Har du någonsin undrat vad OCR står för? Optisk teckenigenkänning är en kraftfull teknik som omvandlar bilder av text till maskinläsbara data. Medan OCR erbjuder enorma fördelar för digitalisering av dokument och utvinning av information, är det inte utan sina nackdelar. När du utforskar denna teknik är det avgörande att förstå både dess kapabiliteter och begränsningar. I denna artikel kommer du att upptäcka betydelsen bakom OCR och fördjupa dig i dess potentiella nackdelar. Genom att få en omfattande förståelse för optisk teckenigenkänning kommer du att vara bättre rustad att avgöra om och hur du ska implementera denna teknik i dina egna arbetsflöden och projekt.
Vad betyder OCR och vad är en OCR?
Vad betyder OCR?
OCR står för optisk teckenigenkänning, en teknik som gör det möjligt för datorer att känna igen och omvandla olika typer av dokument. I sin kärna är OCR processen att skanna tryckt eller handskriven text och omvandla den till maskinkodad text. Detta gör att texten kan sökas, redigeras och överföras med lätthet. Att förstå vad OCR betyder är avgörande för alla som arbetar med dokumentinscanning och textigenkänningstekniker.
Vad är en OCR?
För dem som är obekanta med termen, är "vad är en OCR" en vanlig fråga som hänvisar till optisk teckenigenkänning, en teknik som gör att datorer kan läsa text från bilder eller skannade dokument.
OCR omvandlar tryckt eller handskriven text till maskinläsbara data och överbryggar klyftan mellan papper och digitala format. Denna teknik använder sofistikerade algoritmer för att upptäcka bokstavsformer, ordstrukturer och till och med hela meningar. Genom att göra detta omvandlar den statiska bilder till redigerbara och sökbara textfiler.
OCR-teknik är i grunden baserad på datorvision och mönsterigenkänningstekniker. OCR står för att skanna dokument eller bilder som innehåller text och använda avancerade algoritmer för att identifiera och omvandla texten till ett digitalt, redigerbart format. En av de viktigaste händelserna i OCR-teknikens historia inträffade 1974 när Ray Kurzweil utvecklade ett omni-font OCR-system som kunde känna igen text i praktiskt taget vilken font som helst. Under åren har OCR utvecklats från enkel mallmatchning till mer sofistikerade system.
Trots sina kapabiliteter står OCR-tekniken för närvarande inför vissa begränsningar. Dessa inkluderar utmaningar med att känna igen text i bilder av dålig kvalitet, svårigheter med att hantera komplexa layouter eller bakgrunder och varierande noggrannhet när man hanterar olika typsnitt, språk eller handskrift. Dessutom kan OCR-system ha problem med dokument som har färgade bakgrunder, är suddiga eller snedvridna, samt med kursiv handskrift.
Förstå optisk teckenigenkänningsprogramvara
Optisk teckenigenkänningsprogramvara är en transformativ teknik som omvandlar olika typer av dokument till redigerbara och sökbara data. Den spelar en avgörande roll i digitaliseringen av vår värld, vilket gör information mer tillgänglig och hanterbar. OCR-programvara använder en sofistikerad process för att omvandla bilder av text till maskinläsbara data.
Hur OCR-programvara fungerar
1. Bildförvärv
Resan för OCR börjar med att fånga en bild av dokumentet. Detta kan göras genom en skanner eller en digitalkamera. Bilden översätts sedan till ett digitalt format som en dator kan bearbeta.
2. Förbehandling och bildförbättring
Det andra steget involverar att förbättra bildkvaliteten. När bilden har förvärvats genomgår den förbehandling för att förbättra dess kvalitet för bättre igenkänning. Detta steg kan innebära att justera kontrast, ljusstyrka och skärpa i bilden, samt att ta bort eventuellt brus eller irrelevanta element. Denna förbehandlingsfas är avgörande för att uppnå korrekta resultat, särskilt när man hanterar lågkvalitativa skanningar eller fotografier.
