¿Alguna vez te has preguntado qué significa OCR? El Reconocimiento Óptico de Caracteres es una tecnología poderosa que convierte imágenes de texto en datos legibles por máquina. Si bien el OCR ofrece enormes beneficios para digitalizar documentos y extraer información, no está exento de desventajas. A medida que exploras esta tecnología, es crucial entender tanto sus capacidades como sus limitaciones. En este artículo, descubrirás el significado detrás de OCR y profundizarás en sus posibles desventajas. Al obtener una comprensión completa del Reconocimiento Óptico de Caracteres, estarás mejor preparado para determinar si y cómo implementar esta tecnología en tus propios flujos de trabajo y proyectos.
¿Qué significa OCR y qué es un OCR?
¿Qué significa OCR?
OCR significa Reconocimiento Óptico de Caracteres, una tecnología que permite a las computadoras reconocer y convertir varios tipos de documentos. En su esencia, el OCR es el proceso de escanear texto impreso o manuscrito y convertirlo en texto codificado por máquina. Esto permite que el texto sea buscable, editable y transferible con facilidad. Entender qué significa OCR es esencial para cualquier persona que trabaje con tecnologías de escaneo de documentos y reconocimiento de texto.
¿Qué es un OCR?
Para aquellos que no están familiarizados con el término, "¿qué es un OCR?" es una pregunta común que se refiere al Reconocimiento Óptico de Caracteres, una tecnología que permite a las computadoras leer texto de imágenes o documentos escaneados.
El OCR convierte texto impreso o manuscrito en datos legibles por máquina, cerrando la brecha entre los formatos en papel y digitales. Esta tecnología emplea algoritmos sofisticados para detectar formas de letras, estructuras de palabras e incluso oraciones completas. Al hacerlo, transforma imágenes estáticas en archivos de texto editables y buscables.
La tecnología OCR se basa fundamentalmente en tecnologías de visión por computadora y reconocimiento de patrones. OCR significa trabajar escaneando documentos o imágenes que contienen texto y utilizando algoritmos avanzados para identificar y convertir el texto en un formato digital y editable. Uno de los momentos clave en la historia de la tecnología OCR fue en 1974, cuando Ray Kurzweil desarrolló un sistema OCR omni-fuente que podía reconocer texto en prácticamente cualquier fuente. A lo largo de los años, el OCR ha evolucionado de un simple emparejamiento de plantillas a sistemas más sofisticados.
A pesar de sus capacidades, la tecnología OCR enfrenta actualmente ciertas limitaciones. Estas incluyen desafíos en el reconocimiento de texto en imágenes de mala calidad, dificultad para manejar diseños o fondos complejos, y variaciones en la precisión al tratar con diferentes fuentes, idiomas o escritura a mano. Además, los sistemas OCR pueden tener problemas con documentos que tienen fondos de colores, que están borrosos o inclinados, y con la escritura cursiva.
Entendiendo el software de Reconocimiento Óptico de Caracteres
El software de Reconocimiento Óptico de Caracteres es una tecnología transformadora que convierte varios tipos de documentos en datos editables y buscables. Desempeña un papel crucial en la digitalización de nuestro mundo, haciendo que la información sea más accesible y manejable. El software OCR emplea un proceso sofisticado para convertir imágenes de texto en datos legibles por máquina.
Cómo funciona el software OCR
1. Adquisición de imagen
El viaje del OCR comienza con la captura de una imagen del documento. Esto se puede hacer a través de un escáner o una cámara digital. La imagen se traduce en un formato digital que una computadora puede procesar.
2. Preprocesamiento y mejora de imagen
El segundo paso implica mejorar la calidad de la imagen. Una vez adquirida la imagen, se somete a un preprocesamiento para mejorar su calidad para un mejor reconocimiento. Este paso puede implicar ajustar el contraste, el brillo y la nitidez de la imagen, así como eliminar cualquier ruido o elementos irrelevantes. Esta etapa de preprocesamiento es crucial para lograr resultados precisos, especialmente al tratar con escaneos o fotografías de baja calidad.
