Wprowadzenie
Tabele są fundamentem reprezentacji danych strukturalnych, szeroko stosowanym w branżach takich jak finanse, opieka zdrowotna i badania. Jednak ekstrakcja informacji tabelarycznych z formatów takich jak PDF, zeskanowane dokumenty czy obrazy pozostaje wyzwaniem z powodu różnorodnych układów i złożoności.
Sztuczna inteligencja (AI) zrewolucjonizowała przetwarzanie dokumentów, umożliwiając dokładne i efektywne rozwiązania problemów, takich jak ekstrakcja tabeli z PDF czy konwersja obrazu PNG tabeli na dane strukturalne. Dzięki zaawansowanym technikom AI, firmy mogą teraz łatwo przekształcać niestrukturalne wizualizacje w użyteczne informacje, w tym konwertować obraz na tabelę, aby bezproblemowo integrować je w procesach roboczych.
Ten blog bada, jak ekstrakcja tabel AI wspiera branże, podkreśla technologie leżące u jej podstaw i pokazuje jej potencjał do uproszczenia złożonych zadań przetwarzania dokumentów.

Wyzwania w tradycyjnej ekstrakcji tabel
Ręczna ekstrakcja danych tabelarycznych z dokumentów takich jak PDF czy obrazy jest żmudna, podatna na błędy i nieefektywna. Poniżej przedstawiono niektóre z powszechnych wyzwań związanych z tradycyjnymi metodami:
-
Złożone struktury tabel: Tabele często mają nieregularne układy, takie jak zagnieżdżone komórki, nagłówki wielowierszowe czy scalone wiersze, które są trudne do interpretacji. Tradycyjne narzędzia nie potrafią dokładnie wyodrębnić tabeli z PDF w takich scenariuszach.
-
Różnorodne formaty: Tabele występują w szerokiej gamie formatów, w tym zeskanowanych dokumentach, plikach PNG tabeli i PDF. Ekstrakcja danych z tych wymaga zaawansowanych technik rozpoznawania, które wykraczają poza proste OCR.
-
Kontekst i znaczenie: Tradycyjne systemy mają trudności z zachowaniem relacji między wierszami a kolumnami, co jest kluczowe przy konwersji obrazu na tabelę lub przetwarzaniu dużych zbiorów danych.
Te wyzwania podkreślają potrzebę inteligentnych rozwiązań, takich jak ekstrakcja tabel zasilana AI, które mogą radzić sobie z złożonymi układami i różnorodnymi formatami, zapewniając jednocześnie wysoką dokładność.
Czym jest ekstrakcja tabel AI?
Ekstrakcja tabel AI to zastosowanie technik inteligentnego przetwarzania dokumentów, które są dostosowane do identyfikacji, ekstrakcji i organizacji danych strukturalnych z tabel w różnych formatach dokumentów. W przeciwieństwie do tradycyjnych metod opartych na regułach, podejścia zasilane AI wykorzystują zaawansowane technologie do radzenia sobie z złożonymi wyzwaniami, takimi jak niestandardowe układy, scalone komórki i nagłówki wielowierszowe.
Kluczowym postępem w tej dziedzinie jest wykorzystanie modeli wizji i języka (VLM). VLM łączą moc przetwarzania wizji komputerowej i rozumienia języka naturalnego, co pozwala im interpretować zarówno elementy wizualne, jak i tekstowe w dokumencie. Ta podwójna zdolność pozwala VLM na:
- Wizualne identyfikowanie struktur tabel, nawet gdy brakuje im wyraźnego formatowania.
- Kontekstowe rozumienie treści, takie jak rozróżnianie między nagłówkami, danymi a notatkami.
- Dostosowywanie się do różnych typów dokumentów, w tym zeskanowanych obrazów, PDF i notatek ręcznych.
Dzięki wykorzystaniu VLM, ekstrakcja tabel AI stała się bardziej dokładna i wszechstronna, zdolna do obsługi dokumentów w wielu językach i wyodrębniania relacji między punktami danych, które tradycyjne metody często pomijają.
