Introduksjon
Tabeller er en hjørnestein i strukturert datavisning, mye brukt i bransjer som finans, helsevesen og forskning. Imidlertid er det fortsatt en utfordring å hente ut tabulære opplysninger fra formater som PDF-er, skannede dokumenter eller bilder på grunn av varierte oppsett og kompleksitet.
Kunstig intelligens (AI) har revolusjonert dokumentbehandling, og muliggjort nøyaktige og effektive løsninger på problemer som hvordan man henter ut en tabell fra en PDF eller konverterer en tabell-PNG til strukturert data. Ved å utnytte avanserte AI-teknikker kan bedrifter nå enkelt transformere ustrukturerte visuelle elementer til handlingsbare innsikter, inkludert å konvertere et bilde til en tabell for sømløs integrering i arbeidsflyter.
Denne bloggen utforsker hvordan AI tabellutvinning styrker bransjer, fremhever de underliggende teknologiene, og viser potensialet for å forenkle komplekse dokumentbehandlingsoppgaver.

Utfordringer med Tradisjonell Tabellutvinning
Manuell utvinning av tabulære data fra dokumenter som PDF-er eller bilder er tidkrevende, feilutsatt og ineffektiv. Nedenfor er noen av de vanlige utfordringene med tradisjonelle metoder:
-
Komplekse Tabellstrukturer: Tabeller har ofte uregelmessige oppsett, som nestede celler, flerlags overskrifter eller sammenføyde rader, som er vanskelige å tolke. Tradisjonelle verktøy klarer ikke å hente ut tabeller fra PDF-er i slike scenarier.
-
Mangfoldige Formater: Tabeller forekommer i et bredt spekter av formater, inkludert skannede dokumenter, tabell-PNG-filer og PDF-er. Å hente ut data fra disse krever avanserte gjenkjenningsmetoder som går utover enkel OCR.
-
Kontekst og Betydning: Tradisjonelle systemer sliter med å bevare forholdet mellom rader og kolonner, noe som er avgjørende når man konverterer et bilde til en tabell eller behandler store datasett.
Disse utfordringene understreker behovet for intelligente løsninger som AI-drevet tabellutvinning, som kan håndtere komplekse oppsett og mangfoldige formater samtidig som de sikrer høy nøyaktighet.
Hva er AI Tabellutvinning?
AI tabellutvinning er anvendelsen av intelligente dokumentbehandlingsteknikker tilpasset for å identifisere, hente ut og organisere strukturert data fra tabeller i ulike dokumentformater. I motsetning til tradisjonelle regelbaserte metoder, utnytter AI-drevne tilnærminger avanserte teknologier for å takle komplekse utfordringer, som ikke-standardiserte oppsett, sammenføyde celler og flerlags overskrifter.
Et viktig fremskritt på dette området er bruken av Vision-Language Models (VLM). VLM-er kombinerer styrkene til datavisjon og naturlig språkforståelse, noe som gjør dem i stand til å tolke både visuelle og tekstlige elementer i et dokument. Denne doble kapasiteten gjør det mulig for VLM-er å:
- Identifisere tabellstrukturer visuelt, selv når de mangler eksplisitt formatering.
- Forstå innholdet kontekstuelt, som å skille mellom overskrifter, data og notater.
- Tilpasse seg ulike dokumenttyper, inkludert skannede bilder, PDF-er og håndskrevne notater.
Ved å utnytte VLM-er har AI tabellutvinning blitt mer nøyaktig og allsidig, i stand til å håndtere flerspråklige dokumenter og hente ut relasjoner mellom datapunkter som tradisjonelle metoder ofte overser.
Nøkkel Teknologier Bak AI Tabellutvinning
AI tabellutvinning er avhengig av en rekke avanserte teknologier som arbeider i harmoni for å overvinne tradisjonelle utfordringer. Blant disse skiller Vision-Language Models (VLM-er) seg ut som en transformativ innovasjon. Nedenfor er en oversikt over nøkkel teknologier og den avgjørende rollen til VLM-er:
-
Optical Character Recognition (OCR): Henter ut tekst fra bilder eller skannede dokumenter. Når det kombineres med VLM-er, forbedres OCR-resultatene fordi modellene forstår både den visuelle strukturen og den tekstlige betydningen.
-
Vision-Language Models (VLMs): VLM-er revolusjonerer tabellutvinning ved å integrere visuell og språklig databehandling. De utmerker seg i:
- Å gjenkjenne komplekse tabelloppsett og uregelmessige grenser.
- Å tolke forholdet mellom rader, kolonner og overskrifter.
