En el mundo actual impulsado por los datos, convertir documentos complejos de formato PDF a CSV es una tarea crucial para muchos profesionales. Si estás lidiando con extractos bancarios, informes médicos o pedidos de envío en formato PDF, es probable que estés buscando una solución eficiente.
Aquí entran los Modelos de Lenguaje Visual (VLM), una tecnología de vanguardia que supera los métodos tradicionales de OCR. Al aprovechar tanto la comprensión visual como contextual, los VLM ofrecen una herramienta poderosa para transformar documentos estructurados e intrincados en formatos legibles por máquina.
Esta guía te llevará a través del proceso de aprovechar los VLM para convertir tus PDFs en archivos CSV o Excel utilizando AnyParser, optimizando tu flujo de trabajo y desbloqueando valiosos conocimientos de datos. Con AnyParser, puedes convertir fácilmente PDF a CSV, PDF a Excel, o incluso convertir Word a CSV con solo unos clics en nuestro Playground.
Las Fuertes Necesidades de Conversión de PDF a CSV y las Limitaciones de los Modelos OCR Tradicionales
La Creciente Demanda de Conversión de PDF a CSV
En el mundo actual impulsado por los datos, la necesidad de convertir PDF a CSV se ha vuelto cada vez más crucial. Empresas e individuos buscan formas eficientes de transformar documentos PDF estáticos en hojas de cálculo dinámicas y analizables. Este proceso de conversión es esencial para extraer información valiosa de varios documentos, como extractos bancarios, informes médicos y pedidos de envío. La capacidad de convertir Word a Excel o usar un convertidor PDF a CSV puede optimizar significativamente los procesos de gestión y análisis de datos.
Deficiencias de la Tecnología OCR Convencional
Si bien los modelos de Reconocimiento Óptico de Caracteres (OCR) tradicionales se han utilizado durante mucho tiempo para la extracción de texto, a menudo no son suficientes al tratar con documentos complejos. Estas limitaciones se hacen evidentes al intentar convertir PDFs intrincados a Google Sheets u otros formatos de hoja de cálculo. Los sistemas OCR tienen dificultades con:
- Interpretar con precisión escaneos o imágenes de baja calidad
- Manejar diseños y tablas de múltiples columnas
- Reconocer diversas fuentes e idiomas
- Mantener la estructura original del documento
Estos desafíos resaltan la necesidad de soluciones más avanzadas que puedan manejar sin problemas el proceso de conversión de PDF a CSV, preservando tanto el contenido como el contexto de los documentos originales.
Guía Paso a Paso para Convertir Documentos PDF Usando AnyParser
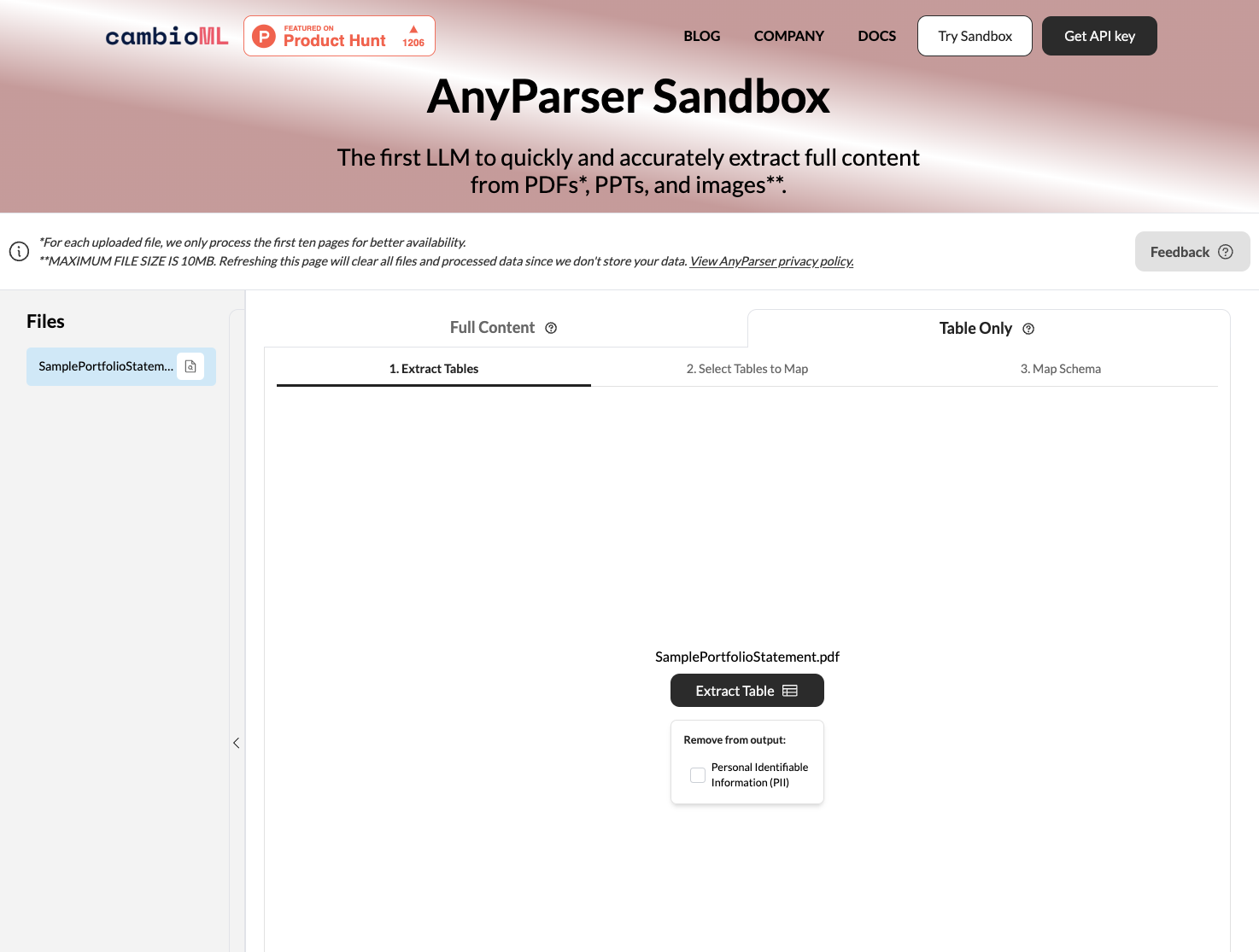
AnyParser es una poderosa herramienta de conversión de PDF a CSV que aprovecha los avanzados Modelos de Lenguaje Visual para extraer datos con precisión de documentos PDF complejos. Aquí están los pasos básicos para usar AnyParser y convertir tus archivos PDF:
-
Sube tu PDF o Word. Simplemente arrastra y suelta tus documentos PDF en la interfaz web de AnyParser o puedes pegar la captura de pantalla del PDF en la interfaz de AnyParser.
-
Selecciona "Solo Tabla" y haz clic en "Extraer". El motor API de AnyParser detectará automáticamente las tablas en el PDF y las extraerá con alta precisión. Los datos extraídos se almacenan en un archivo .csv que puedes descargar o exportar a Google Sheets con solo un clic.
-
Previsualiza y compara. Revisa los datos extraídos en la vista previa para asegurarte de que coincidan con tus expectativas. Previsualiza la extracción inicial de AnyParser y compara lado a lado en la interfaz.
-
Exporta a CSV o Excel. Una vez que estés satisfecho con la extracción, descarga el archivo .csv para usar los datos en tus propias aplicaciones y sistemas. Los datos extraídos se pueden importar fácilmente en hojas de cálculo y bases de datos para un análisis posterior.
Al seguir estos simples pasos y aprovechar el poder de los Modelos de Lenguaje Visual, AnyParser te permite convertir de manera eficiente incluso los documentos PDF más complejos en archivos CSV estructurados y editables que puedes analizar e integrar en tus flujos de trabajo.
