在当今数据驱动的世界中,将复杂文档从PDF格式转换为CSV格式是许多专业人士的重要任务。如果您正在处理PDF格式的银行对账单、医疗报告或发货单,您可能正在寻找高效的解决方案。
视觉语言模型(VLM)应运而生,这是一种超越传统OCR方法的前沿技术。通过利用视觉和上下文理解,VLM提供了一种强大的工具,可以将复杂的结构化文档转换为机器可读的格式。
本指南将引导您通过使用AnyParser利用VLM将PDF转换为CSV或Excel文件,从而简化工作流程并解锁有价值的数据洞察。使用AnyParser,您可以轻松将PDF转换为CSV、PDF转换为Excel,甚至只需在我们的Playground上点击几下即可将Word转换为CSV。
PDF到CSV转换的强烈需求与传统OCR模型的局限性
PDF到CSV转换的日益需求
在当今数据驱动的世界中,将PDF转换为CSV的需求变得越来越重要。企业和个人都在寻求高效的方法,将静态PDF文档转变为动态、可分析的电子表格。这个转换过程对于从各种文档中提取有价值的信息至关重要,例如银行对账单、医疗报告和发货单。能够将Word转换为Excel或使用PDF到CSV转换器可以显著简化数据管理和分析流程。
传统OCR技术的不足之处
尽管传统的光学字符识别(OCR)模型长期以来一直用于文本提取,但在处理复杂文档时,它们往往显得力不从心。这些局限性在尝试将复杂的PDF转换为Google Sheets或其他电子表格格式时尤为明显。OCR系统在以下方面面临挑战:
- 准确解释低质量扫描或图像
- 处理多列布局和表格
- 识别多种字体和语言
- 保持原始文档结构
这些挑战突显了需要更先进的解决方案,以无缝处理PDF到CSV的转换过程,同时保留原始文档的内容和上下文。
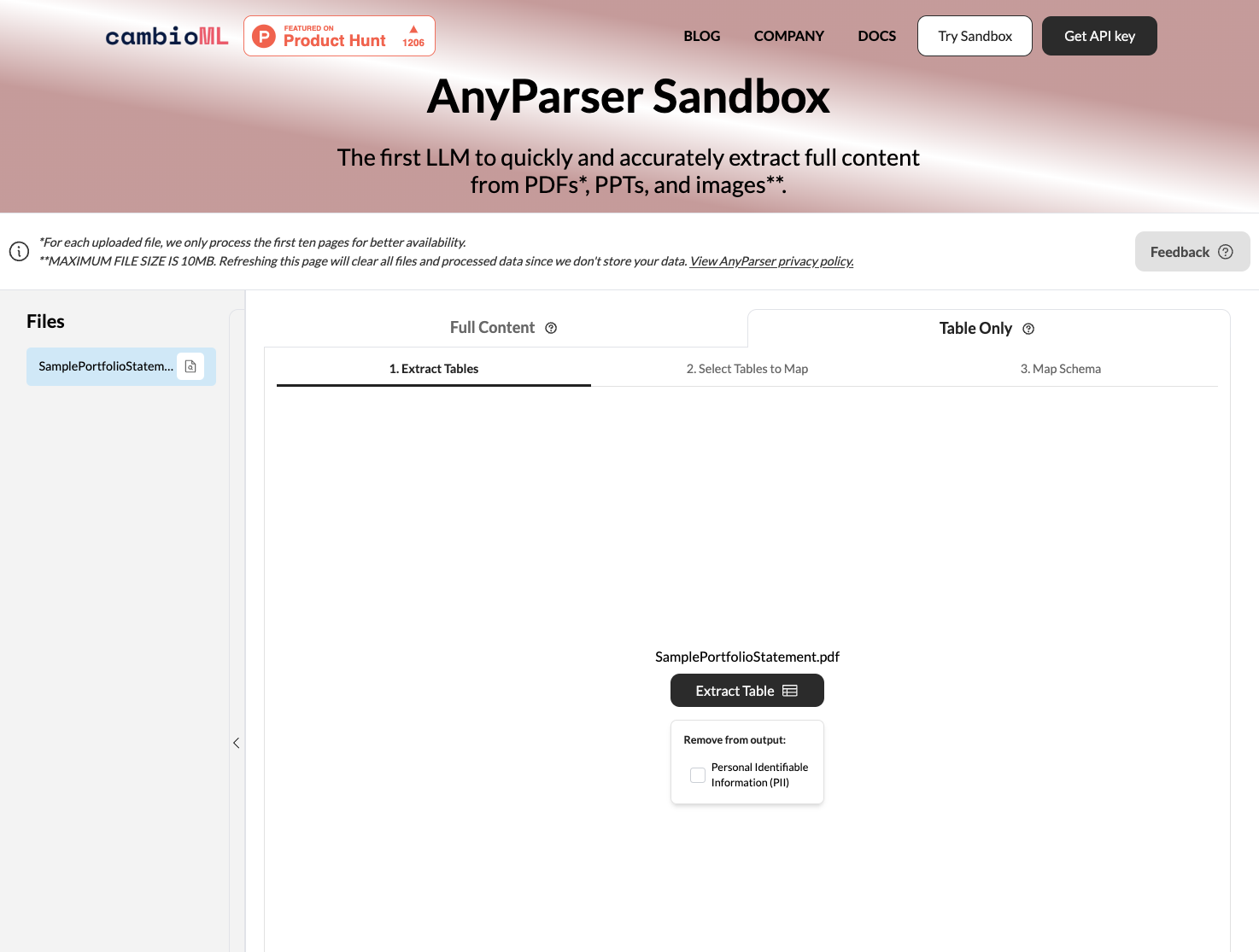
使用AnyParser转换PDF文档的逐步指南
AnyParser是一款强大的PDF到CSV转换工具,利用先进的视觉语言模型准确提取复杂PDF文档中的数据。以下是使用AnyParser转换PDF文件的基本步骤:
-
上传您的PDF或Word。只需将PDF文档拖放到AnyParser的网页界面中,或将PDF截图粘贴到AnyParser UI中。
-
选择“仅表格”,然后点击“提取”。AnyParser API引擎将自动检测PDF中的表格并高精度提取。提取的数据存储在.csv文件中,您可以下载或一键导出到Google Sheets。
-
预览和比较。查看预览中的提取数据,以确保其符合您的期望。预览AnyParser的初始提取,并在UI上进行并排比较。
