
I det konkurransedyktige landskapet av AI-drevne jobbmarkeder har Jobright.ai fremstått som en frontløper, i stor grad takket være sin innovative tilnærming til behandling av CV-dokumenter. I hjertet av denne suksessen ligger AnyParser, en banebrytende AI-teknologi som har revolusjonert måten Jobright.ai henter ut og analyserer CV-data. Denne artikkelen dykker ned i detaljene om CambioML's AnyParser, og utforsker hvordan det har blitt ryggraden i Jobright.ai's evner til å hente ut CV-er. Ved å undersøke den tekniske dyktigheten og de praktiske anvendelsene av AnyParser, vil vi avdekke hvordan denne AI-drevne dokumentparseren har betydelig forbedret nøyaktigheten, effektiviteten og den totale brukeropplevelsen på Jobright.ai's plattform, og satt en ny standard i bransjen.
Jobright.ai's behov for en nøyaktig CV-parser
Som det ledende AI-drevne jobbmarkedet, stod Jobright.ai overfor en kritisk utfordring i behandlingen av millioner av CV-er årlig. Selskapet innså at nøyaktig datautvinning fra CV-er var avgjørende for brukerretensjon og generell tjenestekvalitet. Dette behovet for presisjon i dokumentbehandling og ustrukturert databehandling ble en topp prioritet.
Utfordringer med tradisjonelle parsermetoder
Tradisjonelle OCR-modeller kan ikke fange semantisk informasjon fra CV-er, og sliter ofte med nøyaktighet i varierte dokumentformater. Disse begrensningene resulterte ofte i at viktige detaljer ble oversett, noe som potensielt påvirket kvaliteten på matchene mellom jobbsøkere og arbeidsgivere. Jobright.ai trengte en løsning som kunne overvinne disse hindringene og gi overlegne evner til å parse CV-er.
Jakten på høy nøyaktighet og lav latens
Jobright.ai satte seg fore å finne en AI-parser som kunne tilfredsstille to primære krav:
- Betydelig høyere nøyaktighet enn tradisjonelle OCR-baserte leverandører
- Evne til å håndtere stort gjennomløp samtidig som lav latens opprettholdes
Selskapet innså at forbedring av nøyaktighet samtidig som strenge latensstandarder ble overholdt var essensielt for å forbedre både jobbsøker- og arbeidsgiveropplevelser på plattformen deres. Dette doble fokuset på presisjon og hastighet i PDF-parsing førte Jobright.ai til å utforske avanserte løsninger innen dokumentutvinning, som til slutt førte dem til å vurdere AnyParser som en potensiell game-changer for deres behov innen behandling av CV-dokumenter.
Begrensningene ved tradisjonelle metoder for dokumentutvinning
Tradisjonelle metoder for dokumentparsing og ustrukturert datautvinning møter betydelige utfordringer i dagens digitale landskap. Disse tilnærmingene, som en gang var effektive, sliter nå med å holde tritt med den utviklende kompleksiteten i moderne dokumenter.
Ufleksibilitet og regelavhengighet
Tradisjonelle utvinningsmetoder er ofte avhengige av forhåndsdefinerte regler og maler, noe som gjør dem ufleksible når de konfronteres med varierende dokumentstrukturer. Denne rigiditeten fører til hyppig vedlikehold og oppdateringer, noe som hemmer effektivitet og skalerbarhet.
Mangler i kontekstforståelse
En av de mest åpenbare begrensningene er manglende evne til å forstå kontekst. OCR-baserte systemer sliter med komplekse oppsett, fler-kolonne PDF-er og fri tekst, og overser ofte viktige detaljer eller misforstår informasjon.
Utfordringer med ustrukturert data
Den eksponentielle veksten av ustrukturert big data har avdekket utilstrekkelighetene til konvensjonelle PDF-parserverktøy. Disse systemene svikter når de behandler varierte dokumenttyper, spesielt de med ikke-standard formater eller håndskrevet innhold.
