I dagens digitala ålder har datasäkerhet blivit en avgörande fråga, särskilt med den ökande användningen av AI och automatisering inom dokumentbearbetning. Dokumentparsing, en kritisk komponent av datautvinning, gör det möjligt för företag att effektivt hantera och utnyttja stora mängder information.
IDP, intelligent dokumentbearbetning, revolutionerar hur företag hanterar datautvinning från dokument. Svaret på vad intelligent dokumentbearbetning är, är att IDP är en avancerad teknik som automatiserar utvinning och klassificering av data från dokument. IDP-teknik har blivit oumbärlig för företag som vill automatisera och säkra sin dokumentparsing.

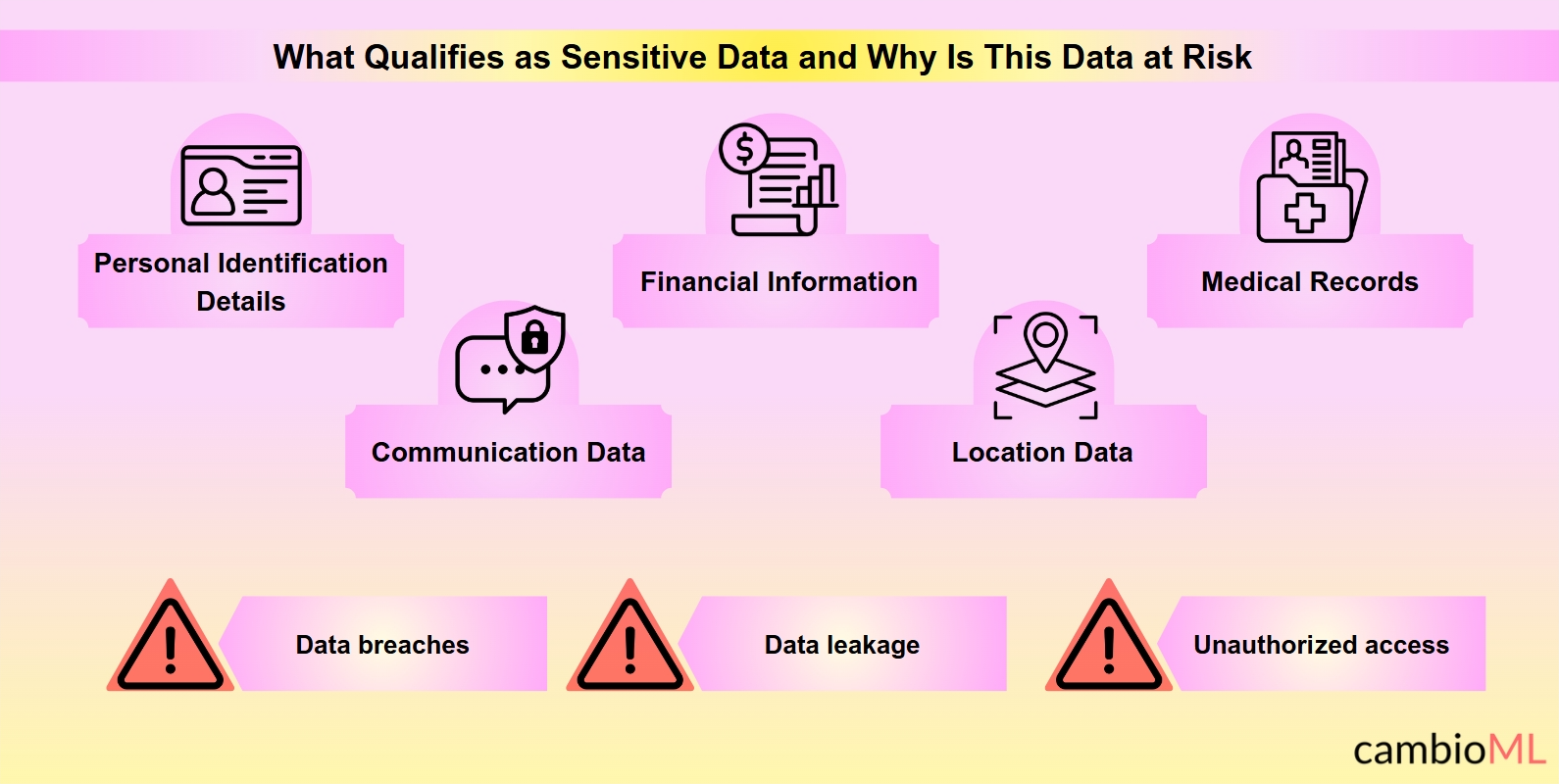
Förståelse för känslig data i dokumentparsing
Känslig data i dokumentparsing avser information som potentiellt kan identifiera individer, avslöja personliga egenskaper eller orsaka skada om den missbrukas eller avslöjas utan samtycke. Detta inkluderar en mängd olika datatyper, var och en med unika konsekvenser för integritet och säkerhet. Antagandet av IDP-teknik är avgörande för att upprätthålla konfidentialiteten och integriteten hos känslig data.
