Het converteren van complexe PDF's naar Markdown kan een uitdaging zijn. Er zijn veel open-source bibliotheken beschikbaar om tekst uit PDF's te extraheren, maar als het gaat om PDF's met complexe elementen zoals tabellen en grafieken, blijven de resultaten vaak achter. Populaire grote taalmodellen zoals GPT of Claude kunnen deze taken aan, maar zijn vaak traag en produceren soms onnauwkeurige output. Traditionele OCR-tools zijn effectief voor eenvoudigere documenten, maar hebben vaak moeite om de exacte structuur en semantische betekenis van de oorspronkelijke inhoud te behouden. Aan de andere kant hallucineren vision-language modellen soms, wat leidt tot foutieve parsingresultaten. Deze blog legt uit wat parse betekent en beschrijft de resultaten van een vergelijkende analyse van meerdere modellen met behulp van verschillende metrics.
Wat betekent parse?
In de context van PDF parsing verwijst "parse" naar het proces van het extraheren van specifieke gegevens uit een PDF-bestand met behulp van gespecialiseerde software die bekend staat als een PDF-parser. Een PDF-parser analyseert de inhoud van een PDF-document en identificeert elementen zoals tekst, afbeeldingen, lettertypen, lay-outs en zelfs metadata. De geëxtraheerde gegevens kunnen vervolgens worden georganiseerd en geëxporteerd naar verschillende formaten zoals XML, JSON of Excel/CSV, die kunnen worden gebruikt voor verschillende doeleinden zoals data-analyse, archivering of automatisering van workflows.
Begrijpen wat parse betekent, is essentieel voor het evalueren van de effectiviteit van een parsingoplossing, vooral bij het vergelijken van verschillende PDF naar Markdown conversietools, aangezien PDF-parsing meer inhoudt dan alleen eenvoudige tekstextractie—het vereist het herkennen en behouden van de semantische structuur van het document.
Hoe meten we de kwaliteit van deze parsingoplossingen?
We hebben een reeks metrische waarden op woordniveau gedefinieerd om de prestaties van verschillende modellen te beoordelen, met de nadruk op belangrijke factoren zoals:
-
Precisie, Herinnering en F-Maat: Evalueren van de kwaliteit en volledigheid van parsing.
-
BLEU-score en ANLS: Nuttig voor het evalueren van taal- en lay-outstructuur.
-
Bewerkingsafstand, Jensen-Shannon Divergentie en Jaccard Afstand: Metrics die specifiek zijn voor het OCR-domein, bijzonder nuttig voor het begrijpen van de nauwkeurigheid van inhoudsreproductie.
Ons vision-language model, AnyParser, toont uitzonderlijke prestaties, met een combinatie van snelheid en nauwkeurigheid, vooral bij complexe lay-outs met tabellen en semantische elementen. AnyParser presteert beter dan andere oplossingen, met een 20x snelheidsverbetering ten opzichte van modellen zoals GPT/Claude, terwijl het hogere nauwkeurigheid bereikt.
Een uitgebreide vergelijkingsresultaat tegen leidende parsingmodellen
Statistisch object
Om de mogelijkheden van AnyParser echt te tonen, hebben we een uitgebreide vergelijking uitgevoerd met leidende parsingmodellen in de industrie en bekende grote taalmodellen (LLM's). Onze evaluatie omvatte:
1. Grote Taalmodellen
- AnyParser
- OpenAI's GPT-4o
- Google's Gemini 1.5 Pro
- Anthropic's Claude 3.5 Sonnet
2. OCR-gebaseerde Diensten
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Resultaatpresentatie en analyse
Experiment 1
Eerst voeren we een reeks rigoureuze vergelijkingen uit van de prestaties van verschillende document AI-modellen op meer dan 5 metrics hieronder: BLEU, Precisie en herinnering, F-Maat en ANLS. U kunt de wiskundige definitie van deze definities in de bijlage vinden.
De vergeleken modellen zijn: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl en Azure-DocAl.
