在当今数据驱动的世界中,您经常会遇到将PDF文件转换为可编辑格式(如Google Sheets)的需求。无论您是在处理财务报表、医疗记录还是物流文件,寻找高效的转换解决方案都是至关重要的。
传统方法往往无法满足需求,让您感到沮丧并浪费宝贵的时间。进入视觉语言模型(VLM)的领域,彻底改变了您处理文档转换的方式。
本指南将引导您利用AnyParser这一尖端工具,利用VLM的强大功能,将您的PDF无缝转换为Google Sheets。您将发现这项技术的实际应用,探索其相较于传统OCR方法的优势,并找到常见问题的答案。准备好在数据管理流程中解锁新的效率水平。
转换PDF为Google Sheets的日益增长的需求
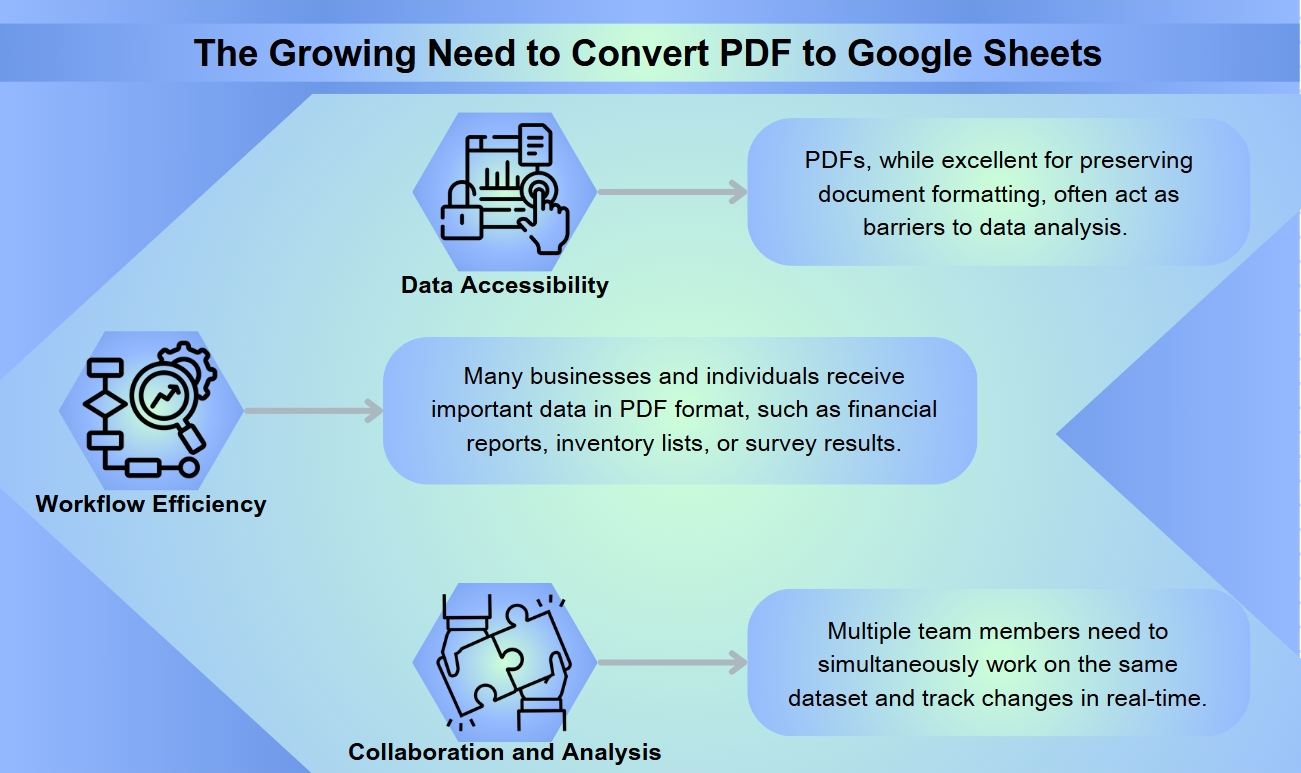
随着企业和个人寻求充分发挥数据的潜力,将PDF转换为Google Sheets的需求正在上升。这种转换允许动态数据分析和管理,简化各行业的流程。
克服数据可访问性挑战
