Hva er Strukturert Data og Ustrukturert Data
I den digitale informasjonsalderen genereres data til enhver tid, og bedrifter skaper verdi gjennom analyse og behandling av data. Derfor har innsamling og registrering av data samt behandling og analyse av data blitt to viktige oppgaver i forretningsdrift. I prosessen med datainnsamling møter man oftere ustrukturert data; kilden og formen til disse dataene er mangfoldige, og det er vanskelig å klassifisere eller søke i dem enkelt. Effektivt datainntak er avgjørende for at organisasjoner skal kunne transformere rådata til handlingsbare innsikter. I prosessen med databehandling er det strukturert data som oftest møter en, som har en klar struktur, veldefinert informasjon, og kan enkelt organiseres, søkes i og analyseres. Derfor er det en viktig oppgave for bedrifter å transformere ustrukturert data til strukturert data for å utnytte dataverdien.
Strukturert Data
Strukturert data er data som passer inn i en forhåndsdefinert datamodell eller skjema. Det er spesielt nyttig for å håndtere diskrete, numeriske data som finansielle operasjoner, salgs- og markedsføringsfigurer, og vitenskapelig modellering.
Strukturert data er typisk kvantitativt og organisert på en måte som gjør det lett søkbart. Det inkluderer vanlige typer som navn, adresser, kredittkortnumre, telefonnumre, stjernerangeringer, bankinformasjon og annen data som enkelt kan forespørres ved hjelp av SQL i relasjonsdatabaser.
Eksempler på strukturert data i virkelige applikasjoner inkluderer fly- og reservasjonsdata når man bestiller en flyreise, samt kundeadferd og preferanser i CRM-systemer som Salesforce. Det er best for tilknyttede samlinger av diskrete, korte, ikke-kontinuerlige numeriske og tekstverdier og brukes til lagerkontroll, CRM-systemer og ERP-systemer.
Strukturert data lagres i relasjonsdatabaser, grafdatabaser, romlige databaser, OLAP-kuber og mer. Den største fordelen er at det er lettere å organisere, rense, søke i og analysere, men hovedutfordringen er at alle data må passe inn i den foreskrevne datamodellen.
Ustrukturert Data
Ustrukturert data er data uten en underliggende modell for å skille attributter. Det brukes når dataene ikke passer inn i et strukturert dataformat, som videomonitorering, bedriftsdokumenter og innlegg på sosiale medier.
Eksempler på ustrukturert data inkluderer en rekke formater som e-poster, bilder, videofiler, lydfiler, innlegg på sosiale medier, PDF-filer og mer. Omtrent 80-90% av dataene er ustrukturerte, noe som betyr at de har stort potensial for konkurransefortrinn hvis selskaper kan utnytte dem.
Eksempler på ustrukturert data i virkelige applikasjoner inkluderer chatboter som utfører tekstanalyse for å svare på kundespørsmål og gi informasjon, samt data som brukes til å forutsi endringer i aksjemarkedet for investeringsbeslutninger. Ustrukturert data er best for tilknyttede samlinger av data, objekter eller filer der attributtene endres eller er ukjente, og det brukes med presentasjons- eller tekstbehandlingsprogramvare og verktøy for å vise eller redigere medier. Ustrukturert supplerende tjenestedata, som innlegg på sosiale medier og kundetilbakemeldinger, kan gi verdifulle innsikter når de konverteres til strukturerte formater.
Det lagres typisk i datalakes, NoSQL-databaser, datavarehus og applikasjoner. Den største fordelen med ustrukturert data er dens evne til å analysere data som ikke lett kan formes til strukturert data, men hovedutfordringen er at det kan være vanskelig å analysere. Hovedanalyseteknikken for ustrukturert data varierer avhengig av konteksten og verktøyene som brukes.
