Im Bereich des Datenmanagements bezieht sich Parsing auf die Umwandlung des Inhalts—wie Text, Bilder, Tabellen und Metadaten—in ein verwendbares Format (z. B. Klartext, strukturierte Daten oder Bilder), das weiter verarbeitet oder analysiert werden kann. Dies wird besonders im Bereich des PDF-Parsings deutlich, einer entscheidenden Methode, die rohe Informationen in strukturierte, nutzbare Daten umwandelt. Dieser umfassende Leitfaden behandelt die Feinheiten des PDF-Parsings, erläutert dessen Definition, das Spektrum der extrahierbaren Daten, die Herausforderungen, denen es gegenübersteht, seine vielfältigen Anwendungen und die Fülle an Methoden, die zur vollständigen Ausschöpfung seines Potenzials zur Verfügung stehen. Sie werden verschiedene Parsing-Methoden erkunden, mit einem besonderen Fokus auf PDF Parsing und wie Tools wie AnyParser sich von der Masse abheben.
Verständnis des PDF-Parsers: Was ist Parsing?
Was ist Parsing: sorgfältiger Datenaufnahmeprozess
Im Kern bezieht sich PDF Parsing auf den Prozess der Extraktion und Interpretation von Daten aus PDF-Dateien (Portable Document Format). Da PDFs hauptsächlich für die Anzeige und nicht für die strukturierte Datenspeicherung konzipiert sind, umfasst Parsing die Umwandlung des Inhalts—wie Text, Bilder, Tabellen und Metadaten—in ein verwendbares Format (z. B. Klartext, strukturierte Daten oder Bilder), das weiter verarbeitet oder analysiert werden kann. Parsing erfordert eine hochrangige Analyse, um spezifische Elemente innerhalb eines PDFs zu identifizieren und abzurufen, die über einfachen Text und Bilder hinausgehen und auch Schriftarten, Layouts, Tabellen und Metadaten umfassen. Dieser Prozess ist nicht nur eine technische Notwendigkeit, sondern auch in Branchen wie Finanzen, Recht, Logistik und Gesundheitswesen von entscheidender Bedeutung, in denen die Wiederverwendung von Informationen von größter Wichtigkeit ist.
Daten, die aus PDFs geparsed werden können
Die aus PDFs extrahierbaren Daten sind vielfältig und umfangreich, einschließlich:
-
Textabsätze: Sequenzen von Wörtern und Zeichen.
-
Einzelne Datenfelder: Einzelne Elemente wie Daten, Sendungsverfolgungsnummern und Namen.
-
Tabellarische Daten: Informationen, die in Tabellen und Listen organisiert sind.
-
Bilder: Grafische Inhalte, die im PDF eingebettet sind.
-
Erweiterte Elemente: Kopfzeilen, Objekte, Querverweistabellen, Trailer und Metadaten, die ausgefeiltere Parsing-Tools erfordern.
