 Evaluierungsmetriken von Ragas
Evaluierungsmetriken von Ragas
In der heutigen datengestützten Landschaft sind Branchen wie die Finanzdienstleistungen stark auf präzise und effiziente Informationsbeschaffung aus Dokumenten angewiesen, insbesondere aus solchen, die sowohl unstrukturierte Texte als auch strukturierte Daten wie Tabellen und Diagramme enthalten. Traditionelle Optical Character Recognition (OCR)-Modelle, trotz ihrer weit verbreiteten Nutzung, stoßen oft an ihre Grenzen, wenn es darum geht, komplexe Dokumentenformate zu verarbeiten, was zu suboptimalen Leistungen in fortgeschrittenen KI-Anwendungen führt. Um diese Lücke zu schließen, haben CambioML und Epsilla ein hochmodernes Wissensabfragesystem eingeführt, das verspricht, die Genauigkeit und den Rückruf bei Datenextraktionsaufgaben erheblich zu verbessern.
Einführung: Überwindung der OCR-Einschränkungen
OCR-basierte Modelle sind zwar effektiv beim Erkennen von Text, haben jedoch Schwierigkeiten, Layoutinformationen zu extrahieren und Daten aus Tabellen und Diagrammen genau zu ziehen. Diese Einschränkungen werden besonders in Branchen offensichtlich, in denen Präzision von größter Bedeutung ist, wie im Finanz- und Gesundheitswesen. Um diese Herausforderungen anzugehen, haben CambioML und Epsilla einen neuartigen Ansatz entwickelt, der modernste Tabellenauszugmodelle mit Retrieval-Augmented Generation (RAG)-Techniken integriert. Dieses neue System erreicht eine bis zu 2-fache Präzision und eine 2,5-fache Rückrufrate im Vergleich zu herkömmlichen RAG-Systemen und setzt damit einen neuen Standard für die Beantwortung von Dokumentenfragen.
AnyParser: Revolutionierung des Tabellenauszugs
Im Mittelpunkt dieses Durchbruchs steht AnyParser, ein Modell, das von fortschrittlichen Vision Language Models (VLMs) angetrieben wird und sich hervorragend eignet, um Informationen aus verschiedenen Datenquellen zu extrahieren. Im Gegensatz zu traditionellen Modellen, die stark auf OCR angewiesen sind, verwendet AnyParser eine Kombination aus visuellen und textbasierten Encodern, um selbst die kleinsten Details aus Dokumenten zu erfassen und sicherzustellen, dass keine kritischen Daten übersehen werden. Dieser Ansatz ist besonders vorteilhaft beim Auszug hochauflösender Daten aus finanziellen und medizinischen Dokumenten, wo Genauigkeit entscheidend ist.
Epsilla: Eine flexible RAG-Plattform
Epsilla ergänzt AnyParser als eine No-Code RAG-as-a-Service-Plattform, die darauf ausgelegt ist, verschiedene RAG-Pipelines zu optimieren. Epsilla verbessert den Wissensabfrageprozess durch fortschrittliche Chunking-, Indexierungs- und Abfrageverfeinerungstechniken. Durch die Integration von schlüsselwortbasierten und semantischen Suchmethoden liefert Epsilla hochgenaue und kontextuell relevante Ergebnisse, was es zu einer idealen Lösung für Anwendungen mit großen Sprachmodellen (LLM) macht.