¡Mira este video para ver una demostración paso a paso!
Aplicaciones del Mundo Real de VLM para Conversión de PDF a CSV/Excel
Los Modelos de Lenguaje Visual (VLM) están revolucionando la forma en que convertimos PDF a CSV y formatos de Excel, ofreciendo soluciones poderosas para diversas industrias. Al aprovechar estos modelos avanzados, puedes transformar de manera eficiente documentos complejos en datos estructurados y legibles por máquina.
Procesamiento de Documentos Financieros
En el sector bancario, los VLM sobresalen en la conversión de PDF a CSV para extractos bancarios. Estos modelos pueden extraer con precisión detalles de transacciones, números de cuenta e información de saldo, incluso de documentos con diseños intrincados o múltiples monedas. Esta capacidad optimiza los procesos de análisis y conciliación financiera.
Gestión de Registros Médicos
Para los profesionales de la salud, los VLM proporcionan una herramienta invaluable para convertir Word a Excel para informes médicos. Al interpretar con precisión la terminología médica compleja y preservar la estructura de los resultados de laboratorio, los VLM facilitan la creación de bases de datos completas de pacientes. Esta transformación permite un análisis de tendencias más fácil y una mejor atención al paciente.
Optimización de Logística y Cadena de Suministro
En la industria de la logística, los VLM brillan al convertir pedidos de envío de PDF a Google Sheets. Estos modelos pueden extraer información crucial como direcciones de entrega, descripciones de artículos y números de seguimiento, manteniendo la integridad de los datos tabulares. Esta conversión permite una gestión eficiente del inventario y la optimización de rutas.
Al utilizar un convertidor PDF a CSV impulsado por VLM, puedes mejorar significativamente la eficiencia del procesamiento de datos en varios sectores. Estos modelos avanzados ofrecen una precisión inigualable en el manejo de documentos multilingües, diseños complejos e incluso escaneos de baja calidad, convirtiéndolos en una herramienta indispensable para las empresas modernas.
Cómo Funcionan los Modelos de Lenguaje Visual para Superar los Desafíos de OCR
Los Modelos de Lenguaje Visual (VLM) están revolucionando la forma en que convertimos PDF a CSV y transformamos documentos complejos en formatos legibles por máquina. A diferencia del OCR tradicional, los VLM aprovechan tanto la comprensión visual como lingüística para abordar los aspectos más desafiantes de la conversión de documentos.
Interpretando Diseños Complejos
Los VLM sobresalen en descifrar estructuras documentales intrincadas, lo que los hace ideales para convertir Word a Excel o manejar extractos bancarios con formatos variados. Al analizar las relaciones espaciales entre los elementos de texto, los VLM pueden reconstruir tablas con precisión y preservar la integridad del diseño. Por ejemplo, los VLM pueden interpretar correctamente un PDF con una factura que contiene múltiples tablas con diferentes números de columnas y filas, mientras que el OCR convencional confundirá las filas y columnas.
Comprensión Contextual
Una de las principales ventajas de los VLM es su capacidad para comprender el significado semántico del contenido del documento. Esta conciencia contextual permite una extracción más precisa al usar un convertidor PDF a CSV, especialmente para documentos específicos de dominio como informes médicos CBC o pedidos de envío logísticos. Por ejemplo, los VLM pueden clasificar correctamente los informes médicos por especialidad según su contenido, incluso entender que el conteo de "leucocitos" es el conteo de "glóbulos blancos (WBCs)".
Capacidad Multilingüe
Los VLM rompen las barreras del idioma al manejar sin problemas múltiples scripts e idiomas dentro de un solo documento. Esto los hace particularmente útiles para empresas internacionales que manejan diversos tipos de documentos. Por ejemplo, los VLM pueden extraer datos de un PDF que contiene texto en inglés y francés.
