OCR'nin ne anlama geldiğini hiç merak ettiniz mi? Optik Karakter Tanıma, metin görüntülerini makine tarafından okunabilir verilere dönüştüren güçlü bir teknolojidir. OCR, belgeleri dijitalleştirme ve bilgi çıkarma konusunda büyük faydalar sağlasa da, dezavantajları da vardır. Bu teknolojiyi keşfederken, hem yeteneklerini hem de sınırlamalarını anlamak çok önemlidir. Bu makalede, OCR'nin arkasındaki anlamı keşfedecek ve potansiyel dezavantajlarına dalacaksınız. Optik Karakter Tanıma hakkında kapsamlı bir anlayış kazanarak, bu teknolojiyi kendi iş akışlarınıza ve projelerinize nasıl uygulayacağınızı daha iyi belirleyebilirsiniz.
OCR ne anlama geliyor ve bir OCR nedir?
OCR ne anlama geliyor?
OCR, bilgisayarların çeşitli belge türlerini tanımasını ve dönüştürmesini sağlayan Optik Karakter Tanıma'nın kısaltmasıdır. Temelde, OCR, basılı veya el yazısı metni tarama ve bunu makine kodlu metne dönüştürme sürecidir. Bu, metnin aranabilir, düzenlenebilir ve kolayca aktarılabilir olmasını sağlar. OCR'nin ne anlama geldiğini anlamak, belge tarama ve metin tanıma teknolojileriyle çalışan herkes için gereklidir.
Bir OCR nedir?
Bu terime aşina olmayanlar için, "bir OCR nedir" sorusu, bilgisayarların görüntülerden veya taranmış belgelerden metin okumasını sağlayan Optik Karakter Tanıma teknolojisini ifade eder.
OCR, basılı veya el yazısı metni makine tarafından okunabilir verilere dönüştürerek kağıt ve dijital formatlar arasındaki boşluğu kapatır. Bu teknoloji, harf şekillerini, kelime yapılarını ve hatta tüm cümleleri tespit etmek için karmaşık algoritmalar kullanır. Böylece, statik görüntüleri düzenlenebilir ve aranabilir metin dosyalarına dönüştürür.
OCR teknolojisi, temelde bilgisayarla görme ve desen tanıma teknolojilerine dayanır. OCR, metin içeren belgeleri veya görüntüleri tarayarak ve metni dijital, düzenlenebilir bir formata tanımlamak ve dönüştürmek için gelişmiş algoritmalar kullanarak çalışır. OCR teknolojisinin tarihindeki önemli anlardan biri, 1974'te Ray Kurzweil'in neredeyse her fontta metin tanıyabilen bir omni-font OCR sistemi geliştirmesiydi. Yıllar içinde, OCR, basit şablon eşleştirmeden daha karmaşık sistemlere evrildi.
Yeteneklerine rağmen, OCR teknolojisi şu anda belirli sınırlamalarla karşı karşıyadır. Bunlar, düşük kaliteli görüntülerde metin tanımada zorluklar, karmaşık düzenler veya arka planlarla başa çıkmada zorluklar ve farklı fontlar, diller veya el yazılarıyla çalışırken değişen doğruluk gibi zorlukları içerir. Ayrıca, OCR sistemleri, renkli arka planlara sahip belgelerle, bulanık veya eğik belgelerle ve akıcı el yazılarıyla başa çıkmada zorluk yaşayabilir.
Optik Karakter Tanıma yazılımını anlama
Optik Karakter Tanıma yazılımı, çeşitli belge türlerini düzenlenebilir ve aranabilir verilere dönüştüren dönüştürücü bir teknolojidir. Bilgiyi daha erişilebilir ve yönetilebilir hale getirerek dünyamızı dijitalleştirmede kritik bir rol oynar. OCR yazılımı, metin görüntülerini makine tarafından okunabilir verilere dönüştürmek için karmaşık bir süreç kullanır.
