将复杂的PDF转换为Markdown可能会面临挑战。虽然有许多开源库可以从PDF中提取文本,但当涉及到包含复杂元素(如表格和图表)的PDF时,结果往往不尽如人意。像GPT或Claude这样的流行大型语言模型可以处理这些任务,但通常速度较慢,有时会产生不准确的输出。传统的OCR工具虽然对简单文档有效,但在保持原始内容的确切结构和语义意义方面常常力不从心。另一方面,视觉语言模型有时会产生幻觉,导致解析结果错误。本文将解释解析的含义,并详细介绍使用多种指标对多个模型进行比较分析的结果。
解析的含义是什么?
在PDF解析的上下文中,“解析”是指使用称为PDF解析器的专用软件从PDF文件中提取特定数据的过程。PDF解析器分析PDF文档的内容,并识别文本、图像、字体、布局甚至元数据等元素。提取的数据可以组织并导出为XML、JSON或Excel/CSV等不同格式,可用于数据分析、记录保存或工作流自动化等多种用途。
理解解析的含义对于评估解析解决方案的有效性至关重要,尤其是在比较不同的PDF到Markdown转换工具时,因为PDF解析不仅仅涉及简单的文本提取——它还需要识别和保持文档的语义结构。
我们如何衡量这些解析解决方案的质量?
我们定义了一系列基于单词的指标来评估不同模型的性能,重点关注以下关键因素:
-
精确度、召回率和F-Measure:评估解析的质量和完整性。
-
BLEU分数和ANLS:用于评估语言和布局结构。
-
编辑距离、Jensen-Shannon散度和Jaccard距离:特定于OCR领域的指标,特别有助于理解内容再现的准确性。
我们的视觉语言模型AnyParser表现出色,结合了速度和准确性,尤其是在包含表格和语义元素的复杂布局上。AnyParser的性能优于其他解决方案,在速度上比GPT/Claude等模型提高了20倍,同时实现了更高的准确性。
与领先解析模型的广泛比较结果
统计对象
为了真正展示AnyParser的能力,我们对行业内领先的解析模型和知名的大型语言模型(LLMs)进行了广泛的比较。我们的评估包括:
1. 大型语言模型
- AnyParser
- OpenAI的GPT-4o
- Google的Gemini 1.5 Pro
- Anthropic的Claude 3.5 Sonnet
2. 基于OCR的服务
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