Forskjell mellom Strukturert og Ustrukturert Data
Fordeler med Strukturert Data og Ulemper med Ustrukturert Data
Strukturert data tilbyr fordelen av å være lett søkbar og brukt for maskinlæringsalgoritmer, noe som gjør det tilgjengelig for bedrifter og organisasjoner for å tolke data. Det finnes også flere verktøy tilgjengelig for å analysere strukturert data enn ustrukturert data. På den annen side krever ustrukturert data at datavitere har ekspertise i å forberede og analysere dataene, noe som kan begrense andre ansatte i organisasjonen fra å få tilgang til det. I tillegg er det nødvendig med spesielle verktøy for å håndtere ustrukturert data, noe som ytterligere bidrar til dens mangel på tilgjengelighet.
Strukturert Dataanalyse vs. Ustrukturert Dataanalyse
Strukturert dataanalyse er typisk mer rett frem fordi dataene er strengt formatert, noe som tillater bruk av programmeringslogikk for å søke etter og lokalisere spesifikke dataoppføringer, samt å opprette, slette eller redigere oppføringer. Dette gjør automatisering av datastyring og analyse av strukturert data mer effektivt. I kontrast har ustrukturert dataanalyse ingen forhåndsdefinerte attributter, noe som gjør det vanskeligere å søke i og organisere. Ustrukturert dataanalyse krever ofte komplekse algoritmer for å forbehandle, manipulere og analysere, noe som utgjør en større utfordring i analyseprosessen. Analysen av ustrukturert supplerende tjenestedata krever ofte avanserte parseringsteknikker for å trekke ut meningsfull informasjon.
Strukturert Datastyring vs. Ustrukturert Datastyring
Håndteringen av strukturert data er generelt mer effektiv på grunn av dens organiserte og forutsigbare natur. Datamaskiner, datastrukturer og programmeringsspråk kan lettere forstå strukturert data, noe som fører til minimale utfordringer i bruken. På den annen side presenterer ustrukturert datastyring to betydelige utfordringer: lagring, ettersom ustrukturert datastyring vanligvis står overfor større behandling enn strukturert datastyring, og analyse, ettersom ustrukturert datastyring ikke er så rett frem som analysen av strukturert datastyring. For å forstå og håndtere ustrukturert data må datasystemer først bryte det ned i forståelige komponenter, noe som er en mer kompleks prosess.
