Haben Sie sich jemals gefragt, wofür OCR steht? Die optische Zeichenerkennung (OCR) ist eine leistungsstarke Technologie, die Bilder von Text in maschinenlesbare Daten umwandelt. Während OCR enorme Vorteile bei der Digitalisierung von Dokumenten und der Informationsgewinnung bietet, ist sie nicht ohne ihre Nachteile. Wenn Sie diese Technologie erkunden, ist es entscheidend, sowohl ihre Fähigkeiten als auch ihre Einschränkungen zu verstehen. In diesem Artikel erfahren Sie die Bedeutung von OCR und tauchen in ihre potenziellen Nachteile ein. Durch ein umfassendes Verständnis der optischen Zeichenerkennung sind Sie besser gerüstet, um zu entscheiden, ob und wie Sie diese Technologie in Ihren eigenen Arbeitsabläufen und Projekten implementieren können.
Was bedeutet OCR und was ist ein OCR?
Was bedeutet OCR?
OCR steht für optische Zeichenerkennung, eine Technologie, die es Computern ermöglicht, verschiedene Arten von Dokumenten zu erkennen und zu konvertieren. Im Kern ist OCR der Prozess, gedruckten oder handgeschriebenen Text zu scannen und in maschinenkodierten Text umzuwandeln. Dies ermöglicht es, den Text einfach durchsuchbar, editierbar und übertragbar zu machen. Zu verstehen, was OCR bedeutet, ist für jeden, der mit Dokumentenscanning und Texterkennungstechnologien arbeitet, unerlässlich.
Was ist ein OCR?
Für diejenigen, die mit dem Begriff nicht vertraut sind, ist "was ist ein OCR" eine häufige Frage, die sich auf die optische Zeichenerkennung bezieht, eine Technologie, die es Computern ermöglicht, Text aus Bildern oder gescannten Dokumenten zu lesen.
OCR wandelt gedruckten oder handgeschriebenen Text in maschinenlesbare Daten um und überbrückt die Kluft zwischen Papier- und digitalen Formaten. Diese Technologie verwendet ausgeklügelte Algorithmen, um Buchstabenformen, Wortstrukturen und sogar ganze Sätze zu erkennen. Dadurch werden statische Bilder in editierbare und durchsuchbare Textdateien umgewandelt.
Die OCR-Technologie basiert im Wesentlichen auf Computer Vision und Mustererkennungstechnologien. OCR steht für das Scannen von Dokumenten oder Bildern, die Text enthalten, und die Verwendung fortschrittlicher Algorithmen zur Identifizierung und Umwandlung des Textes in ein digitales, editierbares Format. Ein entscheidender Moment in der Geschichte der OCR-Technologie war 1974, als Ray Kurzweil ein Omni-Font-OCR-System entwickelte, das Text in nahezu jeder Schriftart erkennen konnte. Im Laufe der Jahre hat sich OCR von einfachen Vorlagenabgleich zu ausgefeilteren Systemen weiterentwickelt.
Trotz ihrer Fähigkeiten sieht sich die OCR-Technologie derzeit bestimmten Einschränkungen gegenüber. Dazu gehören Herausforderungen bei der Erkennung von Text in Bildern mit schlechter Qualität, Schwierigkeiten bei der Handhabung komplexer Layouts oder Hintergründe und unterschiedliche Genauigkeit bei der Verarbeitung verschiedener Schriftarten, Sprachen oder Handschriften. Darüber hinaus können OCR-Systeme Schwierigkeiten mit Dokumenten haben, die farbige Hintergründe, Unschärfen oder Verzerrungen aufweisen, sowie mit geschwungener Handschrift.
Verständnis von Software zur optischen Zeichenerkennung
Software zur optischen Zeichenerkennung ist eine transformative Technologie, die verschiedene Arten von Dokumenten in editierbare und durchsuchbare Daten umwandelt. Sie spielt eine entscheidende Rolle bei der Digitalisierung unserer Welt und macht Informationen zugänglicher und verwaltbarer. OCR-Software verwendet einen ausgeklügelten Prozess, um Bilder von Text in maschinenlesbare Daten umzuwandeln.
