Visjons språkmodeller (VLM-er) revolusjonerer feltet for dokumentanalyse, og adresserer mange av begrensningene som er iboende i tradisjonelle systemer for optisk tegngjenkjenning (OCR). Mens OCR har vært en hjørnestein i teknologien for digitalisering av tekst fra bilder, står det overfor betydelige utfordringer i komplekse scenarier. Disse inkluderer nøyaktighetsproblemer med lavkvalitetsbilder, begrenset kontekstforståelse, vanskeligheter med blandede språk og manglende evne til å tolke visuelle elementer. VLM-er tilbyr en lovende løsning ved å kombinere avansert datamaskinvisjon med evner innen naturalspråkbehandling. Denne artikkelen utforsker hvordan VLM-er overkommer OCRs mangler, og gir mer robuste og allsidige løsninger for dokumentbehandling i den digitale tidsalderen.
Hva er OCR? Hva er prosessene for OCR i dokumentanalyse?
Optisk tegngjenkjenning (OCR) er en teknologi som muliggjør konvertering av forskjellige typer dokumenter, som skannede papirdokumenter, PDF-filer eller bilder tatt med et digitalkamera, til redigerbare og søkbare data. Denne prosessen er avgjørende i dokumentbehandling og PDF-datautvinning, og lar maskiner gjenkjenne trykte eller håndskrevne teksttegn i digitale bilder.
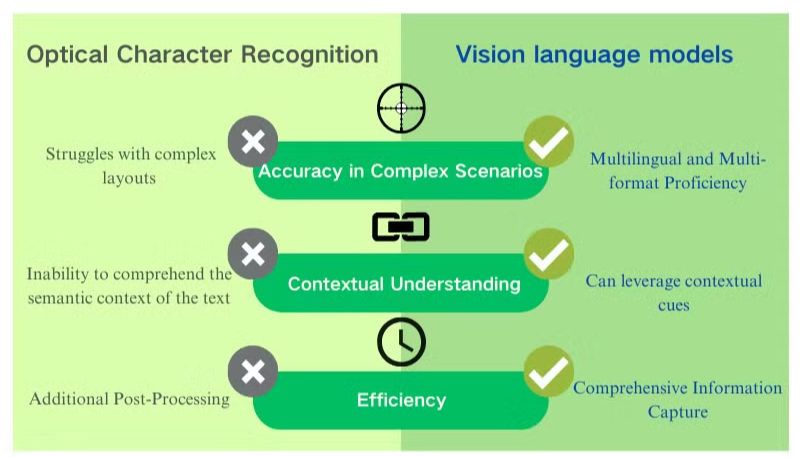
OCR-prosessen
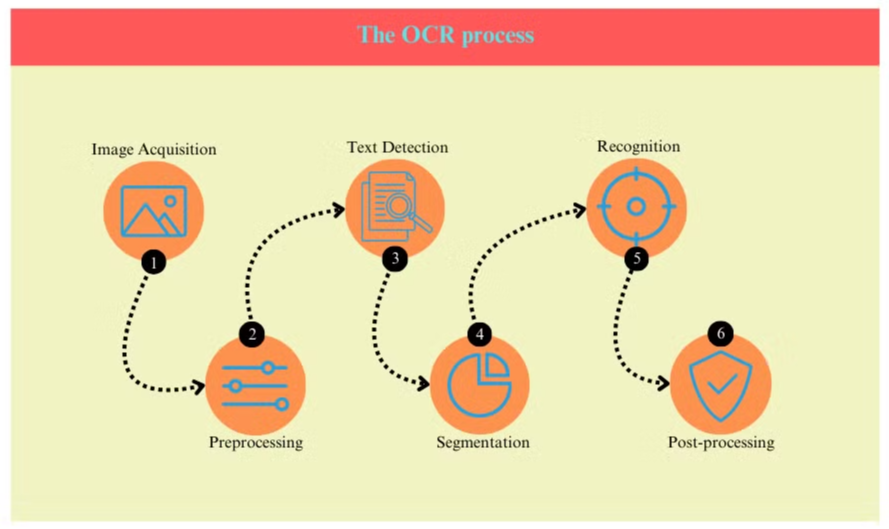
OCR-prosessen involverer vanligvis flere trinn:
- Bildeanskaffelse: Dokumentet skannes eller fotograferes for å lage et digitalt bilde.
- Forbehandling: Bildet renses, støy fjernes og lysstyrke og kontrast justeres.
- Tekstdeteksjon: Systemet identifiserer områder som inneholder tekst i bildet.
- Tegndeling: Individuelle tegn isoleres innenfor tekstområdene.
- Tegngjenkjenning: Hvert tegn analyseres og sammenlignes med en database over kjente tegn.
- Etterbehandling: Den gjenkjente teksten sjekkes for feil ved hjelp av språklig og kontekstuell informasjon.
Selv om OCR har forbedret dokumentanalysekapabiliteter betydelig, står det fortsatt overfor begrensninger når det gjelder håndtering av komplekse oppsett, lavkvalitetsbilder og varierte skrifttyper. Dette er der avanserte teknologier som visjons språkmodeller kommer inn for å forbedre nøyaktigheten og forståelsen i utvinning av data fra bilder og dokumenter.