结果展示与分析
实验1
首先,我们对不同文档AI模型在以下5个指标上的性能进行了严格比较:BLEU、精确度和召回率、F-Measure和ANLS。您可以在附录中找到这些定义的数学定义。
比较的模型包括:AnyParser-base、AnyParser-pro、Textract、Llama-Parse、GPT4o、Gemini-1.5-pro、GCP-DocAl和Azure-DocAl。
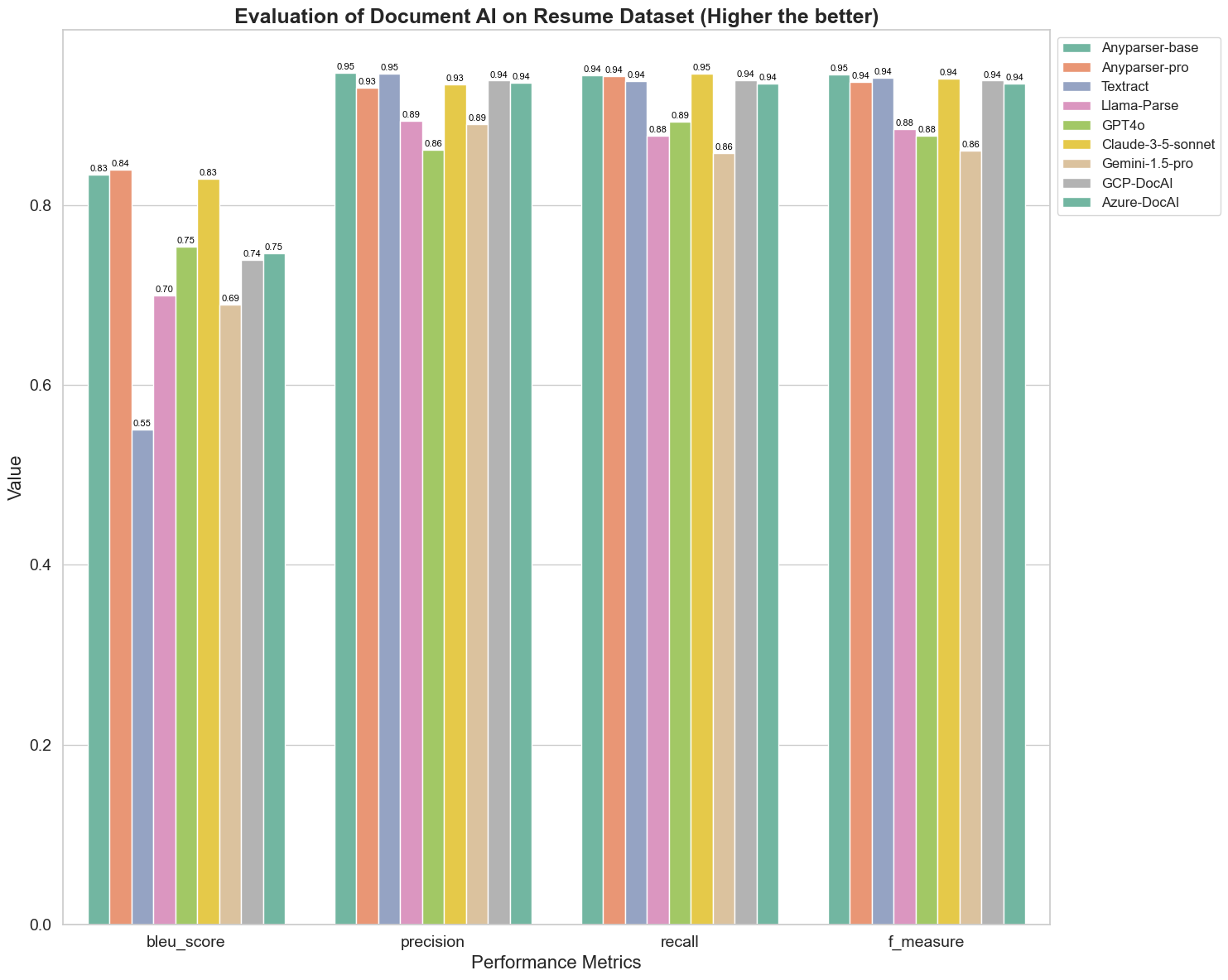
BLEU被用作评估双语翻译质量的工具,以测试模型在处理语句时的质量。通过比较这些解析模型在BLEU评估方法下的结果,我们发现:AnyParser-base和AnyParser-pro的得分显著高于其他模型,Amazon Textract的得分最低,其他模型的得分则处于相对平均水平。
识别准确性通常由精确度和召回率表示,其中精确度表示模型判断为正确的结果中真正正确结果的百分比,而召回率表示模型在所有实际正确结果中真正正确判断结果的百分比。通过比较这些解析模型的精确度和召回率,我们发现:除了Llama-Parse、GPT4o和Gemini-1.5-pro外,所有其他模型的表现都处于高水平。其中,AnyParser和Amazon Textract在精确度上更为突出,而AnyParser-base和AnyParser-pro在召回率上更为突出。模型在精确度上的高得分表明模型在生成结果中输出了更多正确的信息,而召回率的高得分表明模型在从样本中获取正确信息的能力更强。得分结果表明,AnyParser在从PDF中提取文本的识别准确性方面具有明显优势。
F-Measure是对精确度和召回率这两个指标的综合评估指标。通过比较这些解析模型在F-Measure下的得分,我们可以更直观地看到,AnyParser-base、AnyParser-pro、Amazon Textract、GCP-DocAI和Azure-DocAI这五个模型在识别准确性方面相较于其他模型更具优势。我们可以更直观地看到这五个模型在识别准确性方面优于其他模型,而AnyParser在F-Measure下的得分最高,进一步说明了AnyParser在从PDF中提取文本的识别准确性方面的明显优势。
ANLS作为一种常用的评估指标,用于测量原始文本与目标文本在字符级别上的准确性和相似性,对测量模型的解析水平也非常有帮助。AnyParser-base、AnyParser-pro和Azure-DocAI的高得分反映了这些模型相较于其他模型的更高解析水平。