Wie OCR-Software funktioniert
1. Bildaufnahme
Der Weg der OCR beginnt mit der Aufnahme eines Bildes des Dokuments. Dies kann durch einen Scanner oder eine Digitalkamera erfolgen. Das Bild wird dann in ein digitales Format übersetzt, das ein Computer verarbeiten kann.
2. Vorverarbeitung und Bildverbesserung
Der zweite Schritt besteht darin, die Bildqualität zu verbessern. Nachdem das Bild erfasst wurde, wird es einer Vorverarbeitung unterzogen, um die Qualität für eine bessere Erkennung zu optimieren. Dieser Schritt kann das Anpassen von Kontrast, Helligkeit und Schärfe des Bildes sowie das Entfernen von Rauschen oder irrelevanten Elementen umfassen. Diese Vorverarbeitungsphase ist entscheidend für die Erzielung genauer Ergebnisse, insbesondere bei der Verarbeitung von qualitativ minderwertigen Scans oder Fotografien.
3. Texterkennung
Die OCR-Software analysiert das vorverarbeitete Bild, um Bereiche zu erkennen, die Text enthalten. Dies geschieht durch die Suche nach Mustern und Formen, die charakteristisch für Text sind, wie Linien unterschiedlicher Dicke und Höhe.
4. Zeichensegmentierung
Sobald Textbereiche erkannt sind, zerlegt die Software den Text in kleinere Einheiten wie Blöcke, Zeilen, Wörter oder sogar einzelne Zeichen. Die OCR-Software analysiert das Bild Pixel für Pixel, um Muster zu identifizieren, die Zeichen bilden. Sie zerlegt das Bild in kleinere Segmente und isoliert jedes Zeichen.
5. Texterkennung und -extraktion
Die Software vergleicht dann diese isolierten Formen mit einer umfangreichen Datenbank bekannter Zeichenmuster, um zu bestimmen, was jedes Zeichen ist. Die Software extrahiert Merkmale aus den Zeichen, wie die Anzahl der Linien, Kurven oder Winkel. Diese Merkmale helfen der OCR, zwischen verschiedenen Zeichen zu erkennen und zu unterscheiden.
6. Nachbearbeitung
Nachdem die Zeichen identifiziert wurden, durchläuft das OCR-System eine Nachbearbeitungsphase, in der es potenzielle Fehler korrigiert und den Text für die Ausgabe formatiert. Der korrigierte Text wird dann in das gewünschte Format exportiert, wie ein Word-Dokument oder ein durchsuchbares PDF.
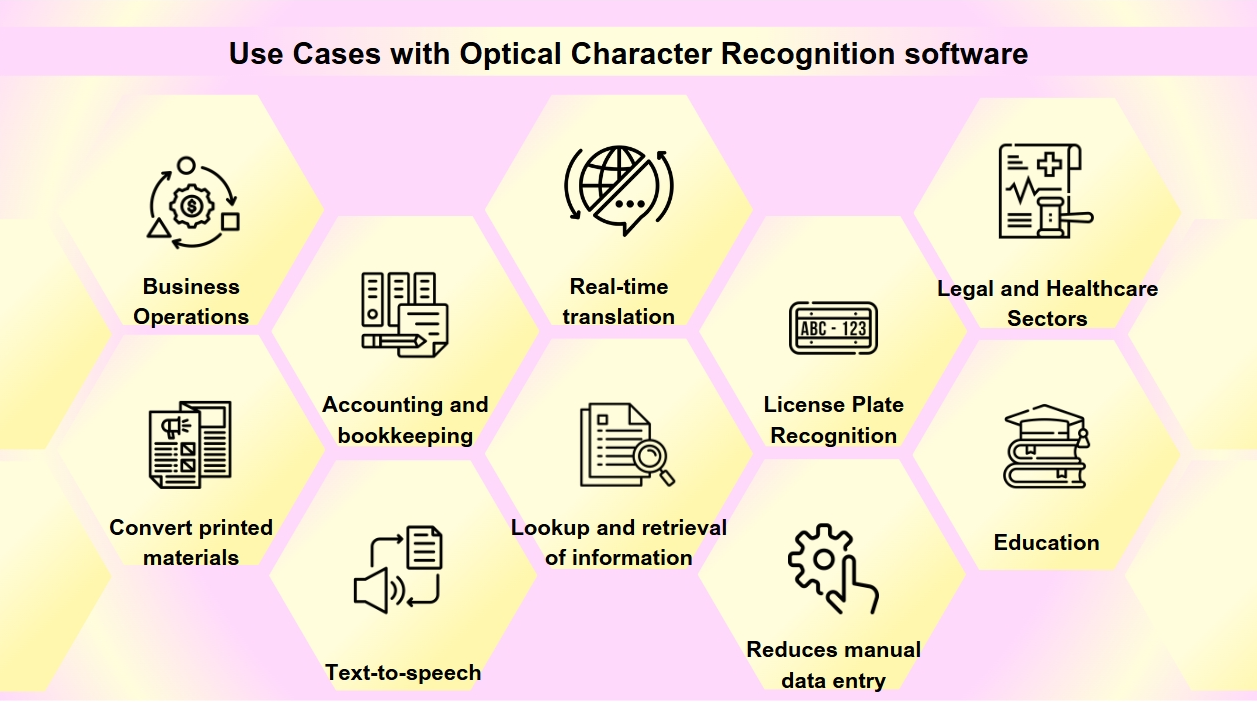