3. Detección de texto
El software OCR analiza la imagen preprocesada para detectar áreas que contienen texto. Lo hace buscando patrones y formas que son características del texto, como líneas de diferentes grosores y alturas.
4. Segmentación de caracteres
Una vez que se detectan las áreas de texto, el software descompone el texto en unidades más pequeñas, como bloques, líneas, palabras o incluso caracteres individuales. El software OCR analiza la imagen píxel por píxel para identificar patrones que forman caracteres. Descompone la imagen en segmentos más pequeños, aislando cada carácter.
5. Reconocimiento y extracción de texto
El software luego compara estas formas aisladas con una vasta base de datos de patrones de caracteres conocidos para determinar qué es cada carácter. El software extrae características de los caracteres, como el número de líneas, curvas o ángulos. Estas características ayudan al OCR a reconocer y distinguir entre diferentes caracteres.
6. Post-procesamiento
Después de que se identifican los caracteres, el sistema OCR pasa por una etapa de post-procesamiento donde corrige cualquier error potencial y formatea el texto para su salida. El texto corregido se exporta al formato deseado, como un documento de Word o un PDF buscable.
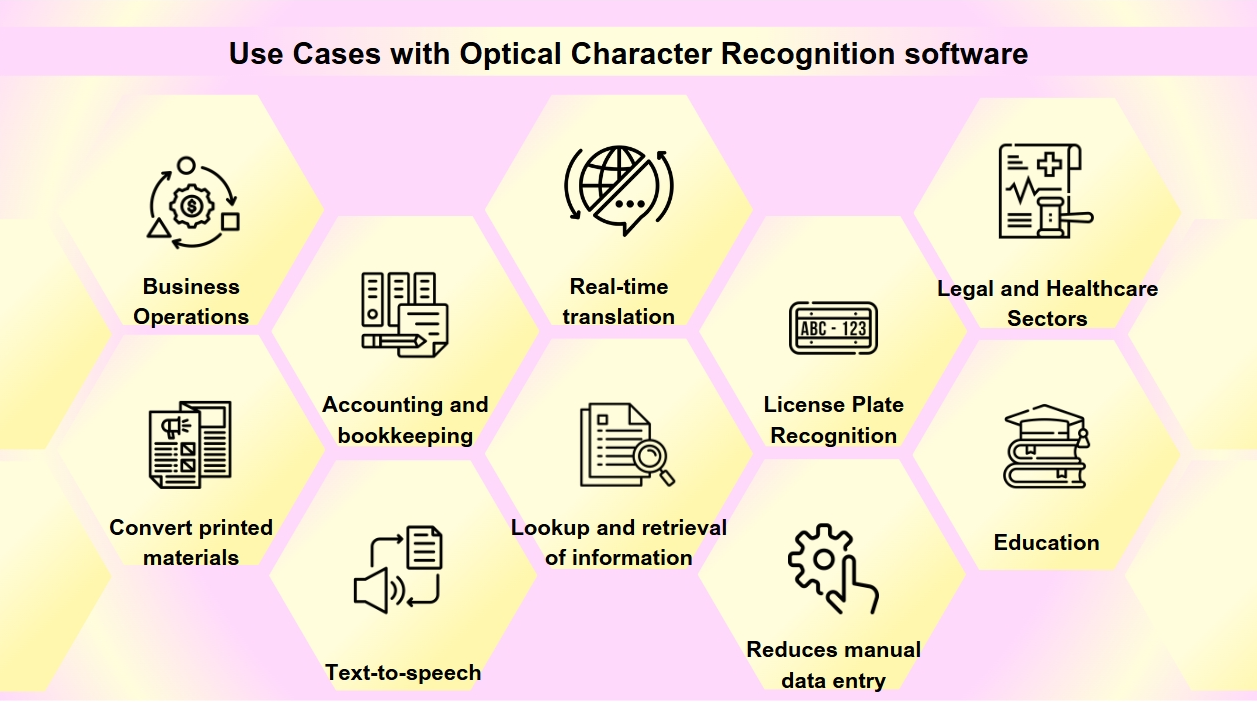
Casos de uso del software de Reconocimiento Óptico de Caracteres
El OCR se ha convertido en una herramienta esencial en la transformación digital de muchas industrias, agilizando procesos y mejorando la accesibilidad y precisión de los datos. Podrías encontrar OCR más a menudo de lo que te das cuenta. Desde escanear tarjetas de presentación hasta digitalizar libros antiguos, el OCR desempeña un papel crucial en varias industrias. La tecnología OCR tiene una amplia gama de aplicaciones:
-
Digitalización de documentos: El OCR se utiliza para convertir materiales impresos como libros antiguos, periódicos y documentos históricos en formatos digitales, haciéndolos buscables y preservándolos para futuras generaciones.
