什么是结构化数据和非结构化数据
在数字信息时代,数据随时生成,企业通过数据的分析和处理创造价值。因此,收集和记录数据以及处理和分析数据已成为商业运营中的两项重要任务。在数据收集的过程中,非结构化数据更为常见,这些数据的来源和形式多种多样,难以简单分类或搜索。有效的数据摄取对组织高效地将原始数据转化为可操作的洞察至关重要。在数据处理过程中,更常见的是结构化数据,它具有清晰的结构、明确定义的信息,并且可以轻松组织、搜索和分析。因此,将非结构化数据转化为结构化数据是企业利用数据价值的重要一步。
结构化数据
结构化数据是符合预定义数据模型或架构的数据。它特别适用于处理离散的、数值型的数据,例如财务操作、销售和营销数字以及科学建模。
结构化数据通常是定量的,并以易于搜索的方式组织。它包括常见类型,如姓名、地址、信用卡号码、电话号码、星级评分、银行信息等,这些数据可以在关系数据库中使用SQL轻松查询。
在实际应用中,结构化数据的例子包括预订航班时的航班和预订数据,以及CRM系统(如Salesforce)中的客户行为和偏好。它最适合与离散的、简短的、非连续的数值和文本值相关的集合,并用于库存控制、CRM系统和ERP系统。
结构化数据存储在关系数据库、图形数据库、空间数据库、OLAP立方体等中。它最大的好处是更容易组织、清理、搜索和分析,但主要挑战在于所有数据必须符合规定的数据模型。
非结构化数据
非结构化数据是没有底层模型来辨别属性的数据。当数据无法适应结构化数据格式时,就会使用非结构化数据,例如视频监控、公司文档和社交媒体帖子。
非结构化数据的例子包括多种格式,如电子邮件、图像、视频文件、音频文件、社交媒体帖子、PDF等。大约80-90%的数据是非结构化的,这意味着如果公司能够利用这些数据,将具有巨大的竞争优势。
在实际应用中,非结构化数据的例子包括聊天机器人执行文本分析以回答客户问题和提供信息,以及用于预测股票市场变化以做出投资决策的数据。非结构化数据最适合与数据、对象或文件相关的集合,其中属性变化或未知,并且与演示或文字处理软件及查看或编辑媒体的工具一起使用。非结构化的补充服务数据,如社交媒体帖子和客户反馈,在转换为结构化格式时可以提供有价值的洞察。
它通常存储在数据湖、NoSQL数据库、数据仓库和应用程序中。非结构化数据的最大好处是能够分析无法轻易转换为结构化数据的数据,但主要挑战在于分析可能会很困难。非结构化数据的主要分析技术因上下文和使用的工具而异。
结构化数据与非结构化数据的区别
结构化数据的优势与非结构化数据的劣势
结构化数据的优势在于易于搜索并可用于机器学习算法,使其对企业和组织在解读数据时更加可访问。与非结构化数据相比,分析结构化数据的工具也更多。另一方面,非结构化数据需要数据科学家具备准备和分析数据的专业知识,这可能限制组织中其他员工的访问。此外,处理非结构化数据需要特殊工具,进一步导致其可访问性不足。
结构化数据分析与非结构化数据分析
结构化数据分析通常更为简单,因为数据是严格格式化的,允许使用编程逻辑搜索和定位特定数据条目,以及创建、删除或编辑条目。这使得结构化数据的自动化数据管理和分析更加高效。相反,非结构化数据分析没有预定义的属性,使得搜索和组织变得更加困难。非结构化数据分析通常需要复杂的算法来预处理、操作和分析,给分析过程带来了更大的挑战。非结构化补充服务数据的分析通常需要先进的解析技术来提取有意义的信息。
结构化数据管理与非结构化数据管理