Anwendungsfälle mit Software zur optischen Zeichenerkennung
OCR ist zu einem wesentlichen Werkzeug in der digitalen Transformation vieler Branchen geworden, das Prozesse rationalisiert und die Datenzugänglichkeit und -genauigkeit verbessert. Sie könnten OCR häufiger begegnen, als Sie denken. Vom Scannen von Visitenkarten bis zur Digitalisierung alter Bücher spielt OCR eine entscheidende Rolle in verschiedenen Branchen. Die OCR-Technologie hat eine Vielzahl von Anwendungen:
-
Dokumentendigitalisierung: OCR wird verwendet, um gedruckte Materialien wie alte Bücher, Zeitungen und historische Dokumente in digitale Formate umzuwandeln, die durchsuchbar sind und für zukünftige Generationen erhalten bleiben.
-
Formularverarbeitung: Unternehmen nutzen OCR, um automatisch Daten aus Formularen zu extrahieren, was die manuelle Dateneingabe reduziert und die Effizienz in verschiedenen Sektoren wie Finanzen und Gesundheitswesen erhöht.
-
Rechnungsverarbeitung: OCR-Technologie kann Text auf Rechnungen lesen und die Daten automatisch in Finanzsysteme eingeben, wodurch Buchhaltungs- und Buchführungsprozesse rationalisiert werden.
-
Barrierefreiheit: OCR ermöglicht die Text-zu-Sprache-Funktionalität und erstellt Audio-Versionen von Texten für sehbehinderte Personen, wodurch gedruckte Materialien zugänglicher werden.
-
Mobile Anwendungen: OCR ist in Apps integriert, um Aufgaben wie das Scannen von Visitenkarten, das Erkennen von Text in Fotos und die Unterstützung von Echtzeitübersetzungen zu ermöglichen.
-
Durchsuchbarkeit: OCR verbessert die Durchsuchbarkeit gescannter Dokumente, indem es Text aus Bildern oder PDFs extrahiert, was eine einfache Suche und Abruf von Informationen ermöglicht.
-
Kennzeichenerkennung: OCR wird für Park- und Verkehrsmanagement verwendet und kann Kennzeichen erkennen, wodurch eine effiziente Überwachung und Durchsetzung ermöglicht wird.
-
Geschäftsabläufe: OCR rationalisiert Geschäftsprozesse, indem es die Dateneingabe aus Dokumenten wie Rechnungen, Quittungen und Bestellungen automatisiert und die Rekrutierung beschleunigt, indem es Bewerbungen und Lebensläufe scannt und verarbeitet.