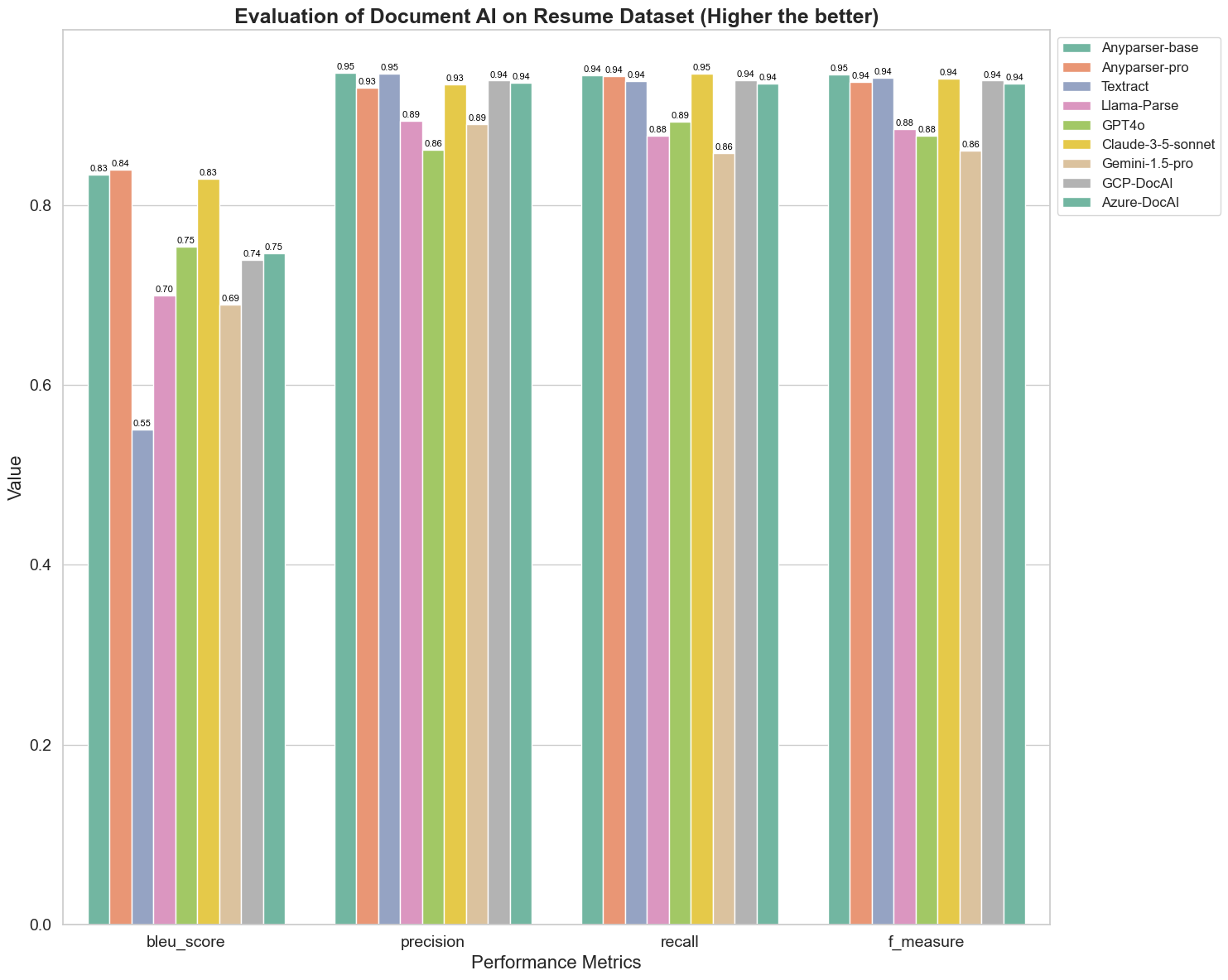
BLEU wordt gebruikt als een beoordeling van de kwaliteit van tweetalige interpretatie om de kwaliteit van de modellen bij het verwerken van uitspraken te testen. Door de resultaten van deze parsingmodellen onder de BLEU-beoordelingsmethode te vergelijken, ontdekken we dat: de scores van AnyParser-base en AnyParser-pro significant hoger zijn dan de scores van de andere modellen, Amazon Textract scoort het laagst, en de resultaten van de scores van de andere modellen bevinden zich op een relatief gemiddeld niveau.
