Inom datamanagement innebär parsing att konvertera innehållet—såsom text, bilder, tabeller och metadata—till ett användbart format (t.ex. ren text, strukturerad data eller bilder) som kan bearbetas eller analyseras vidare. Inget är detta mer uppenbart än inom PDF-parsing, gå in i parsingens värld, en avgörande process som omvandlar rå information till strukturerad, användbar data. Denna omfattande guide dyker ner i intrikaterna av PDF-parsing, förklarar dess definition, spektrumet av data den kan extrahera, de hinder den möter, dess mångfacetterade tillämpningar och det överflöd av metoder som finns tillgängliga för att utnyttja dess fulla potential. Du kommer att utforska olika parsingmetoder, med särskilt fokus på PDF-parsing och hur verktyg som AnyParser står ut från mängden.
Förstå PDF Parser: Vad är Parsing?
Vad är parsing: noggrann datainsamlingsprocess
I sin kärna hänvisar PDF-parsing till processen att extrahera och tolka data från PDF (Portable Document Format) filer. Eftersom PDF-filer är designade främst för visning snarare än strukturerad datalagring, innebär parsing att konvertera innehållet—såsom text, bilder, tabeller och metadata—till ett användbart format (t.ex. ren text, strukturerad data eller bilder) som kan bearbetas eller analyseras vidare. Parsing innebär en hög nivå av analys för att pinpointa och hämta specifika element inom en PDF, vilket sträcker sig bortom enbart text och bilder för att omfatta typsnitt, layouter, tabeller och metadata. Denna process är inte bara en teknikalitet utan en nödvändighet inom branscher så olika som finans, juridik, logistik och hälsovård, där omvandlingen av information är avgörande.
Data som kan parsas från PDF-filer
