Görsel Dil Modelleri (VLM'ler), belgelerin analizinde devrim yaratıyor ve geleneksel Optik Karakter Tanıma (OCR) sistemlerinin birçok sınırlamasını ele alıyor. OCR, görüntülerden metin dijitalleştirmek için temel bir teknoloji olmasına rağmen, karmaşık senaryolarla karşılaştığında önemli zorluklarla karşılaşıyor. Bu zorluklar arasında düşük kaliteli görüntülerdeki doğruluk sorunları, sınırlı bağlamsal anlayış, karışık dillerle ilgili güçlükler ve görsel unsurları yorumlama yeteneğinin olmaması yer alıyor. VLM'ler, gelişmiş bilgisayarla görmeyi doğal dil işleme yetenekleriyle birleştirerek umut verici bir çözüm sunuyor. Bu makalede, VLM'lerin OCR'nin eksikliklerini nasıl aştığı ve dijital çağda belge işleme için daha sağlam ve çok yönlü çözümler sağladığı incelenecektir.
OCR Nedir? Belge ayrıştırmada OCR süreçleri nelerdir?
Optik Karakter Tanıma (OCR), taranmış kağıt belgeleri, PDF dosyaları veya dijital bir kamera ile çekilmiş görüntüler gibi farklı belge türlerinin düzenlenebilir ve aranabilir verilere dönüştürülmesini sağlayan bir teknolojidir. Bu süreç, makinelerin dijital görüntüler içindeki basılı veya el yazısı metin karakterlerini tanımasını sağladığı için belge işleme ve PDF veri çıkarımı açısından kritik öneme sahiptir.
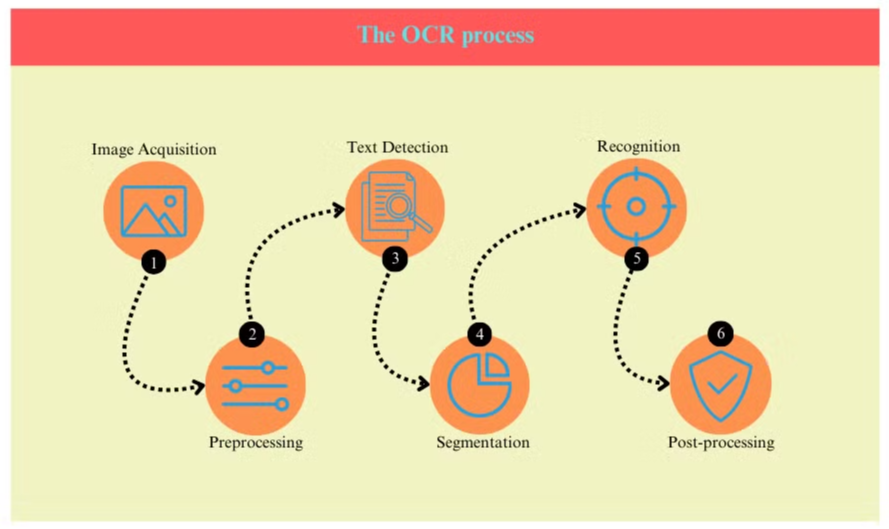
OCR Süreci
OCR süreci genellikle birkaç adımdan oluşur:
- Görüntü Edinme: Belge taranır veya fotoğraflanarak dijital bir görüntü oluşturulur.
- Ön İşleme: Görüntü temizlenir, gürültü kaldırılır ve parlaklık ile kontrast ayarlanır.
- Metin Tespiti: Sistem, görüntü içindeki metin içeren alanları tanımlar.
- Karakter Segmentasyonu: Metin alanları içindeki bireysel karakterler izole edilir.
- Karakter Tanıma: Her karakter analiz edilir ve bilinen karakterler veritabanıyla karşılaştırılır.
- Son İşleme: Tanınan metin, dilbilgisel ve bağlamsal bilgiler kullanılarak hata kontrolüne tabi tutulur.
OCR, belge ayrıştırma yeteneklerini büyük ölçüde geliştirmiş olsa da, karmaşık düzenler, düşük kaliteli görüntüler ve çeşitli yazı tipleriyle başa çıkmada hala sınırlamaları vardır. İşte bu noktada, görsel dil modelleri gibi gelişmiş teknolojiler, görüntülerden ve belgelerden veri çıkarımında doğruluğu ve anlama yeteneğini artırmak için devreye giriyor.
