Vad är Strukturerad Data och Ostrukturerad Data
I den digitala informationseran genereras data hela tiden, och företag skapar värde genom analys och bearbetning av data. Därför har insamling och registrering av data samt bearbetning och analys av data blivit två viktiga uppgifter i affärsverksamheten. I processen för datainsamling stöter man oftare på ostrukturerad data, vars källa och form är mångsidiga och svåra att klassificera eller söka enkelt. Effektiv datainhämtning är avgörande för organisationer för att effektivt omvandla rådata till handlingsbara insikter. I processen för databehandling är det strukturerad data som oftare förekommer, vilket har en tydlig struktur, väldefinierad information och kan enkelt organiseras, sökas och analyseras. Därför är omvandlingen av ostrukturerad data till strukturerad data ett viktigt steg för företag att utnyttja datavärdet.
Strukturerad Data
Strukturerad data är data som passar in i en fördefinierad datamodell eller schema. Det är särskilt användbart för att hantera diskret, numerisk data som finansiella transaktioner, försäljnings- och marknadsföringsfigurer samt vetenskaplig modellering.
Strukturerad data är typiskt kvantitativ och organiserad på ett sätt som gör den lätt att söka. Den inkluderar vanliga typer som namn, adresser, kreditkortsnummer, telefonnummer, stjärnbetyg, bankinformation och annan data som enkelt kan frågas med SQL i relationsdatabaser.
Exempel på strukturerad data i verkliga tillämpningar inkluderar flyg- och reservationsdata vid bokning av en flygning, samt kundbeteende och preferenser i CRM-system som Salesforce. Det är bäst för associerade samlingar av diskreta, korta, icke-kontinuerliga numeriska och textvärden och används för lagerkontroll, CRM-system och ERP-system.
Strukturerad data lagras i relationsdatabaser, grafdatabaser, rumsliga databaser, OLAP-kuber och mer. Dess största fördel är att den är lättare att organisera, rengöra, söka och analysera, men den största utmaningen är att all data måste passa in i den föreskrivna datamodellen.
Ostrukturerad Data
Ostrukturerad data är data utan en underliggande modell för att urskilja attribut. Den används när datan inte passar in i ett strukturerat dataformat, såsom videövervakning, företagsdokument och inlägg på sociala medier.
Exempel på ostrukturerad data inkluderar en mängd olika format som e-post, bilder, videofiler, ljudfiler, inlägg på sociala medier, PDF-filer och mer. Ungefär 80-90% av data är ostrukturerad, vilket innebär att den har stor potential för konkurrensfördelar om företag kan utnyttja den.
Exempel på ostrukturerad data i verkliga tillämpningar inkluderar chatbots som utför textanalys för att svara på kundfrågor och ge information, samt data som används för att förutsäga förändringar på aktiemarknaden för investeringsbeslut. Ostrukturerad data är bäst för associerade samlingar av data, objekt eller filer där attributen förändras eller är okända, och den används med presentations- eller ordbehandlingsprogram och verktyg för att visa eller redigera media. Ostrukturerad tilläggstjänstdata, såsom inlägg på sociala medier och kundfeedback, kan ge värdefulla insikter när de konverteras till strukturerade format.
Den lagras typiskt i datalager, NoSQL-databaser, datalager och applikationer. Den största fördelen med ostrukturerad data är dess förmåga att analysera data som inte lätt kan formas till strukturerad data, men den största utmaningen är att den kan vara svår att analysera. Huvudanalystekniken för ostrukturerad data varierar beroende på kontexten och de verktyg som används.
Skillnad mellan Strukturerad och Ostrukturerad Data
Fördelar med Strukturerad Data och Nackdelar med Ostrukturerad Data
Strukturerad data erbjuder fördelen av att vara lätt sökbar och användbar för maskininlärningsalgoritmer, vilket gör den tillgänglig för företag och organisationer för att tolka data. Det finns också fler verktyg tillgängliga för att analysera strukturerad data än för ostrukturerad data. Å andra sidan kräver ostrukturerad data att datavetare har expertis i att förbereda och analysera datan, vilket kan begränsa andra anställda i organisationen från att få tillgång till den. Dessutom behövs speciella verktyg för att hantera ostrukturerad data, vilket ytterligare bidrar till dess brist på tillgänglighet.