Vad kvalificerar som känslig data?
-
Personliga identifieringsuppgifter: Dessa inkluderar personnummer, körkortnummer, passnummer och andra unika identifierare som kan identifiera en individ. Till exempel kräver dokument som innehåller personliga identifieringsuppgifter noggrant hantering för att förhindra identitetsstöld och bedrägeri.
-
Finansiell information: Denna kategori omfattar bankkontonummer, kreditkortsuppgifter och transaktionsregister. Exponering av sådan data kan leda till ekonomiska förluster och missbruk av medel, vilket betonar behovet av strikta säkerhetskontroller under parsingprocesser.
-
Medicinska journaler: Skyddad hälsodata (PHI) såsom patienthistorik, diagnoser och behandlingsplaner faller under denna kategori. Felaktig hantering av medicinska journaler kan leda till brott mot patientens konfidentialitet och integritet, med allvarliga etiska och juridiska konsekvenser.
-
Kommunikationsdata: Detta inkluderar personlig korrespondens som kan avslöja konfidentiella affärsförhandlingar eller känsliga personliga diskussioner. Parsing av e-post eller meddelandetranskript måste säkerställa att sådan data inte exponeras eller hanteras felaktigt.
-
Platsdata: Geolokaliseringsinformation som kan peka ut en individs rörelser eller bostad, särskilt när den kombineras med annan data, kan vara känslig. Parsing av dokument som innehåller reseplaner eller hemadresser kräver särskild uppmärksamhet på integritetsfrågor.
Varför är denna data i riskzonen?
En IDP-lösning erbjuder en omfattande strategi för att hantera komplexiteten i dokumentparsing. Att förstå vad intelligent dokumentbearbetning är, är avgörande för företag som vill förbättra sina databehandlingsförmågor. Känslig data är i riskzonen under dokumentparsing på grund av flera sårbarheter:
- Dataintrång: Obehörig åtkomst till känslig information kan inträffa om säkerhetsåtgärderna är otillräckliga.
- Dataleakage: Känslig information kan oavsiktligt exponeras under utvinnings- eller bearbetningsfaserna.
- Obefogad åtkomst: Utan ordentliga åtkomstkontroller kan känslig data nås av otillförlitliga parter.
Nyckelutmaningar för integritet och säkerhet i dokumentparsing
Dokumentparsing involverar utvinning av strukturerad data från ostrukturerade eller semi-strukturerade dokument, vilket kan utsätta känslig information för olika risker om den inte hanteras säkert. Med en IDP-lösning på plats kan organisationer mildra riskerna kopplade till känsliga dataintrång. Användningen av verktyg för intelligent dokumentbearbetning kan avsevärt minska risken för dataleakage och obehörig åtkomst.
Risker vid datautvinning
En av de primära utmaningarna är risken för dataleakage under utvinningsprocessen. Känslig data kan oavsiktligt exponeras om dokument inte saneras ordentligt eller om utvinningsverktyg saknar nödvändiga säkerhetsåtgärder. Till exempel kan parsingverktyg som inte döljer personliga identifieringsuppgifter innan bearbetning leda till oavsiktlig avslöjande av personnummer eller finansiell information.
