在数据管理领域,解析涉及将内容(如文本、图像、表格和元数据)转换为可用格式(例如,纯文本、结构化数据或图像),以便进一步处理或分析。在PDF解析的领域中,这一点尤为明显,解析是一个关键过程,将原始信息转化为结构化的可用数据。本综合指南深入探讨PDF解析的复杂性,阐明其定义、可以提取的数据范围、面临的挑战、多种应用以及利用其全部潜力的各种方法。您将探索各种解析方法,特别关注PDF解析,以及像AnyParser这样的工具如何脱颖而出。
理解PDF解析器:什么是解析?
什么是解析:细致的数据捕获过程
从本质上讲,PDF解析是指从PDF(可移植文档格式)文件中提取和解释数据的过程。由于PDF主要是为显示而设计,而非结构化数据存储,因此解析涉及将内容(如文本、图像、表格和元数据)转换为可用格式(例如,纯文本、结构化数据或图像),以便进一步处理或分析。解析需要进行高级分析,以定位和检索PDF中的特定元素,超越单纯的文本和图像,涵盖字体、布局、表格和元数据。这一过程不仅仅是技术细节,而是在金融、法律、物流和医疗等各个行业中,信息再利用至关重要的必要条件。
可以从PDF中解析的数据
从PDF中可提取的数据种类繁多,包括:
-
文本段落:单词和字符的序列。
-
单个数据字段:如日期、跟踪号码和姓名等单独元素。
-
表格数据:组织成表格和列表的信息。
-
图像:嵌入在PDF中的图形内容。
-
高级元素:需要更复杂解析工具的标题、对象、交叉引用表、尾部和元数据。
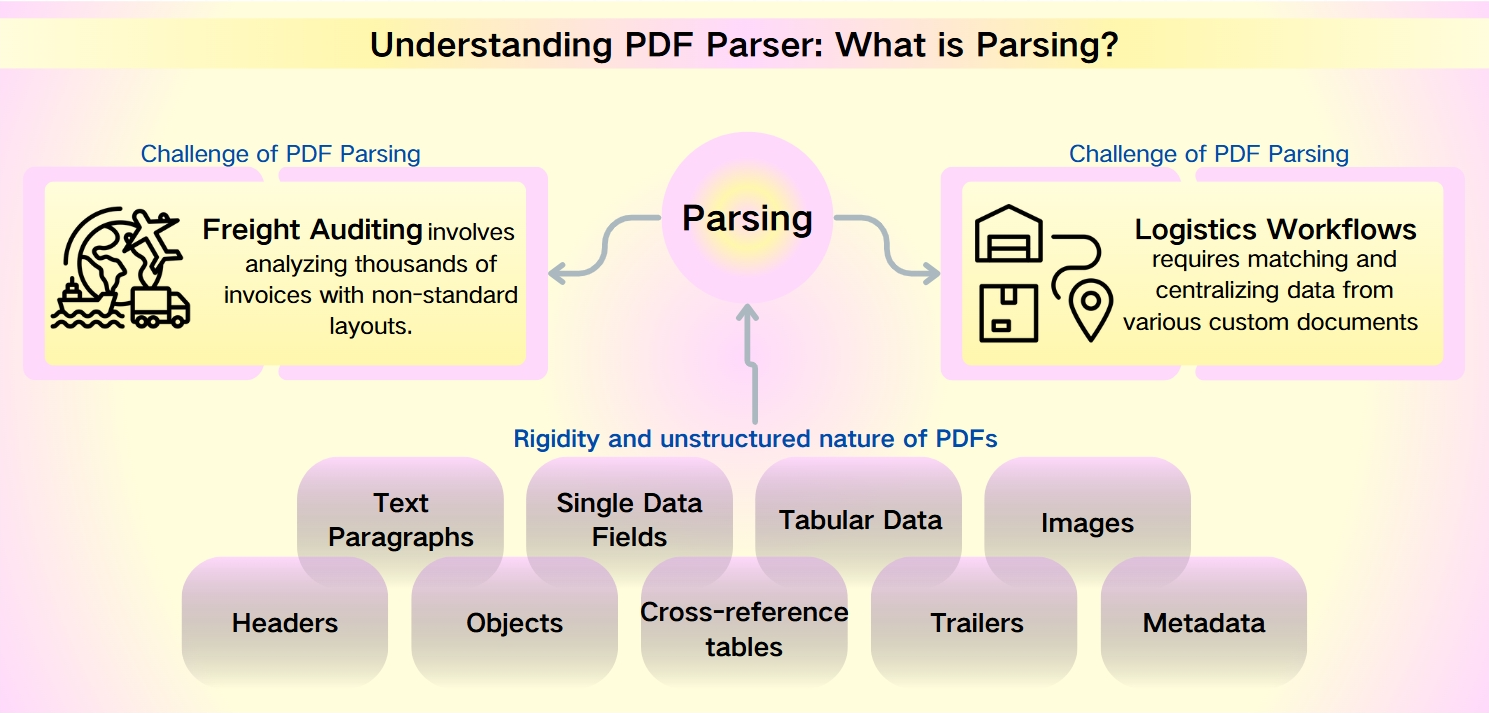
PDF解析的挑战:PDF元数据的非结构化特性
尽管PDF具有安全性、设备兼容性和紧凑文件大小等优点,但从中提取数据却面临着巨大的挑战。PDF的刚性和非结构化特性妨碍了快速分析和信息检索。这在货运审计和物流工作流程等场景中尤为明显,非标准布局和庞大的数据集加剧了复杂性。
货运审计涉及分析成千上万的具有非标准布局的发票。物流工作流程需要匹配和集中来自各种自定义文档(如装箱单、商业发票和提单)的数据。
解析的重要性
解析在从网页开发到数据捕获的各个领域中扮演着至关重要的角色。它使企业能够从非结构化数据源(如PDF文档、HTML文件和XML数据)中提取有价值的见解。解析促进了:
-
通过数据驱动的见解改善决策。
-
提高数据的准确性和一致性。
-
精简数据处理和分析。
-
高效的信息检索和存储。
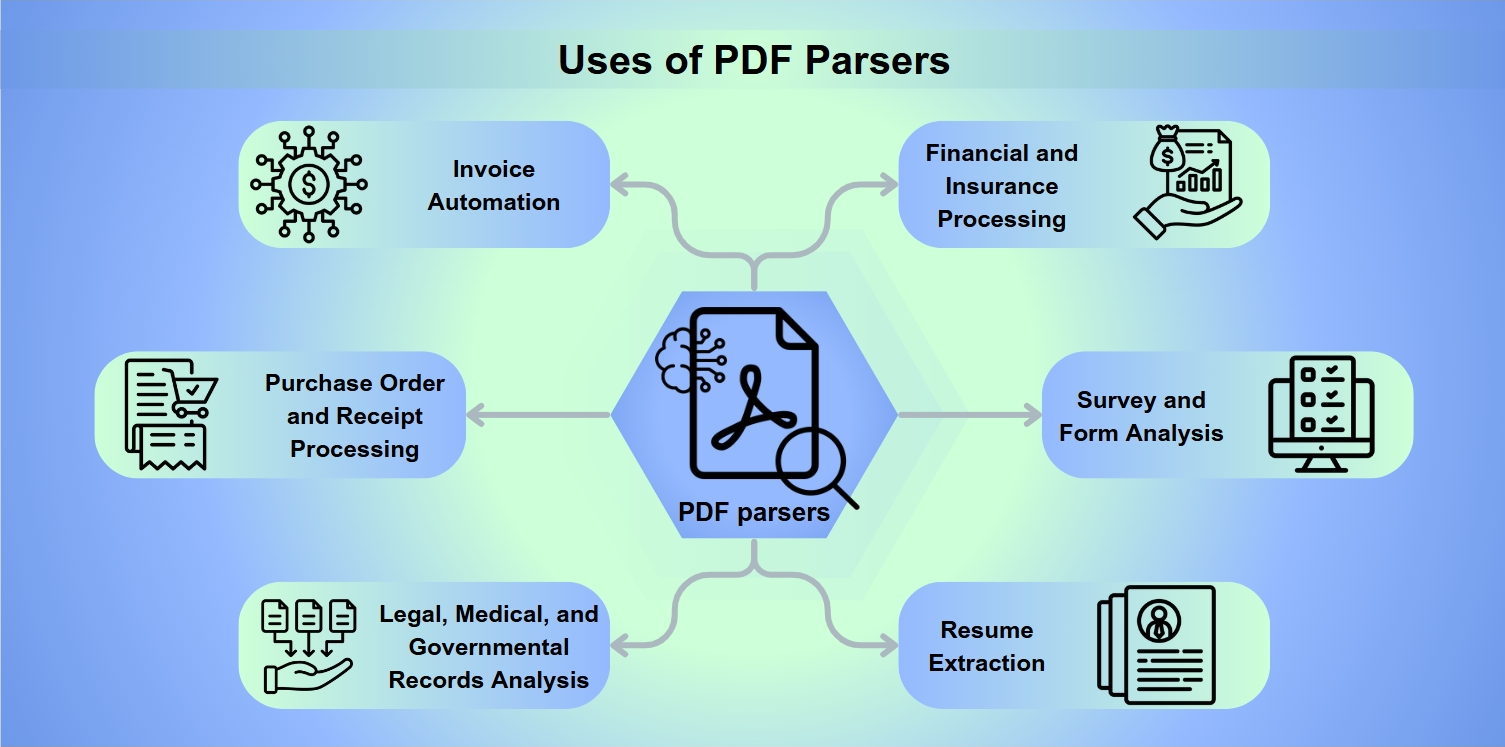
PDF解析器的用途
PDF解析器是各种应用中不可或缺的工具,包括:
-
发票自动化:简化发票的处理和支付。
-
采购订单和收据处理:促进退款和报销。
-
法律、医疗和政府记录分析:实现深入的数据提取以进行分析。
-
金融和保险处理:评估风险和分析资产负债表。
-
调查和表单分析:收集和解释表单响应。
-
简历提取:帮助招聘人员进行候选人筛选。
不同解析方法的比较
数据解析方法随着时间的推移发生了显著变化。传统的数据捕获方法通常依赖于正则表达式(regex)从文本中提取特定模式。尽管功能强大,但对于复杂的解析任务,正则表达式可能变得复杂且难以维护。另一种常见技术是字符串操作,它涉及根据分隔符或特定字符拆分和处理文本。这些方法虽然在某些场景中仍然有用,但在处理非结构化或不一致的数据格式时可能会遇到困难。
PDF解析的领域由多种方法服务,每种方法都有其独特的优缺点:
-
在线PDF转换器/解析器:如Zamzar和Smallpdf,提供便利和速度,但功能有限且可能不安全。
-
Adobe Acrobat:保留结构和格式,但可能需要在转换后进行手动调整。
-
复制和粘贴:提供完全控制,但繁琐且容易出错。
-
自动化平台:现代解析技术如AnyParser利用机器学习和自然语言处理(NLP)来处理更复杂的数据结构。
这些基于AI的方法能够理解上下文和语义,使其在解析非结构化文本或具有不同格式的文档时特别有效。一些先进的解析器利用深度学习模型,以高准确率识别和提取相关信息,即使是从以前未见过的文档布局中。
如何进行PDF解析:提取PDF元数据的最佳免费PDF解析器
理解PDF元数据
PDF元数据包含有关文档的重要信息,包括其标题、作者、创建日期和关键词。高效提取这些元数据对于组织、搜索和管理大量PDF文件至关重要。一个强大的PDF解析器可以简化这一过程,节省时间并提高工作效率。