Oppsummering av Forskjellen mellom Strukturert og Ustrukturert Data
Strukturert data er definert og søkbar, inkludert data som datoer, telefonnumre og produkt-SKUer. Dette gjør det lettere å organisere, rense, søke i og analysere sammenlignet med ustrukturert data, som omfatter alt annet som er vanskeligere å kategorisere eller søke i, som bilder, videoer, podcaster, innlegg på sosiale medier og e-poster. En setning for å forklare forskjellen mellom strukturert og ustrukturert data: Det meste av dataene i verden er ustrukturert, men strukturert datas letthet i håndtering og analyse gir det en betydelig fordel i applikasjoner der data kan organiseres pent og raskt aksesseres.
Eksempler på Strukturert og Ustrukturert Data
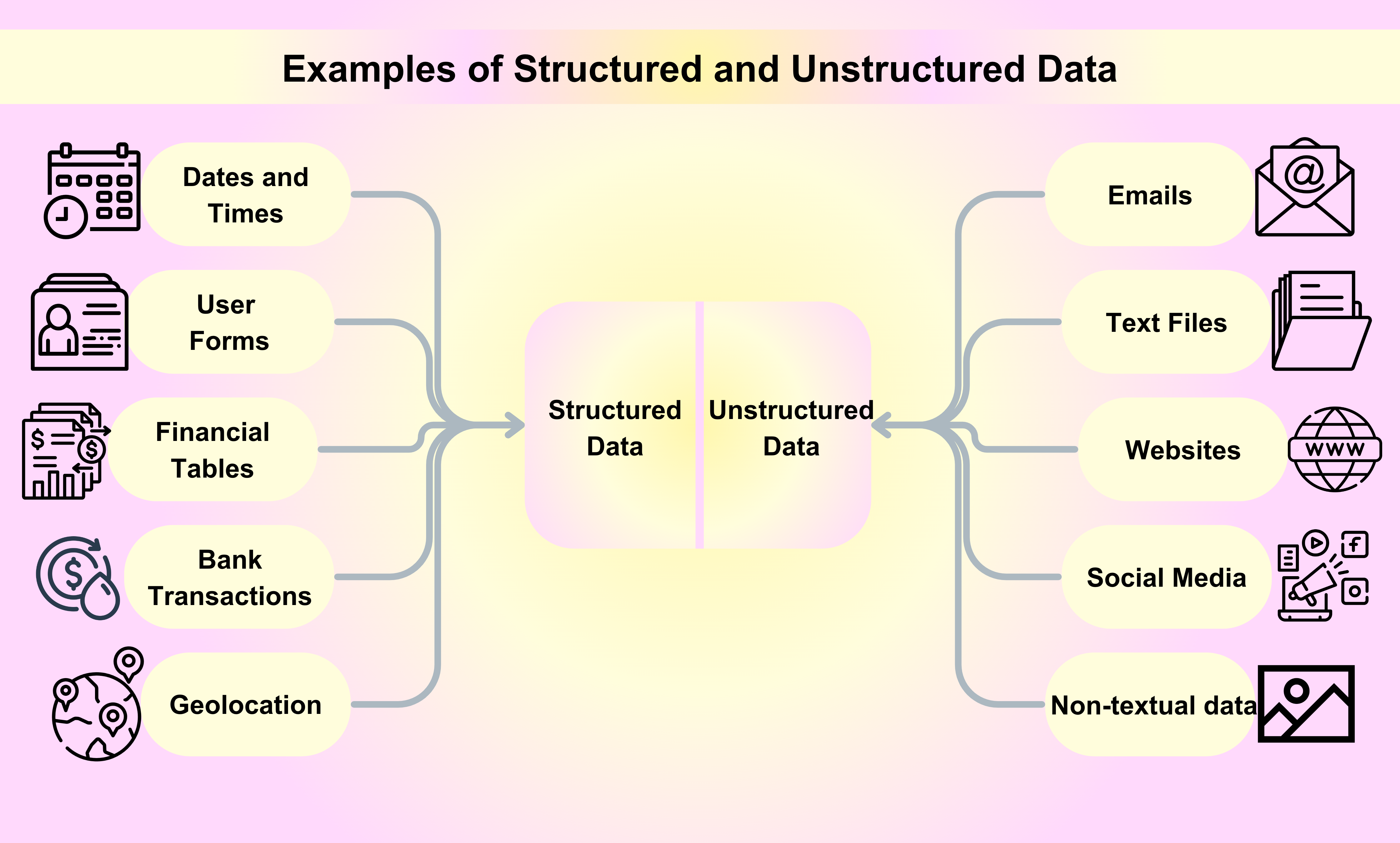
Eksempler på Strukturert Data
-
Datoer og Tidspunkter: Datoer og tidspunkter følger et spesifikt format, noe som gjør det enkelt for maskiner å lese og analysere dem. For eksempel kan en dato struktureres som YYYY-MM-DD, mens et tidspunkt kan struktureres som HH:MM:SS.
-
Kundenavn og Kontaktinformasjon: Når du registrerer deg for en tjeneste eller kjøper et produkt på nettet, samles og lagres navnet ditt, e-postadresse, telefonnummer og annen kontaktinformasjon på en strukturert måte.
-
Finansielle Transaksjoner: Finansielle transaksjoner som kredittkorttransaksjoner, bankinnskudd og pengeoverføringer er alle eksempler på strukturert data. Hver transaksjon kommer med spesifikk informasjon i form av et serienummer, en transaksjonsdato, beløpet og partene involvert.
-
Aksjeinformasjon: Aksjeinformasjon som aksjekurser, handelsvolumer og markedsverdi er et annet eksempel på strukturert data. Denne informasjonen er systematisk organisert og oppdatert i sanntid.
-
Geolokasjon: Geolokasjonsdata, inkludert GPS-koordinater og IP-adresser, brukes ofte i ulike applikasjoner, fra navigasjonssystemer til markedsføringskampanjer basert på plassering.
Eksempler på Ustrukturert Data
-
E-poster: E-poster er blant de mest populære eksemplene på ustrukturert data vi bruker hver dag til forretnings- eller personlige formål.