-
Procesamiento de formularios: Las empresas aprovechan el OCR para extraer automáticamente datos de formularios, lo que reduce la entrada manual de datos y aumenta la eficiencia en varios sectores como finanzas y salud.
-
Procesamiento de facturas: La tecnología OCR puede leer texto en facturas e introducir automáticamente los datos en sistemas financieros, agilizando los procesos contables y de teneduría de libros.
-
Accesibilidad: El OCR permite la funcionalidad de texto a voz, creando versiones de audio de texto para personas con discapacidad visual, haciendo así que los materiales impresos sean más accesibles.
-
Aplicaciones móviles: El OCR está integrado en aplicaciones para tareas como escanear tarjetas de presentación, reconocer texto en fotos y facilitar traducciones en tiempo real.
-
Buscabilidad: El OCR mejora la buscabilidad de documentos escaneados al extraer texto de imágenes o PDFs, permitiendo una fácil búsqueda y recuperación de información.
-
Reconocimiento de matrículas: Utilizado para la gestión de estacionamientos y tráfico, el OCR puede reconocer matrículas, permitiendo un monitoreo y aplicación eficientes.
-
Operaciones comerciales: El OCR agiliza los procesos comerciales al automatizar la entrada de datos de documentos como facturas, recibos y órdenes de compra, así como acelera el reclutamiento al escanear y procesar solicitudes de empleo y currículos.
-
Sectores legal y de salud: Las firmas de abogados utilizan OCR para digitalizar archivos de casos y documentos legales para una recuperación de información más fácil, mientras que los proveedores de salud lo utilizan para convertir registros de pacientes y formularios médicos en registros electrónicos de salud (EHR), mejorando la gestión de datos y la atención al paciente.
-
Educación: En entornos educativos, se utiliza OCR para crear libros de texto digitales y materiales de aprendizaje, mejorando la accesibilidad para estudiantes con diversas necesidades y apoyando un entorno de aprendizaje inclusivo.
A medida que la tecnología OCR avanza, continúa desempeñando un papel vital en hacer que la información sea más accesible y eficiente de manejar en la era digital.
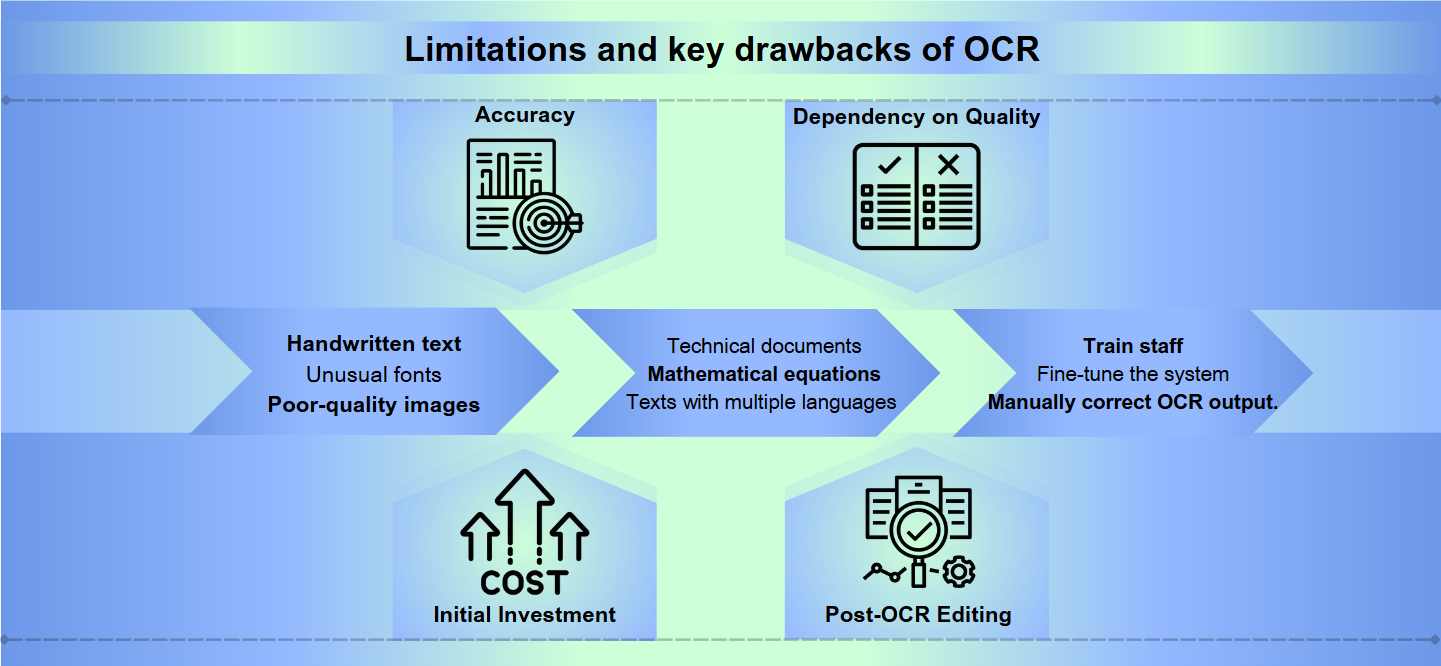