Herkenningsnauwkeurigheid wordt meestal weergegeven door precisie en herinnering, waarbij precisie het percentage van werkelijk correcte resultaten onder de resultaten die door het model als correct zijn beoordeeld, vertegenwoordigt, en herinnering het percentage van werkelijk correct beoordeelde resultaten door het model onder alle daadwerkelijk correcte resultaten vertegenwoordigt. Door de precisie en herinnering van deze parsingmodellen te vergelijken, ontdekken we dat: behalve Llama-Parse, GPT4o en Gemini-1.5-pro, alle andere modellen op een hoog niveau zijn. Onder hen zijn AnyParser en Amazon Textract prominenter in precisie, en AnyParser-base en AnyParser-pro zijn prominenter in herinnering. De hogere score van het model op Precisie geeft aan dat het model meer correcte informatie in de productie resultaten output, en de hogere score op herinnering geeft aan dat het model meer in staat is om correcte informatie uit de steekproef te verkrijgen. De resultaten van de scores tonen aan dat AnyParser een duidelijke voorsprong heeft op het gebied van herkenningsnauwkeurigheid bij het extraheren van tekst uit PDF.
F-Maat is een uitgebreide evaluatie-index van precisie en herinnering op deze twee indicatoren. Door de scores van deze parsingmodellen onder F-Maat te vergelijken, kunnen we intuïtiever zien dat de vijf modellen, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI en Azure-DocAI, een betere kracht hebben op het gebied van herkenningsnauwkeurigheid in vergelijking met andere modellen. We kunnen intuïtiever zien dat de vijf modellen meer kracht hebben in herkenningsnauwkeurigheid dan de andere modellen, en AnyParser heeft de hoogste score onder F-Maat, wat de duidelijke voordelen van AnyParser in herkenningsnauwkeurigheid bij het extraheren van tekst uit PDF verder illustreert.
ANLS, als een veelgebruikte evaluatie-index bij het meten van de nauwkeurigheid en gelijkenis tussen de oorspronkelijke tekst en de doeltekst op het karakterniveau, is ook zeer informatief voor het meten van het parsingniveau van de modellen. De hogere scores van AnyParser-base, AnyParser-pro en Azure-DocAI weerspiegelen het hogere parsingniveau van deze modellen in vergelijking met de andere modellen.
Over het geheel genomen presteren AnyParser-base en AnyParser-pro beter dan de andere modellen.