-
导出为CSV或Excel。一旦您对提取结果满意,下载.csv文件以在自己的应用程序和系统中使用。提取的数据可以轻松导入电子表格和数据库以进行进一步分析。
通过遵循这些简单步骤并利用视觉语言模型的强大功能,AnyParser使您能够高效地将即使是最复杂的PDF文档转换为结构化、可编辑的CSV文件,以便您进行分析并集成到工作流程中。
查看此视频以获取逐步视频演示!
VLM在PDF到CSV/Excel转换中的实际应用
视觉语言模型(VLM)正在革新我们将PDF转换为CSV和Excel格式的方式,为各个行业提供强大的解决方案。通过利用这些先进的模型,您可以高效地将复杂文档转换为结构化的机器可读数据。
财务文档处理
在银行业,VLM在将PDF转换为CSV的银行对账单方面表现出色。这些模型可以准确提取交易详情、账户号码和余额信息,即使是具有复杂布局或多种货币的文档。这种能力简化了财务分析和对账流程。
医疗记录管理
对于医疗专业人员来说,VLM提供了一种宝贵的工具,可以将Word转换为Excel以处理医疗报告。通过准确解释复杂的医学术语并保留实验结果的结构,VLM促进了全面患者数据库的创建。这种转变使得趋势分析更为容易,并改善了患者护理。
物流和供应链优化
在物流行业,VLM在将发货单从PDF转换为Google Sheets时表现出色。这些模型可以提取关键信息,如送货地址、物品描述和追踪号码,同时保持表格数据的完整性。这种转换使得高效的库存管理和路线优化成为可能。
通过利用由VLM驱动的PDF到CSV转换器,您可以显著提高各个行业的数据处理效率。这些先进模型在处理多语言文档、复杂布局甚至低质量扫描方面提供了无与伦比的准确性,使其成为现代企业不可或缺的工具。
视觉语言模型如何克服OCR挑战
视觉语言模型(VLM)正在革新我们将PDF转换为CSV并将复杂文档转变为机器可读格式的方式。与传统OCR不同,VLM利用视觉和语言理解来应对文档转换中最具挑战性的方面。
解释复杂布局
VLM在解读复杂文档结构方面表现出色,使其成为将Word转换为Excel或处理格式各异的银行对账单的理想选择。通过分析文本元素之间的空间关系,VLM可以准确重建表格并保持布局完整性。例如,VLM可以正确解释包含多个不同列数和行数表格的发票PDF,而传统OCR则会混淆行和列。
上下文理解
VLM的一个关键优势是其理解文档内容语义的能力。这种上下文意识使得在使用PDF到CSV转换器时的提取更加准确,尤其是对于医疗CBC报告或物流发货单等特定领域的文档。例如,VLM可以根据内容正确分类医疗报告,甚至理解“白细胞”计数是“白细胞(WBC)”计数!
