I dagens digitale tidsalder har datasikkerhet blitt en avgjørende bekymring, spesielt med den økende bruken av AI og automatisering i dokumentbehandling. Dokumentparsering, en kritisk komponent av datautvinning, gjør det mulig for bedrifter å effektivt håndtere og utnytte store mengder informasjon.
IDP intelligent dokumentbehandling revolusjonerer måten bedrifter håndterer datautvinning fra dokumenter. Svaret på hva intelligent dokumentbehandling er, er at IDP er en avansert teknologi som automatiserer utvinning og klassifisering av data fra dokumenter. IDP-teknologi har blitt uunnværlig for bedrifter som ønsker å automatisere og sikre sin dokumentparsering.

Forståelse av sensitiv data i dokumentparsering
Sensitiv data i dokumentparsering refererer til informasjon som potensielt kan identifisere enkeltpersoner, avsløre personlige egenskaper eller forårsake skade hvis den misbrukes eller avsløres uten samtykke. Dette inkluderer et bredt spekter av datatyper, hver med unike implikasjoner for personvern og sikkerhet. Adopsjonen av IDP-teknologi er avgjørende for å opprettholde konfidensialiteten og integriteten til sensitiv data.
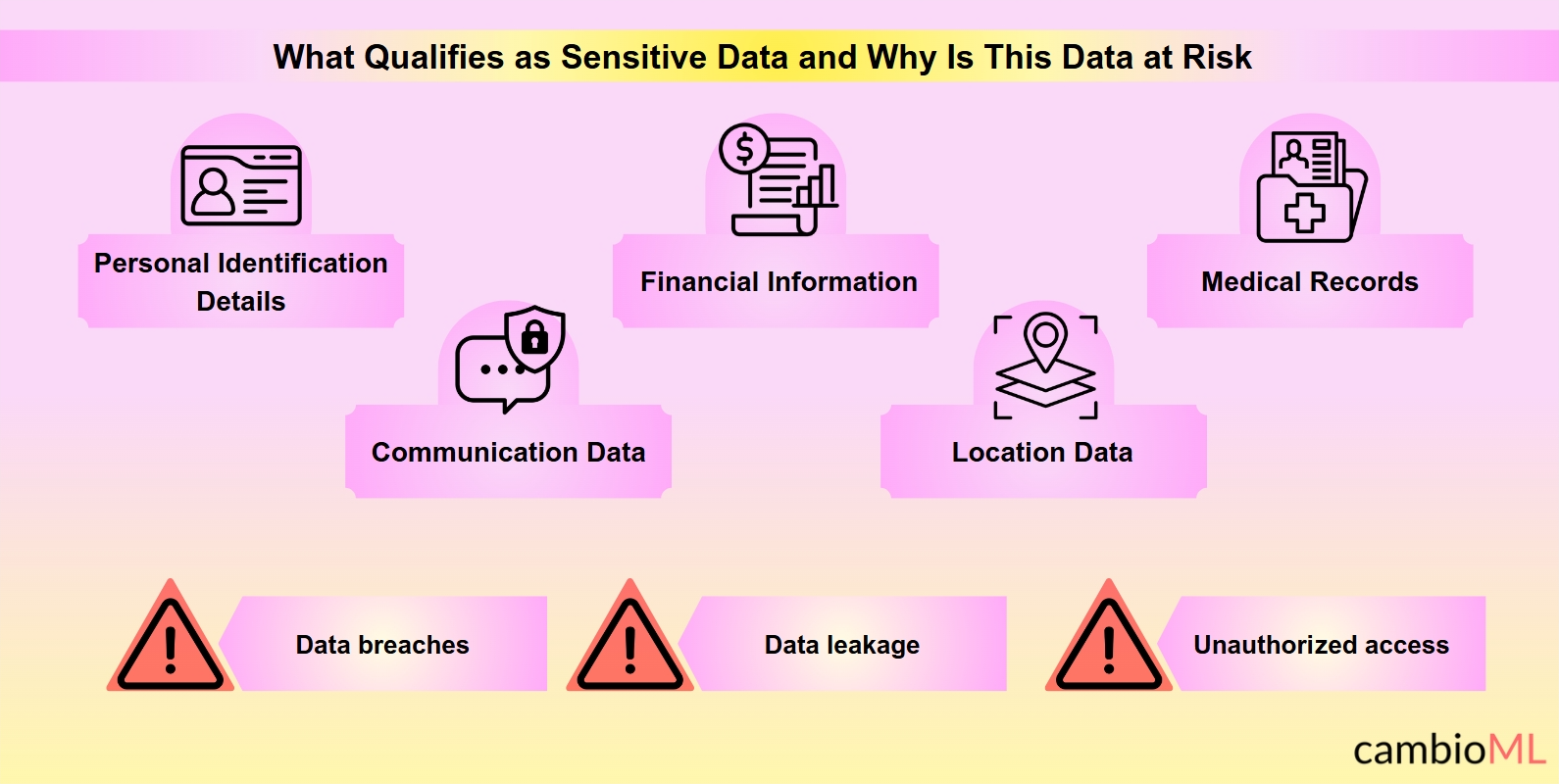
Hva kvalifiserer som sensitiv data?