OCR Yazılımı Nasıl Çalışır
1. Görüntü Edinme
OCR'nin yolculuğu, belgenin bir görüntüsünü yakalamakla başlar. Bu, bir tarayıcı veya dijital kamera aracılığıyla yapılabilir. Görüntü daha sonra bir bilgisayarın işleyebileceği dijital bir formata dönüştürülür.
2. Ön İşleme ve Görüntü İyileştirme
İkinci adım, görüntü kalitesini artırmayı içerir. Görüntü edinildikten sonra, daha iyi tanıma için kalitesini artırmak amacıyla ön işleme tabi tutulur. Bu adım, görüntünün kontrastını, parlaklığını ve keskinliğini ayarlamayı, ayrıca gürültü veya alakasız unsurları kaldırmayı içerebilir. Bu ön işleme aşaması, özellikle düşük kaliteli taramalar veya fotoğraflarla çalışırken doğru sonuçlar elde etmek için kritik öneme sahiptir.
3. Metin Tespiti
OCR yazılımı, ön işlenmiş görüntüyü analiz ederek metin içeren alanları tespit eder. Bunu, metne özgü olan kalıpları ve şekilleri, farklı kalınlık ve yüksekliklerdeki çizgileri arayarak yapar.
4. Karakter Segmentasyonu
Metin alanları tespit edildikten sonra, yazılım metni daha küçük birimlere, bloklara, satırlara, kelimelere veya hatta bireysel karakterlere ayırır. OCR yazılımı, karakterleri oluşturmak için pikselleri piksel piksel analiz eder. Görüntüyü daha küçük segmentlere ayırarak her bir karakteri izole eder.
5. Metin Tanıma ve Çıkarma
Yazılım daha sonra bu izole edilmiş şekilleri, her bir karakterin ne olduğunu belirlemek için bilinen karakter kalıplarının geniş bir veritabanıyla karşılaştırır. Yazılım, karakterlerden, çizgi, eğri veya açı sayısı gibi özellikler çıkarır. Bu özellikler, OCR'nin farklı karakterleri tanımasına ve ayırt etmesine yardımcı olur.
6. Son İşleme
Karakterler tanımlandıktan sonra, OCR sistemi, potansiyel hataları düzeltmek ve metni çıktı için biçimlendirmek amacıyla bir son işleme aşamasından geçer. Düzeltme yapılan metin daha sonra istenen formatta, örneğin bir Word belgesi veya aranabilir bir PDF olarak dışa aktarılır.
Optik Karakter Tanıma yazılımıyla kullanım durumları
