 来自 Ragas 的评估指标
来自 Ragas 的评估指标
在当今数据驱动的环境中,金融服务等行业高度依赖于从文档中精确和高效的信息提取,尤其是那些包含非结构化文本和结构化数据(如表格和图表)的文档。尽管传统的光学字符识别(OCR)模型被广泛使用,但在处理复杂文档格式时往往表现不佳,导致在高级 AI 应用中的表现不尽如人意。为了填补这一空白,CambioML 和 Epsilla 推出了一个尖端的知识检索系统,承诺显著提高数据提取任务的准确性和召回率。
引言:克服 OCR 的局限性
基于 OCR 的模型虽然在检测文本方面有效,但在提取布局信息和准确提取表格和图表中的数据方面却存在困难。这些局限性在金融和医疗等对精确度要求极高的行业中尤为明显。为了解决这些挑战,CambioML 和 Epsilla 开发了一种新颖的方法,将最先进的表格提取模型与增强检索生成(RAG)技术相结合。该新系统的精确度比传统 RAG 系统提高了 2 倍,召回率提高了 2.5 倍,为文档问答设定了新的标准。
AnyParser:革命性的表格提取
这一突破的核心是 AnyParser,这是一种由先进的视觉语言模型(VLM)驱动的模型,擅长从多种数据源中提取信息。与依赖于 OCR 的传统模型不同,AnyParser 使用视觉和基于文本的编码器的组合,捕捉文档中的每一个细节,确保没有关键数据被遗漏。这种方法在提取金融和医疗文档中的高分辨率数据时尤其有利,因为准确性至关重要。
Epsilla:灵活的 RAG 平台
与 AnyParser 相辅相成的是 Epsilla,这是一种无代码的 RAG-as-a-Service 平台,旨在优化各种 RAG 流水线。Epsilla 通过先进的分块、索引和查询优化技术增强知识检索过程。通过整合基于关键词和语义搜索的方法,Epsilla 提供高度准确和上下文相关的结果,使其成为大型语言模型(LLM)应用的理想解决方案。
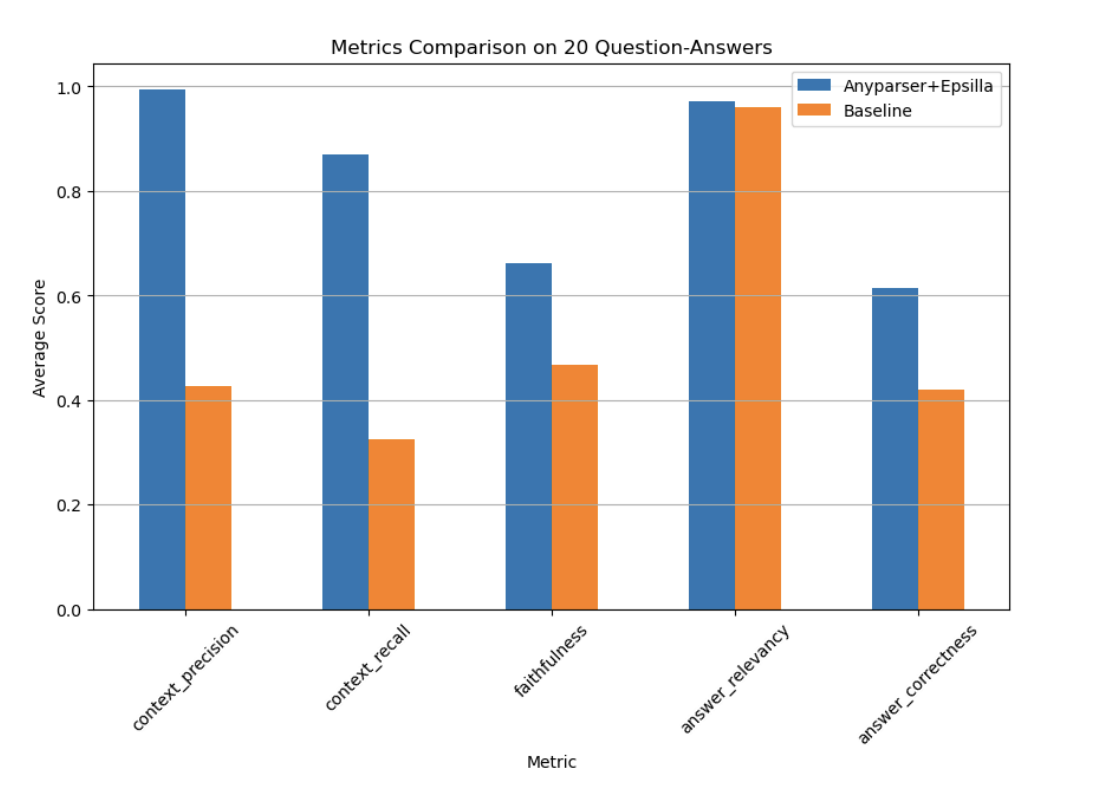
实验与评估:现实世界的影响
来自 Ragas 的评估指标
为了验证 AnyParser 和 Epsilla 的有效性,该系统在来自 Apple 和 Meta 等公司的 10-K 财务文档上进行了测试。结果令人印象深刻,系统在所有关键评估指标(包括上下文精确度、召回率、忠实度和答案正确性)上表现出显著更高的性能。在某些情况下,系统的表现比传统 RAG 系统高出多达 2.7 倍,突显了其在处理复杂数据提取任务中的优越性。
常见用例和关键优势
-
准确性:在将结构化和非结构化数据转换为可用格式方面具有高精度。
-
隐私:能够在客户的数据中心内部署系统,确保数据的完全安全。
-
可扩展性:快速处理大量文档,促进更快的决策。
结论:知识检索的新纪元
AnyParser 和 Epsilla 的推出标志着知识检索技术的重大进步。通过将先进的提取模型与强大的 RAG 基础设施相结合,这一集成解决方案不仅提高了准确性和效率,还提供了现代企业所需的灵活性和隐私。随着技术的不断发展,该系统的应用和优势广泛而充满潜力,使其成为依赖精确数据提取的行业的游戏规则改变者。
有关详细的白皮书,请查看 此链接。