3. Textdetektion
OCR-programvara analyserar den förbehandlade bilden för att upptäcka områden som innehåller text. Den gör detta genom att leta efter mönster och former som är karaktäristiska för text, såsom linjer av olika tjocklekar och höjder.
4. Teckensegmentering
När textområden har upptäckts bryter programvaran ner texten i mindre enheter, som block, rader, ord eller till och med individuella tecken. OCR-programvara analyserar bilden pixel för pixel för att identifiera mönster som bildar tecken. Den bryter ner bilden i mindre segment och isolerar varje tecken.
5. Textigenkänning och utvinning
Programvaran jämför sedan dessa isolerade former med en stor databas av kända teckenmönster för att avgöra vad varje tecken är. Programvaran extraherar funktioner från tecknen, såsom antalet linjer, kurvor eller vinklar. Dessa funktioner hjälper OCR att känna igen och särskilja mellan olika tecken.
6. Efterbehandling
Efter att tecknen har identifierats går OCR-systemet igenom en efterbehandlingsfas där det korrigerar eventuella potentiella fel och formaterar texten för utdata. Den korrigerade texten exporteras sedan till önskat format, såsom ett Word-dokument eller en sökbar PDF.
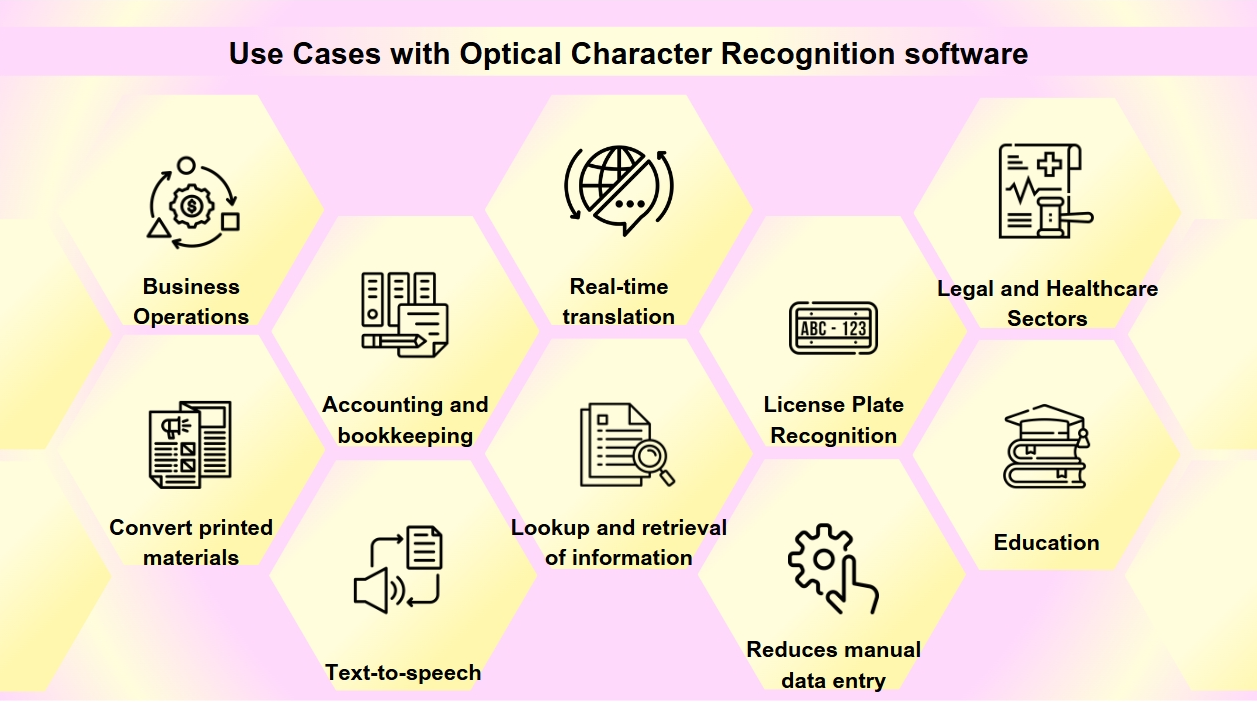
Användningsfall med optisk teckenigenkänningsprogramvara
OCR har blivit ett viktigt verktyg i den digitala transformationen av många industrier, vilket strömlinjeformar processer och förbättrar datatillgänglighet och noggrannhet. Du kanske stöter på OCR oftare än du inser. Från att skanna visitkort till att digitalisera gamla böcker spelar OCR en avgörande roll i olika branscher. OCR-teknik har en mängd olika tillämpningar:
-
Dokumentdigitalisering: OCR används för att omvandla tryckta material som gamla böcker, tidningar och historiska dokument till digitala format, vilket gör dem sökbara och bevarar dem för framtida generationer.