在当今数据驱动的世界中,轻松访问和操作信息的能力至关重要。虽然PDF在保留文档格式方面表现出色,但往往成为数据分析的障碍。将PDF转换为Google Sheets可以解锁丰富的可能性,使用户能够对先前静态的信息进行排序、筛选和计算。
精简工作流程效率
许多企业和个人以PDF格式接收重要数据,例如财务报告、库存清单或调查结果。手动将这些数据重新输入到电子表格中既耗时又容易出错。通过将PDF转换为Google Sheets,用户可以自动化此过程,节省无数小时并确保数据准确性。
增强协作与分析
Google Sheets提供强大的协作功能,而PDF则无法匹敌。一旦转换,多个团队成员可以同时在同一数据集上工作,添加评论并实时跟踪更改。这种从静态文档到动态电子表格的转变使组织能够更深入地洞察数据,并更高效地做出数据驱动的决策。
转换PDF为表格的传统方法
手动数据输入
将PDF文件转换为Google Sheets传统上是一个劳动密集型的过程。许多用户不得不手动重新输入数据,这种方法既耗时又容易出错。当处理大量数据或复杂的PDF布局时,这种方法尤其具有挑战性。
复制和粘贴技术
另一种常见的方法是从PDF中复制内容并粘贴到Google Sheets中。虽然这比手动输入快,但通常会导致格式问题。表格可能会失去结构,文本可能无法正确对齐,需要进行大量清理。