Begrensningene ved tradisjonell OCR-teknologi
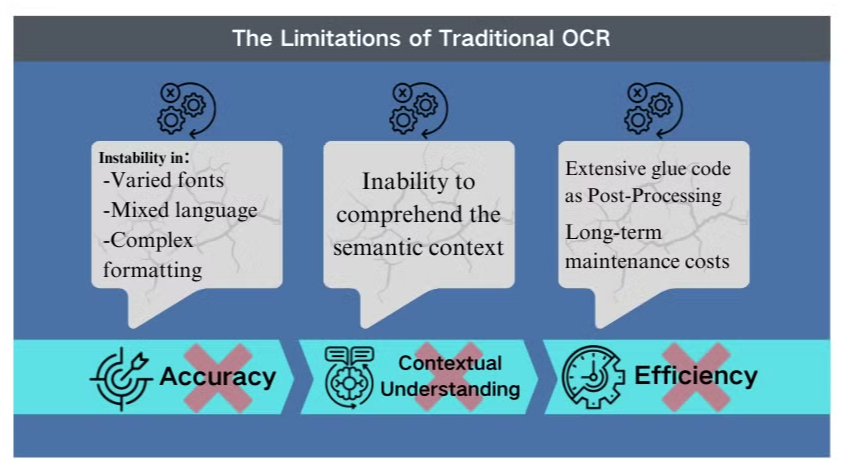
Nøyaktighetsutfordringer i komplekse scenarier
Tradisjonell optisk tegngjenkjenning (OCR) teknologi, selv om den er nyttig for grunnleggende tekstutvinning, står overfor betydelige hindringer når den konfronteres med intrikate dokumentoppsett eller lavkvalitetsbilder. Disse systemene sliter ofte med å opprettholde nøyaktighet når de behandler dokumenter med varierte skrifttyper, blandede språk eller kompleks formatering. For eksempel kan OCR mislykkes når den prøver å utvinne data fra bilde-tunge presentasjoner eller tett formaterte PDF-er.
Manglende kontekstforståelse
En av de mest åpenbare begrensningene ved konvensjonell OCR er dens manglende evne til å forstå den semantiske konteksten av teksten den behandler. Denne mangelen blir spesielt tydelig i scenarier som krever nyansert tolkning, som juridiske kontrakter eller medisinske rapporter. OCRs fokus på tegngjenkjenning uten kontekstuell bevissthet kan føre til kritiske feiltolkninger, spesielt når det gjelder tvetydige tegn eller bransjespesifikke terminologier.
Ineffektivitet i etterbehandling
Begrensningene ved OCR krever ofte omfattende etterbehandlingsinnsats. Dette ekstra trinnet kan betydelig øke tiden og ressursene som kreves for dokumentbehandling. Videre faller tradisjonelle OCR-systemer vanligvis kort når de får i oppdrag å utvinne informasjon fra diagrammer, tabeller eller andre ikke-tekstlige elementer, noe som ytterligere kompliserer dokumentutvinningsprosessen. Disse ineffektivitetene understreker behovet for mer avanserte løsninger, som visjons språkmodeller, som tilbyr en mer helhetlig tilnærming til dokumentanalyse og datautvinning.
Hva er visjons-språkmodeller og hvordan forbedrer de OCR
Visjons språkmodeller representerer et betydelig fremskritt innen dokumentbehandlingsteknologi, og adresserer mange av begrensningene som er iboende i tradisjonelle systemer for optisk tegngjenkjenning (OCR). Disse avanserte modellene kombinerer datamaskinvisjon med naturalspråkbehandling for å forstå både de visuelle og tekstlige elementene i dokumenter samtidig.
Forbedret nøyaktighet og kontekstforståelse
I motsetning til OCR, som sliter med lavkvalitetsbilder og komplekse oppsett, utmerker visjons språkmodeller seg i tolkningen av forskjellige dokumentformater. De kan nøyaktig utvinne data fra bilder, PDF-er og annet visuelt innhold, selv når de står overfor utfordrende scenarier. Denne forbedrede nøyaktigheten stammer fra deres evne til å vurdere hele konteksten av et dokument, i stedet for kun å fokusere på individuelle tegn eller ord.
Omfattende datautvinning
Visjons språkmodeller går utover enkel tekstgjenkjenning, og tilbyr omfattende PDF-datautvinningskapabiliteter. De kan identifisere og tolke tabeller, diagrammer og figurer i dokumenter, og bevare integriteten til komplekse oppsett. Denne helhetlige tilnærmingen til dokumentanalyse muliggjør mer nyansert og komplett informasjonsinnhenting, noe som betydelig forbedrer nytten av utvunnede data for nedstrømsapplikasjoner.