-
Personidentifikasjonsdetaljer: Dette inkluderer personnummer, førerkortnumre, passnumre og andre unike identifikatorer som kan identifisere en enkeltperson. For eksempel krever dokumenter som inneholder personidentifikasjonsdetaljer nøye håndtering for å forhindre identitetstyveri og svindel.
-
Finansiell informasjon: Denne kategorien omfatter bankkontonumre, kredittkortdetaljer og transaksjonsopptegnelser. Eksponering av slik data kan føre til økonomisk tap og misbruk av midler, noe som understreker behovet for strenge sikkerhetskontroller under parseringsprosesser.
-
Medisinske journaler: Beskyttet helseinformasjon (PHI) som pasienthistorier, diagnoser og behandlingsplaner faller inn under denne kategorien. Feil håndtering av medisinske journaler kan føre til brudd på pasientkonfidensialitet og personvern, med alvorlige etiske og juridiske konsekvenser.
-
Kommunikasjonsdata: Dette inkluderer personlig korrespondanse som kan avsløre konfidensielle forretningsforhandlinger eller sensitive personlige diskusjoner. Parsering av e-poster eller meldingsutskrifter må sikre at slik data ikke blir eksponert eller feilbehandlet.
-
Plasseringdata: Geolokasjonsinformasjon som kan peke ut en enkeltpersons bevegelser eller bosted, spesielt når den kombineres med annen data, kan være sensitiv. Parsering av dokumenter som inneholder reiseplaner eller hjemmeadresser krever spesiell oppmerksomhet til personvernhensyn.
Hvorfor er denne dataen i fare?
En IDP-løsning gir en omfattende tilnærming til å håndtere kompleksiteten i dokumentparsering. Å forstå hva intelligent dokumentbehandling er, er essensielt for bedrifter som ønsker å forbedre sine databehandlingsmuligheter. Sensitiv data er i fare under dokumentparsering på grunn av flere sårbarheter:
- Datainnbrudd: Uautorisert tilgang til sensitiv informasjon kan forekomme hvis sikkerhetstiltakene er utilstrekkelige.
- Datalekkasje: Sensitiv informasjon kan utilsiktet bli eksponert under utvinnings- eller behandlingsfasene.
- Uautorisert tilgang: Uten riktige tilgangskontroller kan sensitiv data bli tilgjengelig for ubetrodde parter.
Nøkkelutfordringer innen personvern og sikkerhet i dokumentparsering
Dokumentparsering involverer utvinning av strukturert data fra ustrukturerte eller semi-strukturerte dokumenter, noe som kan eksponere sensitiv informasjon for ulike risikoer hvis det ikke håndteres sikkert. Med en IDP-løsning på plass kan organisasjoner redusere risikoene knyttet til brudd på sensitiv data. Bruken av verktøy for intelligent dokumentbehandling kan betydelig redusere risikoen for datalekkasje og uautorisert tilgang.
Risikoer ved datautvinning
En av de primære utfordringene er risikoen for datalekkasje under utvinningsprosessen. Sensitiv data kan utilsiktet bli eksponert hvis dokumenter ikke blir riktig renset eller hvis utvinningsverktøy mangler nødvendige sikkerhetstiltak. For eksempel kan parseringsverktøy som ikke skjuler personidentifikasjonsdetaljer før behandling føre til utilsiktet avsløring av personnummer eller finansiell informasjon.