顶级PDF解析器的关键特性
最佳免费PDF解析器提供准确性、速度和多功能性的结合。它们应能够处理各种PDF格式,包括扫描文档和具有复杂布局的文档。寻找能够提取基本元数据以及自定义字段和隐藏信息的解析器。此外,顶级解析器通常提供PDF数据提取器的批处理和与其他软件系统的集成选项。
AnyParser的特点
由CambioML开发的AnyParser因其准确性、隐私性和可配置性而特别引人注目。AnyParser能够处理多种文件格式,用户友好的界面和可扩展性使其成为各类企业的优秀选择。此外,其API允许无缝集成到现有工作流程中,提高整体文档管理效率。以下是使AnyParser成为PDF解析的优秀选择的一些关键特性:
-
精确性:AnyParser旨在准确提取文本、数字和符号,同时保持原始布局和格式。它利用先进的语言模型增强文档理解和信息提取,准确率比传统OCR模型高出2倍。
-
隐私:支持本地和云数据解析,确保敏感信息保持私密和安全。
-
可配置性:用户可以自定义提取规则和输出格式,以满足特定需求。
-
多源支持:AnyParser支持多种文档类型,包括PDF、图像和图表。
-
结构化输出:提取的信息可以转换为结构化格式,如Markdown、Excel或JSON,便于进一步处理和分析。
-
基于云的部署选项:AnyParser SDK可以在云中、数据中心或私有环境中部署,提供灵活性和可扩展性。
-
用户友好的界面:该工具提供简单的API,使复杂的文档解析任务只需几行代码即可完成。
-
高性能:优化算法确保快速处理大量文档,比通用的LLM(如GPT4o)快5倍。
-
社区支持:作为一个开源项目,AnyParser受益于活跃的社区并欢迎贡献。
-
免费使用配额:AnyParser为每个帐户提供免费使用配额,允许用户在承诺付费计划之前测试工具的能力。
-
客户反馈:用户称赞AnyParser的高准确性、隐私保护和数据提取效率,案例研究显示显著的时间节省和数据质量改善。
这些优势使AnyParser成为文档解析和信息提取的有价值的PDF数据提取器,尤其适合需要高精度和安全性的企业用户。随着技术的不断进步和社区的积极参与,AnyParser在文档解析和信息提取领域的作用将愈加重要。
