Vision Language Models (VLMs) revolutionieren das Feld der Dokumentenanalyse und adressieren viele der Einschränkungen, die traditionellen Systemen zur optischen Zeichenerkennung (OCR) innewohnen. Während OCR eine grundlegende Technologie zur Digitalisierung von Text aus Bildern war, steht es vor erheblichen Herausforderungen in komplexen Szenarien. Dazu gehören Genauigkeitsprobleme bei qualitativ minderwertigen Bildern, begrenztes Kontextverständnis, Schwierigkeiten mit gemischten Sprachen und die Unfähigkeit, visuelle Elemente zu interpretieren. VLMs bieten eine vielversprechende Lösung, indem sie fortschrittliche Computer Vision mit Fähigkeiten der natürlichen Sprachverarbeitung kombinieren. Dieser Artikel untersucht, wie VLMs die Schwächen von OCR überwinden und robustere sowie vielseitigere Lösungen für die Dokumentenverarbeitung im digitalen Zeitalter bieten.
Was ist OCR? Was sind die Prozesse von OCR bei der Dokumentenparsing?
Die optische Zeichenerkennung (OCR) ist eine Technologie, die die Umwandlung verschiedener Dokumenttypen, wie gescannte Papierdokumente, PDF-Dateien oder Bilder, die mit einer Digitalkamera aufgenommen wurden, in bearbeitbare und durchsuchbare Daten ermöglicht. Dieser Prozess ist entscheidend für die Dokumentenverarbeitung und die PDF-Datenextraktion, da er Maschinen ermöglicht, gedruckte oder handgeschriebene Textzeichen in digitalen Bildern zu erkennen.
Der OCR-Prozess
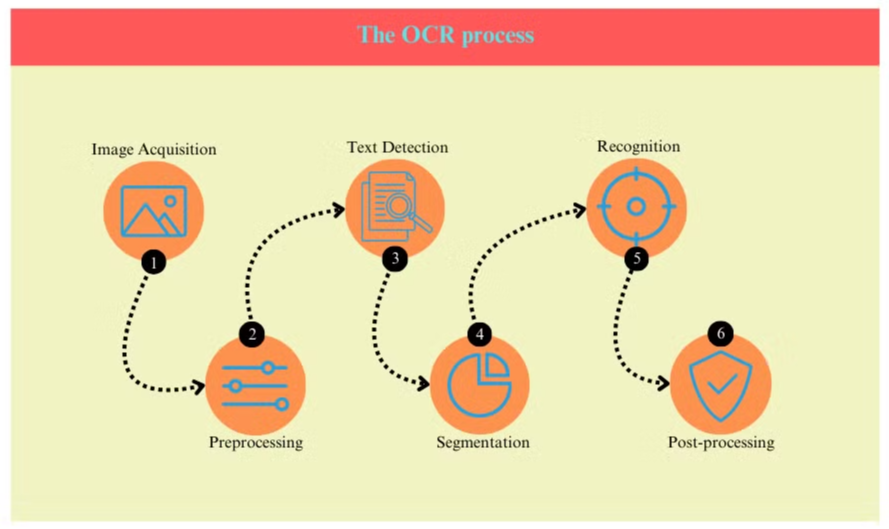
Der OCR-Prozess umfasst typischerweise mehrere Schritte:
- Bildakquisition: Das Dokument wird gescannt oder fotografiert, um ein digitales Bild zu erstellen.
- Vorverarbeitung: Das Bild wird bereinigt, indem Rauschen entfernt und Helligkeit sowie Kontrast angepasst werden.
- Texterkennung: Das System identifiziert Bereiche, die Text im Bild enthalten.
- Zeichensegmentierung: Einzelne Zeichen werden innerhalb der Textbereiche isoliert.
- Zeichenerkennung: Jedes Zeichen wird analysiert und mit einer Datenbank bekannter Zeichen verglichen.
- Nachbearbeitung: Der erkannte Text wird auf Fehler überprüft, wobei linguistische und kontextuelle Informationen verwendet werden.
Obwohl OCR die Fähigkeiten zur Dokumentenparsing erheblich verbessert hat, steht es weiterhin vor Einschränkungen bei der Verarbeitung komplexer Layouts, qualitativ minderwertiger Bilder und unterschiedlicher Schriftarten. Hier kommen fortschrittliche Technologien wie Vision Language Models ins Spiel, um die Genauigkeit und das Verständnis bei der Datenextraktion aus Bildern und Dokumenten zu verbessern.
