Vision Language Models (VLMs) revolutionerar området för dokumentanalys och adresserar många av de begränsningar som är inneboende i traditionella system för optisk teckenigenkänning (OCR). Medan OCR har varit en hörnstensteknologi för att digitalisera text från bilder, står den inför betydande utmaningar i komplexa scenarier. Dessa inkluderar noggrannhetsproblem med lågkvalitativa bilder, begränsad kontextuell förståelse, svårigheter med blandade språk och oförmåga att tolka visuella element. VLMs erbjuder en lovande lösning genom att kombinera avancerat datorseende med kapabiliteter för naturlig språkbehandling. Denna artikel utforskar hur VLMs övervinner OCR:s brister och erbjuder mer robusta och mångsidiga lösningar för dokumenthantering i den digitala tidsåldern.
Vad är OCR? Vilka processer ingår i OCR vid dokumentbearbetning?
Optisk teckenigenkänning (OCR) är en teknik som möjliggör konvertering av olika typer av dokument, såsom skannade pappersdokument, PDF-filer eller bilder tagna med en digitalkamera, till redigerbara och sökbara data. Denna process är avgörande inom dokumenthantering och PDF-datautvinning, vilket gör det möjligt för maskiner att känna igen tryckta eller handskrivna tecken inuti digitala bilder.
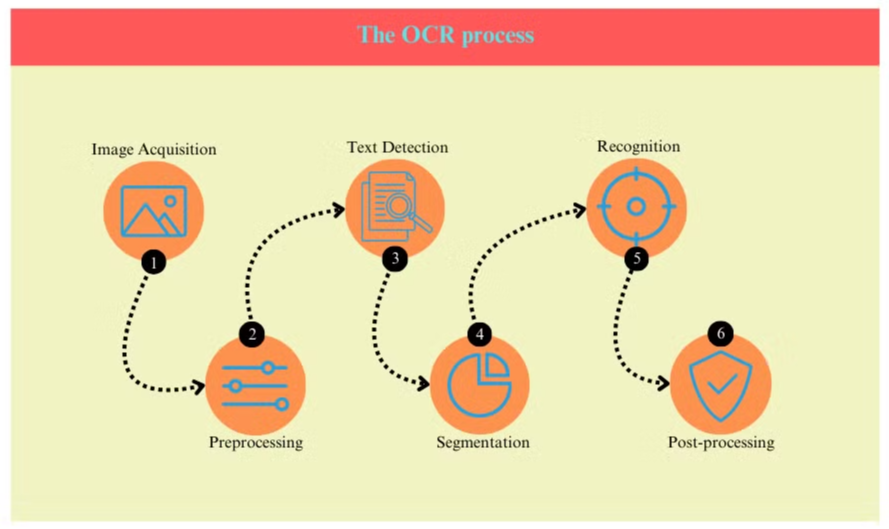
OCR-processen
OCR-processen involverar vanligtvis flera steg:
- Bildförvärv: Dokumentet skannas eller fotograferas för att skapa en digital bild.
- Förbehandling: Bilden rensas, brus tas bort och ljusstyrka och kontrast justeras.
- Textdetektering: Systemet identifierar områden som innehåller text inom bilden.
- Teckensegmentering: Individuella tecken isoleras inom textområdena.
- Teckenigenkänning: Varje tecken analyseras och jämförs med en databas av kända tecken.
- Efterbehandling: Den erkända texten kontrolleras för fel med hjälp av språklig och kontextuell information.
Även om OCR har förbättrat dokumentbearbetningskapabiliteterna avsevärt, står den fortfarande inför begränsningar när det gäller att hantera komplexa layouter, lågkvalitativa bilder och varierande typsnitt. Det är här avancerade teknologier som vision language models kommer in för att förbättra noggrannheten och förståelsen vid datautvinning från bilder och dokument.