Analys av Strukturerad Data vs. Analys av Ostrukturerad Data
Analys av strukturerad data är typiskt mer rak på sak eftersom datan är strikt formaterad, vilket möjliggör användning av programmeringslogik för att söka efter och lokalisera specifika datauppgifter, samt för att skapa, ta bort eller redigera poster. Detta gör automatisering av datamanagement och analys av strukturerad data mer effektiv. I kontrast saknar analys av ostrukturerad data fördefinierade attribut, vilket gör det svårare att söka och organisera. Analys av ostrukturerad data kräver ofta komplexa algoritmer för att förbehandla, manipulera och analysera, vilket utgör en större utmaning i analysprocessen. Analys av ostrukturerad tilläggstjänstdata kräver ofta avancerade parsningstekniker för att extrahera meningsfull information.
Hantering av Strukturerad Data vs. Hantering av Ostrukturerad Data
Hanteringen av strukturerad data är generellt mer effektiv på grund av dess organiserade och förutsägbara natur. Datorer, datastrukturer och programmeringsspråk kan lättare förstå strukturerad data, vilket leder till minimala utmaningar i dess användning. Å sin sida presenterar hanteringen av ostrukturerad data två betydande utmaningar: lagring, eftersom hanteringen av ostrukturerad data typiskt står inför större bearbetning än hanteringen av strukturerad data, och analys, eftersom hanteringen av ostrukturerad data inte är lika rak som analysen av strukturerad data. För att förstå och hantera ostrukturerad data måste datorsystem först bryta ner den i förståeliga komponenter, vilket är en mer komplex process.
Sammanfattning av Skillnaden mellan Strukturerad och Ostrukturerad Data