-
Formulärbearbetning: Företag utnyttjar OCR för att automatiskt extrahera data från formulär, vilket minskar manuell datainmatning och ökar effektiviteten inom olika sektorer som ekonomi och hälsovård.
-
Faktura-bearbetning: OCR-teknik kan läsa text på fakturor och automatiskt mata in data i ekonomiska system, vilket strömlinjeformar bokförings- och redovisningsprocesser.
-
Tillgänglighet: OCR möjliggör text-till-tal-funktionalitet, vilket skapar ljudversioner av text för synskadade individer, vilket gör tryckta material mer tillgängliga.
-
Mobilapplikationer: OCR är integrerat i appar för uppgifter som att skanna visitkort, känna igen text i foton och underlätta realtidsöversättning.
-
Sökbarhet: OCR förbättrar sökbarheten av skannade dokument genom att extrahera text från bilder eller PDF-filer, vilket möjliggör enkel sökning och hämtning av information.
-
Registreringsskyltsigenkänning: Används för parkering och trafikhantering kan OCR känna igen registreringsskyltar, vilket möjliggör effektiv övervakning och verkställighet.
-
Affärsverksamhet: OCR strömlinjeformar affärsprocesser genom att automatisera datainmatning från dokument som fakturor, kvitton och inköpsordrar, samt påskynda rekrytering genom att skanna och bearbeta jobbansökningar och CV:n.
-
Juridiska och hälsovårdssektorer: Advokatbyråer använder OCR för att digitalisera ärendeakter och juridiska dokument för enklare informationshämtning, medan vårdgivare använder det för att omvandla patientjournaler och medicinska formulär till elektroniska hälsoregister (EHR), vilket förbättrar databehandling och patientvård.
-
Utbildning: Inom utbildningsmiljöer används OCR för att skapa digitala läroböcker och lärmaterial, vilket förbättrar tillgängligheten för studenter med olika behov och stödjer en inkluderande lärandemiljö.
När OCR-tekniken utvecklas fortsätter den att spela en avgörande roll i att göra information mer tillgänglig och effektiv att hantera i den digitala tidsåldern.
Nackdelen med OCR: Begränsningar och nackdelar