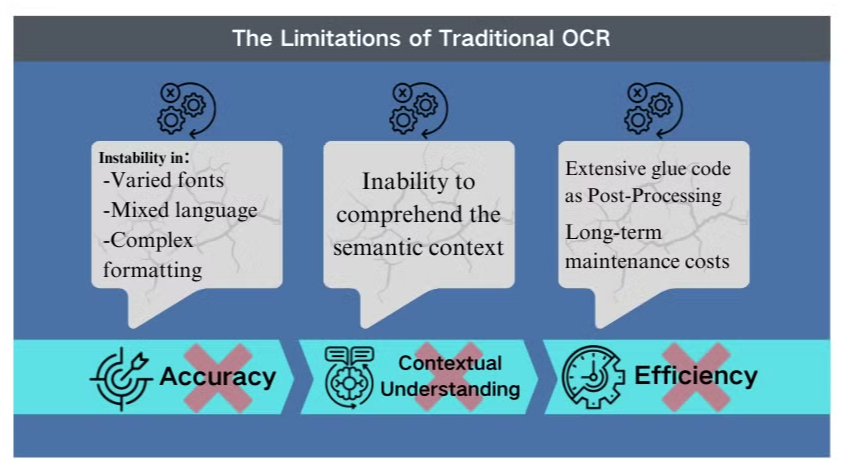
Begränsningarna med traditionell OCR-teknologi
Noggrannhetsutmaningar i komplexa scenarier
Traditionell optisk teckenigenkänning (OCR) är, även om den är fördelaktig för grundläggande textutvinning, utsatt för betydande hinder när den ställs inför intrikata dokumentlayouter eller lågkvalitativa bilder. Dessa system har ofta svårt att upprätthålla noggrannheten när de bearbetar dokument med varierande typsnitt, blandade språk eller komplex formatering. Till exempel kan OCR misslyckas när den försöker extrahera data från bildtunga presentationer eller tätt formaterade PDF-filer.
Brist på kontextuell förståelse
En av de mest påtagliga begränsningarna med konventionell OCR är dess oförmåga att förstå den semantiska kontexten av den text den bearbetar. Denna brist blir särskilt tydlig i scenarier som kräver nyanserad tolkning, såsom juridiska kontrakt eller medicinska rapporter. OCR:s fokus på teckenigenkänning utan kontextuell medvetenhet kan leda till kritiska feltolkningar, särskilt när det gäller tvetydiga tecken eller branschspecifik terminologi.
Ineffektivitet i efterbehandling
Begränsningarna med OCR kräver ofta omfattande efterbehandlingsinsatser. Detta ytterligare steg kan avsevärt öka den tid och de resurser som krävs för dokumentbearbetning. Dessutom faller traditionella OCR-system ofta kort när de ska extrahera information från diagram, tabeller eller andra icke-textuella element, vilket ytterligare komplicerar dokumentutvinningsprocessen. Dessa ineffektivitet understryker behovet av mer avancerade lösningar, såsom vision language models, som erbjuder en mer heltäckande metod för dokumentanalys och datautvinning.
Vad är Vision-Language Models och hur förbättrar de OCR
Vision language models representerar ett betydande framsteg inom dokumentbearbetningsteknologi, som adresserar många av de begränsningar som är inneboende i traditionella system för optisk teckenigenkänning (OCR). Dessa avancerade modeller kombinerar datorseende med naturlig språkbehandling för att förstå både de visuella och textuella elementen i dokument samtidigt.
Förbättrad noggrannhet och kontextförståelse
Till skillnad från OCR, som har svårt med lågkvalitativa bilder och komplexa layouter, utmärker sig vision language models i att tolka olika dokumentformat. De kan noggrant extrahera data från bilder, PDF-filer och annat visuellt innehåll, även när de ställs inför utmanande scenarier. Denna förbättrade noggrannhet beror på deras förmåga att beakta hela kontexten av ett dokument, snarare än att enbart fokusera på individuella tecken eller ord.
Omfattande datautvinning
Vision language models går bortom enkel textigenkänning och erbjuder omfattande kapabiliteter för PDF-datautvinning. De kan identifiera och tolka tabeller, diagram och figurer inom dokument, vilket bevarar integriteten hos komplexa layouter. Denna holistiska metod för dokumentanalys möjliggör mer nyanserad och komplett informationshämtning, vilket avsevärt ökar nyttan av den extraherade datan för efterföljande tillämpningar.
Flerspråkig och multiformat kompetens
En av de viktigaste fördelarna med vision language models är deras flexibilitet i att hantera flera språk och dokumentformat. Till skillnad från OCR-system som kan ha svårt med icke-latinska skript eller blandade språk, kan dessa modeller sömlöst bearbeta innehåll över olika språk och skript, vilket gör dem ovärderliga för globala dokumenthanteringsbehov.
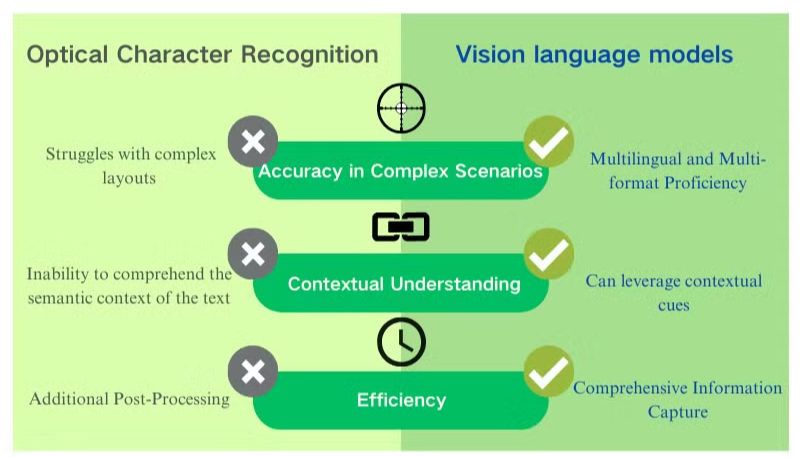
Nyckelfördelar med Vision-Language Models för dokumentförståelse
Vision language models erbjuder betydande fördelar jämfört med traditionell OCR för dokumentbearbetning och datautvinning. Dessa AI-drivna system kombinerar visuell och textuell förståelse för att leverera överlägsna resultat över olika dokumenttyper.