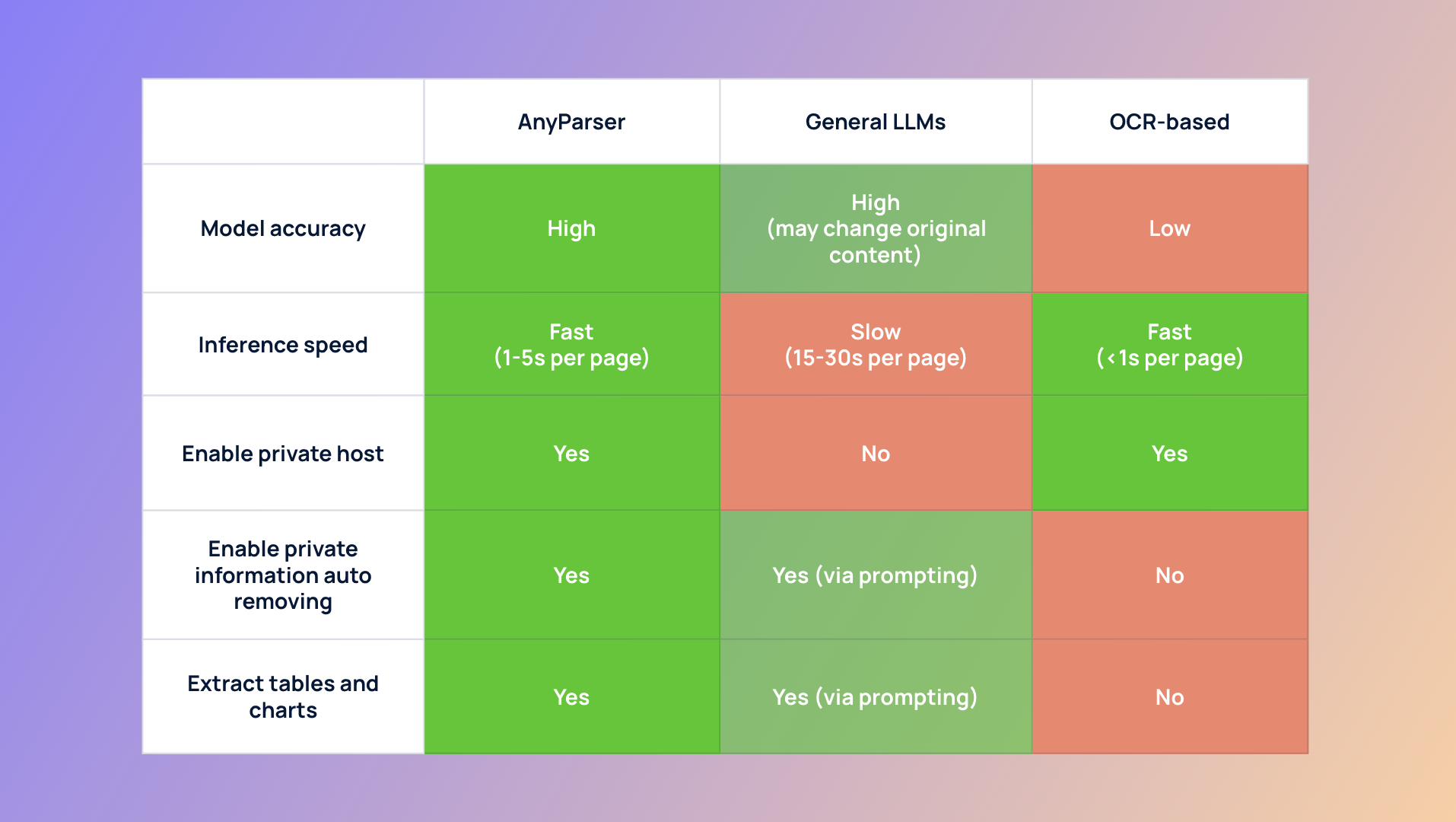
Hvordan AnyParser økte Jobright.ai's nøyaktighet i CV-parsing
Etter en intensiv testperiode for proof-of-concept, valgte Jobright.ai CambioML's Resume Parser, i stor grad på grunn av kvaliteten på AnyParser-modellen, som er langt over 10+ andre OCR-baserte parserne. Tradisjonelle OCR-modeller kan ikke fange semantisk informasjon fra CV-er, sliter ofte med nøyaktighet, og overser ofte viktige detaljer i varierte dokumentformater. Det er derfor CambioML's AnyParser skinner—en multimodal modell designet for nøyaktig å hente ut tekst, tabeller og diagraminformasjon fra PDF-er, Word-dokumenter, PPT-er og bilder.