多语言能力
VLM通过无缝处理单个文档中的多种脚本和语言,打破了语言障碍。这使得它们对于处理多样化文档类型的国际企业特别有用。例如,VLM可以从包含英语和法语文本的PDF中提取数据。
噪声减少
低质量扫描或图像通常给传统OCR系统带来挑战。然而,VLM可以有效过滤噪声,专注于相关信息,确保在将文档转换为Google Sheets或其他格式时输出高质量结果。例如,VLM可以准确提取模糊或褪色的PDF文档中的数据。
关于使用视觉语言模型将PDF转换为CSV的常见问题
VLM基础的转换与传统OCR有何不同?
视觉语言模型(VLM)在将PDF转换为CSV或Excel时提供了显著的优势。与OCR不同,VLM能够准确解释复杂布局、理解上下文,并无缝处理多种语言。这使得它们非常适合将银行对账单、医疗CBC报告和物流发货单转换为机器可读格式。
哪些类型的文档最适合VLM转换?
VLM在转换具有表格、图表和混合内容的结构化文档方面表现出色。它们特别适用于财务报表、医疗报告和发货清单。由VLM驱动的PDF到CSV转换器可以保持表格完整性,并从即使是低质量扫描或复杂多语言文档中提取数据。
VLM基础的转换与手动数据输入相比准确性如何?
与手动数据输入或传统OCR相比,基于VLM的解决方案如AnyParser可以显著提高准确性。通过利用视觉和上下文理解,这些工具可以将将Word转换为Excel或PDF转换为Google Sheets的错误率降低多达50%。这种准确性对于维护财务、医疗和物流应用中的数据完整性至关重要。
VLM能处理PDF以外的不同文件格式吗?
是的,先进的基于VLM的工具可以处理多种文件格式。虽然PDF到CSV转换很常见,但这些模型也可以从图像、Word文档、PowerPoint演示文稿和扫描文档中提取数据。这种多功能性使得VLM成为各行业全面文档处理需求的强大解决方案。
结论
在您开始利用视觉语言模型进行PDF到CSV转换时,请记住,成功在于结构良好的方法。通过实施强大的预处理、准确的文档分类和彻底的后处理,您可以充分发挥VLM在数据提取需求中的潜力。无论您处理的是复杂的银行对账单、错综复杂的医疗报告,还是详细的发货单,VLM都提供了一种强大的解决方案,将非结构化数据转变为可操作的洞察。拥抱这一前沿技术,以简化您的工作流程、提高数据准确性,并解锁文档处理的新可能性。借助VLM,您将能够高效、有效地应对即使是最具挑战性的PDF转换任务。
行动呼吁
让我们通过实施这些见解向前迈进。考虑联系视觉语言模型方面的专家,例如AnyParser团队,以:
- 免费试用AnyParser,将您的PDF转换为CSV,访问 https://www.cambioml.com/sandbox
- 如果您更喜欢无代码体验来将大量PDF转换为Excel,请访问 https://www.energent.ai
- 获取有关VLM如何改善您的数据提取工作流程的免费咨询
充分利用视觉语言模型的全部潜力需要借助转换专家的经验和最佳实践。通过与行业领袖联系,迈出下一步,加速您向更自动化、更准确和更具洞察力的数据提取过程的过渡。