Karmaşık PDF'leri Markdown'a dönüştürmek zorlayıcı olabilir. PDF'den metin çıkarmak için birçok açık kaynak kütüphane mevcut, ancak tablolar ve grafikler gibi karmaşık öğeler içeren PDF'lerde sonuçlar genellikle tatmin edici olmaktan uzaktır. GPT veya Claude gibi popüler büyük dil modelleri bu görevleri yerine getirebilir, ancak genellikle yavaş çalışır ve bazen hatalı çıktılar üretir. Geleneksel OCR araçları, daha basit belgeler için etkili olsa da, genellikle orijinal içeriğin tam yapısını ve anlamsal anlamını korumakta zorlanır. Öte yandan, görsel-dil modelleri bazen hayal gücüyle yanlış sonuçlar üretebilir. Bu blog, ayrıştırmanın ne anlama geldiğini açıklayacak ve birden fazla metriği kullanarak çeşitli modellerin karşılaştırmalı analizinin sonuçlarını detaylandıracaktır.
Ayrıştırma ne anlama geliyor?
PDF ayrıştırma bağlamında, "ayrıştırma", bir PDF dosyasından belirli verileri çıkarmak için PDF ayrıştırıcı olarak bilinen özel yazılımların kullanılmasını ifade eder. Bir PDF ayrıştırıcı, bir PDF belgesinin içeriğini analiz eder ve metin, resimler, yazı tipleri, düzenler ve hatta meta veriler gibi öğeleri tanımlar. Çıkarılan veriler daha sonra XML, JSON veya Excel/CSV gibi farklı formatlara düzenlenip aktarılabilir; bu da veri analizi, kayıt tutma veya iş akışlarının otomasyonu gibi çeşitli amaçlar için kullanılabilir.
Ayrıştırmanın ne anlama geldiğini anlamak, özellikle farklı PDF'den Markdown'a dönüşüm araçlarını karşılaştırırken bir ayrıştırma çözümünün etkinliğini değerlendirmek için önemlidir; çünkü PDF ayrıştırıcı, yalnızca basit metin çıkarımından daha fazlasını içerir—belgenin anlamsal yapısını tanımayı ve korumayı gerektirir.
Bu ayrıştırma çözümlerinin kalitesini nasıl ölçeriz?
Farklı modellerin performansını değerlendirmek için bir dizi kelime düzeyinde metrik tanımladık ve temel faktörlere odaklandık:
-
Kesinlik, Geri Çağırma ve F-Ölçütü: Ayrıştırmanın kalitesini ve bütünlüğünü değerlendirme.
-
BLEU Skoru ve ANLS: Dil ve düzen yapısını değerlendirmek için yararlıdır.
-
Düzenleme Mesafesi, Jensen-Shannon Sapması ve Jaccard Mesafesi: OCR alanına özgü metriklerdir ve içerik yeniden üretiminin doğruluğunu anlamak için özellikle faydalıdır.
Görsel-dil modelimiz AnyParser, hız ve doğruluğu birleştirerek, özellikle tablolar ve anlamsal öğeler içeren karmaşık düzenlerde olağanüstü bir performans sergilemektedir. AnyParser diğer çözümleri geride bırakıyor, GPT/Claude gibi modellere göre 20 kat hız artışı sağlarken daha yüksek doğruluk elde ediyor.
Önde Gelen Ayrıştırma Modellerine Karşı Kapsamlı Bir Karşılaştırma Sonucu
İstatistiksel nesne
AnyParser'ın yeteneklerini gerçekten sergilemek için, sektördeki önde gelen ayrıştırma modelleri ve tanınmış Büyük Dil Modelleri (LLM'ler) ile kapsamlı bir karşılaştırma gerçekleştirdik. Değerlendirmemiz şunları içeriyordu:
1. Büyük Dil Modelleri
- AnyParser
- OpenAI'nin GPT-4o
- Google'ın Gemini 1.5 Pro
- Anthropic'in Claude 3.5 Sonnet
2. OCR Tabanlı Hizmetler
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Sonuçların Sunumu ve Analizi
Deney 1
Öncelikle, aşağıdaki 5 metrik üzerinde farklı doküman AI modellerinin performansını titiz bir şekilde karşılaştırdık: BLEU, Kesinlik ve geri çağırma, F-Ölçütü ve ANLS. Bu tanımların matematiksel tanımını ek bölümde bulabilirsiniz.
Karşılaştırılan modeller: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl ve Azure-DocAl.