Revolusjonering av dokumentutvinning
CambioML AnyParser's avanserte AI-teknologi revolusjonerte Jobright.ai's evner til å parse CV-er, og forbedret nøyaktigheten og effektiviteten dramatisk. Ved å utnytte banebrytende maskinlæringsalgoritmer, utmerker AnyParser seg i dokumentparsing, spesielt for komplekse formater som PDF-er og bilder. Denne innovative tilnærmingen til ustrukturert datautvinning gjorde det mulig for Jobright.ai å behandle CV-er med enestående presisjon.
Overvinne tradisjonelle parserutfordringer
I motsetning til konvensjonelle OCR-baserte systemer, kan AnyParser's sofistikerte PDF-parser tolke og hente informasjon fra ulike dokumentoppsett, inkludert tabeller, diagrammer og ikke-standard formatering. Denne allsidigheten sikrer at viktige detaljer aldri blir oversett, uansett CV-ens struktur eller design. Resultatet er et mer omfattende og pålitelig datasett for Jobright.ai's AI-drevne jobbmatching-algoritmer.
Forbedre brukeropplevelsen
Implementeringen av AnyParser forbedret betydelig opplevelsen for både jobbsøkere og arbeidsgivere på Jobright.ai-plattformen. Jobbsøkere drar nytte av en smidigere, mer nøyaktig søknadsprosess, mens rekrutterere får mer detaljert og pålitelig informasjon om kandidater. Denne forbedringen i datakvalitet har ført til bedre matcher mellom jobbåpninger og potensielle kandidater, og strømlinjeformet ansettelsesprosessen for alle involverte parter.
Opprettholde sikkerhet og samsvar
Samtidig som nøyaktigheten i parsing økes, overholder AnyParser også strenge databeskyttelsesprosedyrer. Dette sikrer at sensitiv personlig informasjon som hentes ut under dokumentparsingprosessen forblir beskyttet, og opprettholder Jobright.ai's forpliktelse til brukerens personvern og regulatorisk samsvar i det konkurransedyktige jobbmarkedet.
Fordelene med AnyParser for Jobright.ai's virksomhet
Forbedret nøyaktighet i CV-behandling
AnyParser's avanserte dokumentparsingkapabiliteter har betydelig forbedret Jobright.ai's evne til å hente ut nøyaktig informasjon fra CV-er. I motsetning til tradisjonelle OCR-baserte parserne, bruker AnyParser multimodale modeller for nøyaktig å hente ut tekst, tabeller og diagraminformasjon fra ulike dokumentformater. Denne økte nøyaktigheten i ustrukturert datautvinning har ført til mer presise kandidatmatcher og forbedrede brukeropplevelser for både jobbsøkere og arbeidsgivere.
Strømlinjeformet søknadsprosess
Ved å utnytte AnyParser's kraftige PDF-parserteknologi, har Jobright.ai strømlinjeformet sin søknadsprosess. Verktøyet kan automatisk fylle ut vanlige søknadsfelt, noe som sparer tid for jobbsøkere og reduserer datainntastingsfeil. Denne effektiviteten har bidratt til høyere brukertilfredshet og økt plattformengasjement.
Forbedret kandidatvurdering
AnyParser's avanserte dokumentutvinningskapabiliteter har gjort det mulig for Jobright.ai å implementere mer sofistikerte prosesser for kandidatvurdering. Det AI-drevne verktøyet kan raskt analysere store mengder CV-er, hente ut relevante ferdigheter og erfaringer for å matche kandidater med passende jobbåpninger. Dette har resultert i en mer effektiv ansettelsesprosess for arbeidsgivere og bedre jobb-anbefalinger for søkere.