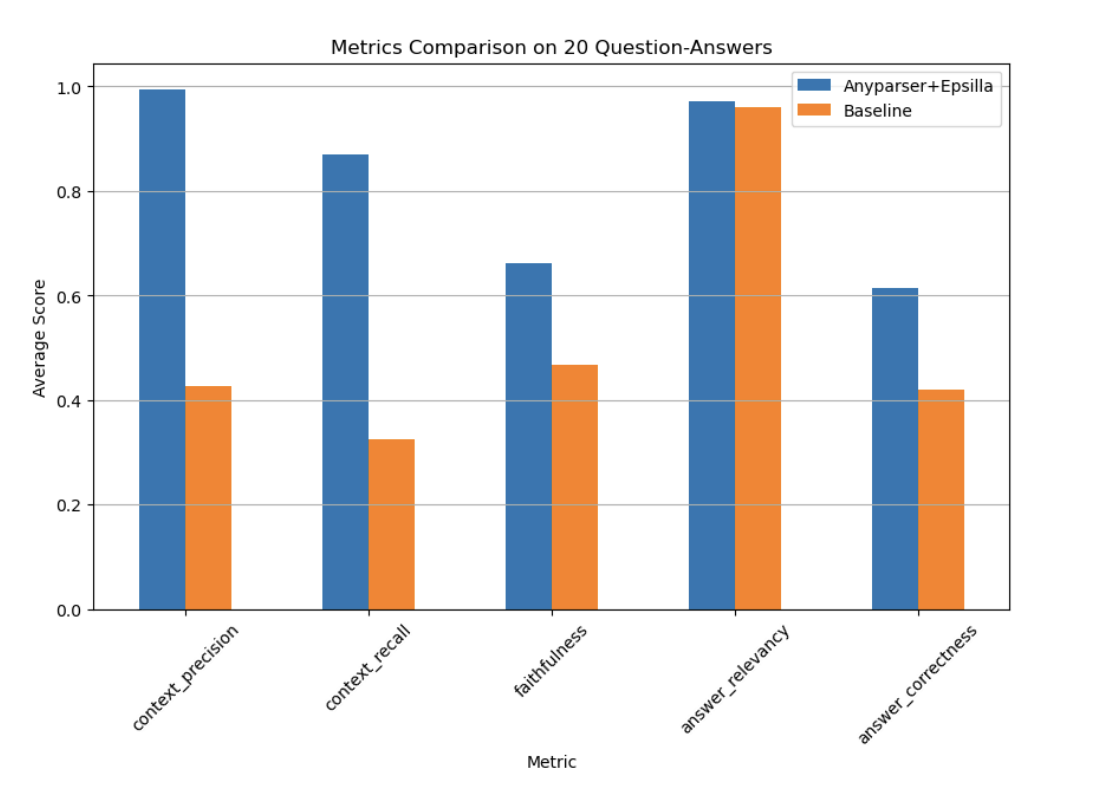
Experiment & Bewertung: Auswirkungen in der realen Welt
Evaluierungsmetriken von Ragas
Um die Effektivität von AnyParser und Epsilla zu validieren, wurde das System an 10-K finanziellen Dokumenten von Unternehmen wie Apple und Meta getestet. Die Ergebnisse waren beeindruckend, da das System eine signifikant höhere Leistung in allen wichtigen Bewertungsmetriken zeigte, einschließlich Kontextgenauigkeit, Rückruf, Treue und Antwortkorrektheit. In einigen Fällen übertraf das System herkömmliche RAG-Systeme um bis zu 2,7-fach und hob damit seine Überlegenheit bei der Verarbeitung komplexer Datenextraktionsaufgaben hervor.
Häufige Anwendungsfälle und wichtige Vorteile
-
Genauigkeit: Hohe Präzision bei der Umwandlung sowohl strukturierter als auch unstrukturierter Daten in verwendbare Formate.
-
Datenschutz: Die Möglichkeit, das System im Rechenzentrum eines Kunden bereitzustellen, gewährleistet vollständige Datensicherheit.
-
Skalierbarkeit: Schnelle Verarbeitung großer Dokumentenmengen, die schnellere Entscheidungsfindung ermöglicht.
Fazit: Eine neue Ära in der Wissensabfrage
Die Einführung von AnyParser und Epsilla stellt einen bedeutenden Fortschritt in der Technologie der Wissensabfrage dar. Durch die Kombination fortschrittlicher Extraktionsmodelle mit einer robusten RAG-Infrastruktur verbessert diese integrierte Lösung nicht nur Genauigkeit und Effizienz, sondern bietet auch die Flexibilität und den Datenschutz, die moderne Unternehmen verlangen. Während sich die Technologie weiterentwickelt, sind die Anwendungen und Vorteile dieses Systems vielfältig und vielversprechend, was es zu einem Game-Changer für Branchen macht, die auf präzise Datenextraktion angewiesen sind.
Für das vollständige detaillierte Whitepaper besuchen Sie bitte diesen Link.