Strukturerad data är definierad och sökbar, inklusive data som datum, telefonnummer och produkt-SKU:er. Detta gör den lättare att organisera, rengöra, söka och analysera jämfört med ostrukturerad data, som omfattar allt annat som är svårare att kategorisera eller söka, såsom foton, videor, podcasts, inlägg på sociala medier och e-post. En mening för att förklara skillnaden mellan strukturerad och ostrukturerad data: Det mesta av datan i världen är ostrukturerad, men den strukturerade datans lätthet i hantering och analys ger den en betydande fördel i tillämpningar där data kan organiseras prydligt och snabbt nås.
Exempel på Strukturerad och Ostrukturerad Data
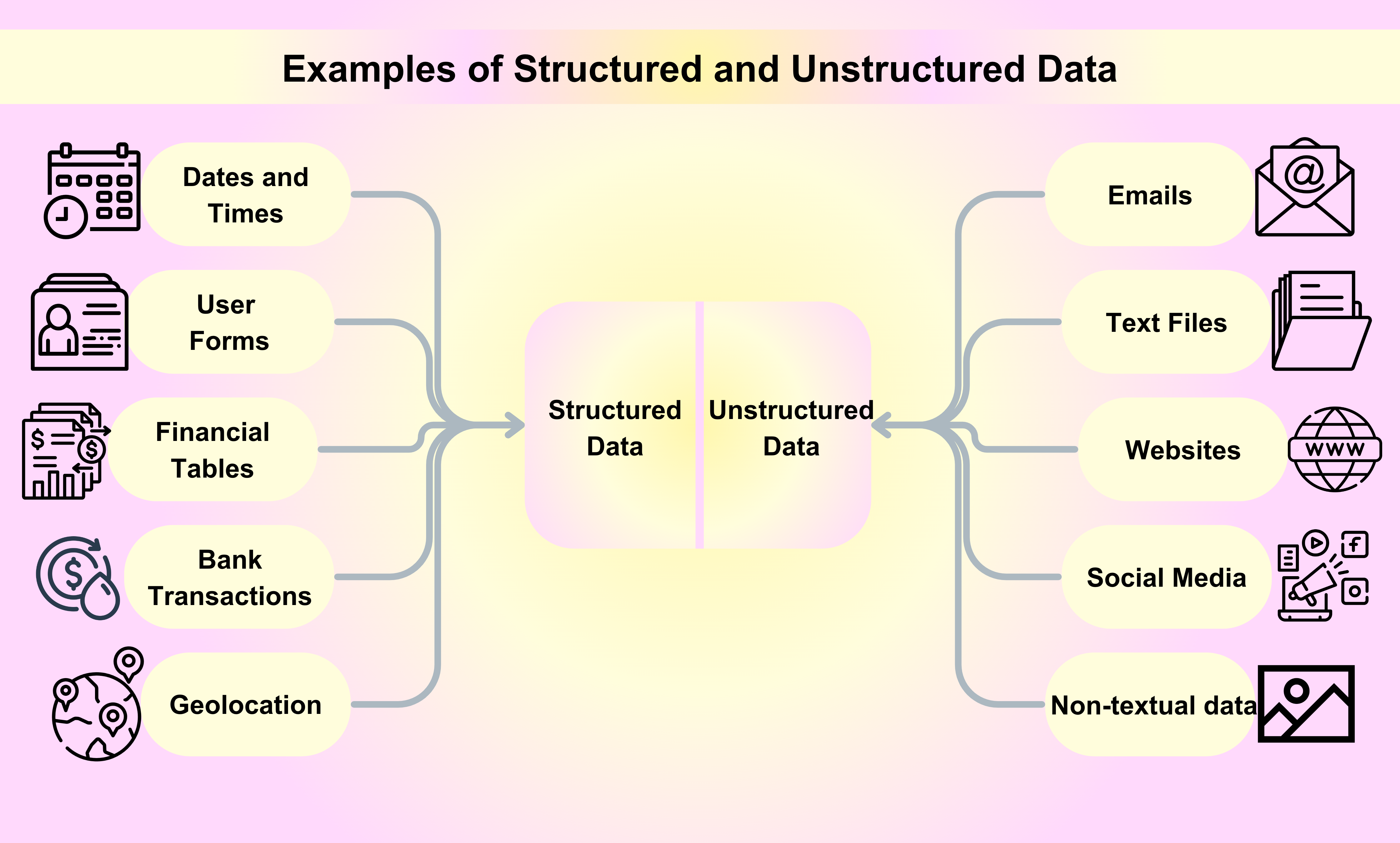
Exempel på Strukturerad Data
-
Datum och Tider: Datum och tider följer ett specifikt format, vilket gör det lätt för maskiner att läsa och analysera dem. Till exempel kan ett datum struktureras som YYYY-MM-DD, medan en tid kan struktureras som HH:MM:SS.
-
Kundnamn och Kontaktinformation: När du registrerar dig för en tjänst eller köper en produkt online samlas ditt namn, e-postadress, telefonnummer och annan kontaktinformation in och lagras på ett strukturerat sätt.
-
Finansiella Transaktioner: Finansiella transaktioner som kreditkortstransaktioner, bankinsättningar och överföringar är alla exempel på strukturerad data. Varje transaktion kommer med specifik information i form av ett serienummer, ett transaktionsdatum, beloppet och de involverade parterna.
-
Aktieinformation: Aktieinformation såsom aktiepriser, handelsvolymer och marknadsvärde är ett annat exempel på strukturerad data. Denna information är systematiskt organiserad och uppdateras i realtid.
-
Geolokalisering: Geolokaliseringdata, inklusive GPS-koordinater och IP-adresser, används ofta i olika applikationer, från navigationssystem till platsbaserade marknadsföringskampanjer.
