Introduktion
Tabeller är en hörnsten i strukturerad datarepresentation och används i stor utsträckning inom branscher som finans, hälsovård och forskning. Att extrahera tabulär information från format som PDF, skannade dokument eller bilder är dock en utmaning på grund av varierande layouter och komplexiteter.
Artificiell intelligens (AI) har revolutionerat dokumentbearbetning och möjliggjort exakta och effektiva lösningar på problem som hur man extraherar en tabell från en PDF eller konverterar en tabell-PNG till strukturerad data. Genom att utnyttja avancerade AI-tekniker kan företag nu enkelt omvandla ostrukturerade visuella element till handlingsbara insikter, inklusive att konvertera en bild till en tabell för sömlös integration i arbetsflöden.
Denna blogg utforskar hur AI-tabellutvinning stärker industrier, belyser de underliggande teknologierna och visar dess potential att förenkla komplexa dokumentbearbetningsuppgifter.

Utmaningar med Traditionell Tabellutvinning
Att manuellt extrahera tabulär data från dokument som PDF eller bilder är tidskrävande, felbenäget och ineffektivt. Nedan följer några av de vanliga utmaningarna med traditionella metoder:
-
Komplexa Tabellstrukturer: Tabeller har ofta oregelbundna layouter, såsom nästlade celler, fleradiga rubriker eller sammanslagna rader, vilket gör dem svåra att tolka. Traditionella verktyg misslyckas med att exakt extrahera tabeller från PDF i sådana scenarier.
-
Mångfaldiga Format: Tabeller förekommer i en mängd olika format, inklusive skannade dokument, tabell-PNG-filer och PDF:er. Att extrahera data från dessa kräver avancerade igenkänningstekniker som går bortom enkel OCR.
-
Kontext och Betydelse: Traditionella system har svårt att bevara relationerna mellan rader och kolumner, vilket är avgörande när man konverterar en bild till tabell eller bearbetar stora datamängder.
Dessa utmaningar betonar behovet av intelligenta lösningar som AI-driven tabellutvinning, som kan hantera komplexa layouter och mångfaldiga format samtidigt som hög noggrannhet säkerställs.
Vad är AI Tabellutvinning?
AI-tabellutvinning är tillämpningen av intelligenta dokumentbearbetningstekniker som är skräddarsydda för att identifiera, extrahera och organisera strukturerad data från tabeller i olika dokumentformat. Till skillnad från traditionella regelbaserade metoder utnyttjar AI-drivna tillvägagångssätt avancerade teknologier för att hantera komplexa utmaningar, såsom icke-standardiserade layouter, sammanslagna celler och fleradiga rubriker.
En viktig framsteg inom detta område är användningen av Vision-Language Models (VLMs). VLMs kombinerar styrkorna hos datorseende och förståelse av naturligt språk, vilket gör att de kan tolka både visuella och textuella element inom ett dokument. Denna dubbla kapabilitet gör att VLMs kan:
- Identifiera tabellstrukturer visuellt, även när de saknar tydlig formatering.
- Kontextuellt förstå innehållet, såsom att särskilja mellan rubriker, data och anteckningar.
- Anpassa sig till olika dokumenttyper, inklusive skannade bilder, PDF:er och handskrivna anteckningar.
Genom att utnyttja VLMs har AI-tabellutvinning blivit mer exakt och mångsidig, kapabel att hantera flerspråkiga dokument och extrahera relationer mellan datapunkter som traditionella metoder ofta missar.
Nyckelteknologier bakom AI Tabellutvinning
AI-tabellutvinning bygger på en uppsättning avancerade teknologier som arbetar i harmoni för att övervinna traditionella utmaningar. Bland dessa utmärker sig Vision-Language Models (VLMs) som en transformativ innovation. Här är en sammanställning av nyckelteknologier och den avgörande rollen för VLMs:
-
Optisk Teckenigenkänning (OCR): Extraherar text från bilder eller skannade dokument. När den kombineras med VLMs förbättras OCR-resultaten eftersom modellerna förstår både den visuella strukturen och den textuella betydelsen.
-
Vision-Language Models (VLMs): VLMs revolutionerar tabellutvinning genom att integrera visuell och språklig databehandling. De excellerar i:
- Att känna igen komplexa tabellayouts och oregelbundna gränser.
- Att tolka relationer mellan rader, kolumner och rubriker.
- Att hantera tabeller i olika format, inklusive bilder och PDF:er, med flerspråkigt stöd. VLMs möjliggör en djupare kontextuell förståelse, vilket säkerställer att den extraherade datan behåller sin ursprungliga betydelse och struktur.