总体而言,AnyParser-base和AnyParser-pro的表现优于其他模型。
实验2
我们还比较了不同文档AI模型在三个不同指标上的性能:编辑距离、Jensen-Shannon散度和Jaccard距离。这些指标用于测量模型输出与参考文档之间的相似性。较低的值表示更好的性能。
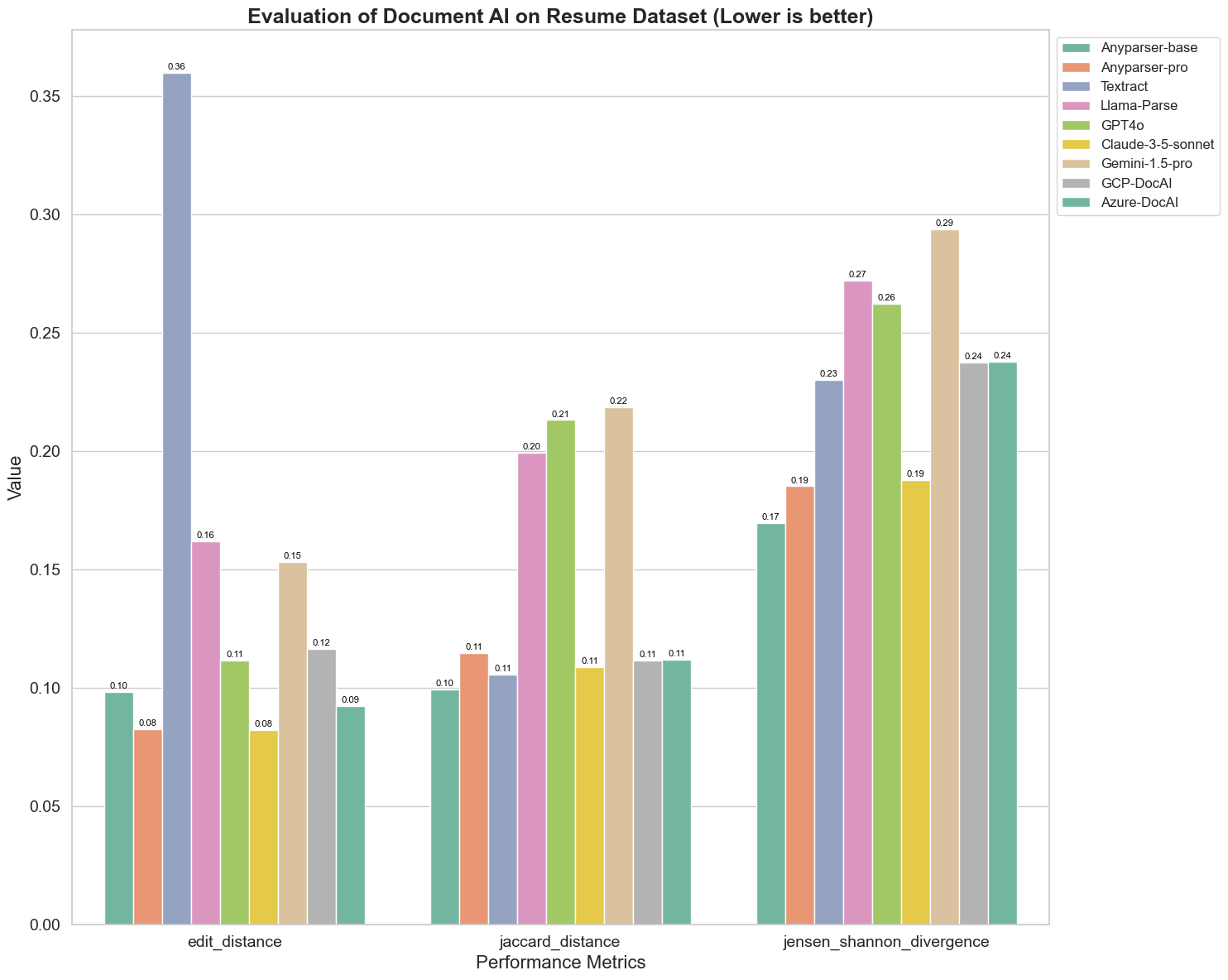
以下是图表的一些关键观察结果:
-
编辑距离:模型AnyParser-base和AnyParser-pro表现最佳,编辑距离最低,表明它们的输出与参考文档最接近。
-
Jensen-Shannon散度:模型AnyParser-base和AnyParser-pro的散度最低,意味着它们的输出在词分布方面与参考文档最相似。
-
Jaccard距离:除了Llama-parse、GPT4O和Gemini-1.5外,所有其他模型的表现都不错,Jaccard距离最低,表明它们的输出在使用的词汇集合上与参考文档的重叠度最高。
结论
总体而言,我们的严格测试表明,AnyParser-base和AnyParser-pro在各种指标上表现良好,表明其在准确文档处理方面的潜力。从图表中可以看出,传统的OCR模型(如著名的Amazon Textract)得分远低于视觉语言模型。然而,不同模型的性能因所用指标而异,这突显了在比较AI模型时考虑多种评估标准的重要性。
介绍我们的开源评估管道
为了简化评估,我们创建了一个评估管道,提供了一种行业标准的方法来比较解析模型。在我们的示例中,我们演示了其在HR领域的应用,其中简历解析是常见的。我们构建了一个包含128份简历的多样化合成数据集,使用成对的图像-Markdown文件生成。利用GPT-4,我们生成了HTML内容,将其渲染为图像,并使用提取的文本作为比较的基准。
而且最棒的是:我们已在GitHub上开源了这个评估框架!无论您是开发者还是商业用户,我们的管道使您能够在自己的数据集上评估和比较不同模型的解析质量。
在Github仓库中找到快速入门指南,看看不同的解析模型如何相互比较。我们相信,通过展示我们模型的优势,我们可以吸引更多希望获得可靠、快速和准确解析能力的用户。
附录 - 指标
1. 精确度