Exempel på Ostrukturerad Data
-
E-post: E-post är bland de mest populära exemplen på ostrukturerad data som vi använder varje dag för affärs- eller personliga ändamål.
-
Textfiler: Exempel på ostrukturerad data inkluderar ordbehandlingsfiler, kalkylblad, PDF-filer, rapporter och presentationer.
-
Webbplatser: Innehåll från webbplatser som YouTube, Instagram och Flickr betraktas som exempel på ostrukturerad data.
-
Sociala Medier: Data som genereras från sociala medieplattformar som Facebook, Twitter och LinkedIn är exempel på ostrukturerad data.
-
Media: Digitala bilder, ljudinspelningar och videor representerar en stor mängd icke-textuell data på ett ostrukturerat sätt som kan betraktas som exempel på ostrukturerad data.
Tekniker för Analys av Strukturerad Data
-
SQL-frågor: Strukturerad data kan effektivt frågas med SQL (Structured Query Language), vilket möjliggör snabb hämtning och manipulation av data som lagras i relationsdatabaser.
-
Data Warehouse: Strukturerad data kan lagras i datalager, som integrerar data från flera källor och stödjer komplexa frågor och analyser.
-
Maskininlärningsalgoritmer: Algoritmer kan enkelt bearbeta strukturerad data för att identifiera mönster och göra förutsägelser.
Strukturerad data är lätt att förstå och manipulera, vilket gör den tillgänglig för en bred grupp användare. Strukturerad data möjliggör effektiv lagring, hämtning och analys, vilket påskyndar beslutsprocesser. System för strukturerad data kan skalas för att hantera stora volymer av data, vilket säkerställer att prestandan förblir hög när datan växer.
Tekniker för Analys av Ostrukturerad Data
-
Natural Language Processing (NLP): NLP-tekniker används för att analysera textdata, extrahera meningsfull information och insikter från stora volymer ostrukturerad text.
-
Maskininlärning: Maskininlärningsalgoritmer kan tränas för att känna igen mönster i ostrukturerad data, såsom bilder eller ljudfiler.
-
Datalager: Ostrukturerad data kan lagras i datalager, som tillåter lagring av rådata i sitt ursprungliga format tills den behövs för analys.
Från exemplen på tekniker för analys av ostrukturerad data är analys av ostrukturerad data mer komplex och kräver specialiserade verktyg och tekniker. Bearbetning av ostrukturerad data kräver ofta betydande datorkapacitet och lagringskapacitet. Ostrukturerad data kan innehålla inkonsekvenser, fel eller irrelevant information, vilket gör det utmanande att säkerställa datakvalitet. Att strömlinjeforma datainhämtning kan avsevärt förbättra en organisations förmåga att hantera och analysera stora volymer av data.
Exempel på Behovet av att Konvertera Ostrukturerad Data till Strukturerad Data
-
Analys av Kundfeedback: Att konvertera kundrecensioner och feedback från ostrukturerad text till strukturerad data gör det möjligt för företag att utföra sentimentanalys och identifiera trender i kundnöjdhet.
-
Medicinska Journaler: Att strukturera ostrukturerade medicinska journaler, såsom läkarens anteckningar och avbildningsrapporter, möjliggör bättre integration med elektroniska journaler (EHR) och förbättrar patientvården.
-
Efterlevnad och Rapportering: Processen för datainhämtning innebär att extrahera, ladda och transformera data från olika källor till ett format som är lämpligt för analys. Organisationer kan behöva konvertera ostrukturerad data till strukturerade format för att uppfylla regulatoriska krav och underlätta korrekt rapportering.
-
Marknadsundersökningar: Att konvertera ostrukturerad data från enkäter och fokusgrupper till strukturerad data hjälper till att analysera marknadstrender och konsumentbeteende.