Kluczowe technologie stojące za ekstrakcją tabel AI
Ekstrakcja tabel AI opiera się na zestawie zaawansowanych technologii, które współpracują ze sobą, aby przezwyciężyć tradycyjne wyzwania. Wśród nich modele wizji i języka (VLM) wyróżniają się jako przełomowa innowacja. Poniżej przedstawiono kluczowe technologie oraz kluczową rolę VLM:
-
Optical Character Recognition (OCR): Ekstrakcja tekstu z obrazów lub zeskanowanych dokumentów. W połączeniu z VLM, wyniki OCR są ulepszane, ponieważ modele rozumieją zarówno strukturę wizualną, jak i znaczenie tekstowe.
-
Modele wizji i języka (VLM): VLM rewolucjonizują ekstrakcję tabel poprzez integrację przetwarzania danych wizualnych i językowych. Doskonale radzą sobie w:
- Rozpoznawaniu złożonych układów tabel i nieregularnych granic.
- Interpretowaniu relacji między wierszami, kolumnami i nagłówkami.
- Obsłudze tabel w różnych formatach, w tym obrazach i PDF, z wsparciem dla wielu języków. VLM umożliwiają głębsze zrozumienie kontekstowe, zapewniając, że wyodrębnione dane zachowują swoje pierwotne znaczenie i strukturę.
-
Natural Language Processing (NLP): Analizuje i organizuje wyodrębnione dane, zapewniając spójność semantyczną. VLM dodatkowo wzmacniają NLP, dostarczając wskazówki kontekstowe z wzorców wizualnych.
-
Algorytmy uczenia głębokiego: Trenują modele do wykrywania granic tabel, hierarchii komórek i wzorców w niestrukturalnych dokumentach. Gdy są wzbogacone o VLM, te algorytmy osiągają większą precyzję i elastyczność.
Podkreślając VLM, ekstrakcja tabel AI przeszła z zadania prostego pozyskiwania danych do zadania zrozumienia kontekstowego, co czyni ją nieocenioną dla branż, w których dokładność i niuanse są kluczowe.
Przykłady zastosowania ekstrakcji tabel AI
Ekstrakcja tabel zasilana AI przekształca branże, automatyzując proces ekstrakcji i organizacji danych tabelarycznych z różnych formatów dokumentów. Poniżej przedstawiono kilka znaczących przypadków użycia, gdzie inteligentna ekstrakcja tabel okazała się nieoceniona:
-
Finanse: Ekstrakcja danych strukturalnych z zestawów finansowych, faktur i raportów jest często pracochłonnym zadaniem. AI umożliwia bezproblemowe kopiowanie tabeli PDF do Excela, co przyspiesza uzgadnianie, analizę i raportowanie.
-
Opieka zdrowotna: Organizacja wyników badań klinicznych, dokumentacji pacjentów czy danych badań medycznych jest uproszczona. Na przykład, dostawcy usług zdrowotnych mogą łatwo skopiować tabelę z PDF do Excela, zapewniając, że dane są gotowe do integracji z systemami elektronicznej dokumentacji zdrowotnej (EHR).
-
Prawo: Analiza umów i ekstrakcja zorganizowanych klauzul z zagnieżdżonych tabel pomaga zespołom prawnym pracować bardziej efektywnie. Modele AI ułatwiają kopiowanie tabeli PDF do Excela, oszczędzając czas na kontrole zgodności i badaniach sądowych.
-
Badania i akademia: Naukowcy mogą szybko wyodrębniać dane z artykułów naukowych, upraszczając zadanie przenoszenia kluczowych metryk przy użyciu narzędzi do kopiowania tabeli z PDF do Excela, przygotowując zbiory danych do analizy statystycznej.
Zdolność ekstrakcji tabel AI do dokładnego przetwarzania różnorodnych formatów dokumentów rewolucjonizuje procesy robocze, ułatwiając kopiowanie, organizowanie i analizowanie danych tabelarycznych w arkuszach Excela.