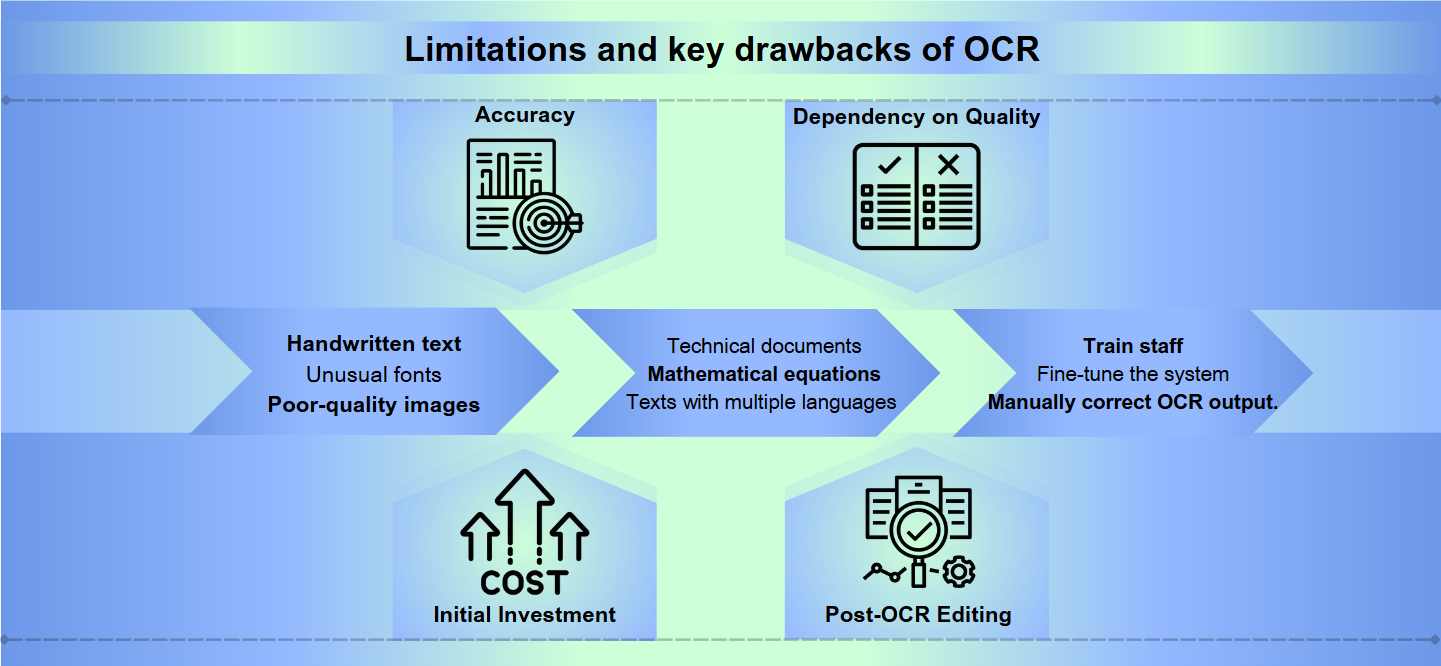
Noggrannhetsutmaningar
Även om optisk teckenigenkänning (OCR) har kommit långt står den fortfarande inför betydande hinder för att uppnå perfekt noggrannhet. Handskriven text, ovanliga typsnitt eller bilder av låg kvalitet kan leda till feltolkningar och fel. Även små variationer i teckenformer eller storlekar kan förvirra OCR-system, vilket resulterar i otydlig utdata som kräver manuell korrigering.
Språk- och formatbegränsningar
De flesta OCR-lösningar excellerar med standard språk och format men kämpar med specialiserat innehåll. Tekniska dokument, matematiska ekvationer eller texter med flera språk kan utgöra betydande utmaningar. Dessutom kan OCR misslyckas när den konfronteras med komplexa layouter, tabeller eller dokument med intrikata format, vilket potentiellt kan förlora avgörande strukturell information.
Resursintensitet
Att implementera och underhålla ett effektivt OCR-system kan vara resursintensivt. Högkvalitativ OCR-programvara kommer ofta med ett högt pris, och den hårdvara som krävs för att bearbeta stora volymer av dokument kan vara kostsam. Dessutom kan den tid och ansträngning som behövs för att utbilda personal, finjustera systemet och manuellt granska och korrigera OCR-utdata belasta organisatoriska resurser.
Nyckelnackdelar med OCR
-
Noggrannhet: OCR-programvara kan ha problem med noggrannhet, särskilt när den hanterar bilder av låg kvalitet, komplexa layouter eller handskriven text. Fel kan sträcka sig från att felavläsa tecken till att hoppa över hela textavsnitt.
-
Beroende av kvalitet: Effektiviteten av OCR är starkt beroende av kvaliteten på det ursprungliga dokumentet. Blekt bläck, fläckar eller skrynkligt papper kan leda till felaktiga översättningar.
-
Initial investering: Att sätta upp ett OCR-system kan kräva en betydande initial kostnad, inklusive inte bara programvaran utan också kompatibel hårdvara som skannrar.
-
Efter-OCR-redigering: Ofta kräver utdata från OCR-processer manuell granskning och korrigering, vilket kan vara tidskrävande.