由于结构化数据的组织性和可预测性,结构化数据的管理通常更为高效。计算机、数据结构和编程语言更容易理解结构化数据,从而在使用时面临的挑战较小。相比之下,非结构化数据管理面临两个重大挑战:存储,因为非结构化数据管理通常面临比结构化数据管理更大的处理需求;分析,因为非结构化数据管理的分析并不像结构化数据管理那样简单。为了理解和管理非结构化数据,计算机系统必须首先将其分解为可理解的组件,这一过程更加复杂。
结构化数据与非结构化数据的区别总结
结构化数据是定义明确且可搜索的,包括日期、电话号码和产品SKU等数据。这使得它比非结构化数据更容易组织、清理、搜索和分析,后者则包括更难以分类或搜索的所有其他数据,如照片、视频、播客、社交媒体帖子和电子邮件。用一句话来解释结构化数据与非结构化数据的区别:世界上大多数数据是非结构化的,但结构化数据的易管理性和易分析性使其在数据可以整齐组织和快速访问的应用中具有显著优势。
结构化数据与非结构化数据的例子
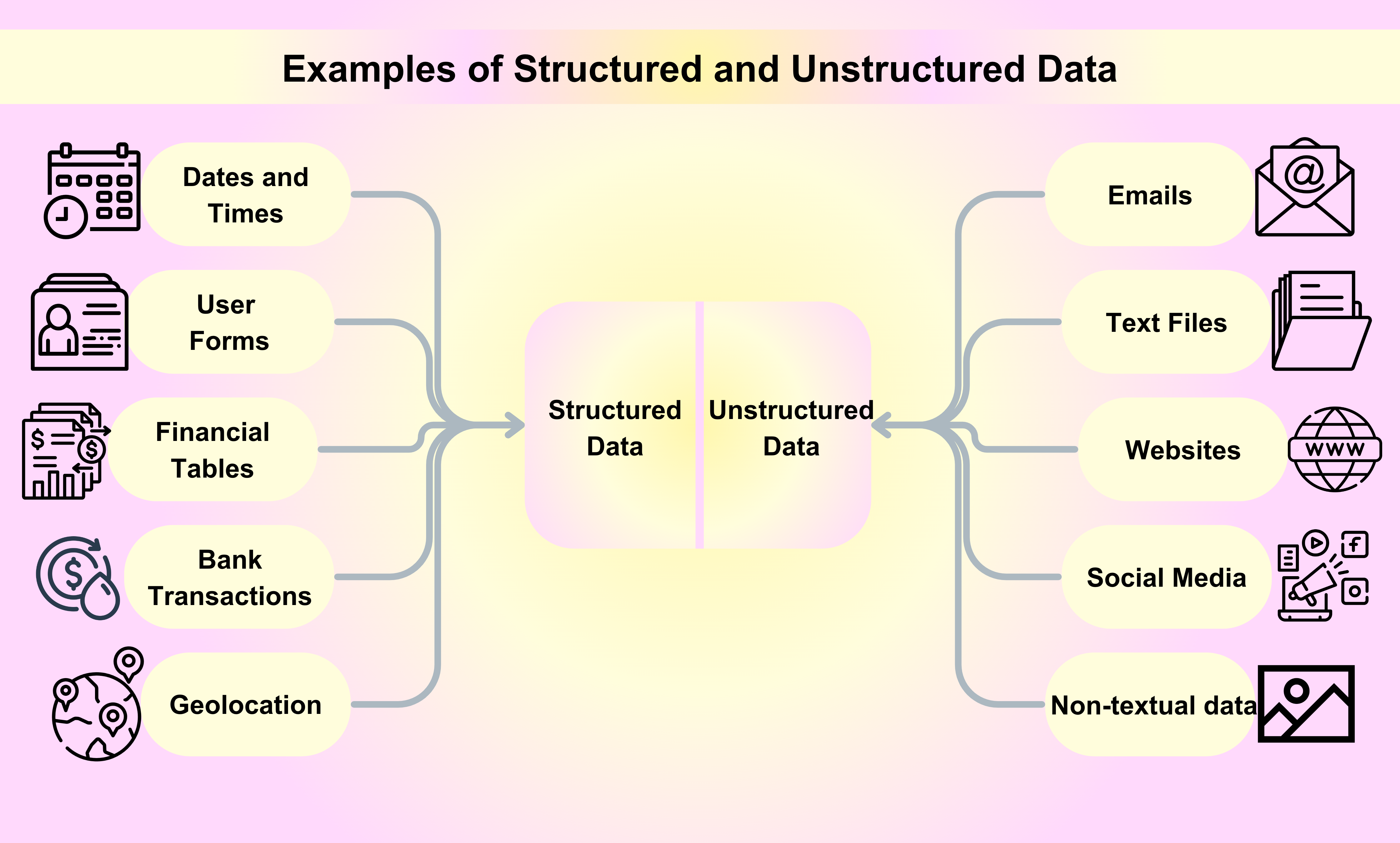
结构化数据示例
-
日期和时间:日期和时间遵循特定格式,使机器能够轻松读取和分析。例如,日期可以结构化为YYYY-MM-DD,而时间可以结构化为HH:MM:SS。
-
客户姓名和联系信息:当您注册服务或在线购买产品时,您的姓名、电子邮件地址、电话号码和其他联系信息以结构化方式收集和存储。
-
金融交易:信用卡交易、银行存款和电汇等金融交易都是结构化数据的例子。每笔交易都有特定的信息,包括序列号、交易日期、金额和相关方。
-
股票信息:股票信息,如股价、交易量和市值,另一个结构化数据的例子。这些信息系统地组织并实时更新。
-
地理位置:地理位置数据,包括GPS坐标和IP地址,通常用于各种应用,从导航系统到基于位置的营销活动。
非结构化数据示例
-
电子邮件:电子邮件是我们每天用于商业或个人目的的最常见非结构化数据示例之一。
-
文本文件:非结构化数据的例子包括文字处理文件、电子表格、PDF文件、报告和演示文稿。
-
网站:来自YouTube、Instagram和Flickr等网站的内容被视为非结构化数据的例子。
-
社交媒体:来自Facebook、Twitter和LinkedIn等社交媒体平台生成的数据是非结构化数据的例子。
-
媒体:数字图像、音频录音和视频代表了大量以非结构化方式存在的非文本数据,可以视为非结构化数据的例子。
结构化数据分析的技术
-
SQL查询:结构化数据可以使用SQL(结构化查询语言)高效查询,从而快速检索和操作存储在关系数据库中的数据。
-
数据仓库:结构化数据可以存储在数据仓库中,数据仓库集成来自多个来源的数据并支持复杂的查询和分析。
-
机器学习算法:算法可以轻松处理结构化数据以识别模式和进行预测。
结构化数据易于理解和操作,使其对广泛用户可访问。结构化数据允许高效的存储、检索和分析,从而加快决策过程。结构化数据系统可以扩展以处理大量数据,确保随着数据增长性能保持高效。
非结构化数据分析的技术
-
自然语言处理(NLP):NLP技术用于分析文本数据,从大量非结构化文本中提取有意义的信息和洞察。
-
机器学习:机器学习算法可以训练以识别非结构化数据中的模式,例如图像或音频文件。
-
数据湖:非结构化数据可以存储在数据湖中,数据湖允许以其原始格式存储原始数据,直到需要进行分析。
从非结构化数据分析技术的例子来看,分析非结构化数据更为复杂,需要专业的工具和技术。处理非结构化数据通常需要显著的计算资源和存储能力。非结构化数据可能包含不一致性、错误或无关信息,使确保数据质量变得具有挑战性。简化数据摄取可以显著增强组织管理和分析大量数据的能力。
