Los Modelos de Lenguaje Visual (VLM) están revolucionando el campo del análisis de documentos, abordando muchas de las limitaciones inherentes a los sistemas tradicionales de Reconocimiento Óptico de Caracteres (OCR). Si bien el OCR ha sido una tecnología fundamental para digitalizar texto a partir de imágenes, enfrenta desafíos significativos en escenarios complejos. Estos incluyen problemas de precisión con imágenes de baja calidad, comprensión contextual limitada, dificultades con lenguajes mixtos e incapacidad para interpretar elementos visuales. Los VLM ofrecen una solución prometedora al combinar visión por computadora avanzada con capacidades de procesamiento de lenguaje natural. Este artículo explora cómo los VLM están superando las deficiencias del OCR, proporcionando soluciones más robustas y versátiles para el procesamiento de documentos en la era digital.
¿Qué es el OCR? ¿Cuáles son los procesos del OCR en el análisis de documentos?
El Reconocimiento Óptico de Caracteres (OCR) es una tecnología que permite la conversión de diferentes tipos de documentos, como documentos en papel escaneados, archivos PDF o imágenes capturadas por una cámara digital, en datos editables y buscables. Este proceso es crucial en el procesamiento de documentos y la extracción de datos de PDF, permitiendo que las máquinas reconozcan caracteres de texto impresos o manuscritos dentro de imágenes digitales.
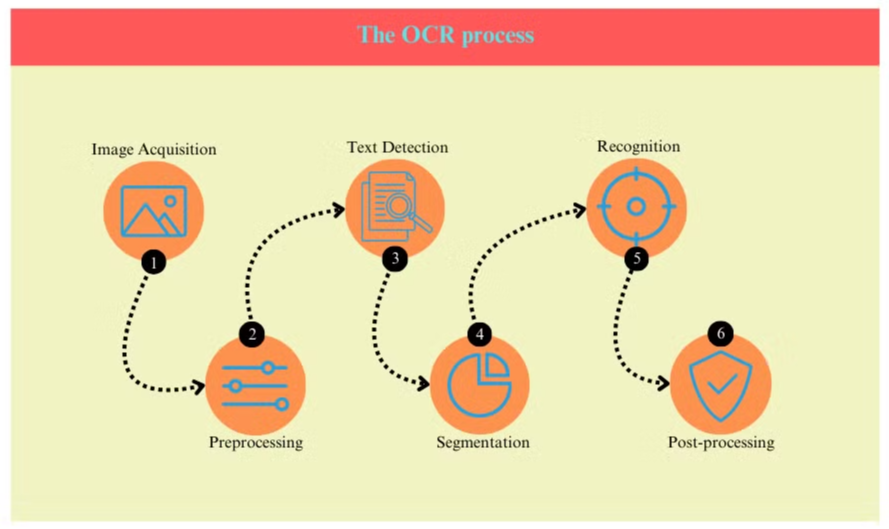
El Proceso de OCR
El proceso de OCR generalmente implica varios pasos:
- Adquisición de Imagen: El documento se escanea o fotografía para crear una imagen digital.
- Preprocesamiento: La imagen se limpia, eliminando ruido y ajustando brillo y contraste.
- Detección de Texto: El sistema identifica áreas que contienen texto dentro de la imagen.
- Segmentación de Caracteres: Se aíslan caracteres individuales dentro de las áreas de texto.
- Reconocimiento de Caracteres: Cada carácter se analiza y se compara con una base de datos de caracteres conocidos.
- Post-procesamiento: El texto reconocido se verifica en busca de errores utilizando información lingüística y contextual.
Si bien el OCR ha mejorado enormemente las capacidades de análisis de documentos, todavía enfrenta limitaciones al manejar diseños complejos, imágenes de baja calidad y fuentes variadas. Aquí es donde tecnologías avanzadas como los modelos de lenguaje visual están interviniendo para mejorar la precisión y la comprensión en la extracción de datos de imágenes y documentos.