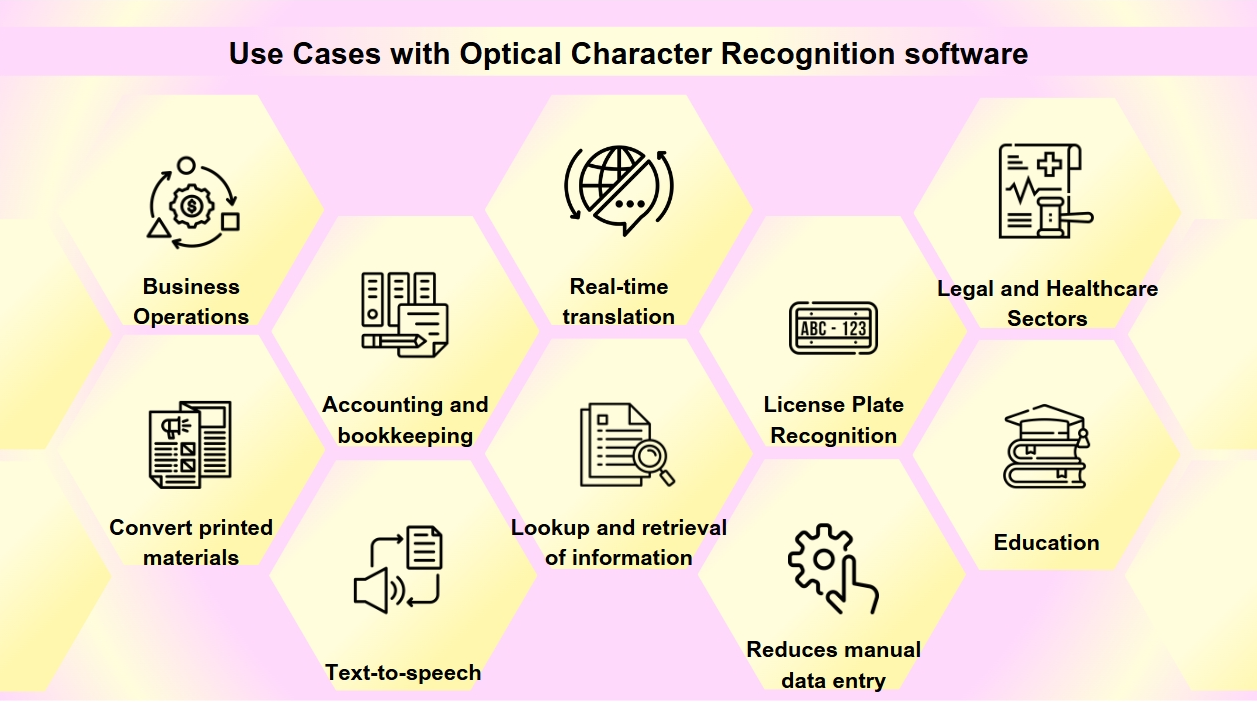
OCR, birçok endüstrinin dijital dönüşümünde temel bir araç haline gelerek süreçleri kolaylaştırmakta ve veri erişilebilirliğini ve doğruluğunu artırmaktadır. OCR'yi fark ettiğinizden daha sık karşılaşabilirsiniz. İş kartlarını taramaktan eski kitapları dijitalleştirmeye kadar, OCR çeşitli endüstrilerde kritik bir rol oynamaktadır. OCR teknolojisinin geniş bir uygulama yelpazesi vardır:
-
Belge Dijitalleştirme: OCR, eski kitaplar, gazeteler ve tarihi belgeler gibi basılı materyalleri dijital formatlara dönüştürmek için kullanılır, böylece aranabilir hale gelir ve gelecek nesiller için korunur.
-
Form İşleme: İşletmeler, formlardan otomatik olarak veri çıkarmak için OCR kullanarak manuel veri girişini azaltır ve finans ve sağlık gibi çeşitli sektörlerde verimliliği artırır.
-
Fatura İşleme: OCR teknolojisi, faturalar üzerindeki metni okuyabilir ve verileri otomatik olarak finansal sistemlere girebilir, muhasebe ve defter tutma süreçlerini kolaylaştırır.
-
Erişilebilirlik: OCR, metinleri sesli okuma işlevselliği sağlayarak, görme engelli bireyler için metinlerin sesli versiyonlarını oluşturur ve böylece basılı materyalleri daha erişilebilir hale getirir.
-
Mobil Uygulamalar: OCR, iş kartlarını tarama, fotoğraflardaki metni tanıma ve gerçek zamanlı çeviriyi kolaylaştırma gibi görevler için uygulamalara entegre edilmiştir.
-
Aranabilirlik: OCR, görüntülerden veya PDF'lerden metin çıkararak taranmış belgelerin aranabilirliğini artırır ve bilgilerin kolayca bulunmasını ve geri alınmasını sağlar.
-
Plaka Tanıma: Otopark ve trafik yönetimi için kullanılan OCR, plaka tanıma yeteneğine sahiptir ve verimli izleme ve uygulama sağlar.
-
İşletme Operasyonları: OCR, faturalar, makbuzlar ve satın alma siparişleri gibi belgelerden veri girişini otomatikleştirerek iş süreçlerini kolaylaştırır ve işe alım sürecini hızlandırarak iş başvurularını ve özgeçmişleri tarar ve işler.