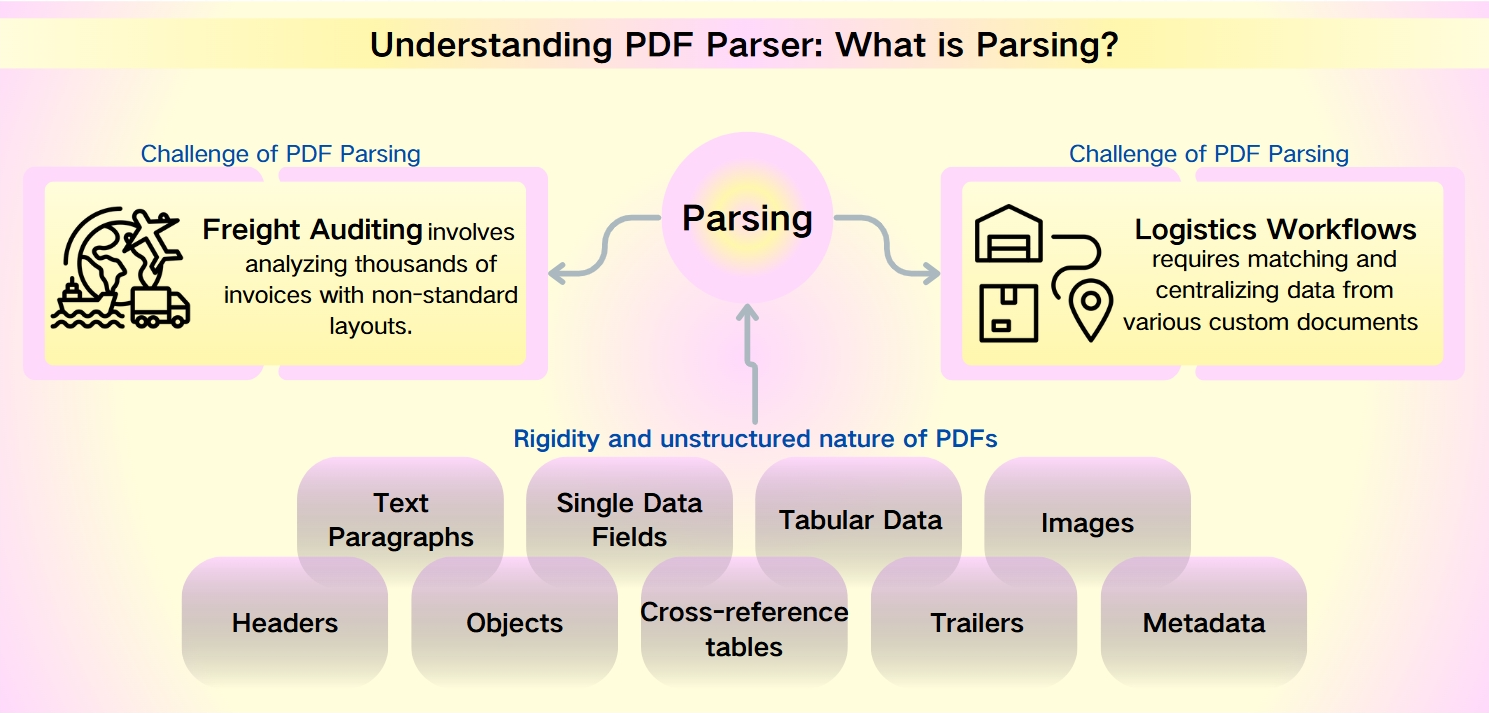
Herausforderungen des PDF-Parsings: unstrukturierte Natur der PDF-Metadaten
Trotz der Robustheit von PDFs—gekennzeichnet durch ihre Sicherheit, Gerätekompatibilität und kompakten Dateigrößen—stellt die Datenextraktion aus ihnen eine erhebliche Herausforderung dar. Die Starrheit und unstrukturierte Natur von PDFs erschweren eine schnelle Analyse und Informationsbeschaffung. Dies ist besonders ausgeprägt in Szenarien wie der Frachtprüfung und Logistik-Workflows, in denen nicht standardisierte Layouts und umfangreiche Datensätze die Komplexität erhöhen.
Die Frachtprüfung umfasst die Analyse von Tausenden von Rechnungen mit nicht standardisierten Layouts. Logistik-Workflows erfordern das Abgleichen und Zentralisieren von Daten aus verschiedenen benutzerdefinierten Dokumenten wie Packlisten, Handelsrechnungen und Frachtbriefen.
Die Bedeutung des Parsings
Parsing spielt eine entscheidende Rolle in verschiedenen Bereichen, von der Webentwicklung bis zur Datenerfassung. Es ermöglicht Unternehmen, wertvolle Einblicke aus unstrukturierten Datenquellen wie PDF-Dokumenten, HTML-Dateien und XML-Daten zu extrahieren. Parsing erleichtert:
-
Verbesserte Entscheidungsfindung durch datengestützte Einblicke.