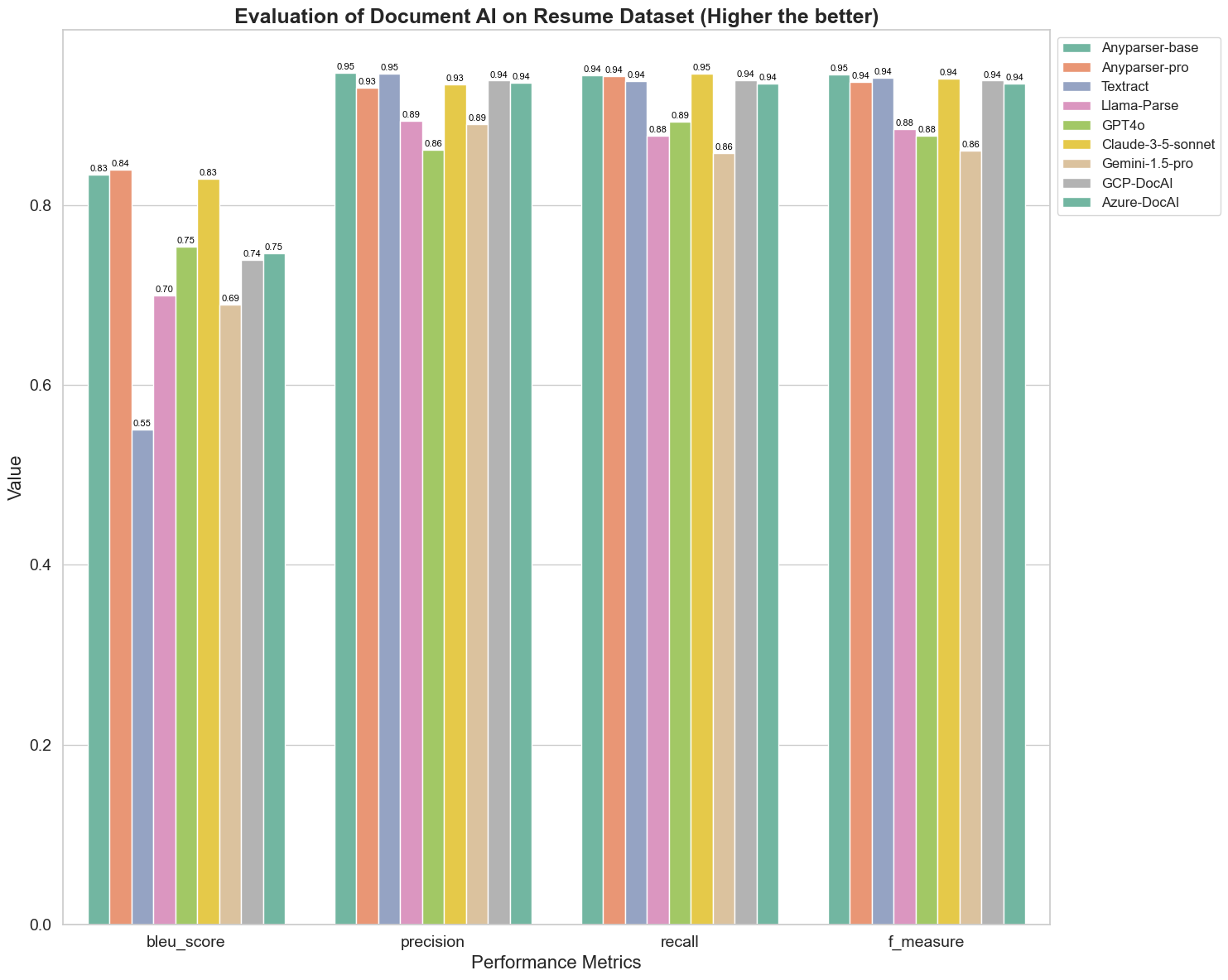
BLEU, iki dilli yorumlamanın kalitesini değerlendirmek için kullanılır ve modellerin ifadeleri işleme kalitesini test eder. Bu ayrıştırma modellerinin BLEU değerlendirme yöntemi altındaki sonuçlarını karşılaştırarak, AnyParser-base ve AnyParser-pro'nun puanlarının diğer modellerin puanlarından önemli ölçüde daha yüksek olduğunu, Amazon Textract'ın en düşük puanı aldığını ve diğer modellerin puanlarının ortalama bir seviyede olduğunu buluyoruz.