Lagring och åtkomsthantering
Känslig data som parsas från dokument behöver ofta lagras för vidare analys eller arkivering. Emellertid kan felaktiga lagringsmetoder, såsom otillräcklig kryptering eller bristande åtkomstkontroller, leda till obehörig åtkomst. Till exempel, om parsad data lagras i en databas utan ordentlig kryptering, kan den vara sårbar för intrång, vilket potentiellt exponerar känsliga finansiella eller medicinska journaler.
Juridisk efterlevnad
Regler som GDPR och HIPAA ställer strikta krav på hur känslig data ska hanteras, inklusive under dokumentparsing. Bristande efterlevnad kan resultera i betydande juridiska och ekonomiska påföljder. Till exempel, enligt GDPR, måste organisationer säkerställa att personuppgifter behandlas på ett sätt som garanterar lämplig säkerhet, inklusive skydd mot obehörig eller olaglig behandling och mot oavsiktlig förlust, förstörelse eller skada.
Viktiga bästa metoder för integritet och säkerhet i dokumentparsing
För att mildra utmaningarna kopplade till dokumentparsing är det avgörande att implementera bästa metoder som prioriterar integritet och säkerhet. IDP-teknik, med sina avancerade funktioner, spelar en avgörande roll för att säkerställa integriteten och säkerheten vid dokumentparsing. Noggrannheten hos VLM har förbättrats dramatiskt jämfört med OCR-fakturaskanning, vilket minskar behovet av manuell datainmatning.
Datakryptering
Kryptering är en kritisk åtgärd för att skydda känslig data både under överföring och i vila. Genom att implementera IDP, intelligent dokumentbearbetning, kan företag effektivisera sina operationer och förbättra datanoggrannheten. Användningen av en Python PDF-parser kan effektivisera processen för dokumentparsing, vilket säkerställer snabbare och mer exakt datautvinning.
Anonymisering och pseudonymisering
Anonymisering innebär att all identifierbar information tas bort från data, vilket gör det omöjligt att spåra tillbaka till en individ. Pseudonymisering ersätter identifierare med artificiella, vilket minskar risken för återidentifiering. Dessa tekniker är avgörande vid parsing av dokument som innehåller personuppgifter för att säkerställa efterlevnad av integritetsregler som GDPR, som betonar principen om dataminimering.
Åtkomstkontroller och revisionsloggar
Implementering av strikta åtkomstkontroller och upprätthållande av revisionsloggar är avgörande för att hantera vem som kan få åtkomst till känslig data. Åtkomst bör beviljas på ett behov- att-veta-basis, och all åtkomst bör loggas och övervakas. Till exempel kan rollbaserad åtkomstkontroll (RBAC) säkerställa att endast auktoriserad personal kan få åtkomst till känslig data, och revisionsloggar kan hjälpa till att spåra eventuella obehöriga åtkomstförsök.
Regelbundna säkerhetsrevisioner
Regelbundna säkerhetsrevisioner kan hjälpa till att identifiera sårbarheter i dokumentparsingprocessen. Dessa revisioner bör inkludera penetrationstester, kodgranskningar och sårbarhetsbedömningar. Till exempel kan det vara fördelaktigt att anlita en tredje part för att genomföra en red-teaming-övning för att avslöja potentiella svagheter i parsingsystemet som kan utnyttjas av angripare. Genom att implementera dessa bästa metoder kan organisationer avsevärt minska risken för dataintrång och säkerställa efterlevnad av dataskyddsregler, vilket skyddar både deras verksamhet och integriteten hos de individer vars data de hanterar.
AnyParser i dokumentparsing: Förbättra integritet och säkerhet
Verktyg för intelligent dokumentbearbetning är utformade för att extrahera, analysera och hantera data med hög precision. AnyParser, utvecklad av CambioML-teamet, utmärker sig som ett robust dokumentparsingverktyg som adresserar de centrala utmaningarna för integritet och säkerhet i dokumentparsing med sin unika uppsättning funktioner och kapabiliteter.