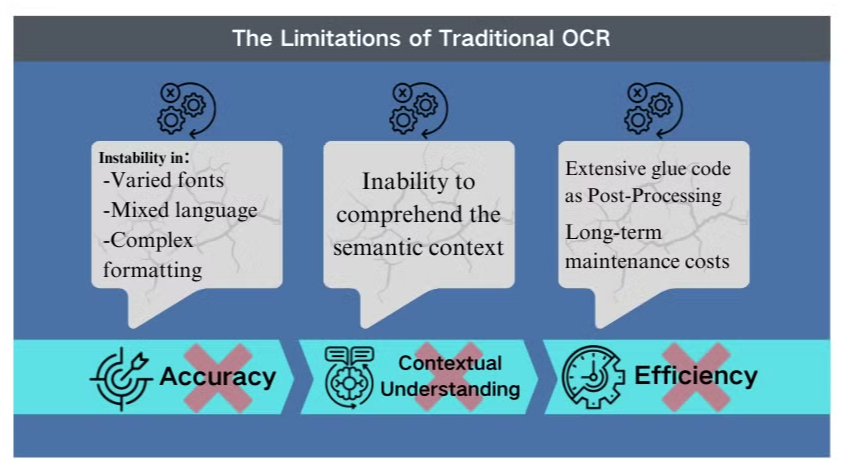
Geleneksel OCR Teknolojisinin Sınırlamaları
Karmaşık Senaryolarda Doğruluk Zorlukları
Geleneksel optik karakter tanıma (OCR) teknolojisi, temel metin çıkarımı için faydalı olsa da, karmaşık belge düzenleri veya düşük kaliteli görüntülerle karşılaştığında önemli engellerle karşılaşmaktadır. Bu sistemler, çeşitli yazı tipleri, karışık diller veya karmaşık biçimlendirme içeren belgeleri işlerken doğruluğu korumakta genellikle zorlanır. Örneğin, OCR, görüntü ağırlıklı sunumlardan veya yoğun biçimlendirilmiş PDF'lerden veri çıkarmaya çalışırken başarısız olabilir.
Bağlamsal Anlayış Eksikliği
Geleneksel OCR'nin en belirgin sınırlamalarından biri, işlediği metnin anlamsal bağlamını anlama yeteneğinin olmamasıdır. Bu eksiklik, hukuki sözleşmeler veya tıbbi raporlar gibi incelikli yorumlama gerektiren senaryolar söz konusu olduğunda özellikle belirgin hale gelir. OCR'nin bağlamsal farkındalık olmaksızın karakter tanımaya odaklanması, belirsiz karakterler veya sektöre özgü terminoloji ile başa çıkarken kritik yanlış anlamalara yol açabilir.
Son İşlemede Verimsizlikler
OCR'nin sınırlamaları genellikle kapsamlı son işleme çabalarını gerektirir. Bu ek adım, belge işleme için gereken zaman ve kaynakları önemli ölçüde artırabilir. Ayrıca, geleneksel OCR sistemleri genellikle grafikler, tablolar veya diğer metin dışı unsurlardan bilgi çıkarmakla görevlendirildiğinde yetersiz kalır ve belge çıkarım sürecini daha da karmaşık hale getirir. Bu verimsizlikler, daha kapsamlı bir belge analizi ve veri çıkarım yaklaşımı sunan görsel dil modelleri gibi daha gelişmiş çözümlere olan ihtiyacı vurgulamaktadır.