OCR软件
光学字符识别(OCR)软件一直是许多人的首选解决方案。这些工具试图识别PDF中的文本并将其转换为可编辑格式。然而,OCR技术在处理手写文本、复杂布局或低质量扫描时可能会遇到困难。基于OCR的转换的准确性差异很大,通常需要手动审查和修正。常见问题包括:
- 无法准确解释低质量扫描或图像
- 难以处理多列布局和表格
- 识别不同字体和语言的挑战
- 保持原始文档结构的一致性
第三方转换器
各种第三方工具和在线转换器提供PDF到Google Sheets的转换。虽然有些提供不错的结果,但许多在处理复杂PDF或大文件时存在局限性。用户在将敏感文档上传到这些平台时也可能面临隐私问题。
使用AnyParser将PDF转换为Google Sheets的逐步指南
AnyParser利用先进的VLM提供了一种精确高效的PDF到Google Sheets转换解决方案。以下是使用AnyParser的步骤:
-
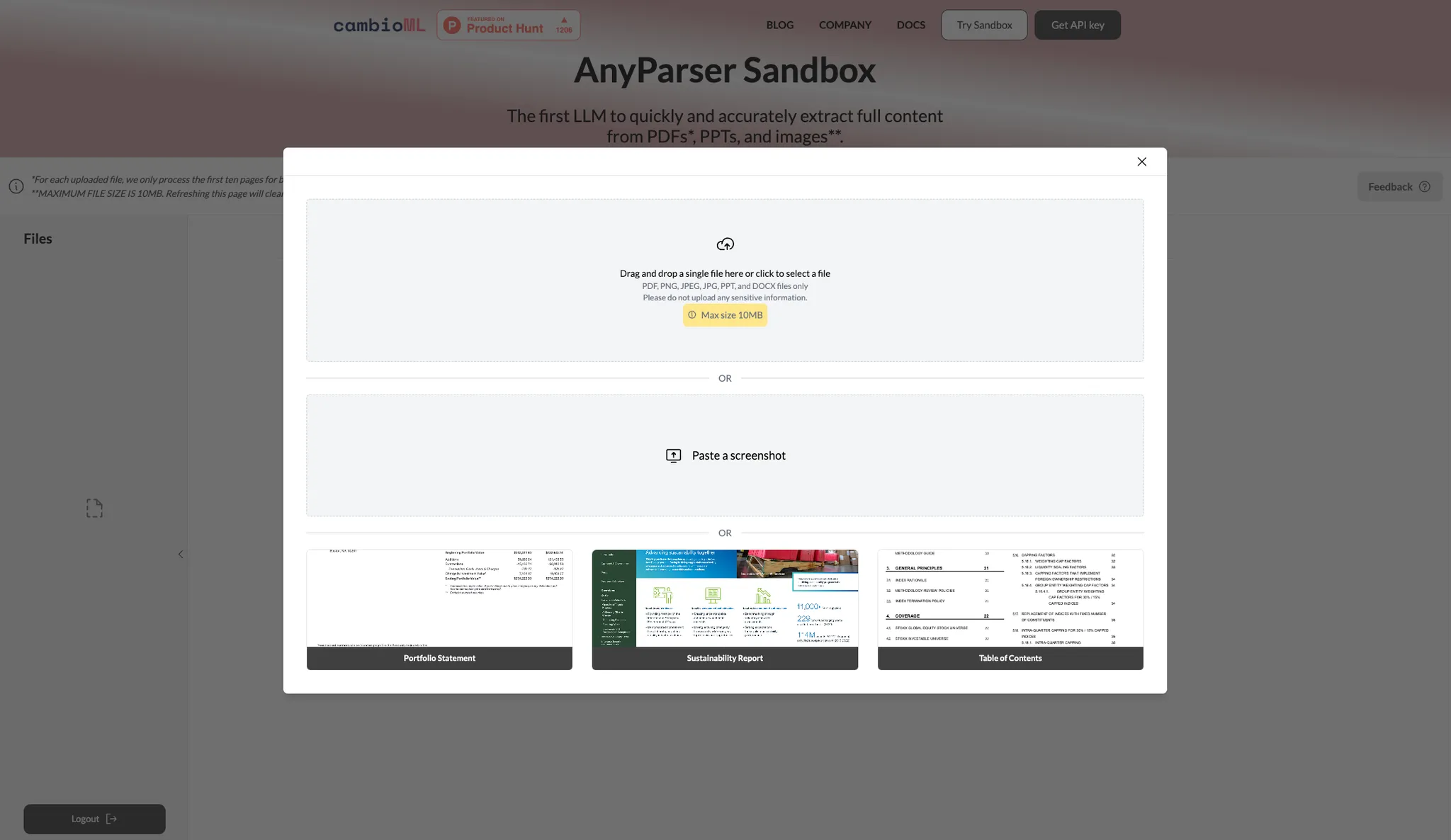