-
Erhöhte Datengenauigkeit und Konsistenz.
-
Rationalisierte Datenverarbeitung und -analyse.
-
Effiziente Informationsbeschaffung und -speicherung.
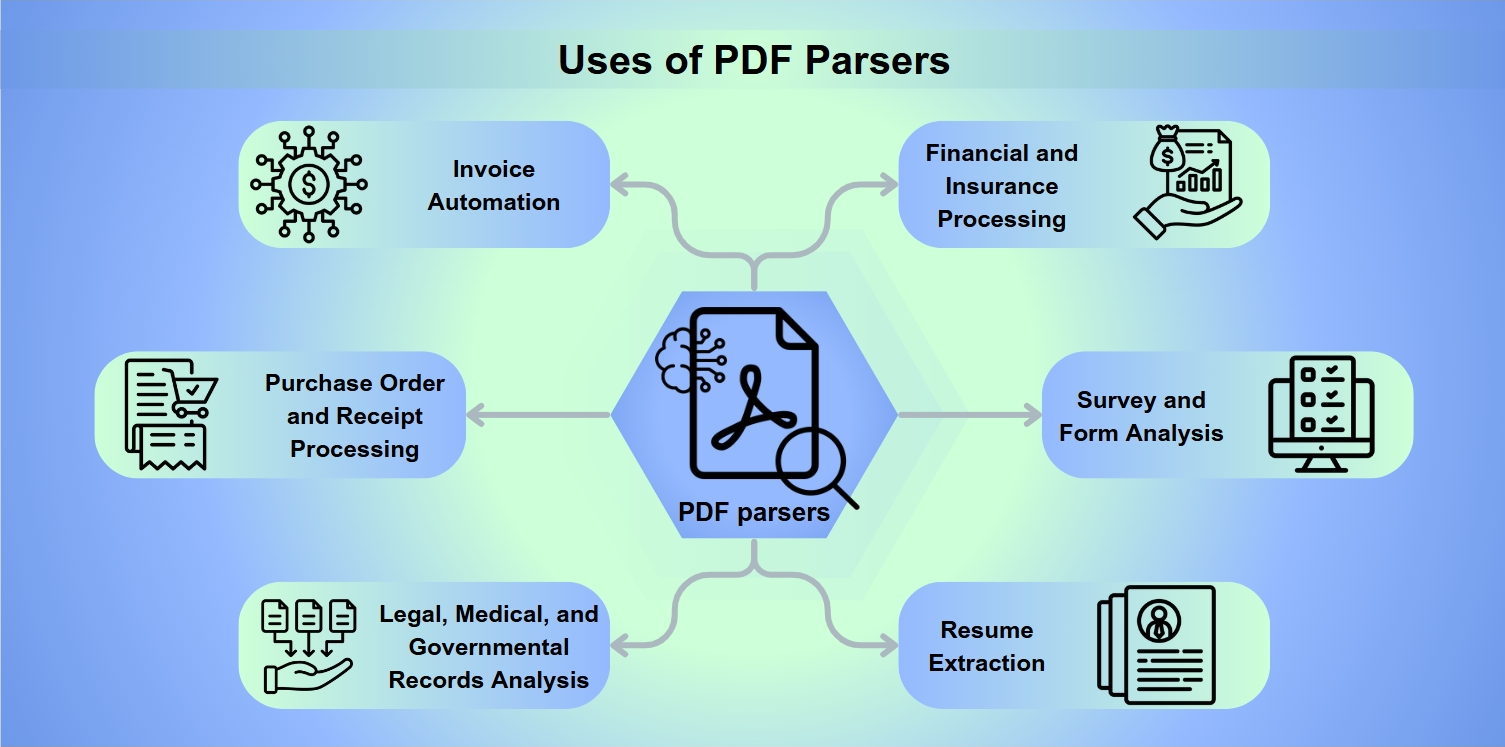
Anwendungen von PDF-Parsern
PDF-Parser sind unverzichtbare Werkzeuge in einer Vielzahl von Anwendungen, einschließlich:
-
Rechnungsautomatisierung: Rationalisierung der Verarbeitung und Zahlung von Rechnungen.