-
Naturlig Språkbehandling (NLP): Analyserar och organiserar den extraherade datan, vilket säkerställer semantisk koherens. VLMs förbättrar ytterligare NLP genom att tillhandahålla kontextuella ledtrådar från visuella mönster.
-
Djupinlärningsalgoritmer: Tränar modeller för att upptäcka tabellgränser, cellhierarkier och mönster i ostrukturerade dokument. När de berikas av VLMs uppnår dessa algoritmer större precision och anpassningsförmåga.
Genom att betona VLMs har AI-tabellutvinning flyttat från en uppgift av enkel datainsamling till en av kontextualiserad förståelse, vilket gör den ovärderlig för industrier där noggrannhet och nyans är avgörande.
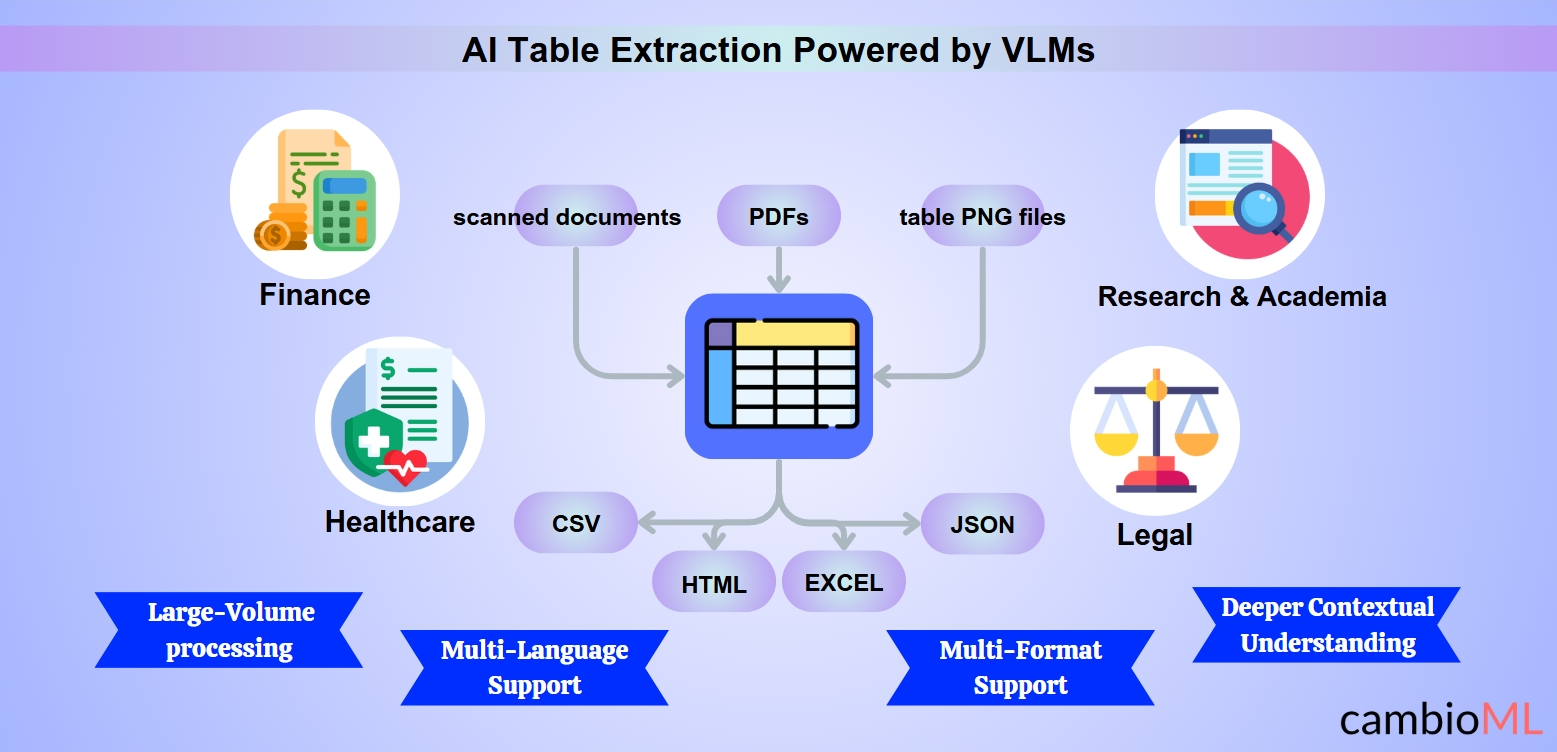
Användningsfall för AI Tabellutvinning
AI-driven tabellutvinning omvandlar industrier genom att automatisera processen att extrahera och organisera tabulär data från olika dokumentformat. Här är några anmärkningsvärda användningsfall där intelligent tabellutvinning har visat sig ovärderlig:
-
Finans: Att extrahera strukturerad data från finansiella rapporter, fakturor och redovisningar är ofta en arbetsintensiv uppgift. AI gör det sömlöst att kopiera PDF-tabeller till Excel, vilket möjliggör snabbare avstämning, analys och rapportering.
