Har du noen gang lurt på hva OCR står for? Optisk Tegngjenkjenning er en kraftig teknologi som konverterer bilder av tekst til maskinlesbare data. Selv om OCR tilbyr enorme fordeler for digitalisering av dokumenter og ekstraksjon av informasjon, er det ikke uten sine ulemper. Når du utforsker denne teknologien, er det avgjørende å forstå både dens muligheter og begrensninger. I denne artikkelen vil du oppdage betydningen bak OCR og dykke inn i dens potensielle ulemper. Ved å få en omfattende forståelse av optisk tegngjenkjenning, vil du være bedre rustet til å avgjøre om og hvordan du skal implementere denne teknologien i dine egne arbeidsflyter og prosjekter.
Hva betyr OCR og hva er en OCR?
Hva betyr OCR?
OCR står for Optisk Tegngjenkjenning, en teknologi som gjør det mulig for datamaskiner å gjenkjenne og konvertere ulike typer dokumenter. I sin kjerne er OCR prosessen med å skanne trykt eller håndskrevet tekst og konvertere den til maskinkodet tekst. Dette gjør teksten søkbar, redigerbar og overførbar med letthet. Å forstå hva OCR betyr er essensielt for alle som jobber med dokumentskanning og tekstgjenkjenningsteknologier.
Hva er en OCR?
For de som ikke er kjent med begrepet, er "hva er en OCR" et vanlig spørsmål som refererer til optisk tegngjenkjenning, en teknologi som lar datamaskiner lese tekst fra bilder eller skannede dokumenter.
OCR konverterer trykt eller håndskrevet tekst til maskinlesbare data, og bygger bro mellom papir- og digitale formater. Denne teknologien bruker sofistikerte algoritmer for å oppdage bokstavformer, ordstrukturer og til og med hele setninger. Ved å gjøre dette, forvandler den statiske bilder til redigerbare og søkbare tekstfiler.
OCR-teknologi er fundamentalt basert på datamaskinsyn og mønstergjenkjenningsteknologier. OCR står for arbeidet med å skanne dokumenter eller bilder som inneholder tekst og bruke avanserte algoritmer for å identifisere og konvertere teksten til et digitalt, redigerbart format. Et av de viktigste øyeblikkene i historien til OCR-teknologi var i 1974 da Ray Kurzweil utviklet et omni-font OCR-system som kunne gjenkjenne tekst i praktisk talt hvilken som helst skrifttype. I løpet av årene har OCR utviklet seg fra enkel malmatching til mer sofistikerte systemer.
Til tross for sine muligheter, står OCR-teknologi for tiden overfor visse begrensninger. Disse inkluderer utfordringer med å gjenkjenne tekst i bilder med dårlig kvalitet, vanskeligheter med å håndtere komplekse oppsett eller bakgrunner, og varierende nøyaktighet når det gjelder forskjellige skrifttyper, språk eller håndskrift. I tillegg kan OCR-systemer slite med dokumenter som har fargede bakgrunner, er uklare eller skjeve, og med kursiv håndskrift.
Forståelse av programvare for optisk tegngjenkjenning
Programvare for optisk tegngjenkjenning er en transformativ teknologi som konverterer ulike typer dokumenter til redigerbare og søkbare data. Den spiller en avgjørende rolle i digitaliseringen av vår verden, noe som gjør informasjon mer tilgjengelig og håndterbar. OCR-programvare bruker en sofistikert prosess for å konvertere bilder av tekst til maskinlesbare data.
Hvordan OCR-programvare fungerer
1. Bildeinnhenting
Reisen til OCR begynner med å fange et bilde av dokumentet. Dette kan gjøres gjennom en skanner eller et digitalkamera. Bildet blir deretter oversatt til et digitalt format som en datamaskin kan prosessere.
2. Forbehandling og bildeforbedring
Det andre trinnet involverer å forbedre bildekvaliteten. Når bildet er innhentet, gjennomgår det forbehandling for å forbedre kvaliteten for bedre gjenkjenning. Dette trinnet kan innebære justering av kontrast, lysstyrke og skarphet i bildet, samt fjerning av støy eller irrelevante elementer. Denne forbehandlingsfasen er avgjørende for å oppnå nøyaktige resultater, spesielt når man arbeider med lavkvalitets skanninger eller fotografier.