Reducción de Ruido
Los escaneos o imágenes de baja calidad a menudo representan desafíos para los sistemas OCR tradicionales. Sin embargo, los VLM pueden filtrar efectivamente el ruido y centrarse en la información relevante, asegurando una salida de alta calidad al convertir documentos a Google Sheets u otros formatos. Por ejemplo, los VLM pueden extraer datos de manera precisa de un documento PDF borroso o desvanecido.
Preguntas Frecuentes sobre Convertir PDF a CSV Usando Modelos de Lenguaje Visual
¿Cómo difiere la conversión basada en VLM de la OCR tradicional?
Los Modelos de Lenguaje Visual (VLM) ofrecen ventajas significativas sobre el OCR tradicional al convertir PDF a CSV o Excel. A diferencia del OCR, los VLM pueden interpretar con precisión diseños complejos, comprender el contexto y manejar múltiples idiomas sin problemas. Esto los hace ideales para convertir extractos bancarios, informes médicos CBC y pedidos de envío logísticos en formatos legibles por máquina.
¿Qué tipos de documentos funcionan mejor con la conversión VLM?
Los VLM son excelentes para convertir documentos estructurados con tablas, gráficos y contenido mixto. Son particularmente efectivos para estados financieros, informes médicos y manifiestos de envío. El convertidor PDF a CSV impulsado por VLM puede mantener la integridad de las tablas y extraer datos incluso de escaneos de baja calidad o documentos multilingües complejos.
¿Qué tan precisa es la conversión basada en VLM en comparación con la entrada de datos manual?
Las soluciones basadas en VLM como AnyParser pueden mejorar significativamente la precisión en comparación con la entrada de datos manual o el OCR tradicional. Al aprovechar tanto la comprensión visual como contextual, estas herramientas pueden reducir los errores en la conversión de Word a Excel o PDF a Google Sheets en hasta un 50%. Esta precisión es crucial para mantener la integridad de los datos en aplicaciones financieras, médicas y logísticas.
¿Pueden los VLM manejar diferentes formatos de archivo más allá de los PDFs?
Sí, las herramientas avanzadas basadas en VLM pueden procesar varios formatos de archivo. Si bien la conversión de PDF a CSV es común, estos modelos también pueden extraer datos de imágenes, documentos de Word, presentaciones de PowerPoint y documentos escaneados. Esta versatilidad convierte a los VLM en una solución poderosa para necesidades integrales de procesamiento de documentos en diversas industrias.
Conclusión
A medida que te embarcas en aprovechar los Modelos de Lenguaje Visual para la conversión de PDF a CSV, recuerda que el éxito radica en un enfoque bien estructurado. Al implementar un preprocesamiento robusto, una clasificación de documentos precisa y un postprocesamiento exhaustivo, puedes aprovechar todo el potencial de los VLM para tus necesidades de extracción de datos. Ya sea que estés tratando con extractos bancarios complejos, informes médicos intrincados o pedidos de envío detallados, los VLM ofrecen una solución poderosa para transformar datos no estructurados en conocimientos procesables. Adopta esta tecnología de vanguardia para optimizar tus flujos de trabajo, mejorar la precisión de los datos y desbloquear nuevas posibilidades en el procesamiento de documentos. Con los VLM a tu disposición, estás bien equipado para abordar incluso las tareas de conversión de PDF más desafiantes de manera eficiente y efectiva.
Llamado a la Acción
Avancemos implementando estos conocimientos. Considera contactar a expertos en Modelos de Lenguaje Visual como el equipo de AnyParser para:
- Probar AnyParser gratis para convertir tu PDF a CSV en https://www.cambioml.com/sandbox
- Si prefieres una experiencia sin código para convertir un gran volumen de PDFs a Excel, visita https://www.energent.ai
- Obtener una consulta gratuita sobre cómo los VLM pueden mejorar tu flujo de trabajo de extracción de datos
Aprovechar todo el poder de los Modelos de Lenguaje Visual requiere aprovechar la experiencia y las mejores prácticas de los especialistas en conversión. Da el siguiente paso conectándote con líderes de la industria para acelerar tu transición hacia un proceso de extracción de datos más automatizado, preciso y perspicaz.