Die Einschränkungen traditioneller OCR-Technologie
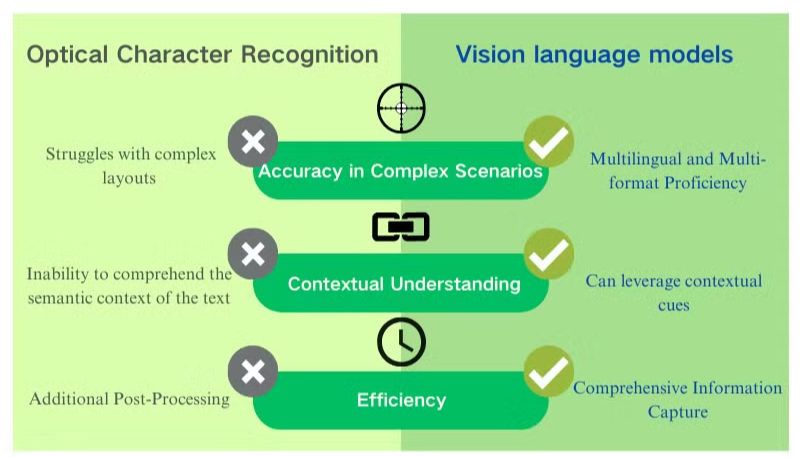
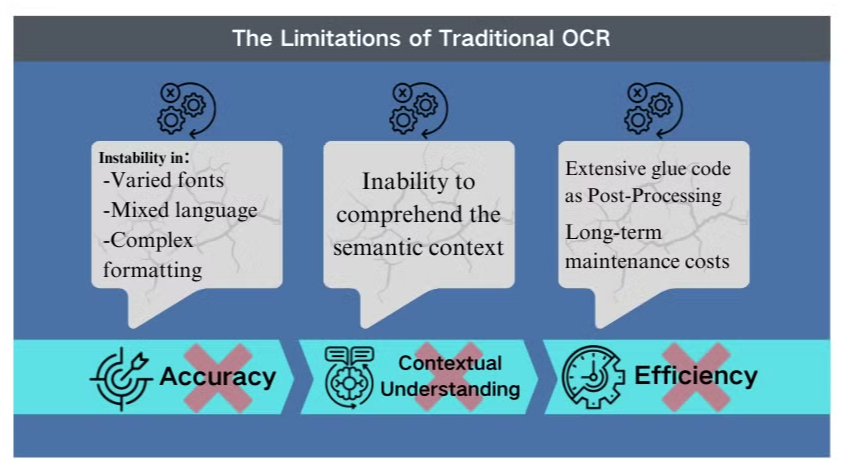
Genauigkeitsherausforderungen in komplexen Szenarien
Die traditionelle optische Zeichenerkennung (OCR) ist zwar vorteilhaft für die grundlegende Textextraktion, steht jedoch vor erheblichen Hürden, wenn sie mit komplexen Dokumentenlayouts oder qualitativ minderwertigen Bildern konfrontiert wird. Diese Systeme haben oft Schwierigkeiten, die Genauigkeit bei der Verarbeitung von Dokumenten mit unterschiedlichen Schriftarten, gemischten Sprachen oder komplexen Formaten aufrechtzuerhalten. Beispielsweise kann OCR versagen, wenn es versucht, Daten aus bildlastigen Präsentationen oder dicht formatierten PDFs zu extrahieren.
Mangel an kontextuellem Verständnis
Eine der auffälligsten Einschränkungen der herkömmlichen OCR ist ihre Unfähigkeit, den semantischen Kontext des Textes, den sie verarbeitet, zu verstehen. Diese Schwäche wird besonders in Szenarien offensichtlich, die eine nuancierte Interpretation erfordern, wie z. B. rechtliche Verträge oder medizinische Berichte. Der Fokus von OCR auf die Zeichenerkennung ohne kontextuelles Bewusstsein kann zu kritischen Fehlinterpretationen führen, insbesondere bei mehrdeutigen Zeichen oder branchenspezifischer Terminologie.