La desventaja del OCR: Limitaciones y desventajas
Desafíos de precisión
Si bien la tecnología de Reconocimiento Óptico de Caracteres (OCR) ha avanzado mucho, todavía enfrenta obstáculos significativos para lograr una precisión perfecta. El texto manuscrito, fuentes inusuales o imágenes de mala calidad pueden llevar a interpretaciones erróneas y errores. Incluso ligeras variaciones en las formas o tamaños de los caracteres pueden confundir a los sistemas OCR, resultando en una salida confusa que requiere corrección manual.
Restricciones de idioma y formato
La mayoría de las soluciones OCR sobresalen con idiomas y formatos estándar, pero luchan con contenido especializado. Documentos técnicos, ecuaciones matemáticas o textos con múltiples idiomas pueden presentar desafíos significativos. Además, el OCR puede fallar cuando se enfrenta a diseños complejos, tablas o documentos con formatos intrincados, perdiendo potencialmente información estructural crucial.
Intensidad de recursos
Implementar y mantener un sistema OCR efectivo puede ser intensivo en recursos. El software OCR de alta calidad a menudo viene con un precio elevado, y el hardware necesario para procesar grandes volúmenes de documentos puede ser costoso. Además, el tiempo y esfuerzo necesarios para capacitar al personal, ajustar el sistema y revisar y corregir manualmente la salida del OCR pueden agotar los recursos organizacionales.
Principales desventajas del OCR
-
Precisión: El software OCR puede tener dificultades con la precisión, especialmente al tratar con imágenes de mala calidad, diseños complejos o texto manuscrito. Los errores pueden variar desde la lectura incorrecta de caracteres hasta la omisión de secciones enteras de texto.
-
Dependencia de la calidad: La efectividad del OCR depende en gran medida de la calidad del documento original. Tinta desvanecida, manchas o papel arrugado pueden llevar a traducciones inexactas.
-
Inversión inicial: Configurar un sistema OCR puede requerir un costo inicial significativo, que incluye no solo el software, sino también hardware compatible como escáneres.
-
Edición post-OCR: A menudo, la salida de los procesos OCR requiere revisión y corrección manual, lo que puede llevar mucho tiempo.
