视觉语言模型(VLM)正在彻底改变文档分析领域,解决传统光学字符识别(OCR)系统固有的许多局限性。虽然OCR一直是从图像中数字化文本的基石技术,但在复杂场景中面临着重大挑战。这些挑战包括低质量图像的准确性问题、有限的上下文理解、混合语言的困难以及无法解释视觉元素。VLM通过结合先进的计算机视觉和自然语言处理能力,提供了一个有前景的解决方案。本文探讨了VLM如何克服OCR的不足,为数字时代的文档处理提供更强大和多样化的解决方案。
什么是OCR?OCR在文档解析中的过程是什么?
光学字符识别(OCR)是一种技术,能够将不同类型的文档(如扫描的纸质文档、PDF文件或数字相机拍摄的图像)转换为可编辑和可搜索的数据。这个过程在文档处理和PDF数据提取中至关重要,使机器能够识别数字图像中的印刷或手写文本字符。
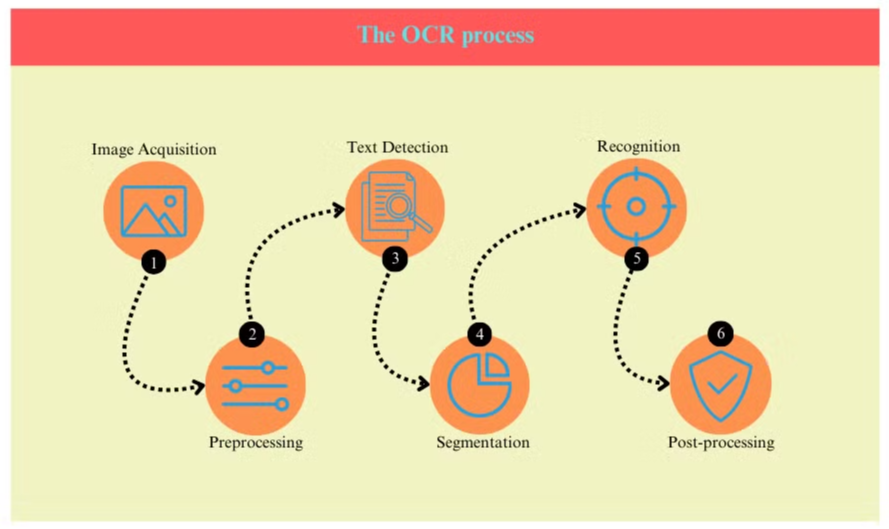
OCR过程
OCR过程通常涉及几个步骤:
- 图像获取:对文档进行扫描或拍照,以创建数字图像。
- 预处理:对图像进行清理,去除噪声并调整亮度和对比度。
- 文本检测:系统识别图像中包含文本的区域。
- 字符分割:在文本区域内孤立出单个字符。
- 字符识别:分析每个字符并与已知字符数据库进行比较。
- 后处理:使用语言和上下文信息检查识别的文本是否存在错误。
尽管OCR在文档解析能力上有了很大改善,但在处理复杂布局、低质量图像和多样字体时仍面临局限性。这正是视觉语言模型等先进技术介入以提高从图像和文档中提取数据的准确性和理解能力的地方。
传统OCR技术的局限性
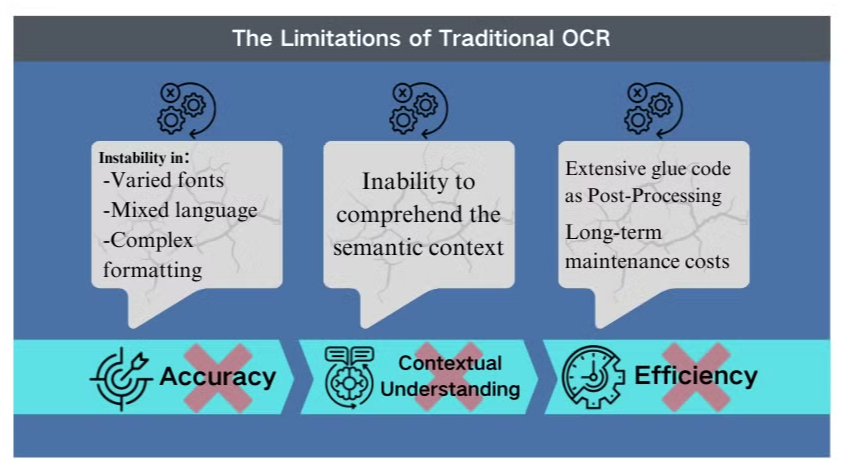
复杂场景中的准确性挑战
传统的光学字符识别(OCR)技术虽然在基本文本提取方面有益,但在面对复杂文档布局或低质量图像时面临重大障碍。这些系统在处理具有多样字体、混合语言或复杂格式的文档时,往往难以保持准确性。例如,OCR在尝试从图像密集的演示文稿或格式复杂的PDF中提取数据时可能会出现问题。
缺乏上下文理解
传统OCR最明显的局限性之一是其无法理解所处理文本的语义上下文。这一缺陷在需要细致解释的场景中尤为明显,例如法律合同或医疗报告。OCR专注于字符识别而缺乏上下文意识,可能导致关键的误解,尤其是在处理模糊字符或行业特定术语时。
后处理中的低效
OCR的局限性往往需要大量的后处理工作。这一额外步骤可能显著增加文档处理所需的时间和资源。此外,传统OCR系统在提取图表、表格或其他非文本元素的信息时通常表现不佳,进一步复杂化了文档提取过程。这些低效性强调了更先进解决方案的需求,例如视觉语言模型,它们提供了更全面的文档分析和数据提取方法。
什么是视觉语言模型,它如何改善OCR
视觉语言模型代表了文档处理技术的重大进步,解决了传统光学字符识别(OCR)系统固有的许多局限性。这些先进模型将计算机视觉与自然语言处理相结合,能够同时理解文档的视觉和文本元素。
提高准确性和上下文理解
与在低质量图像和复杂布局中挣扎的OCR不同,视觉语言模型在解释多样文档格式方面表现出色。即使在面临挑战的场景中,它们也能准确提取图像、PDF和其他视觉内容中的数据。这种改进的准确性源于它们能够考虑文档的整体上下文,而不仅仅是关注单个字符或单词。
全面的数据提取