Tanıma doğruluğu genellikle kesinlik ve geri çağırma ile temsil edilir; burada kesinlik, model tarafından doğru olarak değerlendirilen sonuçlar arasındaki gerçekten doğru sonuçların yüzdesini temsil eder, geri çağırma ise model tarafından gerçekten doğru olarak değerlendirilen sonuçların, tüm gerçekten doğru sonuçlar arasındaki yüzdesini temsil eder. Bu ayrıştırma modellerinin kesinlik ve geri çağırmasını karşılaştırarak, Llama-Parse, GPT4o ve Gemini-1.5-pro dışındaki tüm diğer modellerin yüksek seviyede olduğunu buluyoruz. Bunlar arasında, AnyParser ve Amazon Textract kesinlikte daha belirgin, AnyParser-base ve AnyParser-pro ise geri çağırmada daha belirgin. Modelin Kesinlik üzerindeki daha yüksek puanı, modelin üretim sonuçlarında daha fazla doğru bilgi çıkardığını gösterirken, geri çağırmadaki daha yüksek puan, modelin örnekten doğru bilgi elde etme yeteneğinin daha yüksek olduğunu gösterir. Puanların sonuçları, AnyParser'ın PDF'den metin çıkarmada tanıma doğruluğu açısından belirgin bir avantaja sahip olduğunu göstermektedir.
F-Ölçütü, bu iki gösterge üzerindeki kesinlik ve geri çağırmanın kapsamlı bir değerlendirme indeksidir. Bu ayrıştırma modellerinin F-Ölçütü altındaki puanlarını karşılaştırarak, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI ve Azure-DocAI'nın diğer modellere kıyasla tanıma doğruluğu açısından daha iyi bir güce sahip olduğunu daha sezgisel bir şekilde görebiliriz. AnyParser, F-Ölçütü altında en yüksek puanı alarak, PDF'den metin çıkarma konusundaki tanıma doğruluğundaki belirgin avantajını daha da göstermektedir.
ANLS, karakter düzeyinde orijinal metin ile hedef metin arasındaki doğruluk ve benzerliği ölçerken yaygın olarak kullanılan bir değerlendirme indeksidir ve modellerin ayrıştırma seviyesini ölçmek için de oldukça bilgilendiricidir. AnyParser-base, AnyParser-pro ve Azure-DocAI'nın daha yüksek puanları, bu modellerin diğer modellere kıyasla daha yüksek ayrıştırma seviyesini yansıtmaktadır.
Genel olarak, AnyParser-base ve AnyParser-pro diğer modellere göre daha iyi performans göstermektedir.
Deney 2