Den data som kan extraheras från PDF-filer är varierad och omfattande, inklusive:
-
Textstycken: Sekvenser av ord och tecken.
-
Enskilda datafält: Individuella element såsom datum, spårningsnummer och namn.
-
Tabulär data: Information organiserad i tabeller och listor.
-
Bilder: Grafiskt innehåll inbäddat i PDF-filen.
-
Avancerade element: Rubriker, objekt, korsreferenstabeller, trailers och metadata, som kräver mer sofistikerade parsingverktyg.
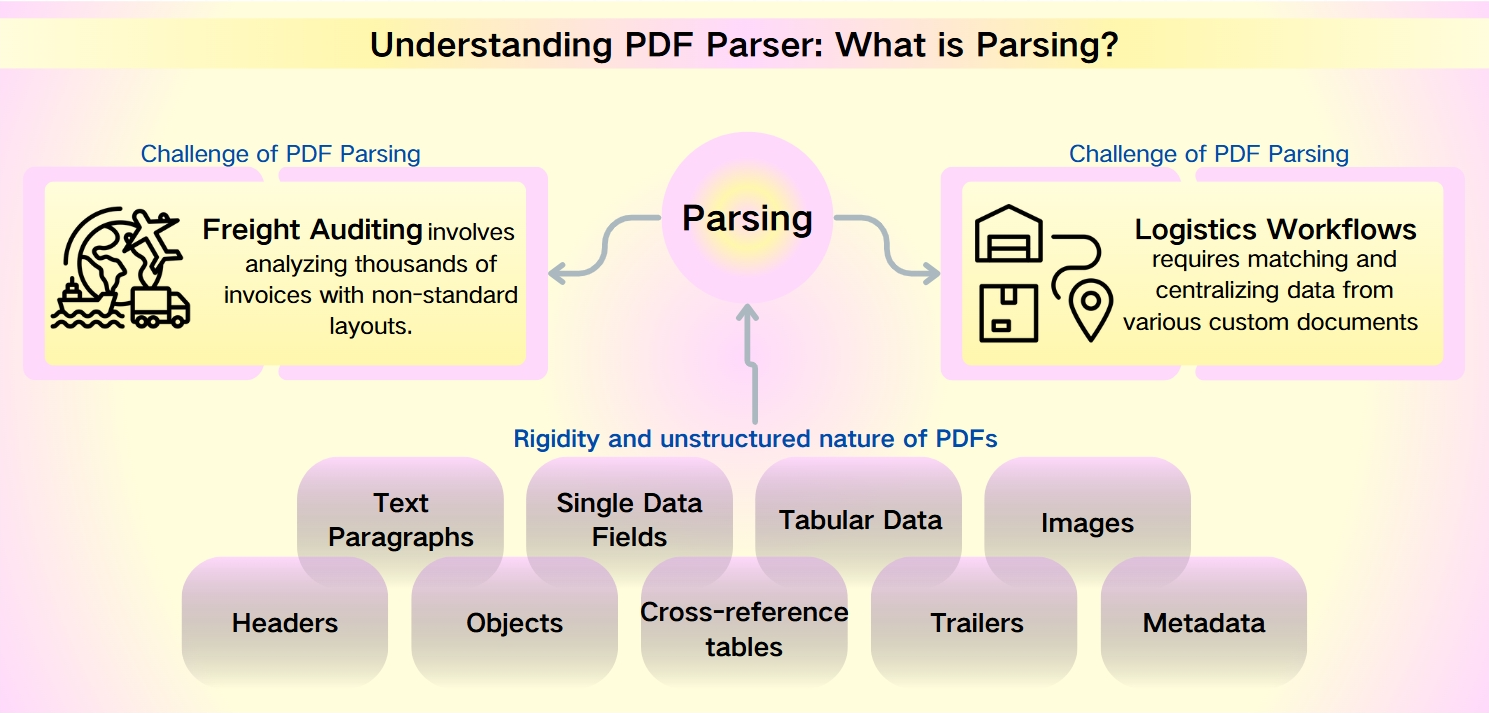
Utmaningar med PDF-parsing: ostrukturerad natur av PDF-metadata
Trots PDF-filers robusthet—karakteriserad av deras säkerhet, enhetskompatibilitet och kompakta filstorlekar—utgör datainsamlingen från dem en formidabel utmaning. Styvheten och den ostrukturerade naturen hos PDF-filer hindrar snabb analys och informationshämtning. Detta är särskilt uttalat i scenarier som fraktgranskning och logistikarbetsflöden, där icke-standardiserade layouter och omfattande datamängder försvårar komplexiteten.
Fraktgranskning involverar att analysera tusentals fakturor med icke-standardiserade layouter. Logistikarbetsflöden kräver att matcha och centralisera data från olika anpassade dokument som packlistor, kommersiella fakturor och fraktsedlar.
Betydelsen av Parsing
Parsing spelar en avgörande roll inom olika områden, från webb utveckling till datainsamling. Det möjliggör för företag att extrahera värdefulla insikter från ostrukturerade datakällor, såsom PDF-dokument, HTML-filer och XML-data. Parsing underlättar:
-
Förbättrad beslutsfattande genom datadrivna insikter.
-
Förbättrad datanoggrannhet och konsekvens.
-
Strömlinjeformad databehandling och analys.
-
Effektiv informationshämtning och lagring.