Vision Language Model övervinner OCR:s begränsningar
När teknologin utvecklas dyker innovativa lösningar upp för att adressera bristerna i traditionell optisk teckenigenkänning (OCR). En sådan genombrott är Vision Language Model (VLM), som kombinerar datorvision och naturlig språkbehandling för att revolutionera textutvinning och förståelse.
Förbättrad kontextuell förståelse
VLM:er excellerar på att förstå kontexten runt text, till skillnad från OCR:s isolerade teckenigenkänning. Genom att analysera visuella element tillsammans med text kan dessa modeller tolka komplexa layouter, handskrivna anteckningar och till och med delvis dolda texter med anmärkningsvärd noggrannhet.
Flerspråkiga och multimodala kapabiliteter
Medan OCR ofta kämpar med olika språk och skript, visar VLM:er imponerande mångsidighet. De kan sömlöst bearbeta flera språk och till och med tolka visuellt innehåll som diagram eller diagram, vilket ger en mer omfattande förståelse av dokument.
Adaptiv inlärning och kontinuerlig förbättring
Till skillnad från statiska OCR-system utnyttjar VLM:er maskininlärning för att anpassa sig och förbättras över tid. När de stöter på nya data och scenarier förfinar dessa modeller sin prestanda och blir alltmer skickliga på att hantera olika dokumenttyper och format.
Genom att övervinna OCR:s begränsningar banar Vision Language Models väg för mer exakt, effektiv och intelligent dokumentbearbetning över branscher.
Välj Vision Language Model: Prova AnyParser
Byggt på framstegen av Vision Language Models (VLM), framträder AnyParser som en sofistikerad lösning som överträffar begränsningarna hos traditionell OCR-teknik. Utvecklad av CambioML-teamet är AnyParser ett kraftfullt dokumentparseringsverktyg som utnyttjar en precis och konfigurerbar API för att extrahera information från olika ostrukturerade datakällor såsom PDF-filer, bilder och diagram, och omvandla dem till strukturerade format.
Teknisk grund och kapabiliteter
AnyParser är förankrad på den robusta grunden av stora språkmodeller (LLMs), vilket säkerställer hög noggrannhet i text-, tabell-, diagram- och layoututvinning från dokument. Den utmärker sig med sin förmåga att behålla den ursprungliga layouten och formatet, en funktion som är särskilt fördelaktig för dokument med komplexa layouter eller de som kräver bevarande av den ursprungliga estetiken.
Integritet och säkerhet
Med betoning på användarens integritet bearbetar AnyParser data lokalt, vilket skyddar känslig information. Denna funktion är en betydande fördel för företag och individer som hanterar konfidentiella data.
Anpassningsbarhet och flexibilitet
Med en hög grad av konfigurerbarhet låter AnyParser användare ställa in anpassade extraktionsregler och definiera utdataformat som passar deras specifika behov. Denna anpassningsförmåga gör den till ett idealiskt verktyg för en mängd olika tillämpningar, från AI-teknik till finansiell analys.
Slutsats
Som du har lärt dig erbjuder OCR-teknik kraftfulla kapabiliteter för att digitalisera text, men den är inte utan begränsningar. Medan optisk teckenigenkänning kan dramatiskt förbättra effektiviteten, måste du noggrant överväga de potentiella nackdelarna. Tänk på noggrannhetsproblemen, formateringsutmaningarna och resurskraven innan du implementerar en OCR-lösning. I slutändan beror beslutet att använda OCR på dina specifika behov och omständigheter. Genom att förstå både fördelarna och nackdelarna kan du fatta ett informerat beslut om huruvida OCR är rätt för din organisation. När OCR fortsätter att utvecklas, håll dig uppdaterad om nya framsteg som kan åtgärda nuvarande brister och låsa upp ännu större potential för denna transformativa teknik.
Call to Action
Omfamna kraften i Vision Language Models genom att prova AnyParser gratis för att konvertera dina PDF-filer till Google Sheets på https://www.cambioml.com/sandbox. Få en gratis konsultation om hur VLM:er kan förbättra ditt arbetsflöde för datautvinning.