视觉语言模型超越了简单的文本识别,提供全面的PDF数据提取能力。它们能够识别和解释文档中的表格、图表和图形,保持复杂布局的完整性。这种全面的文档分析方法使得信息检索更加细致和完整,显著增强了提取数据在下游应用中的实用性。
多语言和多格式的能力
视觉语言模型的一个关键优势是它们在处理多种语言和文档格式方面的灵活性。与可能在处理非拉丁脚本或混合语言文档时遇到困难的OCR系统不同,这些模型能够无缝处理各种语言和脚本的内容,使其在全球文档处理需求中不可或缺。
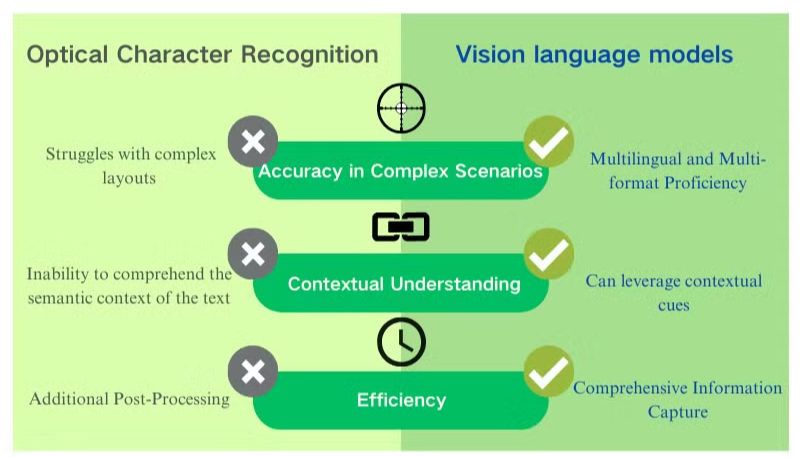
视觉语言模型在文档理解中的关键优势
视觉语言模型在文档处理和数据提取方面相较于传统OCR提供了显著优势。这些人工智能驱动的系统结合了视觉和文本理解,能够在各种文档类型中提供卓越的结果。
提高准确性和上下文理解
视觉语言模型在处理复杂布局、低质量图像和多样字体方面表现出色。与在模糊字符方面挣扎的OCR不同,这些模型利用上下文线索准确解释文本。这一能力显著提高了PDF数据提取的准确性,尤其是对于结构复杂或图像质量较差的文档。
全面的信息捕获
虽然OCR仅专注于文本识别,但视觉语言模型能够从图像、表格和图表中提取数据。这种全面的方法确保在文档处理阶段不会遗漏关键信息。通过捕获文本和视觉元素,这些模型提供了对文档内容的更完整理解。
多语言和多格式的能力
视觉语言模型在处理各种语言和格式的文档时表现出显著的灵活性。它们能够无缝处理混合语言文档和非拉丁脚本,克服了传统OCR系统的一个重大局限性。这种多样性使它们在处理多种文档类型和语言的全球企业中不可或缺。
VLM在OCR未能实现的实际应用
视觉语言模型正在金融、人力资源和其他领域革命性地改变文档处理,解决传统OCR系统的关键局限性。这些先进的人工智能模型通过提供更高的准确性和上下文理解,正在改变各行业的数字化转型努力。
革新金融文档处理
视觉语言模型正在改变金融领域的文档处理,克服传统OCR的局限性。这些先进模型在提取复杂财务报表、发票和收据中的数据方面表现出色,能够理解上下文,准确解释模糊字符(例如区分零和字母O)以及全球金融文档中常见的混合语言。
通过智能文档分析增强人力资源运营
在人力资源领域,视觉语言模型在从简历、员工记录和绩效评估中进行PDF数据提取方面证明了其不可或缺的价值。这些模型能够理解文档的语义结构,从而实现更准确的信息检索和分析。这一能力显著简化了招聘流程和员工数据管理,而这些任务通常是OCR在处理多样格式和手写笔记时所面临的挑战。
改善合规性和风险管理
视觉语言模型在金融和人力资源的合规性和风险管理中尤其有效。它们能够从监管文档、合同和政策中提取和解释关键信息,准确性高于OCR。这种增强的文档处理能力确保更好地遵守法律要求,并提高风险评估程序的效率。
结论
总之,视觉语言模型代表了文档处理技术的重大进步,解决了传统OCR系统固有的许多局限性。通过结合视觉和文本理解,这些先进模型在各种具有挑战性的场景中提供了卓越的性能,从复杂布局到混合语言和低质量图像。随着组织继续数字化其运营并寻求更高效的方式从文档库中提取价值,视觉语言模型作为开发者和工程领导者的强大工具脱颖而出。它们理解上下文、处理多样格式并提供更准确结果的能力,使其成为复杂RAG管道和企业范围搜索能力的关键推动者,最终推动数字化转型倡议达到新的高度。