Experiment 2
We vergelijken ook de prestaties van verschillende document AI-modellen op drie verschillende metrics: Bewerking Afstand, Jensen-Shannon Divergentie en Jaccard Afstand. De metrics worden gebruikt om de gelijkenis tussen de output van de modellen en een referentiedocument te meten. Lagere waarden duiden op betere prestaties.
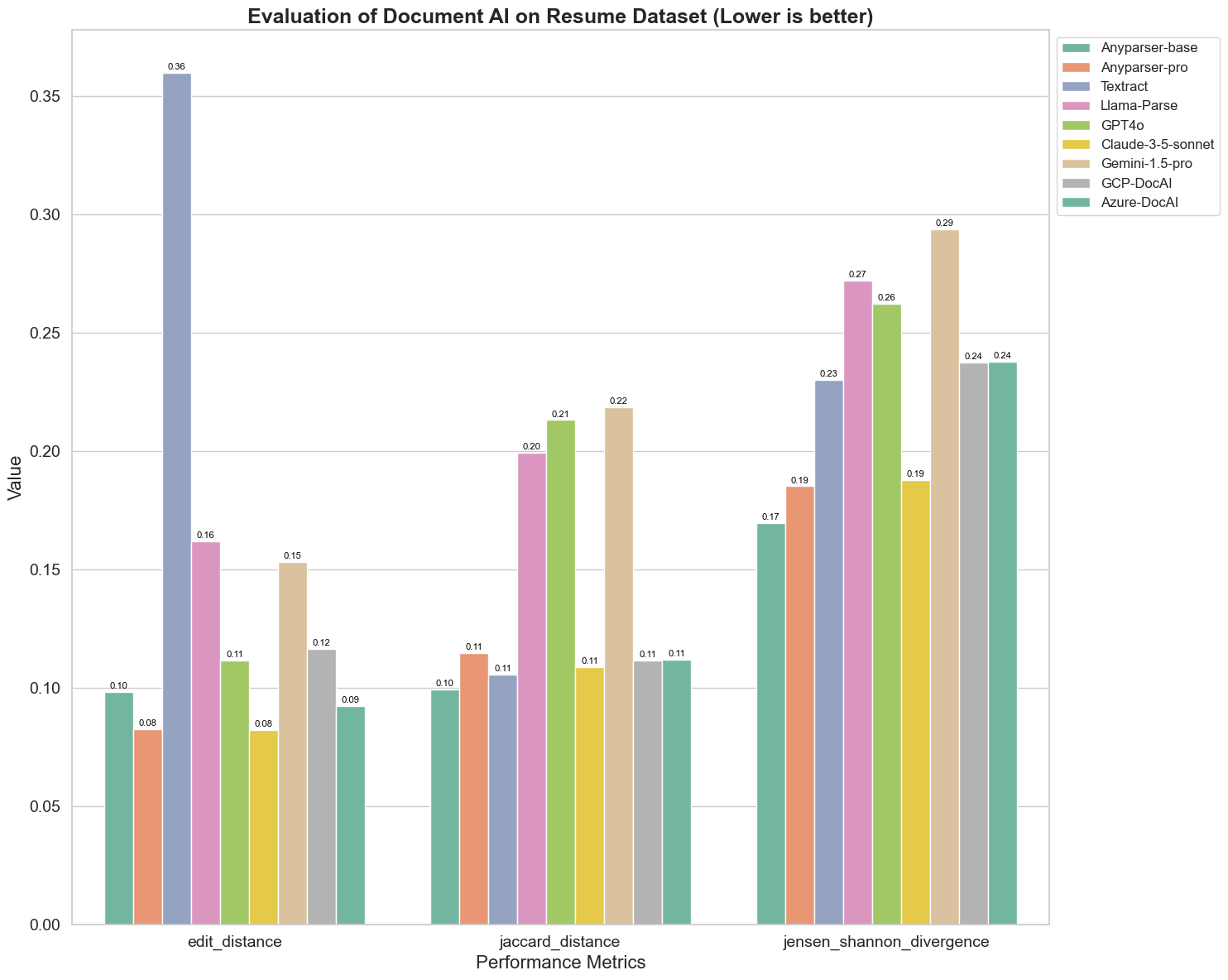
Hier zijn enkele belangrijke observaties uit de grafiek:
-
Bewerking Afstand: De modellen AnyParser-base en AnyParser-pro presteren het beste met de laagste bewerking afstand, wat suggereert dat hun output het dichtst bij het referentiedocument ligt.
-
Jensen-Shannon Divergentie: De modellen AnyParser-base en AnyParser-pro hebben de laagste divergentie, wat impliceert dat hun outputs het meest vergelijkbaar zijn met het referentiedocument in termen van woordverdeling.
-
Jaccard Afstand: Behalve Llama-parse, GPT4O, Gemini-1.5, presteren alle andere modellen redelijk goed met de laagste Jaccard afstand, wat aangeeft dat hun output de hoogste overlap heeft met het referentiedocument in termen van de set van gebruikte woorden.
Conclusie
Over het geheel genomen suggereert onze rigoureuze test dat AnyParser-base en AnyParser-pro over het algemeen goed presteren op verschillende metrics, wat de potentie voor nauwkeurige documentverwerking aangeeft. Uit de grafieken blijkt dat traditionele OCR-modellen zoals het beroemde Amazon Textract veel lager scoren dan vision language modellen. De prestaties van verschillende modellen variëren echter afhankelijk van de gebruikte metric, wat de noodzaak benadrukt om meerdere evaluatiecriteria in overweging te nemen bij het vergelijken van AI-modellen.
Introductie van onze Open-Source Evaluatiepijplijn
Om evaluaties te stroomlijnen, hebben we een evaluatiepijplijn gecreëerd die een industriestandaardmethode biedt voor het vergelijken van parsingmodellen. In ons voorbeeld demonstreren we het gebruik ervan in het HR-domein, waar cv-parsing gebruikelijk is. We hebben een diverse synthetische dataset van 128 cv's opgebouwd, gegenereerd met behulp van gekoppelde afbeelding-Markdown-bestanden. Met behulp van GPT-4 hebben we HTML-inhoud gegenereerd, deze omgezet naar afbeeldingen en de geëxtraheerde tekst gebruikt als grondwaarheid voor vergelijking.