Strukturerad utdata och lokal bearbetning
AnyParser konverterar extraherad information till strukturerade format som Markdown, vilket underlättar vidare databehandling och analys. Dess funktion för lokal bearbetning säkerställer att känslig data aldrig lämnar användarens lokaler, vilket avsevärt minskar risken för dataintrång. En Python PDF-parser är ett viktigt verktyg för utvecklare som vill automatisera utvinning av data från PDF-dokument.
Tekniska fördelar
AnyParser utnyttjar stora språkmodeller (LLM) för dokumentförståelse och informationsextraktion, vilket inte bara förbättrar noggrannheten utan också ökar säkerheten genom att minska behovet av manuell databehandling. Dess modulbaserade design möjliggör enkel expansion och anpassning, vilket tillgodoser föränderliga affärsbehov.
AI och ML i dokument säkerhet
Artificiell intelligens (AI) och maskininlärning (ML) kan förbättra säkerheten vid dokumentparsing genom att automatisera efterlevnadskontroller och identifiera potentiella dataintrång. Dessa teknologier kan snabbt och noggrant analysera stora mängder data, vilket säkerställer att känslig information skyddas. Till exempel är VLM-fakturaskanning, som är bättre än OCR-fakturaskanning, en nyckelkomponent i intelligent dokumentbearbetning, vilket möjliggör automatisk utvinning av fakturadata.
Regulatorisk efterlevnad och dess roll i datasäkerhet
Översikt över viktiga regler
Viktiga regler som GDPR och HIPAA ställer strikta krav på hantering av känslig data. GDPR fokuserar på att skydda personuppgifter inom Europeiska unionen, medan HIPAA ställer standarder för att skydda hälsouppgifter i USA.
Konsekvenser för företag
Bristande efterlevnad av dessa regler kan resultera i stora böter och rättsliga åtgärder. Därför måste företag prioritera säker dokumentparsing för att säkerställa att de uppfyller alla regulatoriska krav och skyddar sina kunders data. Integrationen av IDP, intelligent dokumentbearbetning, säkerställer efterlevnad av dataskyddsregler.
Framtida trender inom integritet och säkerhet för dokumentparsing
Framsteg inom AI och säker databehandling
Framtida trender inkluderar framsteg inom AI och säkra databehandlingsteknologier, såsom kvantkryptering och integritetsskyddande teknologier (PETs). Dessa innovationer lovar att ge ännu starkare säkerhetsåtgärder för att skydda känslig data. För företag som hanterar stora volymer av PDF-dokument erbjuder en Python PDF-parser en skalbar lösning för dokumentbearbetning. Verktyg för intelligent dokumentbearbetning, såsom AnyParser, ligger i framkant av innovation inom dataskydd och säkerhet.
Kontinuerlig anpassning till föränderliga hot
Cyberhotens landskap förändras ständigt. Företag måste hålla sig uppdaterade med nya säkerhetsmetoder och kontinuerligt anpassa sig till nya hot för att säkerställa fortsatt skydd av känslig data.
Slutsats
Att skydda känslig data i dokumentparsing är av yttersta vikt. Genom att anta bästa metoder, utnyttja avancerad teknik och säkerställa regulatorisk efterlevnad kan företag skydda sin data och upprätthålla sina kunders förtroende. Att prioritera datasäkerhet skyddar inte bara företaget utan säkerställer också integriteten och säkerheten för individer vars data bearbetas.
Uppmaning till handling: Anamma AnyParser för säker dokumentparsing
För att skydda känslig data och effektivisera dina dokumentparsingprocesser, överväg att anta AnyParser. Detta kraftfulla verktyg erbjuder en omfattande uppsättning funktioner som är utformade för att förbättra både säkerheten och effektiviteten i dina databehandlingsmetoder. Besök AnyParser's sandbox för att testa dess kapabiliteter GRATIS och se hur det kan gynna din organisation. Ta det första steget mot en mer säker och efterlevande dokumentparsingstrategi idag.