3. Tekstdeteksjon
OCR-programvaren analyserer det forbehandlede bildet for å oppdage områder som inneholder tekst. Den gjør dette ved å se etter mønstre og former som er karakteristiske for tekst, som linjer med forskjellige tykkelser og høyder.
4. Tegnsegmentering
Når tekstområder er oppdaget, bryter programvaren ned teksten i mindre enheter, som blokker, linjer, ord eller til og med individuelle tegn. OCR-programvaren analyserer bildet piksel for piksel for å identifisere mønstre som danner tegn. Den deler opp bildet i mindre segmenter, isolerer hvert tegn.
5. Tekstgjenkjenning og ekstraksjon
Programvaren sammenligner deretter disse isolerte formene med en omfattende database av kjente tegnmønstre for å bestemme hva hvert tegn er. Programvaren trekker ut funksjoner fra tegnene, som antall linjer, kurver eller vinkler. Disse funksjonene hjelper OCR med å gjenkjenne og skille mellom forskjellige tegn.
6. Etterbehandling
Etter at tegnene er identifisert, går OCR-systemet gjennom en etterbehandlingsfase hvor det retter opp eventuelle potensielle feil og formaterer teksten for utdata. Den korrigerte teksten eksporteres deretter til ønsket format, som et Word-dokument eller en søkbar PDF.
Bruksområder med programvare for optisk tegngjenkjenning
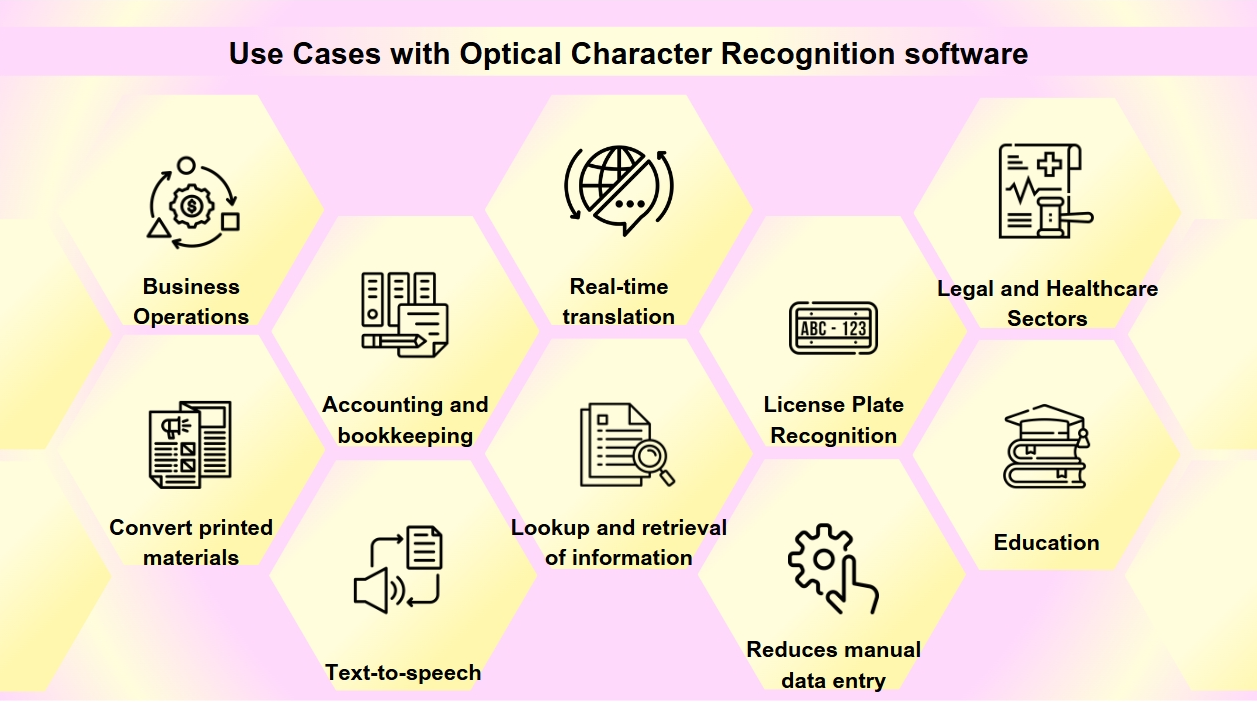
OCR har blitt et essensielt verktøy i den digitale transformasjonen av mange industrier, som strømlinjeformer prosesser og forbedrer datatilgjengelighet og nøyaktighet. Du kan støte på OCR oftere enn du innser. Fra skanning av visittkort til digitalisering av gamle bøker, spiller OCR en avgjørende rolle i ulike industrier. OCR-teknologi har et bredt spekter av applikasjoner:
-
Dokumentdigitalisering: OCR brukes til å konvertere trykte materialer som gamle bøker, aviser og historiske dokumenter til digitale formater, noe som gjør dem søkbare og bevarer dem for fremtidige generasjoner.