-
Tekstfiler: Eksempler på ustrukturert data inkluderer tekstbehandlingsfiler, regneark, PDF-filer, rapporter og presentasjoner.
-
Nettsteder: Innhold fra nettsteder som YouTube, Instagram og Flickr betraktes som eksempler på ustrukturert data.
-
Sosiale Medier: Data generert fra sosiale medieplattformer som Facebook, Twitter og LinkedIn er eksempler på ustrukturert data.
-
Media: Digitale bilder, lydopptak og videoer representerer en stor mengde ikke-tekstlig data på en ustrukturert måte som kan betraktes som eksempler på ustrukturert data.
Teknikker for Analyse av Strukturert Data
-
SQL-spørringer: Strukturert data kan effektivt forespørres ved hjelp av SQL (Structured Query Language), som tillater rask henting og manipulering av data lagret i relasjonsdatabaser.
-
Datavarehus: Strukturert data kan lagres i datavarehus, som integrerer data fra flere kilder og støtter komplekse forespøringer og analyser.
-
Maskinlæringsalgoritmer: Algoritmer kan enkelt prosessere strukturert data for å identifisere mønstre og lage prediksjoner.
Strukturert data er lett å forstå og manipulere, noe som gjør det tilgjengelig for et bredt spekter av brukere. Strukturert data tillater effektiv lagring, henting og analyse, noe som fremskynder beslutningsprosesser. Systemer for strukturert data kan skaleres for å håndtere store datamengder, og sikrer at ytelsen forblir høy etter hvert som dataene vokser.
Teknikker for Analyse av Ustrukturert Data
-
Naturlig Språkbehandling (NLP): NLP-teknikker brukes til å analysere tekstdata, og trekker ut meningsfull informasjon og innsikter fra store mengder ustrukturert tekst.
-
Maskinlæring: Maskinlæringsalgoritmer kan trenes til å gjenkjenne mønstre i ustrukturert data, som bilder eller lydfiler.
-
Datalakes: Ustrukturert data kan lagres i datalakes, som tillater lagring av rådata i sitt opprinnelige format inntil det er nødvendig for analyse.
Fra eksempelet på teknikker for analyse av ustrukturert data er det å analysere ustrukturert data mer komplekst og krever spesialiserte verktøy og teknikker. Behandling av ustrukturert data krever ofte betydelige datakraftressurser og lagringskapasitet. Ustrukturert data kan inneholde inkonsekvenser, feil eller irrelevant informasjon, noe som gjør det utfordrende å sikre datakvalitet. Strømlinjeforming av datainntak kan betydelig forbedre en organisasjons evne til å håndtere og analysere store datamengder.
Eksempler på Behovet for å Konvertere Ustrukturert Data til Strukturert Data
-
Analyse av Kundetilbakemeldinger: Å konvertere kundevurderinger og tilbakemeldinger fra ustrukturert tekst til strukturert data lar bedrifter utføre sentimentanalyse og identifisere trender i kundetilfredshet.
-
Medisinske Journaler: Å strukturere ustrukturerte medisinske journaler, som legenes notater og bildediagnoser, muliggjør bedre integrering med elektroniske helsesystemer (EHR) og forbedrer pasientbehandlingen.
-
Samsvar og Rapportering: Prosessen med datainntak innebærer å hente, laste og transformere data fra ulike kilder til et format som er egnet for analyse. Organisasjoner kan ha behov for å konvertere ustrukturert data til strukturerte formater for å overholde regulatoriske krav og legge til rette for nøyaktig rapportering.
-
Markedsundersøkelser: Å konvertere ustrukturert data fra undersøkelser og fokusgrupper til strukturert data hjelper med å analysere markedstrender og forbrukeradferd.
Hvordan AnyParser Kan Parse Ustrukturert Data til Strukturert Data
AnyParser, utviklet av CambioML, er et kraftig dokumentparseringsverktøy designet for å trekke ut informasjon fra ulike ustrukturerte datakilder som PDF-filer, bilder og diagrammer, og konvertere dem til strukturerte formater. Det utnytter avanserte Vision Language Models (VLMs) for å oppnå høy nøyaktighet og effektivitet i datautvinning.