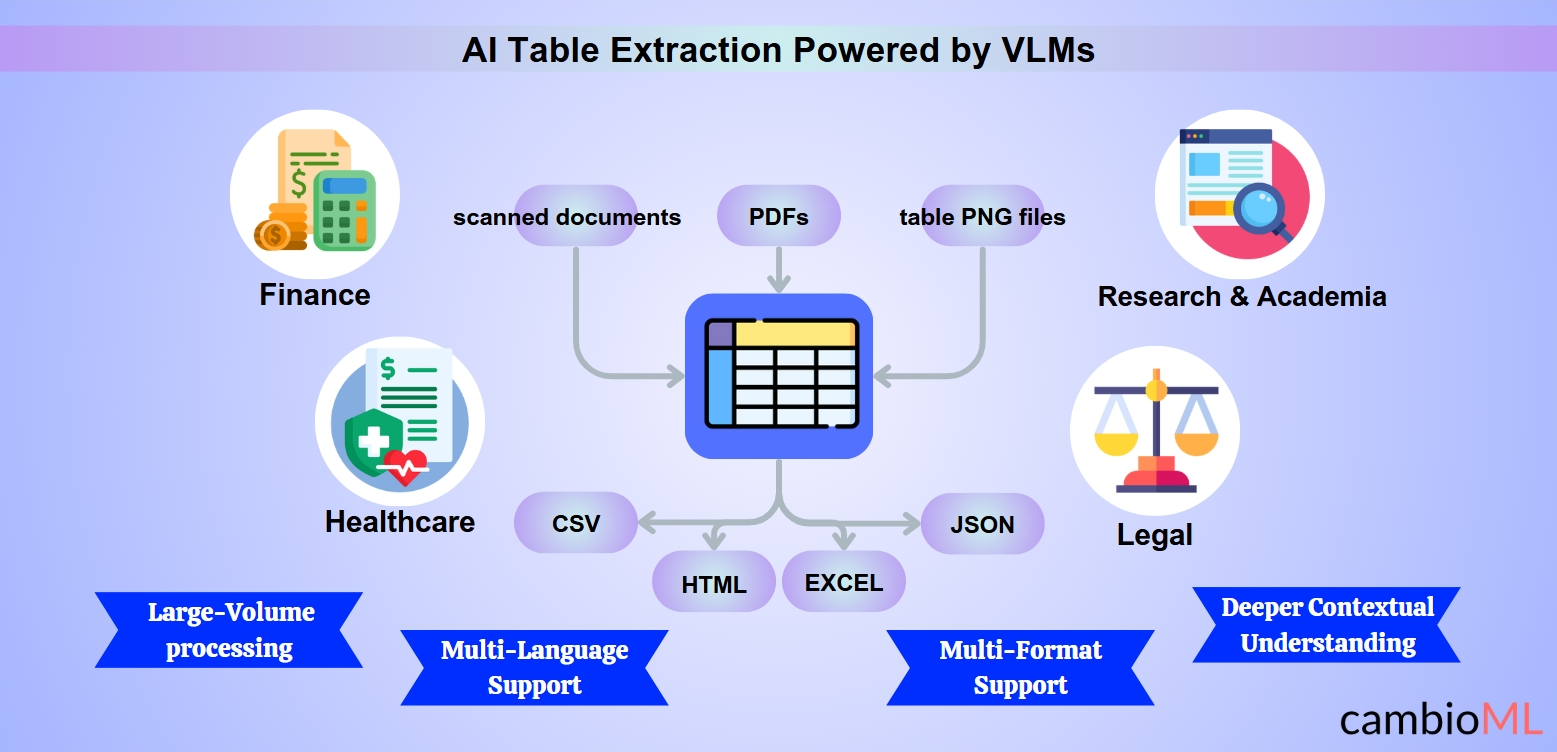
Korzyści z inteligentnej ekstrakcji tabel
Ekstrakcja tabel AI oferuje szereg korzyści, szczególnie w zakresie poprawy efektywności, dokładności i skalowalności. Dzięki wykorzystaniu zaawansowanych technologii, w tym modeli wizji i języka (VLM), firmy mogą przezwyciężyć tradycyjne wyzwania w ekstrakcji tabel:
-
Automatyzacja i oszczędność czasu: Powtarzalne zadania, takie jak ręczne kopiowanie tabel z PDF do Excela, są eliminowane, co pozwala pracownikom skupić się na bardziej wartościowych działaniach.