-
Skjemabehandling: Bedrifter utnytter OCR for automatisk å trekke ut data fra skjemaer, noe som reduserer manuell datainntasting og øker effektiviteten i ulike sektorer som finans og helsevesen.
-
Faktura behandling: OCR-teknologi kan lese tekst på fakturaer og automatisk legge inn dataene i finanssystemer, noe som strømlinjeformer regnskap og bokføring.
-
Tilgjengelighet: OCR muliggjør tekst-til-tale-funksjonalitet, og lager lydversjoner av tekst for synshemmede, og gjør dermed trykte materialer mer tilgjengelige.
-
Mobilapplikasjoner: OCR er integrert i apper for oppgaver som å skanne visittkort, gjenkjenne tekst i bilder og legge til rette for sanntidsoversettelse.
-
Søkbarhet: OCR forbedrer søkbarheten til skannede dokumenter ved å trekke ut tekst fra bilder eller PDF-filer, noe som gjør det enkelt å se opp og hente informasjon.
-
Registrering av bilskilt: Brukt for parkering og trafikkstyring, kan OCR gjenkjenne bilskilt, noe som muliggjør effektiv overvåking og håndheving.
-
Forretningsdrift: OCR strømlinjeformer forretningsprosesser ved å automatisere datainntasting fra dokumenter som fakturaer, kvitteringer og innkjøpsordrer, samt fremskynde rekruttering ved å skanne og behandle jobbsøknader og CV-er.
-
Juridiske og helsesektorer: Advokatfirmaer bruker OCR for å digitalisere sakspapirer og juridiske dokumenter for enklere informasjonsinnhenting, mens helsepersonell utnytter det til å konvertere pasientjournaler og medisinske skjemaer til elektroniske helsedokumenter (EHR), noe som forbedrer databehandling og pasientbehandling.
-
Utdanning: I utdanningsmiljøer brukes OCR til å lage digitale lærebøker og læringsmaterialer, noe som forbedrer tilgjengeligheten for studenter med ulike behov og støtter et inkluderende læringsmiljø.
Etter hvert som OCR-teknologien utvikler seg, fortsetter den å spille en viktig rolle i å gjøre informasjon mer tilgjengelig og effektiv å håndtere i den digitale tidsalderen.
Ulempene med OCR: Begrensninger og ulemper
Nøyaktighetsutfordringer