-
Hälsovård: Att organisera kliniska prövningsresultat, patientjournaler eller medicinska forskningsdata förenklas. Till exempel kan vårdgivare enkelt kopiera tabeller från PDF till Excel, vilket säkerställer att datan är redo för integration i elektroniska journaler (EHR-system).
-
Juridik: Att analysera kontrakt och extrahera strukturerade klausuler från nästlade tabeller hjälper juridiska team att arbeta mer effektivt. AI-modeller gör det enkelt att kopiera PDF-tabeller till Excel, vilket sparar tid på efterlevnadskontroller och rättslig forskning.
-
Forskning och Akademi: Forskare kan snabbt extrahera data från vetenskapliga artiklar, vilket förenklar uppgiften att överföra nyckelmått genom att använda verktyg för att kopiera tabeller från PDF till Excel, vilket gör datamängder redo för statistisk analys.
AI-tabellutvinningens förmåga att exakt bearbeta olika dokumentformat revolutionerar arbetsflöden, vilket gör det enklare att kopiera, organisera och analysera tabulär data i Excel-ark.
Fördelar med Intelligent Tabellutvinning
AI-tabellutvinning erbjuder en mängd fördelar, särskilt när det gäller att förbättra effektivitet, noggrannhet och skalbarhet. Genom att utnyttja avancerade teknologier, inklusive Vision-Language Models (VLMs), kan företag övervinna traditionella utmaningar inom tabellutvinning:
-
Automatisering och Tidsbesparingar: Repetitiva uppgifter som att manuellt kopiera tabeller från PDF till Excel elimineras, vilket gör att anställda kan fokusera på mer värdefulla aktiviteter.
-
Förbättrad Noggrannhet: AI-modeller minskar avsevärt fel som är vanliga när användare manuellt kopierar PDF-tabeller till Excel eller förlitar sig på grundläggande verktyg. Dessa modeller säkerställer att datan behåller sin struktur och betydelse.
-
Skalbarhet för Storskalig Bearbetning: AI-verktyg är utformade för att hantera bulkdatautvinning. Oavsett om det handlar om finansiella poster, forskningsdokument eller efterlevnadsfiler, förenklar de processen att extrahera och organisera data i Excel.
-
Stöd för Flera Format och Språk: Intelligenta system kan bearbeta dokument i olika format och språk, vilket möjliggör sömlös extraktion och kopiering av tabeller från PDF till Excel även i komplexa, flerspråkiga sammanhang.
AI-tabellutvinning strömlinjeformar inte bara arbetsflöden utan säkerställer också datans kontextuella integritet, vilket förändrar hur industrier hanterar tabulär information. Denna effektivitet är avgörande i dagens datadrivna värld, där snabb och exakt bearbetning av tabulär data är en konkurrensfördel.
Hantering av Utmaningar med Flera Format och Språk
Moderna AI-lösningar excellerar i att hantera variabiliteten av format och språk, vilket säkerställer konsekvent noggrannhet och effektivitet över olika datamängder:
-
Kapabiliteter för Flera Format: AI-drivna verktyg kan utan ansträngning bearbeta PDF:er, skannade dokument och bildfiler som tabell-PNG. Denna mångsidighet är särskilt kritisk när användare behöver extrahera tabeller från PDF eller konvertera en bild till tabell för analys och rapportering.
-
Stöd för Flera Språk: AI-modeller tränas på flerspråkiga datamängder, vilket gör att de kan hantera dokument på olika språk. Denna funktion är ovärderlig för globala industrier som hanterar internationell dokumentation.
-
Bevarande av Datarelationer: Oavsett om man bearbetar en bild till tabell eller extraherar en komplex struktur från en PDF, säkerställer AI-system att rubriker, rader och kolumner bevaras, vilket upprätthåller datans integritet.