上传您的PDF或Word文档 只需将PDF拖放到AnyParser的网页界面中,或粘贴PDF截图。
-
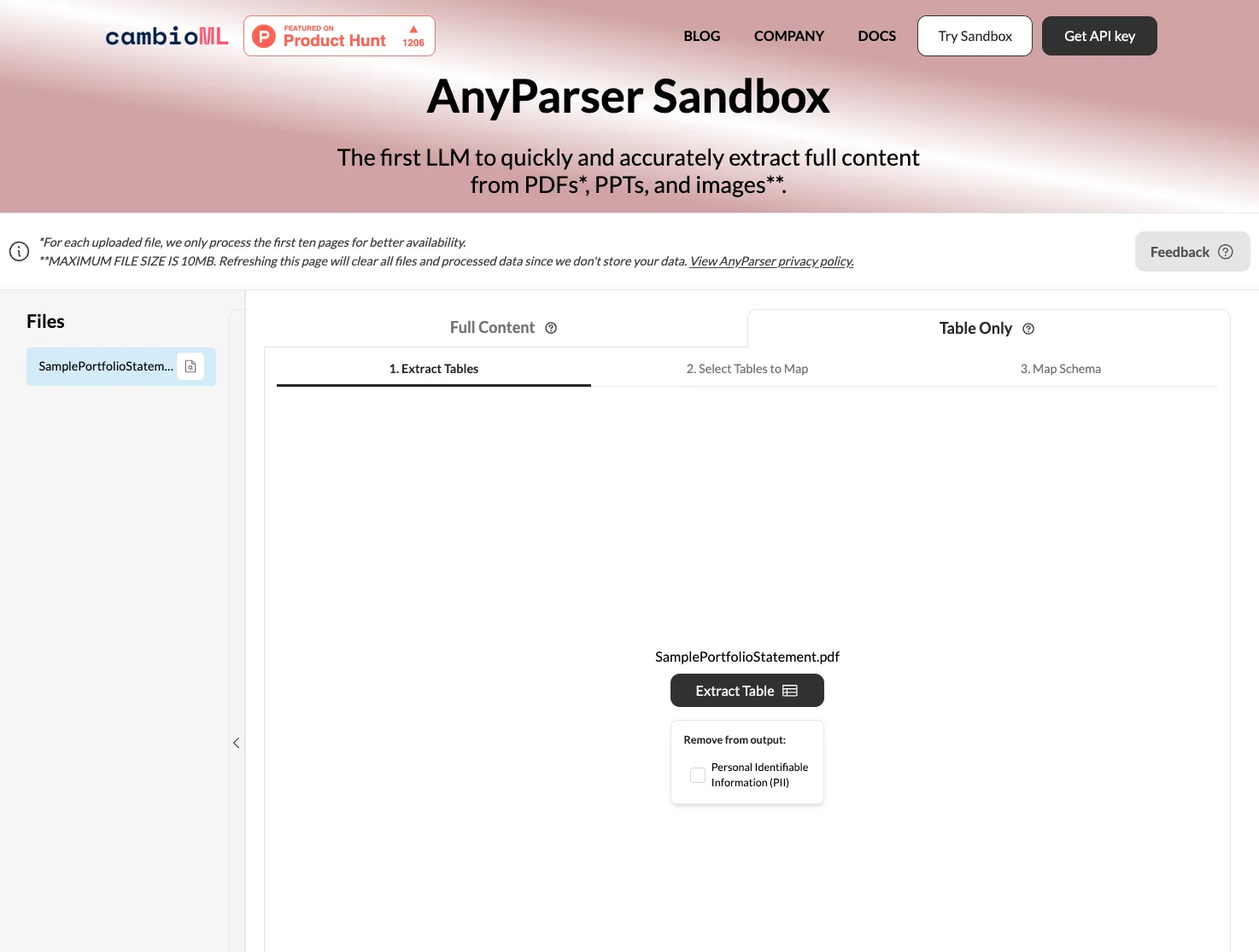
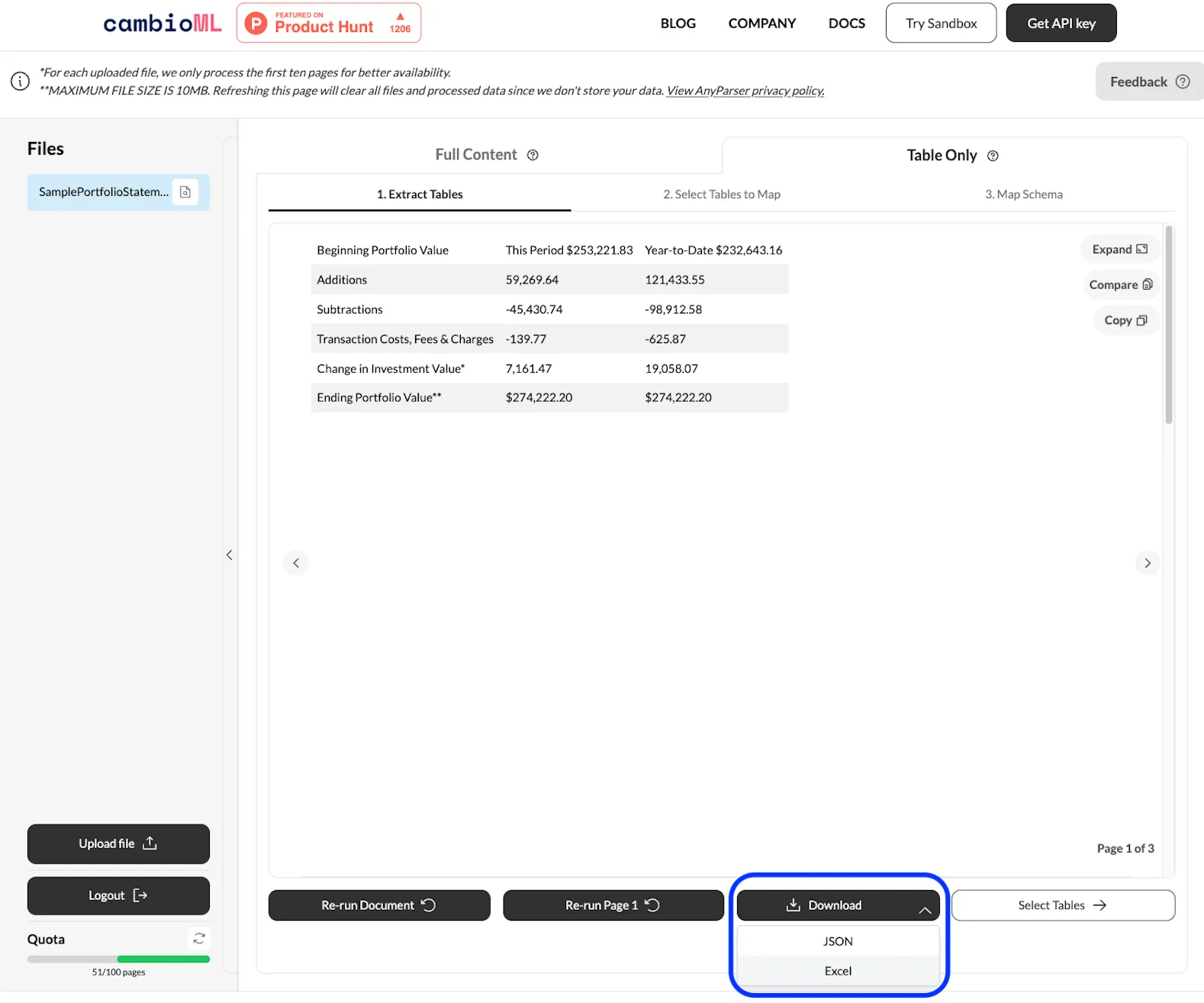
选择“仅表格”并点击“提取” AnyParser的API引擎将自动检测PDF中的表格并高精度提取。数据随后准备好直接导出到Google Sheets。
-
预览和比较 审查提取的数据以确保符合您的期望。AnyParser允许您预览初始提取并进行并排比较。
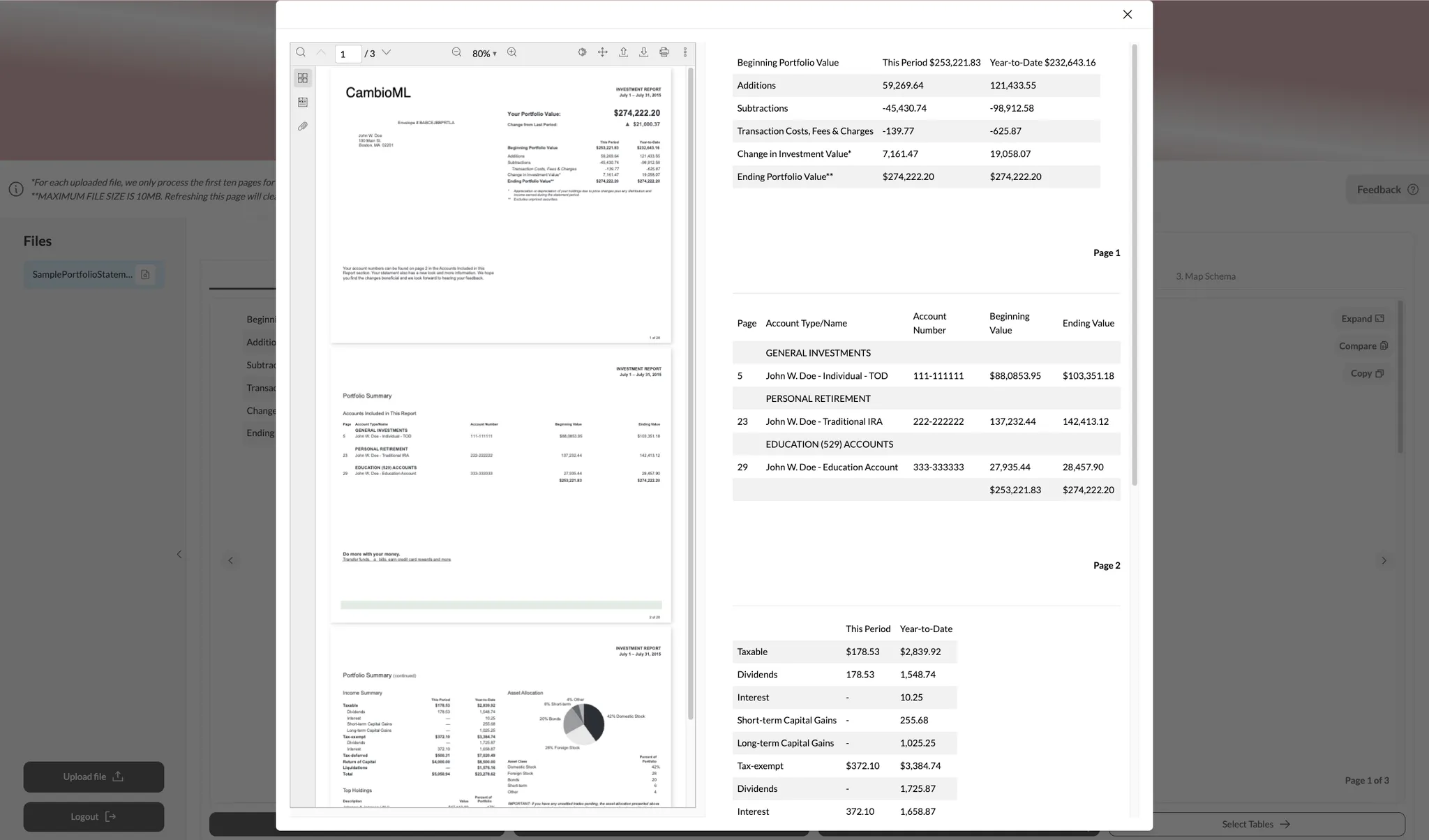
-
导出到Google Sheets 一旦满意,直接将数据导出到Google Sheets以进行进一步分析并集成到您的工作流程中。
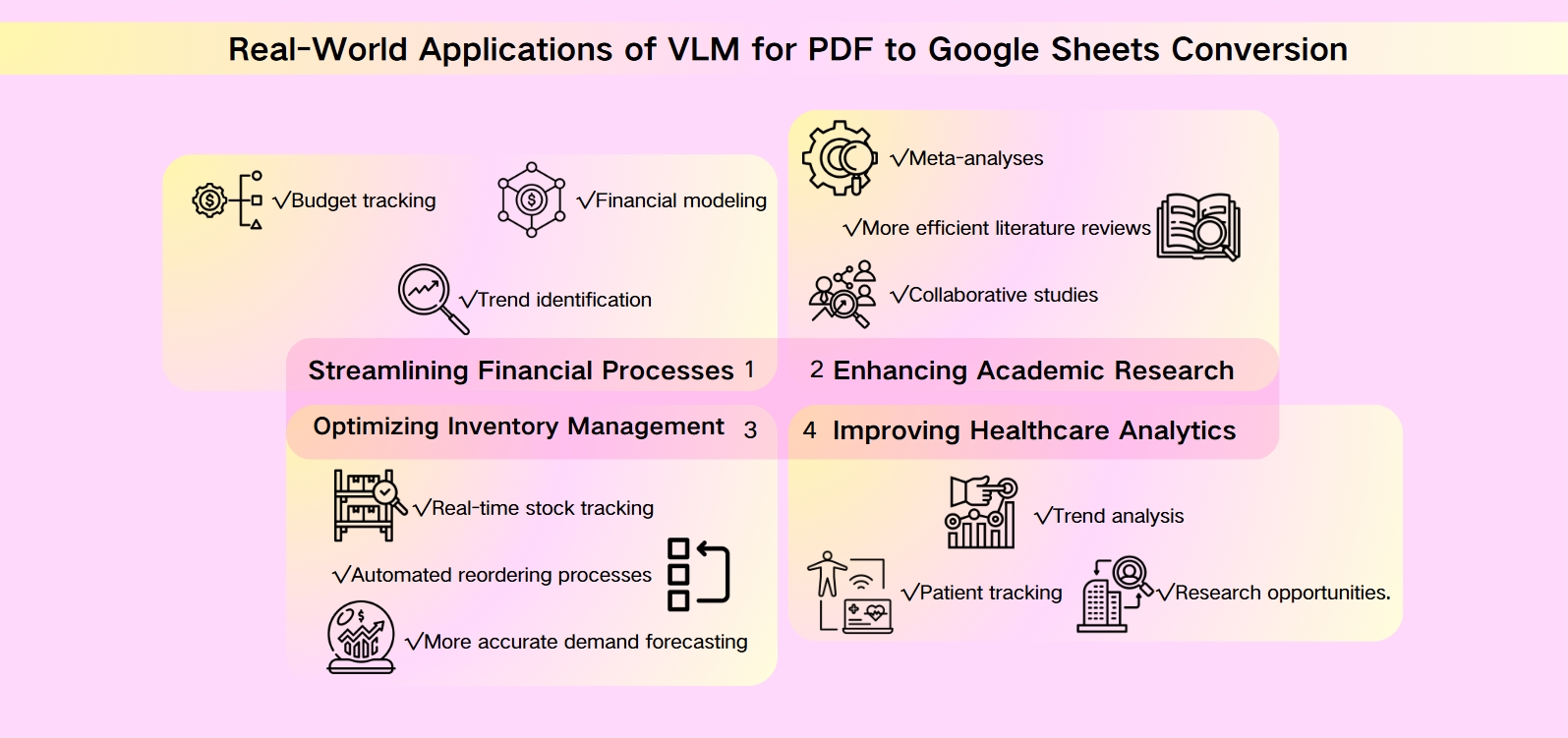
VLM在PDF到Google Sheets转换中的实际应用
精简财务流程