-
Hukuk ve Sağlık Sektörleri: Hukuk firmaları, bilgi erişimini kolaylaştırmak için dava dosyalarını ve hukuki belgeleri dijitalleştirmek için OCR kullanırken, sağlık hizmeti sağlayıcıları, hasta kayıtlarını ve tıbbi formları elektronik sağlık kayıtlarına (EHR) dönüştürmek için bunu kullanır, veri yönetimini ve hasta bakımını geliştirir.
-
Eğitim: Eğitim ortamlarında, OCR, dijital ders kitapları ve öğrenme materyalleri oluşturmak için kullanılır, öğrencilerin çeşitli ihtiyaçlarını karşılayarak erişilebilirliği artırır ve kapsayıcı bir öğrenme ortamını destekler.
OCR teknolojisi geliştikçe, bilgiyi daha erişilebilir ve dijital çağda daha verimli bir şekilde yönetmek için kritik bir rol oynamaya devam etmektedir.
OCR'nin Dezavantajları: Sınırlamalar ve Olumsuzluklar
Doğruluk Zorlukları
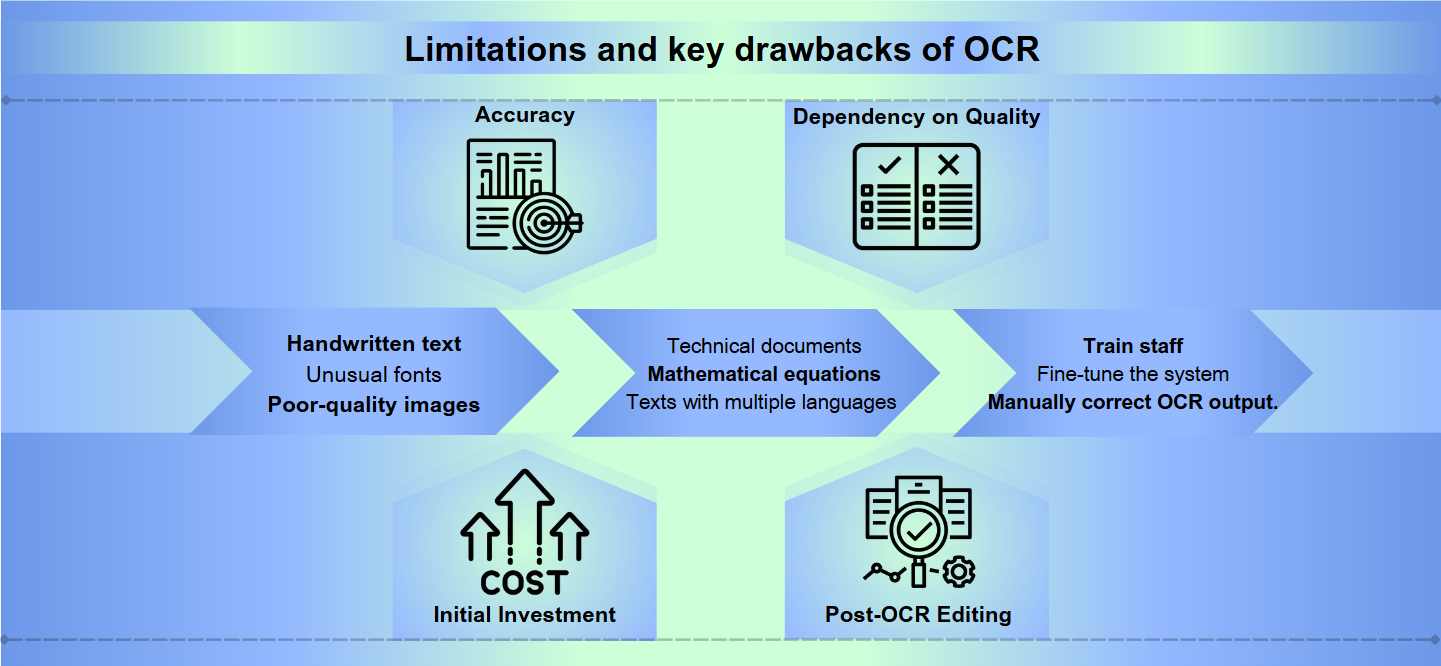
Optik Karakter Tanıma (OCR) teknolojisi uzun bir yol kat etmiş olsa da, mükemmel doğruluk elde etme konusunda hala önemli engellerle karşı karşıyadır. El yazısı metinler, alışılmadık fontlar veya düşük kaliteli görüntüler yanlış yorumlamalara ve hatalara yol açabilir. Karakter şekillerindeki veya boyutlarındaki hafif farklılıklar bile OCR sistemlerini yanıltabilir ve manuel düzeltme gerektiren bozuk çıktılarla sonuçlanabilir.