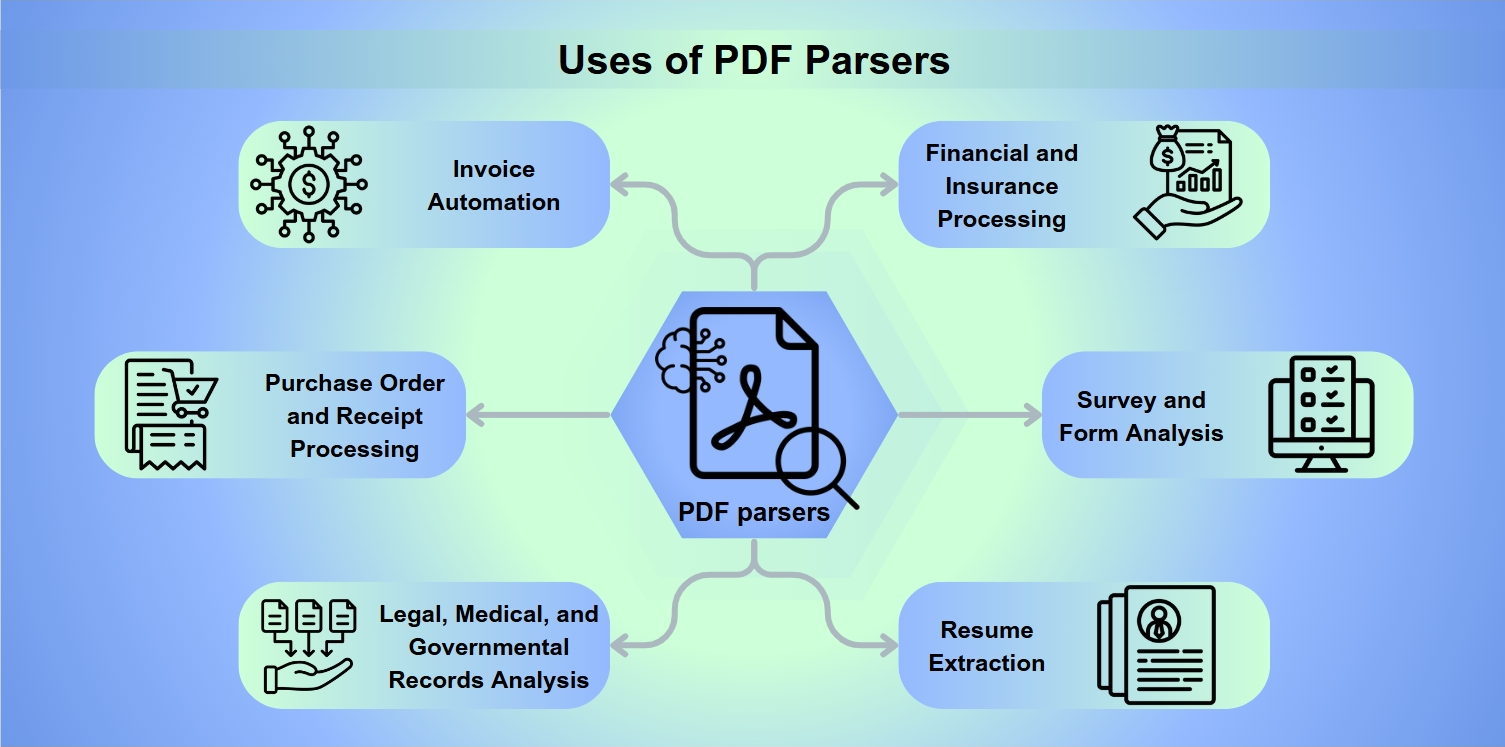
Användningar av PDF Parsers
PDF-parsers är oumbärliga verktyg inom en mängd olika tillämpningar, inklusive:
-
Fakturautomatizering: Strömlinjeformar bearbetningen och betalningen av fakturor.
-
Bearbetning av inköpsorder och kvitton: Underlättar återbetalningar och ersättningar.
-
Analys av juridiska, medicinska och statliga register: Möjliggör djupgående datautvinning för analys.
-
Finansiell och försäkringsbearbetning: Bedömer risk och analyserar balansräkningar.
-
Analys av enkäter och formulär: Samlar in och tolkar formulärsvar.
-
CV-extraktion: Hjälper rekryterare med kandidatutvärdering.
Jämförelse av Olika Parsingmetoder
Dataparseringsmetoder har utvecklats avsevärt över tid. Traditionella metoder för datainsamling förlitar sig ofta på reguljära uttryck (regex) för att extrahera specifika mönster från text. Även om regex är kraftfullt kan det bli komplext och svårt att underhålla för intrikata parsinguppgifter. En annan vanlig teknik är strängmanipulation, som innebär att dela och bearbeta text baserat på avgränsare eller specifika tecken. Dessa metoder, även om de fortfarande är användbara i vissa scenarier, kan kämpa med ostrukturerade eller inkonsekventa dataformat.