Förbättrad noggrannhet och kontextuell förståelse
Vision language models utmärker sig i att hantera komplexa layouter, lågkvalitativa bilder och olika typsnitt. Till skillnad från OCR, som har svårt med tvetydiga tecken, utnyttjar dessa modeller kontextuella ledtrådar för att noggrant tolka text. Denna kapabilitet förbättrar dramatiskt noggrannheten vid PDF-datautvinning, särskilt för dokument med intrikata strukturer eller dålig bildkvalitet.
Omfattande informationsinsamling
Medan OCR enbart fokuserar på textigenkänning kan vision language models extrahera data från bilder, tabeller och diagram. Denna holistiska metod säkerställer att kritisk information inte förbises under dokumentbearbetningsfasen. Genom att fånga både textuella och visuella element ger dessa modeller en mer komplett förståelse av dokumentinnehåll.
Flerspråkig och multiformat kompetens
Vision language models visar en anmärkningsvärd flexibilitet i att bearbeta dokument över olika språk och format. De kan sömlöst hantera blandade språk och icke-latinska skript, vilket övervinner en betydande begränsning hos traditionella OCR-system. Denna mångsidighet gör dem ovärderliga för globala företag som hanterar olika dokumenttyper och språk.
Verkliga tillämpningar möjliggjorda av VLM som OCR misslyckades med
Vision language models revolutionerar dokumentbearbetning inom finans, personalavdelningar och andra sektorer genom att adressera kritiska begränsningar hos traditionella OCR-system. Dessa avancerade AI-modeller omvandlar digitala transformationsinsatser över branscher genom att erbjuda överlägsen noggrannhet och kontextuell förståelse.
Revolutionera dokumentbearbetning inom finans
Vision language models omvandlar dokumentbearbetning inom finans och övervinner begränsningar hos traditionell OCR. Dessa avancerade modeller utmärker sig i att extrahera data från komplexa finansiella rapporter, fakturor och kvitton med intrikata layouter. Till skillnad från OCR kan de förstå kontext och noggrant tolka tvetydiga tecken (t.ex. särskilja mellan en nolla och bokstaven O) samt blandade språk som ofta förekommer i globala finansiella dokument.
Förbättra HR-operationer genom intelligent dokumentanalys
Inom HR-sektorn visar vision language models sig ovärderliga för PDF-datautvinning från CV, anställdas register och prestationsutvärderingar. Dessa modeller kan förstå den semantiska strukturen av dokument, vilket möjliggör mer noggrann informationshämtning och analys. Denna kapabilitet strömlinjeformar avsevärt rekryteringsprocesser och hantering av anställdas data, uppgifter där OCR ofta har svårt med varierande format och handskrivna anteckningar.
Förbättra efterlevnad och riskhantering
Vision language models är särskilt effektiva inom efterlevnad och riskhantering inom både finans och HR. De kan extrahera och tolka kritisk information från reglerande dokument, kontrakt och policys med större noggrannhet än OCR. Denna förbättrade dokumentbearbetningskapabilitet säkerställer bättre efterlevnad av lagkrav och mer effektiva riskbedömningsprocedurer.
Slutsats
Sammanfattningsvis representerar vision language models ett betydande framsteg inom dokumentbearbetningsteknologi, som adresserar många av de inneboende begränsningarna hos traditionella OCR-system. Genom att kombinera visuell och textuell förståelse erbjuder dessa avancerade modeller överlägsen prestanda över ett brett spektrum av utmanande scenarier, från komplexa layouter till blandade språk och lågkvalitativa bilder. När organisationer fortsätter att digitalisera sina verksamheter och söka mer effektiva sätt att utvinna värde från sina dokumentarkiv, framträder vision language models som ett kraftfullt verktyg för utvecklare och ingenjörsledare. Deras förmåga att förstå kontext, hantera olika format och ge mer exakta resultat positionerar dem som en nyckelaktör för sofistikerade RAG-pipelines och företagsomfattande sökfunktioner, vilket i slutändan driver digitala transformationsinitiativ till nya höjder.