视觉语言模型(VLM)正在彻底改变企业处理财务数据的方式。通过将复杂的PDF财务报表转换为Google Sheets,公司可以实现数据输入和分析的自动化。这种转变允许实时财务建模、预算跟踪和趋势识别,赋予决策者最新的洞察力。
增强学术研究
研究人员和学生从VLM驱动的PDF到Google Sheets转换中受益匪浅。来自学术论文的大型数据集,通常被困在PDF格式中,可以轻松转换为可操作的电子表格。这种能力促进了元分析、协作研究和更高效的文献回顾,加速了科学发现的步伐。
优化库存管理
零售商和制造商正在利用VLM将PDF库存报告转换为动态Google Sheets。这一转变使实时库存跟踪、自动重新订购流程和更准确的需求预测成为可能。通过将这些数据与其他业务系统集成,公司可以优化其供应链并减少持有成本。
改善医疗分析
在医疗行业,VLM正在改变患者数据管理。将PDF医疗记录转换为Google Sheets可以更好地跟踪患者、分析趋势和研究机会。这一应用不仅改善了患者护理,还为更广泛的公共卫生倡议和流行病学研究做出了贡献。
使用视觉语言模型进行PDF到表格转换以克服OCR挑战的优势
提高准确性和上下文理解
视觉语言模型(VLM)在PDF到表格转换方面提供了显著的进步,超越了传统的光学字符识别(OCR)方法。VLM擅长解释复杂布局、解读手写文本和理解文档中的上下文。这种先进的能力导致了更准确的数据提取,尤其是对于具有复杂设计或图像质量差的PDF。
适应各种文档类型
与通常在非标准格式中挣扎的OCR不同,VLM表现出显著的灵活性。它们可以有效处理各种文档样式,从发票和收据到科学论文和财务报告。这种适应性消除了对多个专用工具的需求,简化了不同PDF类型的转换过程。
智能数据结构化
VLM不仅仅是识别文本,还理解文档的逻辑结构。这种智能使得在转换为Google Sheets时可以更智能地组织数据。表格、图表和分组信息更有可能被准确保留,维护原始文档的预期布局和数据点之间的关系。
持续学习和改进
与静态的OCR系统不同,VLM受益于持续的机器学习进步。它们可以通过新数据进行微调,不断提高其性能并适应不断变化的文档样式。这确保了PDF到表格的转换过程随着时间的推移变得越来越高效和准确。
VLM相较于传统OCR的几个优势:
- 解释复杂布局:VLM可以准确解读复杂的文档结构,保持布局完整性。
- 上下文理解:VLM理解内容的语义意义,从而实现更准确的提取。