Las Limitaciones de la Tecnología OCR Tradicional
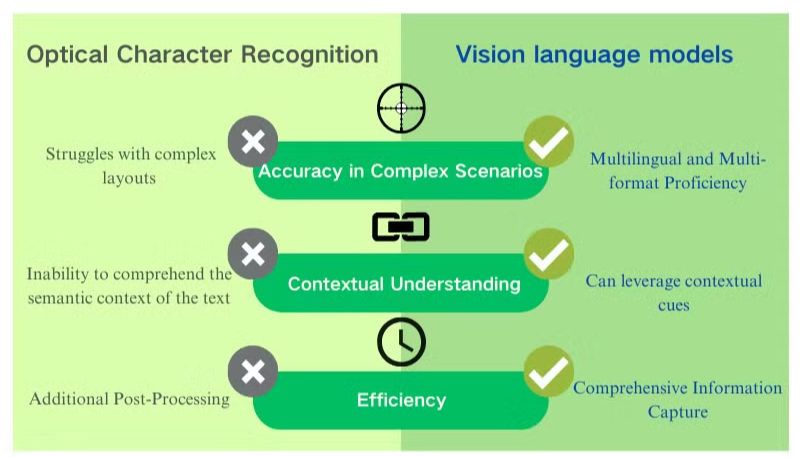
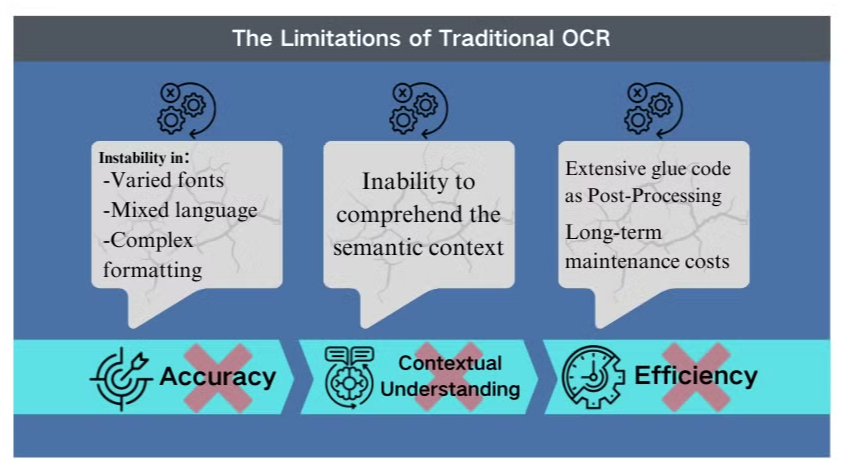
Desafíos de Precisión en Escenarios Complejos
La tecnología de reconocimiento óptico de caracteres (OCR) tradicional, aunque beneficiosa para la extracción básica de texto, enfrenta obstáculos significativos cuando se encuentra con diseños de documentos intrincados o imágenes de baja calidad. Estos sistemas a menudo luchan por mantener la precisión al procesar documentos con fuentes variadas, lenguajes mixtos o formatos complejos. Por ejemplo, el OCR puede fallar al intentar extraer datos de presentaciones con muchas imágenes o PDFs densamente formateados.
Falta de Comprensión Contextual
Una de las limitaciones más evidentes del OCR convencional es su incapacidad para comprender el contexto semántico del texto que procesa. Esta deficiencia se hace particularmente evidente en escenarios que requieren una interpretación matizada, como contratos legales o informes médicos. El enfoque del OCR en el reconocimiento de caracteres sin conciencia contextual puede llevar a interpretaciones críticas erróneas, especialmente cuando se trata de caracteres ambiguos o terminología específica de la industria.
Ineficiencias en el Post-Procesamiento
Las limitaciones del OCR a menudo requieren esfuerzos extensos de post-procesamiento. Este paso adicional puede aumentar significativamente el tiempo y los recursos necesarios para el procesamiento de documentos. Además, los sistemas OCR tradicionales suelen quedarse cortos cuando se les pide extraer información de gráficos, tablas u otros elementos no textuales, complicando aún más el proceso de extracción de documentos. Estas ineficiencias subrayan la necesidad de soluciones más avanzadas, como los modelos de lenguaje visual, que ofrecen un enfoque más integral para el análisis de documentos y la extracción de datos.