Dil ve Format Kısıtlamaları
Çoğu OCR çözümü standart diller ve formatlarla mükemmel bir şekilde çalışırken, özel içeriklerle başa çıkmada zorluk yaşayabilir. Teknik belgeler, matematiksel denklemler veya birden fazla dil içeren metinler önemli zorluklar oluşturabilir. Ayrıca, OCR, karmaşık düzenler, tablolar veya karmaşık biçimlendirmeye sahip belgelerle karşılaştığında zayıf kalabilir ve kritik yapısal bilgileri kaybedebilir.
Kaynak Yoğunluğu
Etkili bir OCR sisteminin uygulanması ve sürdürülmesi kaynak yoğun olabilir. Yüksek kaliteli OCR yazılımları genellikle yüksek bir fiyat etiketine sahiptir ve büyük hacimli belgeleri işlemek için gereken donanım maliyetli olabilir. Ayrıca, personeli eğitmek, sistemi ince ayar yapmak ve OCR çıktısını manuel olarak gözden geçirip düzeltmek için gereken zaman ve çaba, organizasyonel kaynakları zorlayabilir.
OCR'nin Ana Dezavantajları
-
Doğruluk: OCR yazılımı, özellikle düşük kaliteli görüntüler, karmaşık düzenler veya el yazısı metinlerle başa çıkarken doğrulukta zorluk yaşayabilir. Hatalar, karakterleri yanlış okumaktan metin bölümlerini atlamaya kadar değişebilir.
-
Kaliteye Bağımlılık: OCR'nin etkinliği, orijinal belgenin kalitesine büyük ölçüde bağlıdır. Solmuş mürekkep, lekeler veya buruşmuş kağıt, yanlış çevirilere yol açabilir.
-
Başlangıç Yatırımı: Bir OCR sistemi kurmak, yalnızca yazılımı değil, aynı zamanda tarayıcı gibi uyumlu donanımı da içeren önemli bir başlangıç maliyeti gerektirebilir.
-
Post-OCR Düzenleme: Genellikle, OCR süreçlerinden elde edilen çıktıların manuel gözden geçirme ve düzeltme gerektirmesi, zaman alıcı olabilir.
Görsel Dil Modeli, OCR'nin Sınırlamalarını Aşma
Teknoloji ilerledikçe, geleneksel Optik Karakter Tanıma (OCR) sistemlerinin eksikliklerini gidermek için yenilikçi çözümler ortaya çıkmaktadır. Bu tür bir atılım, metin çıkarımı ve anlama süreçlerini devrim niteliğinde değiştiren bilgisayarla görme ve doğal dil işleme teknolojilerini birleştiren Görsel Dil Modeli (VLM)dir.
Gelişmiş bağlamsal anlama
VLM'ler, metnin etrafındaki bağlamı anlamada OCR'nin izole karakter tanımasından daha başarılıdır. Metinle birlikte görsel unsurları analiz ederek, bu modeller karmaşık düzenleri, el yazısı notları ve hatta kısmen gizlenmiş metinleri olağanüstü bir doğrulukla yorumlayabilir.
Çok dilli ve çok modlu yetenekler
OCR, genellikle çeşitli diller ve yazılarla başa çıkmada zorluk yaşarken, VLM'ler etkileyici bir çok yönlülük sergiler. Birden fazla dili sorunsuz bir şekilde işleyebilir ve diyagramlar veya grafikler gibi görsel içeriği yorumlayarak belgelerin daha kapsamlı bir anlayışını sağlar.