-
Rechts- und Gesundheitssektoren: Anwaltskanzleien nutzen OCR, um Fallakten und juristische Dokumente zu digitalisieren, um die Informationsbeschaffung zu erleichtern, während Gesundheitsdienstleister sie verwenden, um Patientenakten und medizinische Formulare in elektronische Gesundheitsakten (EHRs) umzuwandeln, was das Datenmanagement und die Patientenversorgung verbessert.
-
Bildung: In Bildungseinrichtungen wird OCR verwendet, um digitale Lehrbücher und Lernmaterialien zu erstellen, die die Zugänglichkeit für Schüler mit unterschiedlichen Bedürfnissen verbessern und ein integratives Lernumfeld unterstützen.
Mit dem Fortschritt der OCR-Technologie spielt sie weiterhin eine entscheidende Rolle dabei, Informationen im digitalen Zeitalter zugänglicher und effizienter zu handhaben.
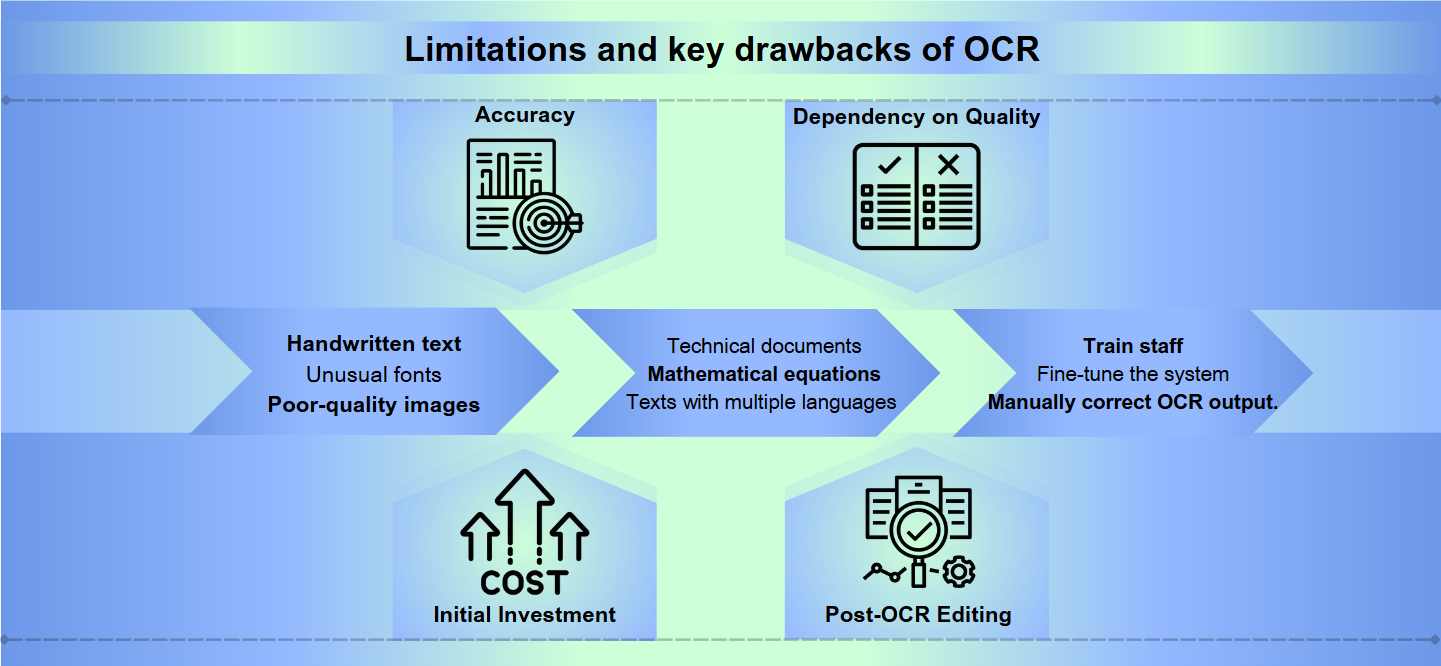
Die Nachteile von OCR: Einschränkungen und Nachteile
Genauigkeitsherausforderungen
Obwohl die Technologie der optischen Zeichenerkennung (OCR) große Fortschritte gemacht hat, steht sie immer noch vor erheblichen Hürden, um perfekte Genauigkeit zu erreichen. Handschriftlicher Text, ungewöhnliche Schriftarten oder Bilder von schlechter Qualität können zu Fehlinterpretationen und Fehlern führen. Selbst geringfügige Variationen in der Form oder Größe von Zeichen können OCR-Systeme verwirren, was zu unleserlichen Ausgaben führt, die manuell korrigiert werden müssen.