- Å håndtere tabeller i ulike formater, inkludert bilder og PDF-er, med flerspråklig støtte. VLM-er muliggjør en dypere kontekstuell forståelse, som sikrer at hentet data beholder sin opprinnelige betydning og struktur.
-
Natural Language Processing (NLP): Analyserer og organiserer hentet data, og sikrer semantisk sammenheng. VLM-er forbedrer ytterligere NLP ved å gi kontekstuelle ledetråder fra visuelle mønstre.
-
Deep Learning Algoritmer: Trener modeller til å oppdage tabellgrenser, cellehierarkier og mønstre i ustrukturerte dokumenter. Når de berikes av VLM-er, oppnår disse algoritmene større presisjon og tilpasningsevne.
Ved å fokusere på VLM-er har AI tabellutvinning gått fra å være en oppgave med enkel datainnhenting til en med kontekstualisert forståelse, noe som gjør den uvurderlig for bransjer der nøyaktighet og nyanser er avgjørende.
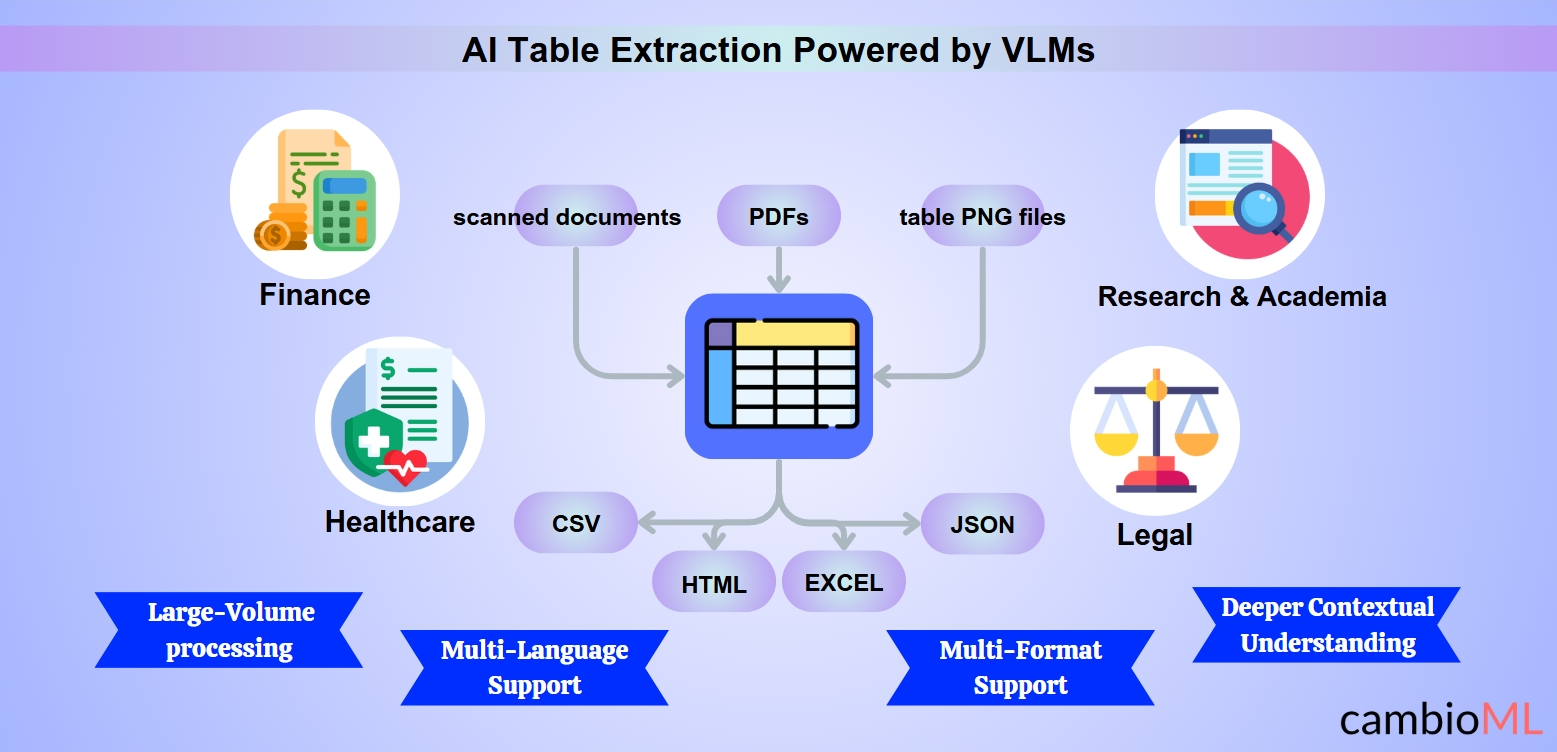
Bruksområder for AI Tabellutvinning
AI-drevet tabellutvinning transformerer bransjer ved å automatisere prosessen med å hente ut og organisere tabulære data fra ulike dokumentformater. Nedenfor er noen bemerkelsesverdige bruksområder der intelligent tabellutvinning har vist seg å være uvurderlig:
-
Finans: Å hente ut strukturert data fra finansielle rapporter, fakturaer og regnskap er ofte en arbeidskrevende oppgave. AI gjør det sømløst å kopiere PDF-tabeller til Excel, noe som muliggjør raskere avstemming, analyse og rapportering.