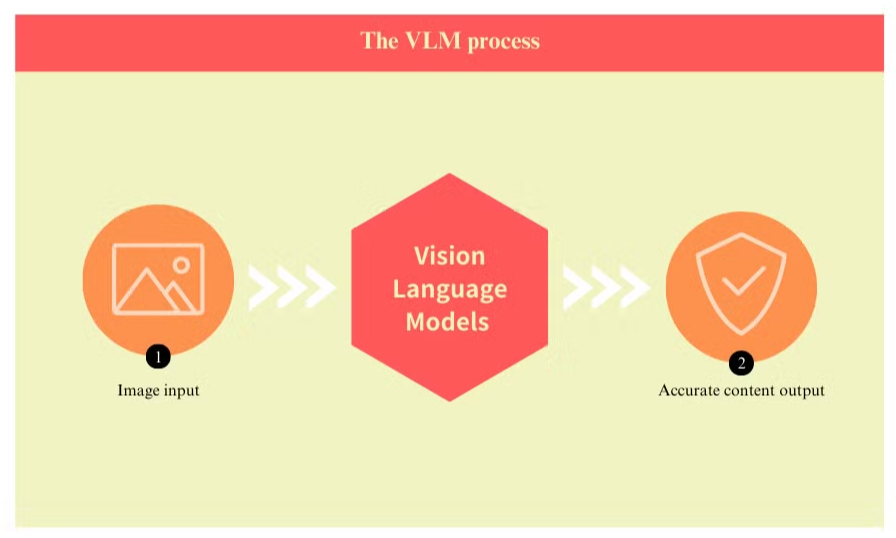
Görsel-Dil Modelleri Nedir ve OCR'yi Nasıl Geliştirir?
Görsel dil modelleri, belge işleme teknolojisinde önemli bir sıçramayı temsil eder ve geleneksel optik karakter tanıma (OCR) sistemlerinin birçok sınırlamasını ele alır. Bu gelişmiş modeller, belgelerin hem görsel hem de metinsel unsurlarını aynı anda anlamak için bilgisayarla görmeyi doğal dil işleme ile birleştirir.
Gelişmiş Doğruluk ve Bağlam Anlayışı
Düşük kaliteli görüntüler ve karmaşık düzenlerle başa çıkmada zorlanan OCR'nin aksine, görsel dil modelleri çeşitli belge formatlarını yorumlamada mükemmel bir performans sergiler. Zorlu senaryolarla karşılaştıklarında bile, görüntülerden, PDF'lerden ve diğer görsel içeriklerden verileri doğru bir şekilde çıkarabilirler. Bu geliştirilmiş doğruluk, bir belgenin tüm bağlamını dikkate alma yeteneklerinden kaynaklanır; yalnızca bireysel karakterler veya kelimelere odaklanmazlar.
Kapsamlı Veri Çıkarma
Görsel dil modelleri, basit metin tanımayı aşarak kapsamlı PDF veri çıkarım yetenekleri sunar. Belgeler içindeki tabloları, grafikleri ve şekilleri tanımlayıp yorumlayabilirler ve karmaşık düzenlerin bütünlüğünü korurlar. Bu bütünsel belge analizi yaklaşımı, daha incelikli ve tamamlayıcı bilgi alımını mümkün kılarak, çıkarılan verilerin sonraki uygulamalar için kullanımını önemli ölçüde artırır.
Çok Dilli ve Çok Formatlı Yeterlilik
Görsel dil modellerinin en önemli avantajlarından biri, birden fazla dil ve belge formatıyla başa çıkmadaki esneklikleridir. Karışık dillerle veya Latin alfabesi dışındaki yazılarla başa çıkmada zorlanan OCR sistemlerinin aksine, bu modeller çeşitli diller ve yazılar arasında içerikleri sorunsuz bir şekilde işleyebilir, bu da onları küresel belge işleme ihtiyaçları için vazgeçilmez kılar.
Belge Anlayışı için Görsel-Dil Modellerinin Ana Faydaları
Görsel dil modelleri, belge işleme ve veri çıkarımı için geleneksel OCR'ye göre önemli avantajlar sunar. Bu AI destekli sistemler, çeşitli belge türlerinde üstün sonuçlar elde etmek için görsel ve metinsel anlayışı birleştirir.
Gelişmiş Doğruluk ve Bağlamsal Anlayış
Görsel dil modelleri, karmaşık düzenler, düşük kaliteli görüntüler ve çeşitli yazı tipleriyle başa çıkmada mükemmel bir performans sergiler. Belirsiz karakterlerle başa çıkmada zorlanan OCR'nin aksine, bu modeller bağlamsal ipuçlarını kullanarak metni doğru bir şekilde yorumlayabilir. Bu yetenek, özellikle karmaşık yapılar veya düşük görüntü kalitesine sahip belgeler için PDF veri çıkarım doğruluğunu önemli ölçüde artırır.