-
Poprawiona dokładność: Modele AI znacznie redukują błędy, które są powszechne, gdy użytkownicy ręcznie kopiują tabelę PDF do Excela lub polegają na podstawowych narzędziach. Te modele zapewniają, że dane zachowują swoją strukturę i znaczenie.
-
Skalowalność dla przetwarzania dużych wolumenów: Narzędzia AI są zaprojektowane do obsługi masowej ekstrakcji danych. Niezależnie od tego, czy są to rekordy finansowe, dokumenty badawcze czy pliki zgodności, upraszczają proces ekstrakcji i organizacji danych w Excelu.
-
Wsparcie dla wielu formatów i języków: Inteligentne systemy mogą przetwarzać dokumenty w różnych formatach i językach, umożliwiając bezproblemową ekstrakcję i kopiowanie tabeli z PDF do Excela, nawet w złożonych, wielojęzycznych kontekstach.
Ekstrakcja tabel AI nie tylko upraszcza procesy robocze, ale także zapewnia integralność kontekstową danych, przekształcając sposób, w jaki branże zajmują się informacjami tabelarycznymi. Ta efektywność jest kluczowa w dzisiejszym świecie zdominowanym przez dane, gdzie szybkie i dokładne przetwarzanie danych tabelarycznych stanowi przewagę konkurencyjną.
Rozwiązywanie wyzwań związanych z wieloma formatami i językami
Nowoczesne rozwiązania AI doskonale radzą sobie z różnorodnością formatów i języków, zapewniając spójną dokładność i efektywność w różnych zbiorach danych:
-
Możliwości wieloformatowe: Narzędzia zasilane AI mogą bez wysiłku przetwarzać PDF, zeskanowane dokumenty i pliki obrazów, takie jak PNG tabel. Ta wszechstronność jest szczególnie istotna, gdy użytkownicy muszą wyodrębnić tabelę z PDF lub przekształcić obraz na tabelę do analizy i raportowania.
-
Wsparcie dla wielu języków: Modele AI są trenowane na wielojęzycznych zbiorach danych, co umożliwia im obsługę dokumentów w różnych językach. Ta funkcja jest nieoceniona dla globalnych branż zajmujących się międzynarodową dokumentacją.
-
Zachowanie relacji danych: Niezależnie od tego, czy przetwarzają obraz na tabelę, czy wyodrębniają złożoną strukturę z PDF, systemy AI zapewniają, że nagłówki, wiersze i kolumny są zachowane, utrzymując integralność danych.
Dzięki rozwiązaniu tych wyzwań, rozwiązania AI ustanowiły się jako niezastąpione narzędzia dla organizacji zajmujących się dokumentacją na dużą skalę, wielojęzyczną i wieloformatową.
Przyszłość AI w ekstrakcji tabel
Przyszłość ekstrakcji tabel AI jest obiecująca, a postępy mają na celu dalsze zwiększenie jej możliwości:
-
Ulepszone modele wizji i języka (VLM): Nowe technologie VLM zapewnią jeszcze bardziej zaawansowane sposoby ekstrakcji tabel z PDF i konwersji złożonych formatów PNG tabel na dane strukturalne. Te modele zlikwidują lukę między elementami wizualnymi a rozumieniem tekstowym.
-
Integracja z generatywną AI: Dzięki integracji generatywnej AI, przyszłe rozwiązania mogą nie tylko wyodrębniać tabelę z PDF lub obrazów, ale także analizować wyodrębnione dane w poszukiwaniu informacji, podsumowań i rekomendacji.
-
Automatyzacja end-to-end: Narzędzia zasilane AI uproszczą procesy robocze, automatycznie przekształcając pliki, takie jak przekształcanie obrazu na tabelę, kategoryzując dane i wprowadzając je bezpośrednio do procesów analitycznych.