PDF解析器的技术解释
PDF解析与网页抓取在概念上有相似之处,但它缺乏HTML的结构层次。虽然网页文档通过可访问的HTML标签进行解析,但PDF呈现的是字符和像素的平面数组,要求更复杂的算法和库来进行数据提取。
PDF解析器与Python PDF解析器:关键区别
PDF解析器通常是专门为从PDF文件中提取数据而设计的独立工具或库。这些解析器通常提供用户友好的界面,并且需要最少的编码知识。另一方面,Python PDF解析器是集成到Python脚本中的模块或库,提供更多灵活性,但需要编程专业知识。
开发人员可以微调解析过程,实施高级文本分析,并将PDF数据提取无缝集成到更广泛的Python应用程序中。PDF解析器虽然在定制化方面不如Python PDF解析器灵活,但通常为常见用例提供预构建的功能,使其非常适合需要快速结果而不需要广泛编程的用户。
AnyParser与VLM在数据解析中的优势
-
高精度:AnyParser的VLM确保数据提取保持高保真度,即使在复杂的文档布局中。
-
速度:在转换速度方面领先,提高生产力,减少处理文档所需的时间。
-
用户友好:AnyParser提供直观的界面,使所有级别的用户都能轻松使用。
-
多功能性:除了PDF,AnyParser还作为强大的图像转Excel转换器,支持多种文档类型。
结论
PDF解析不仅仅是一个技术过程;它是改变企业处理数据方式的门户。尽管面临挑战,软件解决方案的演变使其比以往任何时候都更易于访问。无论您是在处理发票处理还是复杂的数据分析,选择合适的PDF解析器至关重要。这是关于找到提供准确性、安全性和效率完美平衡的工具,以支持您的数据驱动计划。
立即开始您的免费试用
准备好彻底改变您的文档处理方式了吗?立即免费试用AnyParser,无需信用卡,访问https://www.cambioml.com/sandbox。免费试用允许您处理每个文档最多10页,最大文件大小为10MB。亲身体验AnyParser的PDF解析器如何改变您对非结构化数据和文档提取的处理方式。不要错过这个机会,利用最先进的AI技术提升您的数据分析能力并简化工作流程。