-
Bearbeitung von Bestellungen und Quittungen: Erleichterung von Rückerstattungen und Erstattungen.
-
Analyse von rechtlichen, medizinischen und staatlichen Aufzeichnungen: Ermöglichung einer tiefgreifenden Datenextraktion zur Analyse.
-
Finanz- und Versicherungsbearbeitung: Risikobewertung und Analyse von Bilanzen.
-
Umfrage- und Formularanalyse: Sammlung und Interpretation von Formularantworten.
-
Lebenslauf-Extraktion: Unterstützung von Recruitern bei der Kandidatenauswahl.
Vergleich verschiedener Parsing-Methoden
Die Methoden zur Datenextraktion haben sich im Laufe der Zeit erheblich weiterentwickelt. Traditionelle Ansätze zur Datenerfassung basieren oft auf regulären Ausdrücken (Regex), um spezifische Muster aus Text zu extrahieren. Obwohl leistungsfähig, kann Regex komplex und schwer wartbar werden, insbesondere bei komplizierten Parsing-Aufgaben. Eine weitere gängige Technik ist die Zeichenfolgenmanipulation, die das Aufteilen und Verarbeiten von Text basierend auf Trennzeichen oder spezifischen Zeichen umfasst. Diese Methoden sind zwar in bestimmten Szenarien weiterhin nützlich, können jedoch mit unstrukturierten oder inkonsistenten Datenformaten Schwierigkeiten haben.
Die Landschaft des PDF-Parsings wird durch eine Vielzahl von Methoden bedient, die jeweils ihre eigenen Vor- und Nachteile haben:
-
Online-PDF-Konverter/Parser: Wie Zamzar und Smallpdf bieten Bequemlichkeit und Geschwindigkeit, sind jedoch in der Funktionalität eingeschränkt und potenziell unsicher.
-
Adobe Acrobat: Bewahrt Struktur und Formatierung, kann jedoch manuelle Anpassungen nach der Konvertierung erfordern.
-
Kopieren und Einfügen: Bietet vollständige Kontrolle, ist jedoch mühsam und fehleranfällig.
-
Automatisierte Plattformen: Moderne Parsing-Technologien wie AnyParser nutzen maschinelles Lernen und natürliche Sprachverarbeitung (NLP), um komplexere Datenstrukturen zu verarbeiten.
Diese KI-gesteuerten Ansätze können Kontext und Semantik verstehen, was sie besonders effektiv für das Parsing unstrukturierter Texte oder Dokumente mit variierenden Formaten macht. Einige fortschrittliche Parser verwenden Deep-Learning-Modelle, um relevante Informationen mit hoher Genauigkeit zu identifizieren und zu extrahieren, selbst aus zuvor unbekannten Dokumentenlayouts.
So führen Sie PDF Parsing durch: Der beste kostenlose PDF-Parser zur Extraktion von PDF-Metadaten
Verständnis von PDF-Metadaten
PDF-Metadaten enthalten wichtige Informationen über ein Dokument, einschließlich Titel, Autor, Erstellungsdatum und Schlüsselwörter. Die effiziente Extraktion dieser Metadaten ist entscheidend für die Organisation, Suche und Verwaltung großer Sammlungen von PDF-Dateien. Ein robuster PDF-Parser kann diesen Prozess rationalisieren, Zeit sparen und die Produktivität des Workflows verbessern.