Nøkkelfunksjoner
-
Presisjon: Nøyaktig trekker ut tekst, tall og symboler mens den opprettholder det opprinnelige oppsettet og formatet.
-
Personvern: Behandler data lokalt for å sikre beskyttelse av brukerens personvern og sensitiv informasjon.
-
Konfigurerbarhet: Lar brukere definere tilpassede utvinningsregler og utdataformater.
-
Flere kilder Støtte: Støtter utvinning fra ulike ustrukturerte datakilder, inkludert PDF-filer, bilder og diagrammer.
-
Strukturert Utdata: Konverterer utvunnet informasjon til strukturerte formater som Markdown, CSV eller JSON.
Trinn for å Parse Ustrukturert Data ved Bruk av AnyParser
-
Last opp Dokumentet Ditt: Begynn med å laste opp din ustrukturerte datafil (f.eks. PDF, bilde) til AnyParser sin nettgrensesnitt. Du kan dra og slippe filen din eller lime inn et skjermbilde for rask behandling.
-
Velg Uvinningsalternativer: Velg hvilken type data du ønsker å trekke ut. For eksempel, hvis du trenger å trekke ut tabeller fra en PDF, velg alternativet "Kun Tabell".
-
Behandle Dokumentet: AnyParser sin API-motor vil behandle dokumentet, nøyaktig oppdage og trekke ut den nødvendige informasjonen. Verktøyet bruker avanserte VLM-teknikker for å identifisere relevante datapunkter og konvertere dem til et strukturert format.
-
Forhåndsvis og Verifiser: Gå gjennom den uttrukne dataen ved hjelp av AnyParser sin forhåndsvisningsfunksjon. Sammenlign den første utvinningen med det opprinnelige dokumentet for å sikre nøyaktighet.
-
Last ned eller Eksporter: Når du er fornøyd med utvinningen, last ned den strukturerte datafilen (f.eks. CSV, Excel) eller eksporter den direkte til plattformer som Google Sheets for videre analyse.
Fordeler med å Bruke AnyParser
-
Effektivitet og Nøyaktighet: Automatiserer oppgaver for datautvinning, reduserer manuelt arbeid og minimerer feil.
-
Datasikkerhet: Sikrer at sensitiv informasjon behandles lokalt, i samsvar med dataprivacy-standarder.
-
Fleksibel Tilpasning: Brukere kan tilpasse utvinningsparametere og utdataformater for å passe spesifikke behov.
-
Forbedret Analytisk Fokus: Forenkler datautvinning, slik at fagfolk kan fokusere på høyere verdianalyse.
Applikasjoner
-
AI-ingeniører: Trekker ut tekst og oppsettinformasjon fra PDF-filer for å utvikle og trene AI-modeller.
-
Finansanalytikere: Trekker ut numeriske data fra PDF-tabeller for nøyaktig finansiell analyse.
-
Datavitere: Prosesserer store mengder ustrukturerte dokumenter for å avdekke innsikter og trender.
-
Bedrifter: Automatiserer behandling og analyse av ulike dokumenter, som kontrakter og rapporter, for å forbedre drifts effektiviteten.
Ved å utnytte AnyParser kan brukere transformere kompleks ustrukturert data til strukturerte, redigerbare filer, som sømløst integreres i arbeidsflytene deres for forbedret dataanalyse og -håndtering.
Konklusjon
I den digitale tidsalderen er det avgjørende for bedrifter å konvertere ustrukturert data til strukturerte formater ved hjelp av verktøy som AnyParser for å låse opp innsikter og oppnå konkurransefortrinn. AnyParser kan brukes til å parse ustrukturert supplerende tjenestedata, noe som gjør det lettere å integrere i forretningsintelligenssystemer. Ved å strømlinjeforme denne prosessen kan organisasjoner effektivt utnytte det fulle potensialet av dataene sine, noe som driver bedre beslutningstaking og strategisk planlegging.