精确度衡量解析内容的准确性,显示在检索元素中有多少是正确的。在解析中,它是正确提取的单词与所有提取单词的比例。
精确度 = 真阳性 (TP) / (真阳性 (TP) + 假阳性 (FP))
- 真阳性 (TP):解析器正确识别的单词。
- 假阳性 (FP):解析器错误识别的单词。
2. 召回率
召回率表示解析的完整性,或从原始文档中检索到多少相关单词。
召回率 = 真阳性 (TP) / (真阳性 (TP) + 假阴性 (FN))
- 假阴性 (FN):原始文档中被解析器遗漏的单词。
3. F-Measure (F1分数)
F1分数是精确度和召回率的调和平均值,平衡这两个指标以提供解析质量的总体衡量。
F1分数 = 2 × (精确度 × 召回率) / (精确度 + 召回率)
4. BLEU分数(双语评估助手)
BLEU分数衡量解析内容与原始文本之间的相似性,特别强调单词的顺序。它在评估解析文档中的语言和结构一致性时特别有用,因为它会惩罚与原始文本顺序不同的输出。
5. ANLS(平均归一化Levenshtein相似度)
ANLS量化解析内容与原始内容之间的相似性,使用归一化编辑距离。它通过对解析文本和参考文本中每对单词的归一化Levenshtein相似度(NLS)进行平均来计算。NLS的计算如下:
NLS = 1 - (Levenshtein距离 (LD)(解析单词, 原始单词)) / max(解析单词的长度, 原始单词的长度)
然后,ANLS是所有单词对的NLS的平均值:
ANLS = (1/N) × Σ(NLS_i) for i=1 to N
6. 编辑距离
编辑距离计算将解析文本转换为原始文本所需的单词级操作(插入、删除、替换)的数量。
7. Jensen-Shannon散度
Jensen-Shannon散度衡量解析和原始单词计数的离散概率分布之间的相似性,突出单词频率的差异。
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
其中 M = (1/2)(P + Q),KL(P || Q)是Kullback-Leibler散度
8. Jaccard距离
Jaccard距离衡量解析和原始内容中单词集合之间的不相似性,适用于评估单词重叠。
Jaccard距离 = 1 - |A ∩ B| / |A ∪ B|
其中 |A ∩ B| 是A和B之间的共同元素数量,
|A ∪ B| 是两个集合中唯一元素的总数。