Genom att hantera dessa utmaningar har AI-lösningar etablerat sig som oumbärliga verktyg för organisationer som hanterar storskalig, flerspråkig och flerformatdokumentation.
Framtiden för AI inom Tabellutvinning
Framtiden för AI-tabellutvinning ser ljus ut, med framsteg som kommer att ytterligare förbättra dess kapabiliteter:
-
Förbättrade Vision-Language Models (VLMs): Framväxande VLM-teknologier kommer att erbjuda ännu mer sofistikerade sätt att extrahera tabeller från PDF och konvertera komplexa tabell-PNG-format till strukturerad data. Dessa modeller kommer att överbrygga klyftan mellan visuella element och textuell förståelse.
-
Integration med Generativ AI: Genom att integrera generativ AI kan framtida lösningar inte bara extrahera tabeller från PDF eller bilder utan också analysera den extraherade datan för insikter, sammanfattningar och rekommendationer.
-
End-to-End Automatisering: AI-drivna verktyg kommer att strömlinjeforma arbetsflöden genom att automatiskt konvertera filer, såsom att omvandla en bild till tabell, kategorisera datan och mata in den direkt i analyspipelines.
-
Bredare Tillgänglighet: AI-system kommer att bli mer användarvänliga och tillgängliga, vilket gör att även icke-tekniska användare kan bearbeta tabell-PNG-filer eller extrahera data utan ansträngning.
AI-tabellutvinning är redo att omdefiniera dokumentbearbetning, vilket gör datautvinning snabbare, smartare och mer anpassningsbar till föränderliga branschbehov. Företag som antar dessa lösningar kommer att få en konkurrensfördel i att effektivt hantera och utnyttja sin data.
AnyParser: En Spelväxlare inom Dokumentbearbetning och Tabellutvinning
AnyParser ligger i framkant av intelligent dokumentbearbetning och erbjuder företag ett effektivt och pålitligt sätt att extrahera data från även de mest komplexa dokumenten. Dess avancerade kapabiliteter är särskilt tydliga när det gäller tabellutvinning, vilket säkerställer exakt och skalbar datainsamling för olika industrier.
Nyckelfördelar med AnyParser för Tabellutvinning
-
Omfattande Formatstöd: Oavsett om det handlar om PDF:er, bilder eller andra filtyper, förenklar AnyParser datainsamlingen genom att noggrant extrahera tabulär information oavsett format.
-
Hög Precision och Kontextuell Förståelse: Till skillnad från traditionella verktyg bevarar AnyParser strukturen, relationerna och kontexten av tabulär data, vilket ger resultat som är redo för analys och integration.
-
AI-Drivna Effektivitet: Drivet av Vision-Language Models (VLMs) excellerar AnyParser i flerspråkiga och flerformatmiljöer, vilket säkerställer sömlös datainsamling i stor skala.
-
Anpassningsbara Arbetsflöden: Plattformen anpassar sig till dina unika behov, oavsett om du extraherar finansiella tabeller, hälsovårdsregister eller forskningsdata.
Med AnyParser kan företag optimera sina processer, minimera fel och spara tid genom att automatisera den komplexa uppgiften att extrahera tabeller för strukturerad datainsamling.
Slutsats
AI-driven tabellutvinning har omdefinierat hur företag bearbetar och utnyttjar strukturerad data. Oavsett om uppgiften är att extrahera tabeller från PDF:er, bearbeta bilder eller uppnå exakt datainsamling, gör verktyg som AnyParser det enklare än någonsin att omvandla ostrukturerade dokument till handlingsbara insikter. AnyParser är din pålitliga lösning för att förenkla dokumentbearbetning och leverera oöverträffad noggrannhet och effektivitet. Med sin förmåga att hantera olika format och kontexter möjliggör AnyParser organisationer att automatisera sina arbetsflöden och låsa upp den fulla potentialen av sin data.
Call to Action
Varför vänta med att uppleva nästa nivå av dokumentbearbetning? Lås upp den fulla potentialen av AnyParser genom att prova dess funktioner i en praktisk miljö!
Klicka på länken nedan för att gå in i Sandbox, där du kan utforska hur det förenklar:
- Exakt datainsamling från PDF:er och bilder.
- Sömlös extraktion av tabeller för integration i analysverktyg.
- Pålitlig prestanda över komplexa och stora datamängder.
Missa inte chansen att se hur AnyParser kan revolutionera dina arbetsflöden. Testa det idag och upptäck hur enkelt dokumentbearbetning och tabellutvinning kan vara!