-
Helsevesen: Å organisere resultater fra kliniske studier, pasientjournaler eller medisinsk forskningsdata er forenklet. For eksempel kan helsepersonell enkelt kopiere tabeller fra PDF-er til Excel, og sikre at dataene er klare for integrering i elektroniske pasientjournaler (EHR).
-
Juridisk: Å analysere kontrakter og hente ut strukturerte klausuler fra nestede tabeller hjelper juridiske team med å jobbe mer effektivt. AI-modeller gjør det enkelt å kopiere PDF-tabeller til Excel, noe som sparer tid på samsvarskontroller og rettslig forskning.
-
Forskning og Akademia: Forskere kan raskt hente ut data fra vitenskapelige artikler, noe som forenkler oppgaven med å overføre nøkkelmetrikker ved å bruke verktøy for å kopiere tabeller fra PDF til Excel, og gjøre datasett klare for statistisk analyse.
AI tabellutvinnings evne til nøyaktig å behandle ulike dokumentformater revolusjonerer arbeidsflyter, noe som gjør det enklere å kopiere, organisere og analysere tabulære data i Excel-ark.
Fordeler med Intelligent Tabellutvinning
AI tabellutvinning tilbyr en rekke fordeler, spesielt når det gjelder å forbedre effektivitet, nøyaktighet og skalerbarhet. Ved å utnytte avanserte teknologier, inkludert Vision-Language Models (VLM-er), kan bedrifter overvinne tradisjonelle utfordringer i tabellutvinning:
-
Automatisering og Tidsbesparelser: Repeterende oppgaver som manuell kopiering av tabeller fra PDF til Excel elimineres, noe som gjør at ansatte kan fokusere på aktiviteter med høyere verdi.
-
Forbedret Nøyaktighet: AI-modeller reduserer betydelig feil som er vanlige når brukere manuelt kopierer PDF-tabeller til Excel eller stoler på enkle verktøy. Disse modellene sikrer at dataene beholder sin struktur og betydning.
-
Skalerbarhet for Storskala Behandling: AI-verktøy er designet for å håndtere bulkdatautvinning. Enten det er finansielle poster, forskningsdokumenter eller samsvarsmapper, forenkler de prosessen med å hente ut og organisere data i Excel.
-
Multi-Format og Multi-Språks Støtte: Intelligente systemer kan behandle dokumenter i ulike formater og språk, noe som muliggjør sømløs utvinning og kopiering av tabeller fra PDF til Excel selv i komplekse, flerspråklige sammenhenger.
AI tabellutvinning strømlinjeformer ikke bare arbeidsflyter, men sikrer også dataintegritet i konteksten, og transformerer hvordan bransjer håndterer tabulær informasjon. Denne effektiviteten er kritisk i dagens datadrevne verden, hvor rask og nøyaktig behandling av tabulære data er en konkurransefordel.
Håndtering av Multi-Format og Multi-Språks Utfordringer
Moderne AI-løsninger utmerker seg i å takle variasjonen av formater og språk, og sikrer konsekvent nøyaktighet og effektivitet på tvers av forskjellige datasett:
-
Multi-Format Kapabiliteter: AI-drevne verktøy kan enkelt behandle PDF-er, skannede dokumenter og bildefiler som tabell-PNG. Denne allsidigheten er spesielt kritisk når brukere trenger å hente ut tabeller fra PDF eller konvertere et bilde til en tabell for analyse og rapportering.
-
Multi-Språks Støtte: AI-modeller er trent på flerspråklige datasett, noe som gjør dem i stand til å håndtere dokumenter på ulike språk. Denne funksjonen er uvurderlig for globale bransjer som håndterer internasjonal dokumentasjon.
-
Bevaring av Dataforhold: Enten det er å behandle et bilde til tabell eller hente ut en kompleks struktur fra en PDF, sikrer AI-systemer at overskrifter, rader og kolonner bevares, og opprettholder integriteten til dataene.