-
Szersza dostępność: Systemy AI staną się bardziej przyjazne dla użytkownika i dostępne, umożliwiając nawet osobom nietechnicznym łatwe przetwarzanie plików PNG tabel lub wyodrębnianie danych bez wysiłku.
Ekstrakcja tabel AI jest gotowa do zdefiniowania na nowo przetwarzania dokumentów, czyniąc ekstrakcję danych szybszą, inteligentniejszą i bardziej dostosowaną do ewoluujących potrzeb branży. Firmy, które przyjmą te rozwiązania, zyskają przewagę konkurencyjną w zarządzaniu i wykorzystywaniu swoich danych w sposób efektywny.
AnyParser: Przełom w przetwarzaniu dokumentów i ekstrakcji tabel
AnyParser jest na czołowej pozycji w inteligentnym przetwarzaniu dokumentów, oferując firmom wydajny i niezawodny sposób ekstrakcji danych nawet z najbardziej złożonych dokumentów. Jego zaawansowane możliwości są szczególnie widoczne w przypadku ekstrakcji tabel, zapewniając precyzyjne i skalowalne pozyskiwanie danych dla różnych branż.
Kluczowe zalety AnyParser w ekstrakcji tabel
-
Kompleksowe wsparcie formatów: Niezależnie od tego, czy mamy do czynienia z PDF, obrazami czy innymi typami plików, AnyParser upraszcza pozyskiwanie danych, dokładnie ekstraktując informacje tabelaryczne niezależnie od formatu.
-
Wysoka precyzja i zrozumienie kontekstowe: W przeciwieństwie do tradycyjnych narzędzi, AnyParser zachowuje strukturę, relacje i kontekst danych tabelarycznych, dostarczając wyniki gotowe do analizy i integracji.
-
Efektywność napędzana AI: Zasilany modelami wizji i języka (VLM), AnyParser doskonale radzi sobie w środowiskach wielojęzycznych i wieloformatowych, zapewniając bezproblemowe pozyskiwanie danych na dużą skalę.
-
Dostosowywalne procesy robocze: Platforma dostosowuje się do Twoich unikalnych potrzeb, niezależnie od tego, czy wyodrębniasz tabele finansowe, dokumenty medyczne czy dane badawcze.
Dzięki AnyParser firmy mogą optymalizować swoje procesy, minimalizować błędy i oszczędzać czas, automatyzując złożone zadanie ekstrakcji tabel do pozyskiwania danych strukturalnych.
Podsumowanie
Ekstrakcja tabel zasilana AI zdefiniowała na nowo sposób, w jaki firmy przetwarzają i wykorzystują dane strukturalne. Niezależnie od tego, czy zadanie polega na ekstrakcji tabel z PDF, przetwarzaniu obrazów czy osiąganiu dokładnego pozyskiwania danych, narzędzia takie jak AnyParser ułatwiają przekształcanie niestrukturalnych dokumentów w użyteczne informacje. AnyParser to zaufane rozwiązanie do uproszczenia przetwarzania dokumentów, zapewniające niezrównaną dokładność i efektywność. Dzięki swojej zdolności do obsługi różnorodnych formatów i kontekstów, AnyParser umożliwia organizacjom automatyzację procesów roboczych i uwolnienie pełnego potencjału ich danych.
Wezwanie do działania
Dlaczego czekać, aby doświadczyć nowego poziomu przetwarzania dokumentów? Odblokuj pełny potencjał AnyParser, próbując jego funkcji w praktycznym środowisku!
Kliknij poniższy link, aby wejść do Sandbox, gdzie możesz odkryć, jak to upraszcza:
- Dokładne pozyskiwanie danych z PDF i obrazów.
- Bezproblemową ekstrakcję tabel do integracji z narzędziami analitycznymi.
- Niezawodną wydajność w złożonych i dużych zbiorach danych.
Doświadcz AnyParser w Sandboxie teraz
Nie przegap okazji, aby zobaczyć, jak AnyParser może zrewolucjonizować Twoje procesy robocze. Przetestuj go dzisiaj i odkryj, jak łatwe może być przetwarzanie dokumentów i ekstrakcja tabel!