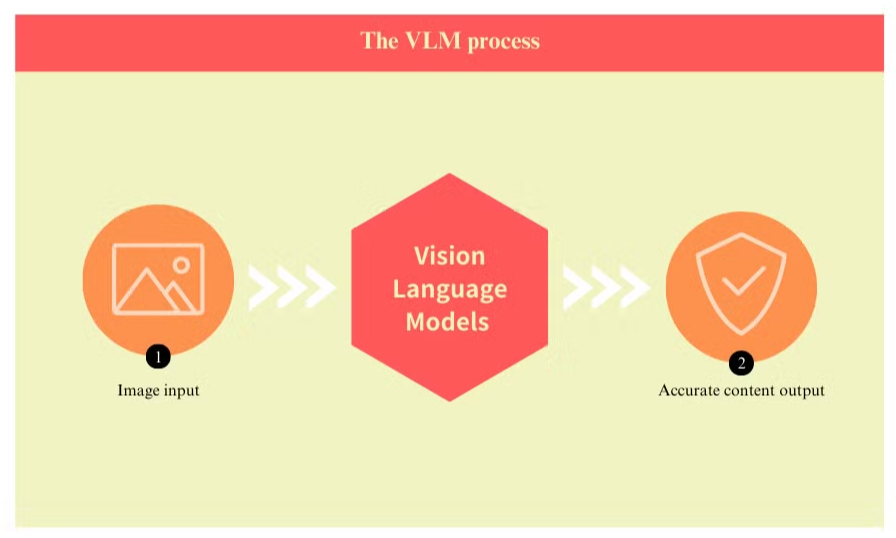
¿Qué son los Modelos de Lenguaje Visual y cómo mejoran el OCR?
Los modelos de lenguaje visual representan un avance significativo en la tecnología de procesamiento de documentos, abordando muchas de las limitaciones inherentes a los sistemas tradicionales de reconocimiento óptico de caracteres (OCR). Estos modelos avanzados combinan visión por computadora con procesamiento de lenguaje natural para comprender simultáneamente tanto los elementos visuales como los textuales de los documentos.
Precisión Mejorada y Comprensión Contextual
A diferencia del OCR, que lucha con imágenes de baja calidad y diseños complejos, los modelos de lenguaje visual sobresalen en la interpretación de diversos formatos de documentos. Pueden extraer datos de manera precisa de imágenes, PDFs y otros contenidos visuales, incluso cuando se enfrentan a escenarios desafiantes. Esta precisión mejorada proviene de su capacidad para considerar todo el contexto de un documento, en lugar de centrarse únicamente en caracteres o palabras individuales.
Extracción de Datos Integral
Los modelos de lenguaje visual van más allá del simple reconocimiento de texto, ofreciendo capacidades integrales de extracción de datos de PDF. Pueden identificar e interpretar tablas, gráficos y figuras dentro de los documentos, preservando la integridad de los diseños complejos. Este enfoque holístico del análisis de documentos permite una recuperación de información más matizada y completa, mejorando significativamente la utilidad de los datos extraídos para aplicaciones posteriores.
Competencia Multilingüe y Multifuncional
Una de las principales ventajas de los modelos de lenguaje visual es su flexibilidad para manejar múltiples idiomas y formatos de documentos. A diferencia de los sistemas OCR que pueden tener dificultades con scripts no latinos o documentos en lenguajes mixtos, estos modelos pueden procesar sin problemas contenido en varios idiomas y scripts, lo que los hace invaluables para las necesidades de procesamiento de documentos globales.
Beneficios Clave de los Modelos de Lenguaje Visual para la Comprensión de Documentos
Los modelos de lenguaje visual ofrecen ventajas significativas sobre el OCR tradicional para el procesamiento de documentos y la extracción de datos. Estos sistemas impulsados por IA combinan la comprensión visual y textual para ofrecer resultados superiores en varios tipos de documentos.