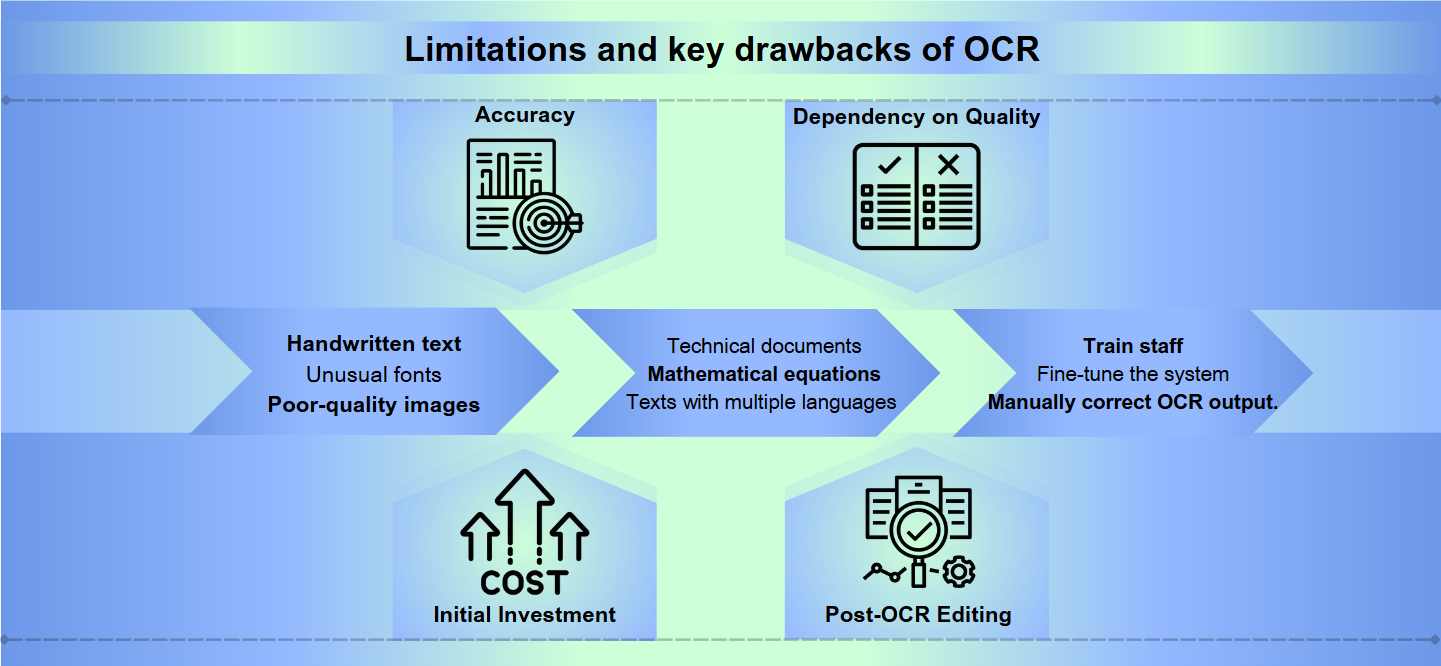
Selv om optisk tegngjenkjenning (OCR) teknologi har kommet langt, står den fortsatt overfor betydelige hindringer for å oppnå perfekt nøyaktighet. Håndskrevet tekst, uvanlige skrifttyper eller bilder av dårlig kvalitet kan føre til feiltolkninger og feil. Selv små variasjoner i tegnformer eller størrelser kan forvirre OCR-systemer, noe som resulterer i uleselig utdata som krever manuell korrigering.
Språk- og formatbegrensninger
De fleste OCR-løsninger utmerker seg med standard språk og formater, men sliter med spesialisert innhold. Tekniske dokumenter, matematiske ligninger eller tekster med flere språk kan utgjøre betydelige utfordringer. I tillegg kan OCR feile når den konfronteres med komplekse oppsett, tabeller eller dokumenter med intrikate formateringer, noe som potensielt kan miste viktig strukturell informasjon.
Ressursintensitet
Implementering og vedlikehold av et effektivt OCR-system kan være ressurskrevende. Høy-kvalitets OCR-programvare kommer ofte med en høy prislapp, og maskinvaren som kreves for å prosessere store mengder dokumenter kan være kostbar. Videre kan tiden og innsatsen som trengs for å trene ansatte, finjustere systemet og manuelt gjennomgå og korrigere OCR-utdata, belaste organisasjonens ressurser.
Nøkkelulemper med OCR
-
Nøyaktighet: OCR-programvare kan slite med nøyaktighet, spesielt når den håndterer bilder av dårlig kvalitet, komplekse oppsett eller håndskrevet tekst. Feil kan variere fra å misforstå tegn til å hoppe over hele tekstseksjoner.
-
Avhengighet av kvalitet: Effektiviteten til OCR er sterkt avhengig av kvaliteten på det opprinnelige dokumentet. Utydelig blekk, smuss eller krøllete papir kan føre til unøyaktige oversettelser.
-
Innledende investering: Å sette opp et OCR-system kan kreve betydelige forhåndskostnader, inkludert ikke bare programvaren, men også kompatibel maskinvare som skannere.
-
Etter-OCR-redigering: Ofte krever utdata fra OCR-prosesser manuell gjennomgang og korrigering, noe som kan være tidkrevende.