Kapsamlı Bilgi Yakalama
OCR yalnızca metin tanımaya odaklanırken, görsel dil modelleri görüntülerden, tablolardan ve grafiklerden veri çıkarabilir. Bu bütünsel yaklaşım, belge işleme aşamasında kritik bilgilerin gözden kaçmamasını sağlar. Hem metinsel hem de görsel unsurları yakalayarak, bu modeller belge içeriklerinin daha tamamlayıcı bir anlayışını sunar.
Çok Dilli ve Çok Formatlı Yeterlilik
Görsel dil modelleri, çeşitli diller ve formatlar arasında belgeleri işleme konusunda olağanüstü bir esneklik gösterir. Karışık dilli belgeleri ve Latin alfabesi dışındaki yazıları sorunsuz bir şekilde işleyebilirler ve bu da geleneksel OCR sistemlerinin önemli bir sınırlamasını aşar. Bu çok yönlülük, farklı belge türleri ve dillerle başa çıkan küresel işletmeler için onları vazgeçilmez kılar.
VLM'nin Başaramadığı OCR'nin Gerçek Dünya Uygulamaları
Görsel dil modelleri, finans, insan kaynakları ve diğer sektörlerde belge işleme alanında devrim yaratıyor ve geleneksel OCR sistemlerinin kritik sınırlamalarını ele alıyor. Bu gelişmiş AI modelleri, endüstriler genelinde dijital dönüşüm çabalarını dönüştürerek, üstün doğruluk ve bağlamsal anlayış sunuyor.
Finansal Belge İşlemede Devrim
Görsel dil modelleri, finans alanında belge işleme süreçlerini dönüştürüyor ve geleneksel OCR'nin sınırlamalarını aşıyor. Bu gelişmiş modeller, karmaşık finansal tablolar, faturalar ve detaylı düzenlere sahip makbuzlardan veri çıkarmada mükemmel bir performans sergiliyor. OCR'nin aksine, bağlamı anlayabilir, belirsiz karakterleri (örneğin, sıfır ile O harfini ayırt etme) ve küresel finansal belgelerde sıkça bulunan karışık dilleri doğru bir şekilde yorumlayabilirler.
İnsan Kaynakları Operasyonlarını Akıllı Belge Analizi ile Geliştirme
İK sektöründe, görsel dil modelleri, özgeçmişler, çalışan kayıtları ve performans değerlendirmelerinden PDF veri çıkarımında son derece değerli hale geliyor. Bu modeller, belgelerin anlamsal yapısını anlayarak daha doğru bilgi alımı ve analizi sağlıyor. Bu yetenek, işe alım süreçlerini ve çalışan veri yönetimini önemli ölçüde kolaylaştırıyor; bu görevlerde OCR genellikle çeşitli formatlar ve el yazısı notları ile başa çıkmada zorlanıyor.
Uyum ve Risk Yönetimini İyileştirme
Görsel-dil modelleri, hem finans hem de İK alanında uyum ve risk yönetiminde özellikle etkilidir. Düzenleyici belgeler, sözleşmeler ve politikalar gibi kritik bilgileri daha yüksek doğrulukla çıkarmak ve yorumlamak için OCR'ye göre daha iyi bir belge işleme yeteneği sunarlar. Bu geliştirilmiş belge işleme yeteneği, yasal gerekliliklere daha iyi uyum sağlanmasını ve daha verimli risk değerlendirme prosedürlerini garanti eder.
Sonuç
Sonuç olarak, görsel dil modelleri, belge işleme teknolojisinde önemli bir sıçramayı temsil eder ve geleneksel OCR sistemlerinin birçok içsel sınırlamasını ele alır. Görsel ve metinsel anlayışı birleştirerek, bu gelişmiş modeller karmaşık düzenlerden karışık dillere ve düşük kaliteli görüntülere kadar geniş bir yelpazede zorlu senaryolar için üstün performans sunar. Kuruluşlar, operasyonlarını dijitalleştirmeye devam ederken ve belge havuzlarından değer çıkarma yollarını ararken, görsel dil modelleri, geliştiriciler ve mühendislik liderleri için güçlü bir araç olarak öne çıkmaktadır. Bağlamı anlama, çeşitli formatlarla başa çıkma ve daha doğru sonuçlar sağlama yetenekleri, onları karmaşık RAG boru hatları ve kurumsal çapta arama yetenekleri için anahtar bir sağlayıcı haline getirir ve nihayetinde dijital dönüşüm girişimlerini yeni zirvelere taşır.