转换非结构化数据为结构化数据的需求示例
-
客户反馈分析:将客户评论和反馈从非结构化文本转换为结构化数据,使企业能够进行情感分析并识别客户满意度的趋势。
-
医疗记录:将非结构化医疗记录(如医生的笔记和影像报告)结构化,使其能够更好地与电子健康记录(EHR)系统集成,改善患者护理。
-
合规与报告:数据摄取过程涉及从各种来源提取、加载和转换数据为适合分析的格式。组织可能需要将非结构化数据转换为结构化格式,以遵守监管要求并促进准确报告。
-
市场研究:将来自调查和焦点小组的非结构化数据转换为结构化数据,有助于分析市场趋势和消费者行为。
AnyParser如何将非结构化数据解析为结构化数据
AnyParser是由CambioML开发的一款强大的文档解析工具,旨在从各种非结构化数据源(如PDF、图像和图表)中提取信息,并将其转换为结构化格式。它利用先进的视觉语言模型(VLM)实现高精度和高效率的数据提取。
主要特性
-
精确性:准确提取文本、数字和符号,同时保持原始布局和格式。
-
隐私:在本地处理数据,以确保用户隐私和敏感信息的保护。
-
可配置性:允许用户定义自定义提取规则和输出格式。
-
多源支持:支持从各种非结构化数据源(包括PDF、图像和图表)中提取数据。
-
结构化输出:将提取的信息转换为结构化格式,如Markdown、CSV或JSON。
使用AnyParser解析非结构化数据的步骤
-
上传文档:首先将您的非结构化数据文件(例如PDF、图像)上传到AnyParser的网页界面。您可以拖放文件或粘贴截图以快速处理。
-
选择提取选项:选择您想要提取的数据类型。例如,如果您需要从PDF中提取表格,请选择“仅表格”选项。
-
处理文档:AnyParser的API引擎将处理文档,准确检测并提取所需信息。该工具使用先进的VLM技术识别相关数据点并将其转换为结构化格式。
-
预览和验证:使用AnyParser的预览功能查看提取的数据。将初始提取与原始文档进行比较,以确保准确性。
-
下载或导出:一旦对提取结果满意,下载结构化数据文件(例如CSV、Excel)或直接导出到Google Sheets等平台以进行进一步分析。
使用AnyParser的好处
-
效率和准确性:自动化数据提取任务,减少人工工作量并最小化错误。
-
数据安全:确保敏感信息在本地处理,符合数据隐私标准。
-
灵活定制:用户可以根据特定需求调整提取参数和输出格式。
-
增强分析专注:简化数据提取,使专业人员能够专注于更高价值的分析。
应用场景
-
AI工程师:从PDF中提取文本和布局信息,以开发和训练AI模型。
-
金融分析师:从PDF表格中提取数据信息,以进行准确的财务分析。
-
数据科学家:处理大量非结构化文档,以发现洞察和趋势。
-
企业:自动化处理和分析各种文档,如合同和报告,以提高运营效率。
通过利用AnyParser,用户可以将复杂的非结构化数据转换为结构化的可编辑文件,顺利地将其整合到工作流程中,以增强数据分析和管理能力。
结论
在数字时代,使用像AnyParser这样的工具将非结构化数据转换为结构化格式对于企业解锁洞察和获得竞争优势至关重要。AnyParser可以用于解析非结构化补充服务数据,使其更容易集成到商业智能系统中。通过简化这一过程,组织可以高效地利用其数据的全部潜力,从而推动更好的决策和战略规划。