Landskapet av PDF-parsing betjänas av en mängd olika metoder, var och en med sina unika fördelar och nackdelar:
-
Online PDF-omvandlare/Parsers: Såsom Zamzar och Smallpdf, erbjuder bekvämlighet och hastighet men är begränsade i funktionalitet och potentiellt osäkra.
-
Adobe Acrobat: Bevarar struktur och formatering men kan kräva manuella justeringar efter konvertering.
-
Kopiera och klistra in: Ger full kontroll men är arbetskrävande och benäget för fel.
-
Automatiserade plattformar: Moderna parsingteknologier såsom AnyParser utnyttjar maskininlärning och naturlig språkbehandling (NLP) för att hantera mer komplexa datastrukturer.
Dessa AI-drivna metoder kan förstå kontext och semantik, vilket gör dem särskilt effektiva för att parsa ostrukturerad text eller dokument med varierande format. Vissa avancerade parsers använder djupinlärningsmodeller för att identifiera och extrahera relevant information med hög noggrannhet, även från tidigare osedda dokumentlayouter.
Hur man utför PDF-parsing: Den Bästa Gratis PDF Parsern för att Extrahera PDF Metadata
Förstå PDF Metadata
PDF-metadata innehåller avgörande information om ett dokument, inklusive dess titel, författare, skapelsedatum och nyckelord. Att effektivt extrahera denna metadata är avgörande för att organisera, söka och hantera stora samlingar av PDF-filer. En robust PDF-parser kan strömlinjeforma denna process, spara tid och förbättra arbetsflödesproduktiviteten.
Nyckelfunktioner hos Topp PDF Parsers
De bästa gratis PDF-parsers erbjuder en kombination av noggrannhet, hastighet och mångsidighet. De bör kunna hantera olika PDF-format, inklusive skannade dokument och de med komplexa layouter. Leta efter parsers som kan extrahera inte bara grundläggande metadata utan också anpassade fält och dold information. Dessutom erbjuder topp-tier parsers ofta alternativ för pdf data extractor för batchbearbetning och integration med andra mjukvarusystem.
Funktioner hos AnyParser
AnyParser, utvecklat av CambioML, är särskilt anmärkningsvärt på grund av sin noggrannhet, integritet och konfigurerbarhet. AnyParser's förmåga att hantera flera filformat, dess användarvänliga gränssnitt och dess skalbarhet gör det till ett utmärkt val för företag av alla storlekar. Dessutom möjliggör dess API sömlös integration i befintliga arbetsflöden, vilket förbättrar den övergripande dokumenthanteringseffektiviteten. Här är några av de nyckelfunktioner som gör AnyParser till ett utmärkt val för PDF-parsing:
-
Precision: AnyParser är designad för att noggrant extrahera text, siffror och symboler samtidigt som den bevarar den ursprungliga layouten och formatet. Den utnyttjar avancerade språkmodeller för att förbättra dokumentförståelse och informationsutvinning, med upp till 2x högre noggrannhet jämfört med traditionella OCR-modeller.
-
Integritet: Den stöder både lokal och molnbaserad dataparsering, vilket säkerställer att känslig information förblir privat och säker.
-
Konfigurerbarhet: Användare kan anpassa extraktionsregler och utdataformat för att passa specifika behov.
-
Multi-källestöd: AnyParser stöder en mängd olika dokumenttyper, inklusive PDF-filer, bilder och diagram.
-
Strukturerad Utdata: Extraherad information kan konverteras till strukturerade format som Markdown, Excel eller JSON, vilket underlättar vidare bearbetning och analys.
-
Molnbaserade distributionsalternativ: AnyParser SDK kan distribueras i molnet, datacenter eller privat, vilket erbjuder flexibilitet och skalbarhet.
-
Användarvänligt gränssnitt: Verktyget erbjuder ett enkelt API som gör det möjligt att utföra komplexa dokumentparsinguppgifter med bara några rader kod.
-
Hög Prestanda: Optimerade algoritmer säkerställer snabb bearbetning av ett stort antal dokument, 5X snabbare än generaliserade LLM:er som GPT4o.