Ayrıca, Edit Mesafesi, Jensen-Shannon Sapması ve Jaccard Mesafesi gibi üç farklı metrik üzerinde farklı doküman AI modellerinin performansını karşılaştırıyoruz. Bu metrikler, modellerin çıktısı ile bir referans belgesi arasındaki benzerliği ölçmek için kullanılır. Daha düşük değerler daha iyi performansı gösterir.
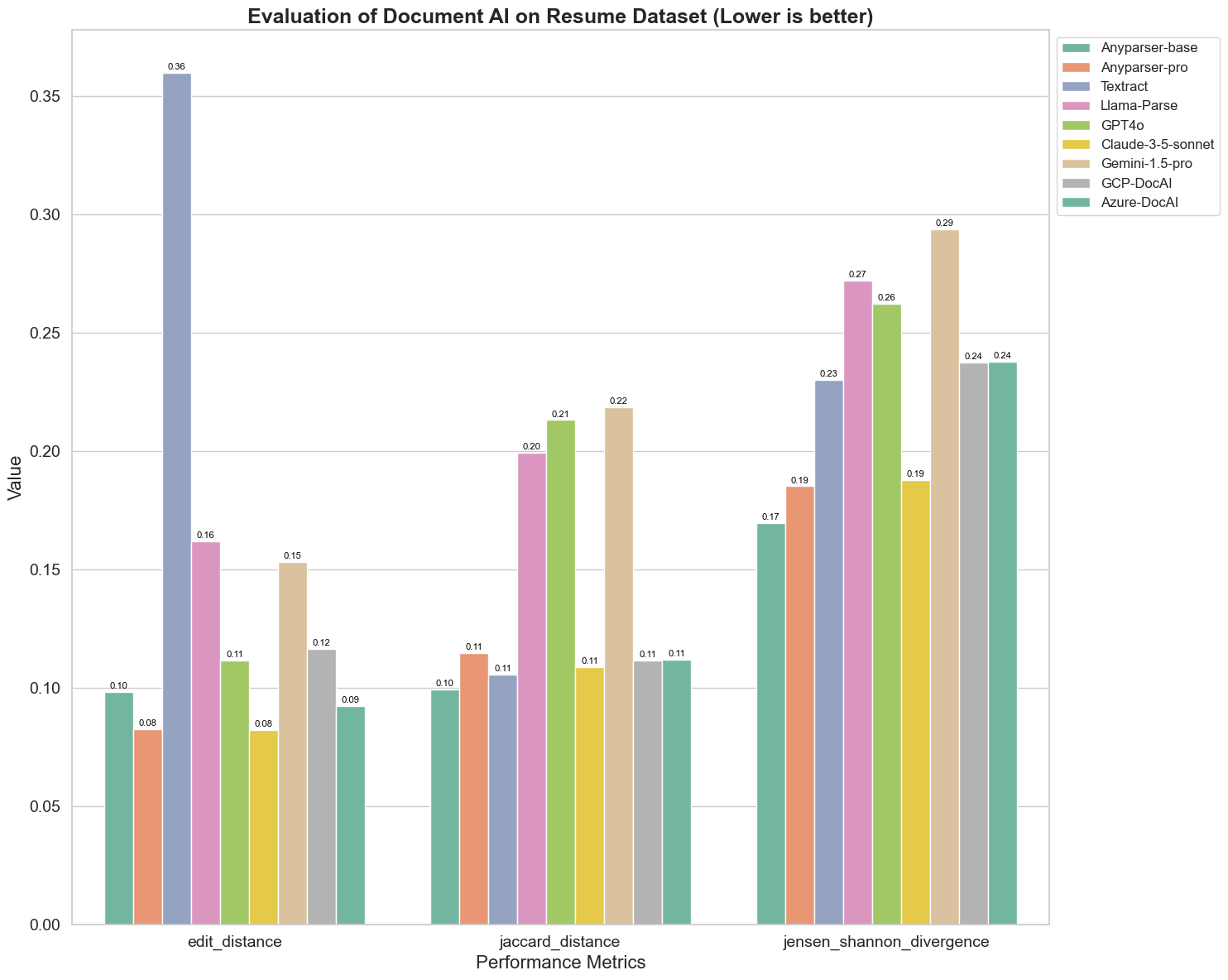
Grafikten bazı önemli gözlemler:
-
Edit Mesafesi: AnyParser-base ve AnyParser-pro modelleri en düşük edit mesafesi ile en iyi performansı gösteriyor; bu, çıktılarının referans belgesine en yakın olduğunu gösteriyor.
-
Jensen-Shannon Sapması: AnyParser-base ve AnyParser-pro en düşük sapmaya sahip, bu da çıktılarının kelime dağılımı açısından referans belgesine en benzer olduğunu ima ediyor.
-
Jaccard Mesafesi: Llama-parse, GPT4O, Gemini-1.5 dışındaki tüm diğer modeller, en düşük Jaccard mesafesi ile iyi bir performans sergiliyor; bu, çıktılarının kullanılan kelimeler seti açısından referans belgesi ile en yüksek örtüşmeye sahip olduğunu gösteriyor.
Sonuç
Genel olarak, titiz testlerimiz AnyParser-base ve AnyParser-pro'nun çeşitli metrikler üzerinde genellikle iyi performans gösterdiğini, bu durumun doğru doküman işleme potansiyelini gösterdiğini önermektedir. Grafiklerden, Amazon Textract gibi geleneksel OCR modellerinin, görsel dil modellerine göre çok daha düşük puan aldığını görebiliriz. Ancak, farklı modellerin performansı kullanılan metriklere bağlı olarak değişmektedir; bu da AI modellerini karşılaştırırken birden fazla değerlendirme kriterinin dikkate alınmasının önemini vurgulamaktadır.
Açık Kaynak Değerlendirme Pipeline'ımızı Tanıtıyoruz
Değerlendirmeleri kolaylaştırmak için, ayrıştırma modellerini karşılaştırmak için endüstri standardı bir yöntem sağlayan bir değerlendirme pipeline'ı oluşturduk. Örneğimizde, özgeçmiş ayrıştırmanın yaygın olduğu İK alanında kullanımını gösteriyoruz. 128 özgeçmişten oluşan çeşitli bir sentetik veri seti oluşturduk; bu veri seti, eşleştirilmiş resim-Markdown dosyaları kullanılarak oluşturuldu. GPT-4 kullanarak HTML içeriği ürettik, bunu görüntülere dönüştürdük ve çıkarılan metni karşılaştırma için gerçek veri olarak kullandık.
