с оригинальным документом для обеспечения точности.
-
Скачайте или экспортируйте: После того как вы удовлетворены извлечением, скачайте файл структурированных данных (например, CSV, Excel) или экспортируйте его напрямую на платформы, такие как Google Sheets, для дальнейшего анализа.
Преимущества использования AnyParser
-
Эффективность и точность: Автоматизирует задачи извлечения данных, снижая ручные усилия и минимизируя ошибки.
-
Безопасность данных: Обеспечивает обработку чувствительной информации локально, соблюдая стандарты конфиденциальности данных.
-
Гибкая настройка: Пользователи могут адаптировать параметры извлечения и форматы вывода под конкретные нужды.
-
Улучшенный аналитический фокус: Упрощает извлечение данных, позволяя профессионалам сосредоточиться на более ценных анализах.
Применения
-
AI-инженеры: Извлекают текст и информацию о компоновке из PDF-файлов для разработки и обучения AI-моделей.
-
Финансовые аналитики: Извлекают числовые данные из таблиц PDF для точного финансового анализа.
-
Специалисты по данным: Обрабатывают большие объемы неструктурированных документов для выявления инсайтов и тенденций.
-
Предприятия: Автоматизируют обработку и анализ различных документов, таких как контракты и отчеты, для повышения операционной эффективности.
Используя AnyParser, пользователи могут преобразовать сложные неструктурированные данные в структурированные, редактируемые файлы, бесшовно интегрируя их в свои рабочие процессы для улучшенного анализа и управления данными.
Заключение
В цифровую эпоху преобразование неструктурированных данных в структурированные форматы с помощью инструментов, таких как AnyParser, имеет решающее значение для бизнеса, чтобы раскрыть инсайты и получить конкурентное преимущество. AnyParser может быть использован для парсинга неструктурированных дополнительных сервисных данных, что упрощает их интеграцию в системы бизнес-аналитики. Оптимизируя этот процесс, организации могут эффективно использовать весь потенциал своих данных, что способствует лучшему принятию решений и стратегическому планированию.