En hier is het beste deel: we hebben dit evaluatiekader open-source gemaakt op GitHub! Of u nu een ontwikkelaar of een zakelijke gebruiker bent, onze pijplijn stelt u in staat om de parsingkwaliteit van verschillende modellen op uw eigen dataset te evalueren en te vergelijken.
Vind de quickstart-gids in de Github repo en zie hoe verschillende parsingmodellen zich tegen elkaar verhouden. We geloven dat we door de kracht van ons model openlijk te tonen, meer gebruikers kunnen aantrekken die betrouwbare, snelle en nauwkeurige parsingcapaciteiten willen.
Bijlage - Metrics
1. Precisie
Precisie meet de nauwkeurigheid van de geparsed inhoud, en toont aan hoeveel van de opgehaalde elementen correct waren. Bij parsing is het de verhouding van correct geëxtraheerde woorden ten opzichte van alle geëxtraheerde woorden.
Precisie = Ware Positieve (TP) / (Ware Positieve (TP) + Valse Positieve (FP))
- Ware Positieve (TP): Woorden die correct zijn geïdentificeerd door de parser.
- Valse Positieve (FP): Woorden die onjuist zijn geïdentificeerd door de parser.
2. Herinnering
Herinnering geeft de volledigheid van de parsing aan, of hoeveel relevante woorden uit het oorspronkelijke document zijn opgehaald.
Herinnering = Ware Positieve (TP) / (Ware Positieve (TP) + Valse Negatieve (FN))
- Valse Negatieve (FN): Woorden in het oorspronkelijke document die door de parser zijn gemist.
3. F-Maat (F1 Score)
De F1 Score is het harmonische gemiddelde van Precisie en Herinnering, en balanceert beide metrics om een algehele maat voor parsingkwaliteit te geven.
F1 Score = 2 × (Precisie × Herinnering) / (Precisie + Herinnering)
4. BLEU-score (Bilingual Evaluation Understudy)
De BLEU-score meet de gelijkenis tussen de geparsed inhoud en de oorspronkelijke tekst, met speciale nadruk op de volgorde van woorden. Het is bijzonder nuttig voor het evalueren van taal- en structuurconsistentie in geparse documenten, omdat het output die afwijkt in volgorde van de oorspronkelijke tekst bestraft.
5. ANLS (Gemiddelde Genormaliseerde Levenshtein Gelijkenis)
ANLS kwantificeert de gelijkenis tussen de geparsed inhoud en de oorspronkelijke tekst, met behulp van genormaliseerde bewerkingsafstand. Het wordt berekend door de Genormaliseerde Levenshtein Gelijkenis (NLS) voor elk woordpaar in de geparsed en referentieteksten te middelen. De NLS wordt als volgt berekend:
NLS = 1 - (Levenshtein Afstand (LD)(geparsed woord, origineel woord)) / max(Lengte van geparsed woord, Lengte van origineel woord)
Daarna is de ANLS het gemiddelde van NLS over alle woordparen:
ANLS = (1/N) × Σ(NLS_i) voor i=1 tot N
6. Bewerking Afstand
Bewerking Afstand berekent het aantal bewerkingen op woordniveau (invoegingen, verwijderingen, vervangingen) dat nodig is om de geparsed tekst naar de oorspronkelijke tekst te converteren.
7. Jensen-Shannon Divergentie
Jensen-Shannon Divergentie meet de gelijkenis tussen discrete kansverdelingen van geparsed en originele woordentellingen, en benadrukt verschillen in woordfrequentie.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
waarbij M = (1/2)(P + Q), en KL(P || Q) de Kullback-Leibler divergentie is
8. Jaccard Afstand
Jaccard Afstand meet de ongelijkheid tussen sets van woorden in geparsed en originele inhoud, nuttig voor het beoordelen van woordoverlap.
Jaccard Afstand = 1 - |A ∩ B| / |A ∪ B|
waarbij |A ∩ B| het aantal gemeenschappelijke elementen tussen A en B is,
en |A ∪ B| het totale aantal unieke elementen in beide sets is.