Sprach- und Formatbeschränkungen
Die meisten OCR-Lösungen sind bei Standardsprachen und -formaten hervorragend, haben jedoch Schwierigkeiten mit spezialisierten Inhalten. Technische Dokumente, mathematische Gleichungen oder Texte in mehreren Sprachen können erhebliche Herausforderungen darstellen. Darüber hinaus kann OCR Schwierigkeiten haben, wenn sie mit komplexen Layouts, Tabellen oder Dokumenten mit komplizierter Formatierung konfrontiert wird, wodurch wichtige strukturelle Informationen verloren gehen können.
Ressourcenintensität
Die Implementierung und Wartung eines effektiven OCR-Systems kann ressourcenintensiv sein. Hochwertige OCR-Software hat oft einen hohen Preis, und die Hardware, die erforderlich ist, um große Mengen an Dokumenten zu verarbeiten, kann kostspielig sein. Darüber hinaus können die Zeit und der Aufwand, die erforderlich sind, um Mitarbeiter zu schulen, das System zu optimieren und die OCR-Ausgabe manuell zu überprüfen und zu korrigieren, die Ressourcen einer Organisation belasten.
Wichtige Nachteile von OCR
-
Genauigkeit: OCR-Software kann mit der Genauigkeit kämpfen, insbesondere bei der Verarbeitung von Bildern schlechter Qualität, komplexen Layouts oder handgeschriebenem Text. Fehler können von der falschen Lesung von Zeichen bis zum Überspringen ganzer Textabschnitte reichen.
-
Abhängigkeit von der Qualität: Die Effektivität von OCR hängt stark von der Qualität des Originaldokuments ab. Verblasste Tinte, Schmierereien oder zerknittertes Papier können zu ungenauen Übersetzungen führen.
-
Anfängliche Investition: Die Einrichtung eines OCR-Systems kann erhebliche Anfangskosten erfordern, die nicht nur die Software, sondern auch kompatible Hardware wie Scanner umfassen.
-
Nachbearbeitung nach OCR: Oft erfordert die Ausgabe von OCR-Prozessen eine manuelle Überprüfung und Korrektur, was zeitaufwendig sein kann.
Vision Language Model überwindet die Einschränkungen von OCR
Mit dem Fortschritt der Technologie entstehen innovative Lösungen, um die Mängel der traditionellen optischen Zeichenerkennung (OCR) anzugehen. Ein solcher Durchbruch ist das Vision Language Model (VLM), das Computer Vision und natürliche Sprachverarbeitung kombiniert, um die Textextraktion und -verständnis zu revolutionieren.
Verbesserte kontextuelle Verständigung
VLMs zeichnen sich durch das Verständnis des Kontexts um den Text herum aus, im Gegensatz zur isolierten Zeichenerkennung von OCR. Durch die Analyse visueller Elemente zusammen mit Text können diese Modelle komplexe Layouts, handschriftliche Notizen und sogar teilweise verdeckten Text mit bemerkenswerter Genauigkeit interpretieren.
Mehrsprachige und multimodale Fähigkeiten
Während OCR oft Schwierigkeiten mit verschiedenen Sprachen und Schriften hat, zeigen VLMs beeindruckende Vielseitigkeit. Sie können nahtlos mehrere Sprachen verarbeiten und sogar visuelle Inhalte wie Diagramme oder Grafiken interpretieren, was ein umfassenderes Verständnis von Dokumenten ermöglicht.