- 多语言能力:VLM能够无缝处理文档中的多种语言。
- 噪声减少:VLM过滤低质量扫描或图像中的噪声,确保高质量的数据提取。
关于将PDF转换为Google Sheets的常见问题
我可以将任何PDF转换为Google Sheets吗?
大多数PDF都可以转换为Google Sheets,但成功率取决于PDF的结构和内容。表格、电子表格和结构化数据通常转换良好。然而,复杂布局或图像密集的PDF可能会带来挑战。
转换过程的准确性如何?
PDF到Google Sheets的转换准确性取决于所使用的工具和PDF的复杂性。像AnyParser中使用的视觉语言模型(VLM)相比传统OCR方法提供更高的准确性,尤其是在处理复杂布局和多语言内容时。
在转换过程中我的数据安全吗?
使用像AnyParser这样的信誉良好的工具时,数据安全是重中之重。然而,始终明智地查看您使用的任何转换服务的隐私政策。避免将敏感或机密信息上传到免费的、未经验证的在线转换器。
转换过程需要多长时间?
转换时间取决于PDF的大小、复杂性和所使用的工具。简单的单页PDF可能在几秒钟内完成转换,而较大、复杂的文档可能需要几分钟。使用VLM驱动的工具通常比传统OCR方法处理文件更快。
结论
总之,将PDF文件转换为Google Sheets已成为许多专业人士和企业的重要任务。通过利用视觉语言模型的强大功能,使用像AnyParser这样的工具,您可以简化这一过程并从PDF文档中解锁有价值的数据。VLM技术相较于传统OCR方法的优势显而易见,提供了更高的准确性和灵活性。当您在工作流程中实施这些转换技术时,请记得探索它们所呈现的各种应用和可能性。掌握这些知识后,您现在可以高效地将PDF数据转换为Google Sheets中的可操作洞察,提升您的生产力和决策能力。
行动呼吁
通过尝试AnyParser免费将您的PDF转换为Google Sheets,拥抱视觉语言模型的力量,访问https://www.cambioml.com/sandbox。获取有关VLM如何增强您的数据提取工作流程的免费咨询。
通过与AnyParser团队等行业领导者联系,您可以加速向更自动化、更准确和更具洞察力的数据提取过程的过渡。利用这一尖端技术,简化您的工作流程,解锁文档处理的新可能性。