Vision Language Model overvinne OCRs begrensninger
Etter hvert som teknologien utvikler seg, dukker det opp innovative løsninger for å adressere svakhetene ved tradisjonell optisk tegngjenkjenning (OCR). Et slikt gjennombrudd er Vision Language Model (VLM), som kombinerer datamaskinsyn og naturlig språkbehandling for å revolusjonere tekstutvinning og forståelse.
Forbedret kontekstuell forståelse
VLM-er utmerker seg i å forstå konteksten rundt tekst, i motsetning til OCRs isolerte tegngjenkjenning. Ved å analysere visuelle elementer sammen med tekst, kan disse modellene tolke komplekse oppsett, håndskrevne notater og til og med delvis skjult tekst med bemerkelsesverdig nøyaktighet.
Flerspråklige og multimodale kapabiliteter
Mens OCR ofte sliter med ulike språk og skrifter, viser VLM-er imponerende allsidighet. De kan sømløst prosessere flere språk og til og med tolke visuelt innhold som diagrammer eller grafer, noe som gir en mer omfattende forståelse av dokumenter.
Adaptiv læring og kontinuerlig forbedring
I motsetning til statiske OCR-systemer, utnytter VLM-er maskinlæring for å tilpasse seg og forbedre seg over tid. Når de møter nye data og scenarier, finjusterer disse modellene ytelsen sin, og blir stadig mer dyktige til å håndtere ulike dokumenttyper og formater.
Ved å overvinne OCRs begrensninger baner Vision Language Models vei for mer nøyaktig, effektiv og intelligent dokumentbehandling på tvers av industrier.
Velg Vision Language Model: Prøv AnyParser
Bygget på fremskrittene til Vision Language Models (VLM), fremstår AnyParser som en sofistikert løsning som overskrider begrensningene til tradisjonell OCR-teknologi. Utviklet av CambioML-teamet, er AnyParser et kraftig dokumentparseringsverktøy som bruker et presist og konfigurerbart API for å trekke ut informasjon fra ulike ustrukturerte datakilder som PDF-er, bilder og diagrammer, og konvertere dem til strukturerte formater.
Teknisk grunnlag og kapabiliteter
AnyParser er forankret i det robuste grunnlaget til store språkmodeller (LLM), som sikrer høy nøyaktighet i tekst-, tabell-, diagram- og layoututvinning fra dokumenter. Den skiller seg ut med sin evne til å opprettholde det opprinnelige oppsettet og formatet, en funksjon som er spesielt gunstig for dokumenter med komplekse oppsett eller de som krever bevaring av den opprinnelige estetikken.
Personvern og sikkerhet
Med fokus på brukerens personvern, prosesserer AnyParser data lokalt, og beskytter dermed sensitiv informasjon. Denne funksjonen er en betydelig fordel for bedrifter og enkeltpersoner som håndterer konfidensielle data.
Tilpasningsevne og fleksibilitet
Med en høy grad av konfigurerbarhet lar AnyParser brukere sette tilpassede utvinningsregler og definere utdataformater som passer deres spesifikke behov. Denne tilpasningsevnen gjør det til et ideelt verktøy for et bredt spekter av applikasjoner, fra AI-ingeniørarbeid til finansanalyse.
Konklusjon
Som du har lært, tilbyr OCR-teknologi kraftige muligheter for digitalisering av tekst, men den er ikke uten begrensninger. Selv om optisk tegngjenkjenning kan dramatisk forbedre effektiviteten, må du nøye vurdere de potensielle ulempene. Vurder nøyaktighetsproblemene, formateringsutfordringene og ressurskravene før du implementerer en OCR-løsning. Til syvende og sist avhenger beslutningen om å bruke OCR av dine spesifikke behov og omstendigheter. Ved å forstå både fordelene og ulempene kan du ta et informert valg om hvorvidt OCR er riktig for din organisasjon. Etter hvert som OCR fortsetter å utvikle seg, hold deg oppdatert på nye utviklinger som kan adressere nåværende svakheter og låse opp enda større potensial for denne transformative teknologien.
Oppfordring til handling
Omfavn kraften til Vision Language Models ved å prøve AnyParser gratis for å konvertere PDF-ene dine til Google Sheets på https://www.cambioml.com/sandbox. Få en gratis konsultasjon om hvordan VLM-er kan forbedre arbeidsflyten din for datautvinning.