Hauptmerkmale der besten PDF-Parser
Die besten kostenlosen PDF-Parser bieten eine Kombination aus Genauigkeit, Geschwindigkeit und Vielseitigkeit. Sie sollten in der Lage sein, verschiedene PDF-Formate zu verarbeiten, einschließlich gescannter Dokumente und solcher mit komplexen Layouts. Achten Sie auf Parser, die nicht nur grundlegende Metadaten, sondern auch benutzerdefinierte Felder und versteckte Informationen extrahieren können. Darüber hinaus bieten erstklassige Parser oft Optionen für die Batch-Verarbeitung und die Integration mit anderen Softwaresystemen.
Funktionen von AnyParser
AnyParser, entwickelt von CambioML, ist besonders bemerkenswert aufgrund seiner Genauigkeit, Privatsphäre und Konfigurierbarkeit. Die Fähigkeit von AnyParser, mehrere Dateiformate zu verarbeiten, seine benutzerfreundliche Oberfläche und seine Skalierbarkeit machen es zu einer ausgezeichneten Wahl für Unternehmen jeder Größe. Darüber hinaus ermöglicht die API eine nahtlose Integration in bestehende Workflows, was die Effizienz des Dokumentenmanagements insgesamt verbessert. Hier sind einige der Hauptmerkmale, die AnyParser zu einer hervorragenden Wahl für PDF Parsing machen:
-
Präzision: AnyParser ist darauf ausgelegt, Text, Zahlen und Symbole genau zu extrahieren, während das ursprüngliche Layout und Format beibehalten werden. Es nutzt fortschrittliche Sprachmodelle, um das Verständnis von Dokumenten und die Informationsextraktion zu verbessern, mit einer bis zu 2-fach höheren Genauigkeitsrate im Vergleich zu traditionellen OCR-Modellen.
-
Privatsphäre: Es unterstützt sowohl die lokale als auch die Cloud-Datenextraktion und stellt sicher, dass sensible Informationen privat und sicher bleiben.
-
Konfigurierbarkeit: Benutzer können Extraktionsregeln und Ausgabeformate an spezifische Bedürfnisse anpassen.
-
Unterstützung mehrerer Quellen: AnyParser unterstützt eine Vielzahl von Dokumenttypen, einschließlich PDFs, Bildern und Diagrammen.
-
Strukturierte Ausgabe: Extrahierte Informationen können in strukturierte Formate wie Markdown, Excel oder JSON umgewandelt werden, was eine weitere Verarbeitung und Analyse erleichtert.
-
Cloud-basierte Bereitstellungsoptionen: Das AnyParser SDK kann in der Cloud, in Rechenzentren oder privat bereitgestellt werden und bietet Flexibilität und Skalierbarkeit.
-
Benutzerfreundliche Oberfläche: Das Tool bietet eine einfache API, die es ermöglicht, komplexe Dokumentenparsing-Aufgaben mit nur wenigen Codezeilen zu erledigen.
-
Hohe Leistung: Optimierte Algorithmen gewährleisten eine schnelle Verarbeitung einer großen Anzahl von Dokumenten, 5-mal schneller als allgemeine LLMs wie GPT-4.
-
Community-Support: Als Open-Source-Projekt profitiert AnyParser von einer aktiven Community und begrüßt Beiträge.
-
Kostenloses Nutzungskontingent: AnyParser bietet ein kostenloses Nutzungskontingent mit jedem Konto, das es Benutzern ermöglicht, die Fähigkeiten des Tools zu testen, bevor sie sich für einen kostenpflichtigen Plan entscheiden.
-
Kundenfeedback: Benutzer haben AnyParser für seine hohe Genauigkeit, den Erhalt der Privatsphäre und die Effizienz bei der Datenextraktion gelobt, wobei Fallstudien signifikante Zeitersparnisse und verbesserte Datenqualität zeigen.
Diese Vorteile machen AnyParser zu einem wertvollen PDF-Datenextraktor für das Dokumentenparsing und die Informationsextraktion, insbesondere für Unternehmensbenutzer, die hohe Präzision und Sicherheit benötigen. Mit fortlaufenden technologischen Fortschritten und aktivem Community-Engagement ist AnyParser bereit, eine zunehmend wichtige Rolle im Bereich des Dokumentenparsing und der Informationsextraktion zu spielen.