Uyarlanabilir öğrenme ve sürekli iyileştirme
Statik OCR sistemlerinin aksine, VLM'ler zamanla uyum sağlamak ve gelişmek için makine öğrenimini kullanır. Yeni veriler ve senaryolarla karşılaştıkça, bu modeller performanslarını geliştirir ve çeşitli belge türleri ve formatlarıyla başa çıkmada giderek daha yetkin hale gelir.
OCR'nin sınırlamalarını aşarak, Görsel Dil Modelleri, endüstrilerde daha doğru, verimli ve akıllı belge işleme için yeni bir yol açmaktadır.
Görsel Dil Modelini Seçin: AnyParser'ı Deneyin
Görsel Dil Modellerinin (VLM) ilerlemelerinden yararlanan AnyParser, geleneksel OCR teknolojisinin sınırlamalarını aşan sofistike bir çözüm olarak ortaya çıkmaktadır. CambioML ekibi tarafından geliştirilen AnyParser, PDF'ler, görüntüler ve grafikler gibi çeşitli yapılandırılmamış veri kaynaklarından bilgi çıkarmak için hassas ve yapılandırılabilir bir API kullanan güçlü bir belge ayrıştırma aracıdır ve bunları yapılandırılmış formatlara dönüştürür.
Teknik Temel ve Yetenekler
AnyParser, belgelerden metin, tablo, grafik ve düzen çıkarımında yüksek doğruluk sağlamak için büyük dil modellerinin (LLM) sağlam temeli üzerine inşa edilmiştir. Özellikle karmaşık düzenlere sahip belgeler veya orijinal estetiğin korunması gereken belgeler için yararlı olan, orijinal düzeni ve formatı koruma yeteneği ile öne çıkar.
Gizlilik ve Güvenlik
Kullanıcı gizliliğini vurgulayan AnyParser, verileri yerel olarak işleyerek hassas bilgileri korur. Bu özellik, gizli verilerle çalışan işletmeler ve bireyler için önemli bir avantajdır.
Özelleştirilebilirlik ve Esneklik
Yüksek düzeyde yapılandırılabilirlik sunan AnyParser, kullanıcıların özel çıkarım kuralları belirlemelerine ve belirli ihtiyaçlarına uygun çıktı formatlarını tanımlamalarına olanak tanır. Bu uyarlanabilirlik, onu AI mühendisliğinden finansal analize kadar geniş bir uygulama yelpazesi için ideal bir araç haline getirir.
Sonuç
Gördüğünüz gibi, OCR teknolojisi metin dijitalleştirme konusunda güçlü yetenekler sunar, ancak sınırlamaları da vardır. Optik karakter tanıma verimliliği önemli ölçüde artırabilir, ancak potansiyel dezavantajları dikkatlice değerlendirmeniz gerekir. Doğruluk sorunlarını, biçimlendirme zorluklarını ve kaynak gereksinimlerini dikkate alarak bir OCR çözümü uygulamayı düşünmelisiniz. Nihayetinde, OCR kullanma kararı, özel ihtiyaçlarınıza ve koşullarınıza bağlıdır. Hem faydaları hem de dezavantajları anlayarak, OCR'nin organizasyonunuz için doğru olup olmadığına dair bilinçli bir seçim yapabilirsiniz. OCR gelişmeye devam ederken, mevcut eksiklikleri giderebilecek ve bu dönüştürücü teknolojinin daha büyük potansiyelini açığa çıkaracak yeni gelişmeleri takip edin.
Eylem Çağrısı
Görsel Dil Modellerinin gücünü benimseyin ve PDF'lerinizi Google Sayfalarına dönüştürmek için AnyParser'ı ücretsiz deneyin: https://www.cambioml.com/sandbox. VLM'lerin veri çıkarım iş akışınızı nasıl geliştirebileceği konusunda ücretsiz bir danışmanlık alın.