Ved å håndtere disse utfordringene har AI-løsninger etablert seg som uunnværlige verktøy for organisasjoner som håndterer storskala, flerspråklig og multi-format dokumentasjon.
Fremtiden for AI i Tabellutvinning
Fremtiden for AI tabellutvinning er lys, med fremskritt som vil ytterligere forbedre dens kapabiliteter:
-
Forbedrede Vision-Language Models (VLM-er): Nye VLM-teknologier vil gi enda mer sofistikerte måter å hente ut tabeller fra PDF-er og konvertere komplekse tabell-PNG-formater til strukturert data. Disse modellene vil bygge bro over gapet mellom visuelle elementer og tekstforståelse.
-
Integrasjon med Generativ AI: Ved å integrere generativ AI, kan fremtidige løsninger ikke bare hente ut tabeller fra PDF-er eller bilder, men også analysere de hentede dataene for innsikter, oppsummeringer og anbefalinger.
-
End-to-End Automatisering: AI-drevne verktøy vil strømlinjeforme arbeidsflyter ved automatisk å konvertere filer, som å transformere et bilde til en tabell, kategorisere dataene, og mate dem direkte inn i analysepipelines.
-
Bredere Tilgjengelighet: AI-systemer vil bli mer brukervennlige og tilgjengelige, noe som gjør det mulig for selv ikke-tekniske brukere å prosessere tabell-PNG-filer eller hente ut data uten problemer.
AI tabellutvinning er i ferd med å redefinere dokumentbehandling, og gjøre datautvinning raskere, smartere og mer tilpasningsdyktig til utviklende bransjebehov. Bedrifter som tar i bruk disse løsningene vil få en konkurransefordel i å håndtere og utnytte dataene sine effektivt.
AnyParser: En Spillveksler i Dokumentbehandling og Tabellutvinning
AnyParser er i frontlinjen av intelligent dokumentbehandling, og tilbyr bedrifter en effektiv og pålitelig måte å hente ut data fra selv de mest komplekse dokumentene. Dens avanserte kapabiliteter er spesielt tydelige når det gjelder tabellutvinning, og sikrer presis og skalerbar datainnhenting for ulike bransjer.
Nøkkelfordeler med AnyParser for Tabellutvinning
-
Omfattende Formatstøtte: Enten det gjelder PDF-er, bilder eller andre filtyper, forenkler AnyParser datainnhenting ved å hente ut tabulær informasjon nøyaktig uavhengig av format.
-
Høy Presisjon og Kontekstuell Forståelse: I motsetning til tradisjonelle verktøy, bevarer AnyParser strukturen, forholdene og konteksten til tabulære data, og leverer resultater klare for analyse og integrering.
-
AI-Drevet Effektivitet: Drevet av Vision-Language Models (VLM-er), utmerker AnyParser seg i flerspråklige og multi-format miljøer, og sikrer sømløs datainnhenting i stor skala.
-
Tilpassbare Arbeidsflyter: Plattformen tilpasser seg dine unike behov, enten du henter ut finansielle tabeller, helseopplysninger eller forskningsdata.
Med AnyParser kan bedrifter optimalisere prosessene sine, minimere feil og spare tid ved å automatisere den komplekse oppgaven med å hente ut tabeller for strukturert datainnhenting.
Konklusjon
AI-drevet tabellutvinning har redefinert hvordan bedrifter behandler og utnytter strukturert data. Enten oppgaven er å hente ut tabeller fra PDF-er, behandle bilder eller oppnå nøyaktig datainnhenting, gjør verktøy som AnyParser det enklere enn noen gang å transformere ustrukturerte dokumenter til handlingsbare innsikter. AnyParser er din pålitelige løsning for å forenkle dokumentbehandling, og levere enestående nøyaktighet og effektivitet. Med sin evne til å håndtere ulike formater og kontekster, gir AnyParser organisasjoner muligheten til å automatisere arbeidsflytene sine og låse opp det fulle potensialet av dataene sine.
Handlingsoppfordring
Hvorfor vente med å oppleve neste nivå av dokumentbehandling? Lås opp det fulle potensialet av AnyParser ved å prøve funksjonene i et praktisk miljø!
Klikk på lenken nedenfor for å gå inn i Sandbox, hvor du kan utforske hvordan det forenkler:
- Nøyaktig datainnhenting fra PDF-er og bilder.
- Sømløs utvinning av tabeller for integrering i analyserverktøy.
- Pålitelig ytelse på tvers av komplekse og store datasett.
Ikke gå glipp av sjansen til å se hvordan AnyParser kan revolusjonere arbeidsflytene dine. Test det i dag og oppdag hvor enkelt dokumentbehandling og tabellutvinning kan være!