Technische Erklärung von PDF-Parsern
PDF Parsing teilt konzeptionelle Grundlagen mit Web-Scraping, verfügt jedoch nicht über die strukturierte Hierarchie von HTML. Während Webdokumente durch zugängliche HTML-Tags geparsed werden, präsentieren PDFs ein flaches Array von Zeichen und Pixeln, was ausgefeiltere Algorithmen und Bibliotheken für die Datenextraktion erfordert.
PDF-Parser vs. Python PDF-Parser: Wichtige Unterschiede
Ein PDF-Parser ist oft ein eigenständiges Tool oder eine Bibliothek, die speziell für die Extraktion von Daten aus PDF-Dateien entwickelt wurde. Diese Parser bieten typischerweise benutzerfreundliche Oberflächen und erfordern nur minimale Programmierkenntnisse. Auf der anderen Seite sind Python-PDF-Parser Module oder Bibliotheken, die in Python-Skripte integriert werden und mehr Flexibilität bieten, jedoch Programmierkenntnisse erfordern.
Entwickler können den Parsing-Prozess optimieren, fortschrittliche Textanalysen implementieren und die PDF-Datenextraktion nahtlos in umfassendere Python-Anwendungen integrieren. PDF-Parser bieten, obwohl sie in der Anpassung begrenzter sind als Python-PDF-Parser, oft vorgefertigte Funktionen für gängige Anwendungsfälle, was sie ideal für Benutzer macht, die schnelle Ergebnisse ohne umfangreiche Programmierung benötigen.
Vorteile von AnyParser mit VLM für die Datenextraktion
-
Hohe Präzision: Die VLMs von AnyParser stellen sicher, dass die Datenextraktion auch bei komplexen Dokumentenlayouts eine hohe Genauigkeit beibehält.
-
Geschwindigkeit: Es führt in der Konversionsgeschwindigkeit und steigert die Produktivität, indem die benötigte Zeit zur Verarbeitung von Dokumenten reduziert wird.
-
Benutzerfreundlichkeit: AnyParser bietet eine einfache Oberfläche, die es Benutzern aller Erfahrungsstufen zugänglich macht.
-
Vielseitigkeit: Über PDFs hinaus dient AnyParser als leistungsstarker Bild-zu-Excel-Konverter und unterstützt verschiedene Dokumenttypen.
Fazit
PDF Parsing ist mehr als nur ein technischer Prozess; es ist ein Tor zur Transformation, wie Unternehmen Daten verwalten. Trotz der Herausforderungen hat die Entwicklung von Softwarelösungen es zugänglicher denn je gemacht. Egal, ob Sie mit der Verarbeitung von Rechnungen oder komplexen Datenanalysen zu tun haben, die Wahl des richtigen PDF-Parsers ist entscheidend. Es geht darum, das Tool zu finden, das das perfekte Gleichgewicht zwischen Genauigkeit, Sicherheit und Effizienz bietet, um Ihre datengestützten Initiativen zu unterstützen.
Starten Sie Ihre kostenlose Testversion noch heute
Bereit, Ihre Dokumentenverarbeitung zu revolutionieren? Probieren Sie AnyParser KOSTENLOS aus, ohne Kreditkarte erforderlich, unter https://www.cambioml.com/sandbox. Die kostenlose Testversion ermöglicht es Ihnen, bis zu 10 Seiten pro Dokument mit einer maximalen Dateigröße von 10 MB zu verarbeiten. Erleben Sie aus erster Hand, wie der PDF-Parser von AnyParser Ihren Umgang mit unstrukturierten Daten und Dokumentenextraktion transformieren kann. Verpassen Sie nicht diese Gelegenheit, Ihre Datenanalysefähigkeiten zu verbessern und Ihren Workflow mit modernster KI-Technologie zu optimieren.