Ve en iyi kısım: Bu değerlendirme çerçevesini GitHub'da açık kaynak olarak paylaştık! İster bir geliştirici, ister bir iş kullanıcısı olun, pipeline'ımız farklı modellerin ayrıştırma kalitesini kendi veri setiniz üzerinde değerlendirip karşılaştırmanıza olanak tanır.
Hızlı başlangıç kılavuzunu Github repo adresinde bulabilir ve farklı ayrıştırma modellerinin birbirleriyle nasıl karşılaştırıldığını görebilirsiniz. Modelimizin gücünü açık bir şekilde sergileyerek, güvenilir, hızlı ve doğru ayrıştırma yeteneklerine sahip kullanıcıları çekebileceğimize inanıyoruz.
Ek - Metrikler
1. Kesinlik
Kesinlik, ayrıştırılan içeriğin doğruluğunu ölçer ve alınan öğelerin ne kadarının doğru olduğunu gösterir. Ayrıştırmada, çıkarılan tüm kelimeler arasındaki doğru çıkarılan kelimelerin oranıdır.
Kesinlik = Gerçek Pozitifler (TP) / (Gerçek Pozitifler (TP) + Yanlış Pozitifler (FP))
- Gerçek Pozitifler (TP): Ayrıştırıcı tarafından doğru olarak tanımlanan kelimeler.
- Yanlış Pozitifler (FP): Ayrıştırıcı tarafından yanlış tanımlanan kelimeler.
2. Geri Çağırma
Geri çağırma, ayrıştırmanın tamlığını, yani orijinal belgede ne kadar ilgili kelimenin alındığını gösterir.
Geri Çağırma = Gerçek Pozitifler (TP) / (Gerçek Pozitifler (TP) + Yanlış Negatifler (FN))
- Yanlış Negatifler (FN): Ayrıştırıcı tarafından atlanan orijinal belgede bulunan kelimeler.
3. F-Ölçütü (F1 Skoru)
F1 Skoru, Kesinlik ve Geri Çağırmanın harmonik ortalamasıdır ve her iki metriği dengeleyerek ayrıştırma kalitesinin genel bir ölçüsünü verir.
F1 Skoru = 2 × (Kesinlik × Geri Çağırma) / (Kesinlik + Geri Çağırma)
4. BLEU Skoru (İki Dilli Değerlendirme Altı)
BLEU skoru, ayrıştırılan içerik ile orijinal metin arasındaki benzerliği ölçer ve kelimelerin sırasına özel bir vurgu yapar. Ayrıştırılan belgelerde dil ve yapı tutarlılığını değerlendirmek için özellikle yararlıdır, çünkü çıktıları orijinalden farklı bir sırada olanları cezalandırır.
5. ANLS (Ortalama Normalize Levenshtein Benzerliği)
ANLS, ayrıştırılan içerik ile orijinal metin arasındaki benzerliği nicelendirir ve normalize edilmiş edit mesafesini kullanır. Ayrıştırılan ve referans metinlerdeki her kelime çifti için Normalize Levenshtein Benzerliği (NLS) ortalamasını alarak hesaplanır. NLS şu şekilde hesaplanır:
NLS = 1 - (Levenshtein Mesafesi (LD)(ayrıştırılan kelime, orijinal kelime)) / max(Ayrıştırılan kelimenin uzunluğu, Orijinal kelimenin uzunluğu)
Daha sonra, ANLS, tüm kelime çiftleri için NLS'nin ortalamasıdır:
ANLS = (1/N) × Σ(NLS_i) için i=1'den N'ye
6. Edit Mesafesi
Edit Mesafesi, ayrıştırılan metni orijinaline dönüştürmek için gereken kelime düzeyindeki işlemlerin (ekleme, silme, değiştirme) sayısını hesaplar.
7. Jensen-Shannon Sapması
Jensen-Shannon Sapması, ayrıştırılan ve orijinal kelime sayıları arasındaki ayrışık olasılık dağılımlarının benzerliğini ölçer ve kelime sıklığındaki farklılıkları vurgular.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
burada M = (1/2)(P + Q) ve KL(P || Q) Kullback-Leibler sapmasıdır.
8. Jaccard Mesafesi
Jaccard Mesafesi, ayrıştırılan ve orijinal içerikteki kelime setleri arasındaki farklılığı ölçer ve kelime örtüşmesini değerlendirmek için kullanışlıdır.
Jaccard Mesafesi = 1 - |A ∩ B| / |A ∪ B|
burada |A ∩ B| A ve B arasındaki ortak elemanların sayısıdır,
|A ∪ B| ise her iki setteki benzersiz elemanların toplam sayısıdır.