Modelo de Lenguaje Visual superando las limitaciones del OCR
A medida que la tecnología avanza, están surgiendo soluciones innovadoras para abordar las deficiencias del Reconocimiento Óptico de Caracteres (OCR) tradicional. Uno de estos avances es el Modelo de Lenguaje Visual (VLM), que combina visión por computadora y procesamiento de lenguaje natural para revolucionar la extracción y comprensión de texto.
Comprensión contextual mejorada
Los VLM sobresalen en comprender el contexto que rodea al texto, a diferencia del reconocimiento aislado de caracteres del OCR. Al analizar elementos visuales junto con el texto, estos modelos pueden interpretar diseños complejos, notas manuscritas e incluso texto parcialmente oculto con notable precisión.
Capacidades multilingües y multimodales
Mientras que el OCR a menudo lucha con diversos idiomas y escrituras, los VLM demuestran una versatilidad impresionante. Pueden procesar múltiples idiomas sin problemas e incluso interpretar contenido visual como diagramas o gráficos, proporcionando una comprensión más completa de los documentos.
Aprendizaje adaptativo y mejora continua
A diferencia de los sistemas OCR estáticos, los VLM aprovechan el aprendizaje automático para adaptarse y mejorar con el tiempo. A medida que encuentran nuevos datos y escenarios, estos modelos refinan su rendimiento, volviéndose cada vez más capaces de manejar varios tipos y formatos de documentos.
Al superar las limitaciones del OCR, los Modelos de Lenguaje Visual están allanando el camino para un procesamiento de documentos más preciso, eficiente e inteligente en diversas industrias.
Elige el Modelo de Lenguaje Visual: Prueba AnyParser
Basándose en los avances de los Modelos de Lenguaje Visual (VLM), AnyParser surge como una solución sofisticada que trasciende las limitaciones de la tecnología OCR tradicional. Desarrollado por el equipo de CambioML, AnyParser es una poderosa herramienta de análisis de documentos que utiliza una API precisa y configurable para extraer información de diversas fuentes de datos no estructurados, como PDFs, imágenes y gráficos, convirtiéndolos en formatos estructurados.
Fundación técnica y capacidades
AnyParser se basa en la sólida fundación de grandes modelos de lenguaje (LLMs), asegurando alta precisión en la extracción de texto, tablas, gráficos y diseños de documentos. Se destaca por su capacidad para mantener el diseño y formato originales, una característica particularmente beneficiosa para documentos con diseños complejos o que requieren la preservación de la estética original.
Privacidad y seguridad
Subrayando la privacidad del usuario, AnyParser procesa datos localmente, protegiendo así información sensible. Esta característica es una ventaja significativa para empresas e individuos que manejan datos confidenciales.
Personalización y flexibilidad
Ofreciendo un alto grado de configurabilidad, AnyParser permite a los usuarios establecer reglas de extracción personalizadas y definir formatos de salida que se adapten a sus necesidades específicas. Esta adaptabilidad lo convierte en una herramienta ideal para una amplia gama de aplicaciones, desde ingeniería de IA hasta análisis financiero.
Conclusión
Como has aprendido, la tecnología OCR ofrece poderosas capacidades para digitalizar texto, pero no está exenta de limitaciones. Si bien el reconocimiento óptico de caracteres puede mejorar drásticamente la eficiencia, debes sopesar cuidadosamente las posibles desventajas. Considera los problemas de precisión, los desafíos de formato y los requisitos de recursos antes de implementar una solución OCR. En última instancia, la decisión de utilizar OCR depende de tus necesidades y circunstancias específicas. Al comprender tanto los beneficios como las desventajas, puedes tomar una decisión informada sobre si el OCR es adecuado para tu organización. A medida que el OCR continúa evolucionando, mantente al tanto de nuevos desarrollos que puedan abordar las deficiencias actuales y desbloquear un potencial aún mayor para esta tecnología transformadora.
Llamado a la acción
Aprovecha el poder de los Modelos de Lenguaje Visual probando AnyParser de forma gratuita para convertir tus PDFs a Google Sheets en https://www.cambioml.com/sandbox. Obtén una consulta gratuita sobre cómo los VLM pueden mejorar tu flujo de trabajo de extracción de datos.