Hur AnyParser Kan Parsning Ostrukturerad Data till Strukturerad Data
AnyParser, utvecklad av CambioML, är ett kraftfullt dokumentparsningsverktyg som är utformat för att extrahera information från olika ostrukturerade datakällor som PDF-filer, bilder och diagram, och konvertera dem till strukturerade format. Det utnyttjar avancerade Vision Language Models (VLM) för att uppnå hög noggrannhet och effektivitet i dataextraktionen.
Nyckelfunktioner
-
Precision: Extraherar noggrant text, siffror och symboler samtidigt som den behåller den ursprungliga layouten och formatet.
-
Integritet: Bearbetar data lokalt för att säkerställa skyddet av användarens integritet och känslig information.
-
Konfigurerbarhet: Gör det möjligt för användare att definiera anpassade extraktionsregler och utdataformat.
-
Stöd för Flera Källor: Stöder extraktion från olika ostrukturerade datakällor, inklusive PDF-filer, bilder och diagram.
-
Strukturerad Utdata: Konverterar extraherad information till strukturerade format som Markdown, CSV eller JSON.
Steg för att Parsning Ostrukturerad Data med AnyParser
-
Ladda upp Ditt Dokument: Börja med att ladda upp din ostrukturerade datafil (t.ex. PDF, bild) till AnyParser's webbgränssnitt. Du kan dra och släppa din fil eller klistra in en skärmdump för snabb bearbetning.
-
Välj Extraktionsalternativ: Välj vilken typ av data du vill extrahera. Om du till exempel behöver extrahera tabeller från en PDF, välj alternativet "Endast Tabell".
-
Bearbeta Dokumentet: AnyParser's API-motor kommer att bearbeta dokumentet, noggrant upptäcka och extrahera den nödvändiga informationen. Verktyget använder avancerade VLM-tekniker för att identifiera relevanta datapunkter och konvertera dem till ett strukturerat format.
-
Förhandsgranska och Verifiera: Granska den extraherade datan med AnyParser's förhandsgranskningsfunktion. Jämför den initiala extraktionen med det ursprungliga dokumentet för att säkerställa noggrannhet.
-
Ladda ner eller Exportera: När du är nöjd med extraktionen, ladda ner den strukturerade datafilen (t.ex. CSV, Excel) eller exportera den direkt till plattformar som Google Sheets för vidare analys.
Fördelar med att Använda AnyParser
-
Effektivitet och Noggrannhet: Automatiserar dataextraktionsuppgifter, minskar manuellt arbete och minimerar fel.
-
Datasäkerhet: Säkerställer att känslig information bearbetas lokalt, i enlighet med dataskyddsstandarder.
-
Flexibel Anpassning: Användare kan skräddarsy extraktionsparametrar och utdataformat för att passa specifika behov.
-
Förbättrad Analytisk Fokus: Förenklar dataextraktion, vilket gör att yrkesverksamma kan fokusera på mer värdefull analys.
Tillämpningar
-
AI-ingenjörer: Extrahera text och layoutinformation från PDF-filer för att utveckla och träna AI-modeller.
-
Finansiella Analytiker: Extrahera numerisk data från PDF-tabeller för noggrann finansiell analys.
-
Datavetare: Bearbeta stora volymer av ostrukturerade dokument för att avslöja insikter och trender.
-
Företag: Automatisera bearbetningen och analysen av olika dokument, såsom kontrakt och rapporter, för att förbättra operativ effektivitet.
Genom att utnyttja AnyParser kan användare omvandla komplex ostrukturerad data till strukturerade, redigerbara filer, vilket sömlöst integreras i deras arbetsflöden för förbättrad dataanalys och hantering.
Slutsats
I den digitala eran är det avgörande för företag att konvertera ostrukturerad data till strukturerade format med hjälp av verktyg som AnyParser för att låsa upp insikter och få en konkurrensfördel. AnyParser kan användas för att parsning ostrukturerad tilläggstjänstdata, vilket gör det enklare att integrera i affärsintelligenssystem. Genom att strömlinjeforma denna process kan organisationer effektivt utnyttja hela potentialen av sin data, vilket driver bättre beslutsfattande och strategisk planering.