Anpassungsfähiges Lernen und kontinuierliche Verbesserung
Im Gegensatz zu statischen OCR-Systemen nutzen VLMs maschinelles Lernen, um sich im Laufe der Zeit anzupassen und zu verbessern. Wenn sie neuen Daten und Szenarien begegnen, verfeinern diese Modelle ihre Leistung und werden zunehmend besser darin, verschiedene Dokumenttypen und -formate zu verarbeiten.
Durch die Überwindung der Einschränkungen von OCR ebnen Vision Language Models den Weg für genauere, effizientere und intelligentere Dokumentenverarbeitung in verschiedenen Branchen.
Wählen Sie Vision Language Model: Probieren Sie AnyParser
Aufbauend auf den Fortschritten der Vision Language Models (VLM) präsentiert sich AnyParser als eine anspruchsvolle Lösung, die die Einschränkungen der traditionellen OCR-Technologie überwindet. Entwickelt vom CambioML-Team, ist AnyParser ein leistungsstarkes Dokumentenparser-Tool, das eine präzise und konfigurierbare API nutzt, um Informationen aus verschiedenen unstrukturierten Datenquellen wie PDFs, Bildern und Diagrammen zu extrahieren und sie in strukturierte Formate umzuwandeln.
Technische Grundlage und Fähigkeiten
AnyParser basiert auf der robusten Grundlage großer Sprachmodelle (LLMs) und gewährleistet eine hohe Genauigkeit bei der Extraktion von Text, Tabellen, Diagrammen und Layouts aus Dokumenten. Es zeichnet sich durch die Fähigkeit aus, das ursprüngliche Layout und Format beizubehalten, ein Merkmal, das besonders vorteilhaft für Dokumente mit komplexen Layouts oder solchen ist, die die Erhaltung der ursprünglichen Ästhetik erfordern.
Datenschutz und Sicherheit
Im Hinblick auf den Datenschutz verarbeitet AnyParser Daten lokal und schützt so sensible Informationen. Dieses Merkmal ist ein erheblicher Vorteil für Unternehmen und Einzelpersonen, die mit vertraulichen Daten umgehen.
Anpassbarkeit und Flexibilität
AnyParser bietet ein hohes Maß an Konfigurierbarkeit, sodass Benutzer benutzerdefinierte Extraktionsregeln festlegen und Ausgabeformate definieren können, die ihren spezifischen Bedürfnissen entsprechen. Diese Anpassungsfähigkeit macht es zu einem idealen Werkzeug für eine Vielzahl von Anwendungen, von KI-Engineering bis hin zu Finanzanalysen.
Fazit
Wie Sie gelernt haben, bietet die OCR-Technologie leistungsstarke Möglichkeiten zur Digitalisierung von Text, ist jedoch nicht ohne Einschränkungen. Während die optische Zeichenerkennung die Effizienz erheblich steigern kann, müssen Sie die potenziellen Nachteile sorgfältig abwägen. Berücksichtigen Sie die Genauigkeitsprobleme, Formatierungsherausforderungen und Ressourcenanforderungen, bevor Sie eine OCR-Lösung implementieren. Letztendlich hängt die Entscheidung, OCR zu nutzen, von Ihren spezifischen Bedürfnissen und Umständen ab. Durch das Verständnis sowohl der Vorteile als auch der Nachteile können Sie eine informierte Entscheidung darüber treffen, ob OCR für Ihre Organisation geeignet ist. Während sich OCR weiterentwickelt, bleiben Sie über neue Entwicklungen informiert, die aktuelle Mängel angehen und noch größere Potenziale für diese transformative Technologie freisetzen können.
Handlungsaufforderung
Nutzen Sie die Vorteile von Vision Language Models, indem Sie AnyParser kostenlos ausprobieren, um Ihre PDFs in Google Sheets zu konvertieren unter https://www.cambioml.com/sandbox. Holen Sie sich eine kostenlose Beratung, wie VLMs Ihren Datenextraktionsworkflow verbessern können.