Lagring og tilgangsstyring
Sensitiv data som er utvunnet fra dokumenter må ofte lagres for videre analyse eller arkivering. Imidlertid kan feil lagringspraksis, som utilstrekkelig kryptering eller utilstrekkelige tilgangskontroller, føre til uautorisert tilgang. For eksempel, hvis utvunnet data lagres i en database uten riktig kryptering, kan det være sårbart for brudd, noe som potensielt eksponerer sensitiv finansiell eller medisinsk informasjon.
Juridisk samsvar
Reguleringer som GDPR og HIPAA pålegger strenge krav til hvordan sensitiv data skal håndteres, inkludert under dokumentparsering. Manglende overholdelse kan resultere i betydelige juridiske og økonomiske straffer. For eksempel, under GDPR, må organisasjoner sørge for at personopplysninger behandles på en måte som sikrer passende sikkerhet, inkludert beskyttelse mot uautorisert eller ulovlig behandling og mot utilsiktet tap, ødeleggelse eller skade.
Viktige beste praksiser for personvern og sikkerhet i dokumentparsering
For å redusere utfordringene knyttet til dokumentparsering er det avgjørende å implementere beste praksiser som prioriterer personvern og sikkerhet. IDP-teknologi, med sine avanserte funksjoner, spiller en avgjørende rolle i å sikre personvernet og sikkerheten til dokumentparsering. Nøyaktigheten til VLM har forbedret seg dramatisk sammenlignet med OCR-faktura skanning, noe som reduserer behovet for manuell dataregistrering.
Datasikkerhetskryptering
Kryptering er et kritisk tiltak for å beskytte sensitiv data både under transport og i ro. Ved å implementere IDP intelligent dokumentbehandling kan selskaper strømlinjeforme driften og forbedre datanøyaktigheten. Bruken av en Python PDF-parser kan effektivisere prosessen med dokumentparsering, og sikre raskere og mer nøyaktig datautvinning.
Anonymisering og pseudonymisering
Anonymisering innebærer å fjerne all identifiserbar informasjon fra data, noe som gjør det umulig å spore tilbake til en enkeltperson. Pseudonymisering erstatter identifikatorer med kunstige, noe som reduserer risikoen for re-identifikasjon. Disse teknikkene er essensielle når man parser dokumenter som inneholder personopplysninger for å sikre samsvar med personvernreguleringer som GDPR, som understreker prinsippet om dataminimering.
Tilgangskontroller og revisjonslogger
Implementering av strenge tilgangskontroller og vedlikehold av revisjonslogger er avgjørende for å håndtere hvem som kan få tilgang til sensitiv data. Tilgang bør gis på et behov-for-å-vite grunnlag, og all tilgang bør loggføres og overvåkes. For eksempel kan rollebasert tilgangskontroll (RBAC) sikre at kun autorisert personell kan få tilgang til sensitiv data, og revisjonslogger kan hjelpe med å spore eventuelle forsøk på uautorisert tilgang.
Regelmessige sikkerhetsrevisjoner
Regelmessige sikkerhetsrevisjoner kan hjelpe med å identifisere sårbarheter i dokumentparseringsprosessen. Disse revisjonene bør inkludere penetrasjonstesting, kodegjennomganger og sårbarhetsvurderinger. For eksempel kan det å engasjere en tredjepart for å gjennomføre en red-teaming-øvelse hjelpe med å avdekke potensielle svakheter i parseringssystemet som kan utnyttes av angripere. Ved å implementere disse beste praksisene kan organisasjoner betydelig redusere risikoen for databrudd og sikre samsvar med databeskyttelsesreguleringer, og dermed beskytte både driften og personvernet til enkeltpersonene hvis data de håndterer.
AnyParser i dokumentparsering: Forbedring av personvern og sikkerhet
Verktøy for intelligent dokumentbehandling er designet for å utvinne, analysere og håndtere data med høy presisjon. AnyParser, utviklet av CambioML-teamet, skiller seg ut som et robust dokumentparseringsverktøy som adresserer de viktigste personvern- og sikkerhetsutfordringene i dokumentparsering med sitt unike sett av funksjoner og kapabiliteter.