Ineffizienzen in der Nachbearbeitung
Die Einschränkungen von OCR erfordern oft umfangreiche Nachbearbeitungsaufwände. Dieser zusätzliche Schritt kann die Zeit und die Ressourcen, die für die Dokumentenverarbeitung benötigt werden, erheblich erhöhen. Darüber hinaus sind traditionelle OCR-Systeme typischerweise unzureichend, wenn es darum geht, Informationen aus Diagrammen, Tabellen oder anderen nicht-textlichen Elementen zu extrahieren, was den Dokumentenextraktionsprozess weiter kompliziert. Diese Ineffizienzen unterstreichen die Notwendigkeit fortschrittlicherer Lösungen wie Vision Language Models, die einen umfassenderen Ansatz zur Dokumentenanalyse und Datenextraktion bieten.
Was sind Vision-Language-Modelle und wie verbessern sie OCR?
Vision Language Models stellen einen bedeutenden Fortschritt in der Dokumentenverarbeitungstechnologie dar und adressieren viele der Einschränkungen, die traditionellen Systemen zur optischen Zeichenerkennung (OCR) innewohnen. Diese fortschrittlichen Modelle kombinieren Computer Vision mit natürlicher Sprachverarbeitung, um sowohl die visuellen als auch die textlichen Elemente von Dokumenten gleichzeitig zu verstehen.
Verbesserte Genauigkeit und Kontextverständnis
Im Gegensatz zu OCR, das bei qualitativ minderwertigen Bildern und komplexen Layouts Schwierigkeiten hat, zeichnen sich Vision Language Models durch ihre Fähigkeit aus, verschiedene Dokumentformate zu interpretieren. Sie können Daten aus Bildern, PDFs und anderen visuellen Inhalten genau extrahieren, selbst wenn sie mit herausfordernden Szenarien konfrontiert sind. Diese verbesserte Genauigkeit resultiert aus ihrer Fähigkeit, den gesamten Kontext eines Dokuments zu berücksichtigen, anstatt sich ausschließlich auf einzelne Zeichen oder Wörter zu konzentrieren.
Umfassende Datenextraktion
Vision Language Models gehen über die einfache Texterkennung hinaus und bieten umfassende Fähigkeiten zur PDF-Datenextraktion. Sie können Tabellen, Diagramme und Abbildungen innerhalb von Dokumenten identifizieren und interpretieren und dabei die Integrität komplexer Layouts bewahren. Dieser ganzheitliche Ansatz zur Dokumentenanalyse ermöglicht eine nuanciertere und vollständigere Informationsbeschaffung, was die Nützlichkeit der extrahierten Daten für nachgelagerte Anwendungen erheblich verbessert.
Mehrsprachige und Multi-Format-Kompetenz
Ein wesentlicher Vorteil von Vision Language Models ist ihre Flexibilität im Umgang mit mehreren Sprachen und Dokumentformaten. Im Gegensatz zu OCR-Systemen, die möglicherweise Schwierigkeiten mit nicht-lateinischen Schriften oder gemischten Sprachdokumenten haben, können diese Modelle Inhalte nahtlos in verschiedenen Sprachen und Schriften verarbeiten, was sie für globale Dokumentenverarbeitungsbedürfnisse unverzichtbar macht.
Wichtige Vorteile von Vision-Language-Modellen für das Dokumentenverständnis
Vision Language Models bieten erhebliche Vorteile gegenüber traditioneller OCR bei der Dokumentenverarbeitung und Datenextraktion. Diese KI-gestützten Systeme kombinieren visuelles und textuelles Verständnis, um überlegene Ergebnisse bei verschiedenen Dokumenttypen zu liefern.
Verbesserte Genauigkeit und kontextuelles Verständnis
Vision Language Models sind hervorragend in der Lage, komplexe Layouts, qualitativ minderwertige Bilder und unterschiedliche Schriftarten zu verarbeiten. Im Gegensatz zu OCR, das Schwierigkeiten mit mehrdeutigen Zeichen hat, nutzen diese Modelle kontextuelle Hinweise, um Text genau zu interpretieren. Diese Fähigkeit verbessert die Genauigkeit der PDF-Datenextraktion erheblich, insbesondere bei Dokumenten mit komplexen Strukturen oder schlechter Bildqualität.
Umfassende Informationsbeschaffung
Während sich OCR ausschließlich auf die Texterkennung konzentriert, können Vision Language Models Daten aus Bildern, Tabellen und Diagrammen extrahieren. Dieser ganzheitliche Ansatz stellt sicher, dass kritische Informationen während der Dokumentenverarbeitungsphase nicht übersehen werden. Durch die Erfassung sowohl textlicher als auch visueller Elemente bieten diese Modelle ein vollständigeres Verständnis des Inhalts von Dokumenten.