Flerspråklig og flerformat kompetanse
En av de viktigste fordelene med visjons språkmodeller er deres fleksibilitet i håndteringen av flere språk og dokumentformater. I motsetning til OCR-systemer som kan slite med ikke-latinske skrifter eller blandede språkdokumenter, kan disse modellene sømløst prosessere innhold på tvers av ulike språk og skrifter, noe som gjør dem uvurderlige for globale dokumentbehandlingsbehov.
Nøkkelfordeler med visjons-språkmodeller for dokumentforståelse
Visjons språkmodeller tilbyr betydelige fordeler sammenlignet med tradisjonell OCR for dokumentbehandling og datautvinning. Disse AI-drevne systemene kombinerer visuell og tekstlig forståelse for å levere overlegne resultater på tvers av ulike dokumenttyper.
Forbedret nøyaktighet og kontekstuell forståelse
Visjons språkmodeller utmerker seg i håndteringen av komplekse oppsett, lavkvalitetsbilder og varierte skrifttyper. I motsetning til OCR, som sliter med tvetydige tegn, utnytter disse modellene kontekstuelle ledetråder for å nøyaktig tolke tekst. Denne evnen forbedrer dramatisk nøyaktigheten av PDF-datautvinning, spesielt for dokumenter med intrikate strukturer eller dårlig bildekvalitet.
Omfattende informasjonsinnhenting
Mens OCR kun fokuserer på tekstgjenkjenning, kan visjons språkmodeller utvinne data fra bilder, tabeller og diagrammer. Denne helhetlige tilnærmingen sikrer at kritisk informasjon ikke blir oversett under dokumentbehandlingsfasen. Ved å fange både tekstlige og visuelle elementer gir disse modellene en mer komplett forståelse av dokumentinnholdet.
Flerspråklig og flerformat kompetanse
Visjons språkmodeller viser bemerkelsesverdig fleksibilitet i behandlingen av dokumenter på tvers av ulike språk og formater. De kan sømløst håndtere blandede språkdokumenter og ikke-latinske skrifter, og overvinne en betydelig begrensning ved tradisjonelle OCR-systemer. Denne allsidigheten gjør dem uvurderlige for globale virksomheter som håndterer forskjellige dokumenttyper og språk.
Virkelige applikasjoner muliggjort av VLM som OCR feilet
Visjons språkmodeller revolusjonerer dokumentbehandling innen finans, HR og andre sektorer ved å adressere kritiske begrensninger ved tradisjonelle OCR-systemer. Disse avanserte AI-modellene transformerer digitale transformasjonsinitiativer på tvers av bransjer ved å tilby overlegen nøyaktighet og kontekstforståelse.
Revolusjonering av finansdokumentbehandling
Visjons språkmodeller transformerer dokumentbehandling innen finans, og overkommer begrensningene ved tradisjonell OCR. Disse avanserte modellene utmerker seg i å utvinne data fra komplekse finansielle oppstillinger, fakturaer og kvitteringer med intrikate oppsett. I motsetning til OCR kan de forstå konteksten, nøyaktig tolke tvetydige tegn (f.eks. skille mellom en null og bokstaven O) og blandede språk som ofte finnes i globale finansdokumenter.
Forbedring av HR-operasjoner gjennom intelligent dokumentanalyse
Innen HR-sektoren viser visjons språkmodeller seg uvurderlige for PDF-datautvinning fra CV-er, ansattregistre og ytelsesvurderinger. Disse modellene kan forstå den semantiske strukturen i dokumenter, noe som muliggjør mer nøyaktig informasjonsinnhenting og analyse. Denne evnen strømlinjeformer ansettelsesprosesser og håndtering av ansattdata, oppgaver der OCR ofte sliter med varierte formater og håndskrevne notater.
Forbedring av overholdelse og risikostyring
Visjons språkmodeller er spesielt effektive i overholdelse og risikostyring innen både finans og HR. De kan utvinne og tolke kritisk informasjon fra regulatoriske dokumenter, kontrakter og retningslinjer med større nøyaktighet enn OCR. Denne forbedrede dokumentbehandlingskapabiliteten sikrer bedre overholdelse av juridiske krav og mer effektive risikovurderingsprosedyrer.
Konklusjon
Avslutningsvis representerer visjons språkmodeller et betydelig fremskritt innen dokumentbehandlingsteknologi, og adresserer mange av de iboende begrensningene ved tradisjonelle OCR-systemer. Ved å kombinere visuell og tekstlig forståelse tilbyr disse avanserte modellene overlegen ytelse på tvers av et bredt spekter av utfordrende scenarier, fra komplekse oppsett til blandede språk og lavkvalitetsbilder. Etter hvert som organisasjoner fortsetter å digitalisere driften sin og søker mer effektive måter å utvinne verdi fra dokumentarkivene sine, fremstår visjons språkmodeller som et kraftig verktøy for utviklere og ingeniørledere. Deres evne til å forstå kontekst, håndtere forskjellige formater og gi mer nøyaktige resultater plasserer dem som en nøkkelenabler for sofistikerte RAG-pipelines og virksomhetsomfattende søkefunksjoner, noe som til slutt driver digitale transformasjonsinitiativer til nye høyder.