-
Gemenskapsstöd: Som ett open-source-projekt drar AnyParser nytta av en aktiv gemenskap och välkomnar bidrag.
-
Gratis Användningskvot: AnyParser erbjuder en gratis användningskvot med varje konto, vilket gör att användare kan testa verktygets kapabiliteter innan de åtar sig en betald plan.
-
Kundfeedback: Användare har berömt AnyParser för sin höga noggrannhet, bevarande av integritet och effektivitet i datautvinning, med fallstudier som visar betydande tidsbesparingar och förbättrad datakvalitet.
Dessa fördelar gör AnyParser till en värdefull pdf data extractor för dokumentparsing och informationsutvinning, särskilt för företagsanvändare som kräver hög precision och säkerhet. Med pågående teknologiska framsteg och aktivt engagemang från gemenskapen är AnyParser väl positionerat för att spela en allt viktigare roll inom dokumentparsing och informationsutvinning.
Teknisk Förklaring av PDF Parsers
PDF-parsing delar konceptuell grund med webbskrapning, men saknar den strukturerade hierarkin av HTML. Medan webbdokument parsas genom tillgängliga HTML-taggar, presenterar PDF-filer en platt array av tecken och pixlar, vilket kräver mer sofistikerade algoritmer och bibliotek för datainsamling.
PDF Parser vs Python PDF Parser: Nyckelskillnader
En PDF-parser är ofta ett fristående verktyg som en pdf data extractor eller bibliotek designat specifikt för att extrahera data från PDF-filer. Dessa parsers erbjuder vanligtvis användarvänliga gränssnitt och kräver minimal kodningskunskap. Å andra sidan är Python PDF-parsers moduler eller bibliotek som integreras i Python-skript, vilket ger mer flexibilitet men kräver programmeringskompetens.
Utvecklare kan finjustera parsingprocessen, implementera avancerad textanalys och sömlöst integrera PDF-datainsamling i bredare Python-applikationer. PDF-parsers, även om de är mer begränsade i anpassning än python PDF-parser, erbjuder ofta förbyggda funktioner för vanliga användningsfall, vilket gör dem idealiska för användare som behöver snabba resultat utan omfattande programmering.
Fördelar med AnyParser med VLM för Data Parsing
-
Hög Precision: AnyParser's VLM:er säkerställer att datautvinning bibehåller hög trohet, även med komplexa dokumentlayouter.
-
Hastighet: Den leder i konverteringshastighet, vilket ökar produktiviteten genom att minska den tid som behövs för att bearbeta dokument.
-
Användarvänlig: AnyParser erbjuder ett enkelt gränssnitt, vilket gör det tillgängligt för användare på alla nivåer.
-
Mångsidighet: Utöver PDF-filer fungerar AnyParser som en kraftfull bild till Excel-omvandlare, vilket stöder olika dokumenttyper.
Slutsats
PDF-parsing är mer än bara en teknisk process; det är en väg till att omvandla hur företag hanterar data. Trots utmaningarna har utvecklingen av mjukvarulösningar gjort det mer tillgängligt än någonsin. Oavsett om du hanterar fakturabehandling eller komplex dataanalys, är valet av rätt PDF-parser avgörande. Det handlar om att hitta verktyget som erbjuder den perfekta balansen mellan noggrannhet, säkerhet och effektivitet för att stärka dina datadrivna initiativ.
Börja din gratis provperiod idag
Redo att revolutionera din dokumentbearbetning? Prova AnyParser GRATIS utan kreditkortskrav på https://www.cambioml.com/sandbox. Den gratis provperioden gör att du kan bearbeta upp till 10 sidor per dokument, med en maximal filstorlek på 10 MB. Upplev förstahands hur AnyParser's pdf parser kan omvandla ditt tillvägagångssätt för ostrukturerad data och dokumentutvinning. Missa inte denna möjlighet att förbättra dina dataanalysförmågor och strömlinjeforma ditt arbetsflöde med toppmodern AI-teknologi.