Mehrsprachige und Multi-Format-Kompetenz
Vision Language Models zeigen bemerkenswerte Flexibilität bei der Verarbeitung von Dokumenten in verschiedenen Sprachen und Formaten. Sie können gemischte Sprachdokumente und nicht-lateinische Schriften nahtlos verarbeiten und überwinden damit eine erhebliche Einschränkung traditioneller OCR-Systeme. Diese Vielseitigkeit macht sie für globale Unternehmen, die mit unterschiedlichen Dokumenttypen und Sprachen umgehen, unverzichtbar.
Anwendungsfälle in der Praxis, die durch VLM ermöglicht werden, wo OCR versagt hat
Vision Language Models revolutionieren die Dokumentenverarbeitung in den Bereichen Finanzen, Personalwesen und anderen Sektoren, indem sie kritische Einschränkungen traditioneller OCR-Systeme angehen. Diese fortschrittlichen KI-Modelle transformieren die digitalen Transformationsbemühungen in verschiedenen Branchen, indem sie überlegene Genauigkeit und kontextuelles Verständnis bieten.
Revolutionierung der Dokumentenverarbeitung im Finanzwesen
Vision Language Models transformieren die Dokumentenverarbeitung im Finanzwesen und überwinden die Einschränkungen traditioneller OCR. Diese fortschrittlichen Modelle sind hervorragend darin, Daten aus komplexen Finanzberichten, Rechnungen und Quittungen mit komplizierten Layouts zu extrahieren. Im Gegensatz zu OCR können sie den Kontext verstehen und mehrdeutige Zeichen (z. B. zwischen einer Null und dem Buchstaben O unterscheiden) sowie gemischte Sprachen, die häufig in globalen Finanzdokumenten vorkommen, genau interpretieren.
Verbesserung der HR-Operationen durch intelligente Dokumentenanalyse
Im Personalwesen erweisen sich Vision Language Models als unschätzbar für die PDF-Datenextraktion aus Lebensläufen, Mitarbeiterakten und Leistungsbewertungen. Diese Modelle können die semantische Struktur von Dokumenten verstehen, was eine genauere Informationsbeschaffung und -analyse ermöglicht. Diese Fähigkeit rationalisiert die Einstellungsprozesse und das Management von Mitarbeiterdaten erheblich, Aufgaben, bei denen OCR oft mit unterschiedlichen Formaten und handschriftlichen Notizen kämpft.
Verbesserung von Compliance und Risikomanagement
Vision Language Models sind besonders effektiv im Bereich Compliance und Risikomanagement sowohl im Finanzwesen als auch im Personalwesen. Sie können kritische Informationen aus regulatorischen Dokumenten, Verträgen und Richtlinien mit größerer Genauigkeit extrahieren und interpretieren als OCR. Diese verbesserte Dokumentenverarbeitungsfähigkeit gewährleistet eine bessere Einhaltung rechtlicher Anforderungen und effizientere Risikobewertungsverfahren.
Fazit
Zusammenfassend stellen Vision Language Models einen bedeutenden Fortschritt in der Dokumentenverarbeitungstechnologie dar und adressieren viele der inhärenten Einschränkungen traditioneller OCR-Systeme. Durch die Kombination von visuellem und textlichem Verständnis bieten diese fortschrittlichen Modelle überlegene Leistungen in einer Vielzahl herausfordernder Szenarien, von komplexen Layouts über gemischte Sprachen bis hin zu qualitativ minderwertigen Bildern. Während Organisationen weiterhin ihre Abläufe digitalisieren und nach effizienteren Möglichkeiten suchen, um Wert aus ihren Dokumentenarchiven zu extrahieren, erweisen sich Vision Language Models als leistungsstarkes Werkzeug für Entwickler und Führungskräfte im Ingenieurwesen. Ihre Fähigkeit, Kontext zu verstehen, mit unterschiedlichen Formaten umzugehen und genauere Ergebnisse zu liefern, positioniert sie als entscheidenden Enabler für anspruchsvolle RAG-Pipelines und unternehmensweite Suchfähigkeiten, was letztendlich die digitalen Transformationsinitiativen auf neue Höhen treibt.