Precisión Mejorada y Comprensión Contextual
Los modelos de lenguaje visual sobresalen en el manejo de diseños complejos, imágenes de baja calidad y fuentes diversas. A diferencia del OCR, que lucha con caracteres ambiguos, estos modelos aprovechan las pistas contextuales para interpretar el texto con precisión. Esta capacidad mejora drásticamente la precisión de la extracción de datos de PDF, especialmente para documentos con estructuras intrincadas o mala calidad de imagen.
Captura Integral de Información
Mientras que el OCR se centra únicamente en el reconocimiento de texto, los modelos de lenguaje visual pueden extraer datos de imágenes, tablas y gráficos. Este enfoque holístico asegura que la información crítica no se pase por alto durante la fase de procesamiento de documentos. Al capturar tanto elementos textuales como visuales, estos modelos proporcionan una comprensión más completa del contenido del documento.
Competencia Multilingüe y Multifuncional
Los modelos de lenguaje visual demuestran una notable flexibilidad en el procesamiento de documentos en varios idiomas y formatos. Pueden manejar sin problemas documentos en lenguajes mixtos y scripts no latinos, superando una limitación significativa de los sistemas OCR tradicionales. Esta versatilidad los hace invaluables para empresas globales que manejan diversos tipos de documentos y lenguajes.
Aplicaciones del Mundo Real Habilitadas por VLM que el OCR No Pudo
Los modelos de lenguaje visual están revolucionando el procesamiento de documentos en finanzas, recursos humanos y otros sectores, abordando limitaciones críticas de los sistemas tradicionales de OCR. Estos modelos avanzados de IA están transformando los esfuerzos de transformación digital en diversas industrias al ofrecer una precisión superior y comprensión contextual.
Revolucionando el Procesamiento de Documentos Financieros
Los modelos de lenguaje visual están transformando el procesamiento de documentos en finanzas, superando las limitaciones del OCR tradicional. Estos modelos avanzados sobresalen en la extracción de datos de estados financieros complejos, facturas y recibos con diseños intrincados. A diferencia del OCR, pueden entender el contexto, interpretando con precisión caracteres ambiguos (por ejemplo, diferenciar entre un cero y la letra O) y lenguajes mixtos que a menudo están presentes en documentos financieros globales.
Mejorando las Operaciones de Recursos Humanos a través del Análisis Inteligente de Documentos
En el sector de recursos humanos, los modelos de lenguaje visual están demostrando ser invaluables para la extracción de datos de PDF de currículos, registros de empleados y evaluaciones de desempeño. Estos modelos pueden comprender la estructura semántica de los documentos, lo que permite una recuperación y análisis de información más precisos. Esta capacidad agiliza significativamente los procesos de contratación y la gestión de datos de empleados, tareas en las que el OCR a menudo lucha con formatos variados y notas manuscritas.
Mejorando el Cumplimiento y la Gestión de Riesgos
Los modelos de lenguaje visual son particularmente efectivos en el cumplimiento y la gestión de riesgos en finanzas y recursos humanos. Pueden extraer e interpretar información crítica de documentos regulatorios, contratos y políticas con mayor precisión que el OCR. Esta capacidad mejorada de procesamiento de documentos asegura una mejor adherencia a los requisitos legales y procedimientos de evaluación de riesgos más eficientes.
Conclusión
En conclusión, los modelos de lenguaje visual representan un avance significativo en la tecnología de procesamiento de documentos, abordando muchas de las limitaciones inherentes a los sistemas tradicionales de OCR. Al combinar la comprensión visual y textual, estos modelos avanzados ofrecen un rendimiento superior en una amplia gama de escenarios desafiantes, desde diseños complejos hasta lenguajes mixtos y imágenes de baja calidad. A medida que las organizaciones continúan digitalizando sus operaciones y buscan formas más eficientes de extraer valor de sus repositorios de documentos, los modelos de lenguaje visual emergen como una herramienta poderosa para desarrolladores y líderes de ingeniería por igual. Su capacidad para comprender el contexto, manejar formatos diversos y proporcionar resultados más precisos los posiciona como un habilitador clave para pipelines sofisticados de RAG y capacidades de búsqueda a nivel empresarial, impulsando en última instancia las iniciativas de transformación digital a nuevas alturas.