Strukturert utdata og lokal behandling
AnyParser konverterer utvunnet informasjon til strukturerte formater som Markdown, noe som letter videre databehandling og analyse. Dets lokale behandlingsfunksjon sikrer at sensitiv data aldri forlater brukerens lokaler, noe som betydelig reduserer risikoen for databrudd. En Python PDF-parser er et essensielt verktøy for utviklere som ønsker å automatisere utvinning av data fra PDF-dokumenter.
Teknologiske fordeler
AnyParser utnytter store språkmodeller (LLM) for dokumentforståelse og informasjonsutvinning, noe som ikke bare forbedrer nøyaktigheten, men også forbedrer sikkerheten ved å redusere behovet for manuell databehandling. Dets modulbaserte design gjør det enkelt å utvide og tilpasse, og imøtekomme utviklende forretningsbehov.
AI og ML i dokumentbeskyttelse
Kunstig intelligens (AI) og maskinlæring (ML) kan forbedre sikkerheten ved dokumentparsering ved å automatisere samsvarskontroller og identifisere potensielle databrudd. Disse teknologiene kan analysere store mengder data raskt og nøyaktig, og sikre at sensitiv informasjon er beskyttet. For eksempel er VLM fakturaskanning, som er bedre enn OCR fakturaskanning, en nøkkelkomponent i intelligent dokumentbehandling, og muliggjør automatisk utvinning av fakturadata.
Reguleringsoverholdelse og dens rolle i datasikkerhet
Oversikt over nøkkelreguleringer
Nøkkelreguleringer som GDPR og HIPAA setter strenge krav til håndtering av sensitiv data. GDPR fokuserer på beskyttelse av personopplysninger innen EU, mens HIPAA setter standarder for beskyttelse av helseopplysninger i USA.
Konsekvenser for bedrifter
Manglende overholdelse av disse reguleringene kan resultere i store bøter og juridiske tiltak. Derfor må bedrifter prioritere sikker dokumentparsering for å sikre at de oppfyller alle regulatoriske krav og beskytter kundenes data. Integrasjonen av IDP intelligent dokumentbehandlingsverktøy sikrer samsvar med databeskyttelsesreguleringer.
Fremtidige trender innen personvern og sikkerhet for dokumentparsering
Fremskritt innen AI og sikker databehandling
Fremtidige trender inkluderer fremskritt innen AI og sikre databehandlingsteknologier, som kvantekryptering og personvernsforbedrende teknologier (PET). Disse innovasjonene lover å gi enda sterkere sikkerhetstiltak for å beskytte sensitiv data. For bedrifter som håndterer store mengder PDF-dokumenter, tilbyr en Python PDF-parser en skalerbar løsning for dokumentbehandling. Verktøy for intelligent dokumentbehandling, som AnyParser, er i forkant av innovasjon innen dataprivacy og sikkerhet.
Kontinuerlig tilpasning til utviklende trusler
Landskapet av cybertrusler er i konstant utvikling. Bedrifter må holde seg oppdatert med nye sikkerhetspraksiser og kontinuerlig tilpasse seg nye trusler for å sikre den pågående beskyttelsen av sensitiv data.
Konklusjon
Å beskytte sensitiv data i dokumentparsering er av største betydning. Ved å adoptere beste praksiser, utnytte avanserte teknologier og sikre regulatorisk samsvar, kan bedrifter sikre sine data og opprettholde tilliten til kundene sine. Å prioritere datasikkerhet beskytter ikke bare selskapet, men sikrer også personvernet og sikkerheten til enkeltpersonene hvis data som behandles.
Oppfordring til handling: Omfavn AnyParser for sikker dokumentparsering
For å sikre sensitiv data og strømlinjeforme dokumentparseringsprosessene dine, vurder å ta i bruk AnyParser. Dette kraftige verktøyet tilbyr en omfattende pakke med funksjoner designet for å forbedre både sikkerheten og effektiviteten i databehandlingspraksisene dine. Besøk AnyParser sin sandkasse for å teste funksjonene gratis og se hvordan det kan gagne organisasjonen din. Ta det første steget mot en mer sikker og samsvarende dokumentparseringsstrategi i dag.