Konkurransefortrinn i AI-jobbmarkedet
Ved å inkorporere AnyParser's banebrytende teknologi, har Jobright.ai befestet sin posisjon som et ledende AI-jobbmarked. Den forbedrede nøyaktigheten og effektiviteten i CV-behandling har skilt Jobright.ai fra konkurrentene, tiltrukket flere brukere og forbedret selskapets omdømme i bransjen. Denne konkurransefordelen har bidratt til Jobright.ai's vekst og suksess i det utviklende landskapet for jobbsøking.
Prøv AnyParser's innovative dokumentparsing gratis
Opplev avansert AI-drevet utvinning
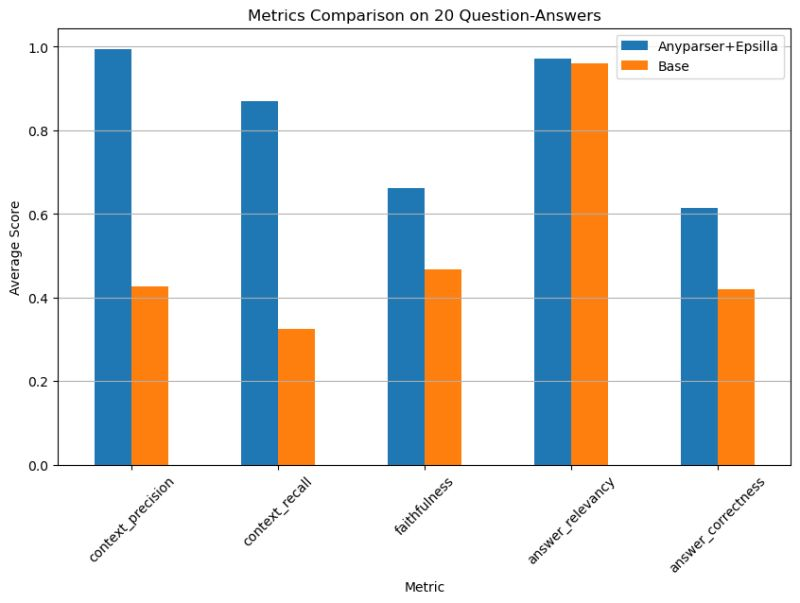
AnyParser tilbyr en banebrytende løsning for dokumentparsing, som utnytter avansert multimodal AI for å hente ut tekst, tabeller, figurer og diagrammer fra komplekse dokumenter med enestående nøyaktighet. Dette innovative verktøyet overgår tradisjonelle OCR-baserte parserne, og gir en 2x forbedring i nøyaktighet ved dokumenthenting. For bedrifter som håndterer ustrukturert data, presenterer AnyParser en mulighet til å strømlinjeforme arbeidsflyter og få verdifulle innsikter.
Utforsk AnyParser's nøkkelfunksjoner
AnyParser's kapabiliteter strekker seg utover grunnleggende tekstutvinning. Dets kjernefunksjoner inkluderer:
- Støtte for flere formater for PDF-er, PowerPoints og bilder
- Personvernsfokusert arkitektur som ikke lagrer kundedata
- Fleksible utvinningsalternativer for overskrifter, bunntekster og andre elementer
- Automatisk PII-redigering for forbedret databeskyttelse
Ifølge CambioML er AnyParser 2x mer presis og 2.5x mer nøyaktig enn bransjegjennomsnittlige OCR-verktøy, samtidig som det tilbyr raskere behandlingstider og lavere kostnader.
Start din gratis prøveperiode i dag
Klar til å revolusjonere dokumentbehandlingen din? Prøv AnyParser gratis uten kredittkort på https://www.cambioml.com/sandbox. Den gratis prøveperioden lar deg behandle opptil 10 sider per dokument, med en maksimal filstørrelse på 10MB. Opplev på egenhånd hvordan AnyParser's PDF-parser kan transformere tilnærmingen din til ustrukturert data og dokumentutvinning. Ikke gå glipp av denne muligheten til å forbedre datanalysekapabilitetene dine og strømlinjeforme arbeidsflyten din med toppmoderne AI-teknologi.