W dziedzinie zarządzania danymi, parsowanie polega na konwersji treści—takiej jak tekst, obrazy, tabele i metadane—na format użyteczny (np. tekst zwykły, dane strukturalne lub obrazy), który można dalej przetwarzać lub analizować. Nic nie ilustruje tego lepiej niż dziedzina parsowania PDF, wchodząc w świat parsowania, kluczowego procesu, który przekształca surowe informacje w uporządkowane, użyteczne dane. Ten kompleksowy przewodnik zagłębia się w zawiłości parsowania PDF, wyjaśniając jego definicję, zakres danych, które może wyodrębnić, przeszkody, przed którymi stoi, jego wieloaspektowe zastosowania oraz bogactwo metod dostępnych do wykorzystania jego pełnego potencjału. Zbadasz różne metody parsowania, ze szczególnym uwzględnieniem parsowania PDF i tego, jak narzędzia takie jak AnyParser wyróżniają się na tle konkurencji.
Zrozumienie parsera PDF: Czym jest parsowanie?
Czym jest parsowanie: skrupulatny proces przechwytywania danych
W swojej istocie, parsowanie PDF odnosi się do procesu wyodrębniania i interpretacji danych z plików PDF (Portable Document Format). Ponieważ PDF-y są zaprojektowane głównie do wyświetlania, a nie do przechowywania danych strukturalnych, parsowanie polega na konwersji treści—takiej jak tekst, obrazy, tabele i metadane—na format użyteczny (np. tekst zwykły, dane strukturalne lub obrazy), który można dalej przetwarzać lub analizować. Parsowanie obejmuje analizę na wysokim poziomie w celu zidentyfikowania i odzyskania konkretnych elementów w PDF, wykraczając poza sam tekst i obrazy, aby obejmować czcionki, układy, tabele i metadane. Proces ten nie jest jedynie technikalią, ale koniecznością w branżach tak różnorodnych jak finanse, prawo, logistyka i opieka zdrowotna, gdzie ponowne wykorzystanie informacji jest kluczowe.
Dane, które można wyodrębnić z PDF-ów
Dane, które można wyodrębnić z PDF-ów, są różnorodne i obszerne, w tym:
-
Paragrafy tekstowe: Sekwencje słów i znaków.
-
Pojedyncze pola danych: Indywidualne elementy, takie jak daty, numery śledzenia i imiona.
-
Dane tabelaryczne: Informacje zorganizowane w tabele i listy.
-
Obrazy: Zawartość graficzna osadzona w PDF.
-
Zaawansowane elementy: Nagłówki, obiekty, tabele krzyżowe, przyczepy i metadane, które wymagają bardziej zaawansowanych narzędzi do parsowania.
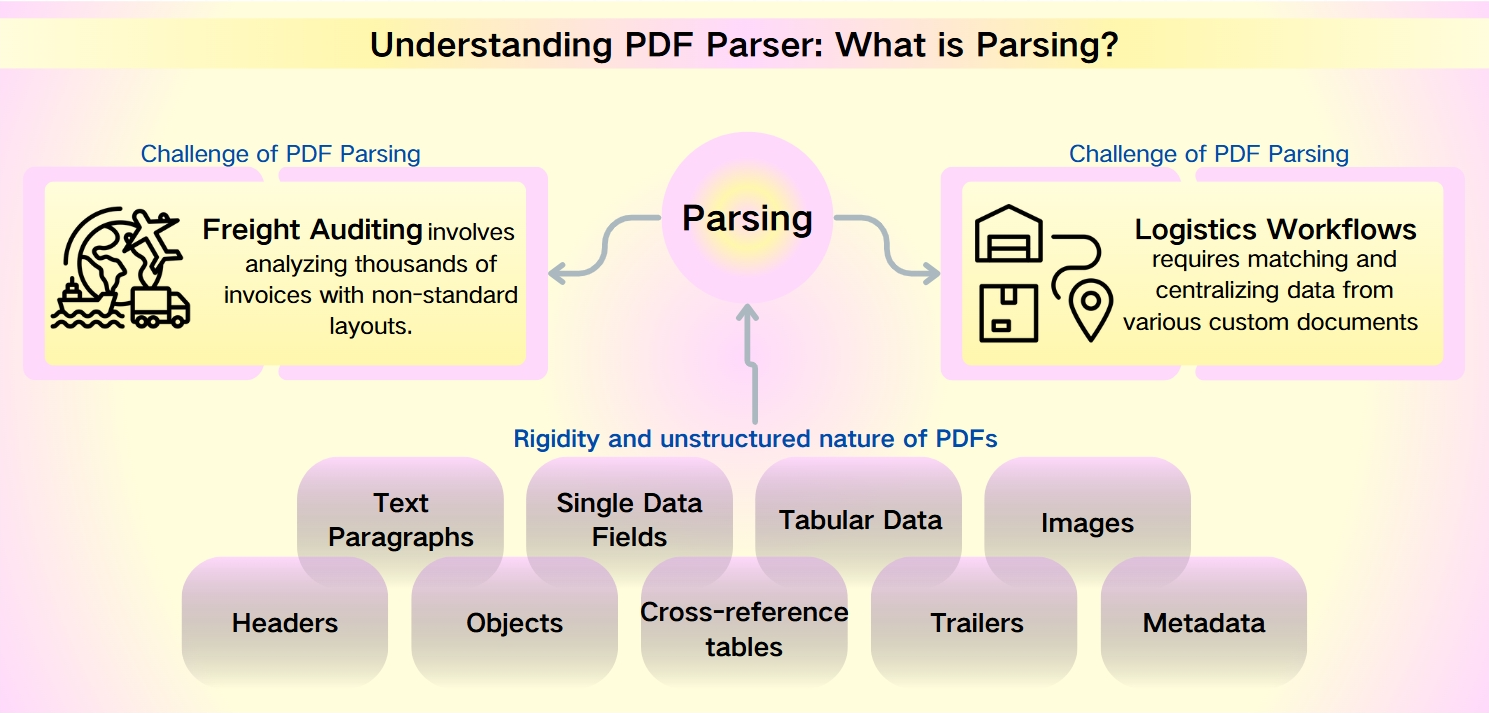
Wyzwania związane z parsowaniem PDF: niestrukturalny charakter metadanych PDF
Pomimo solidności PDF-ów—charakteryzujących się bezpieczeństwem, kompatybilnością z urządzeniami i kompaktowymi rozmiarami plików—wyodrębnianie danych z nich stanowi poważne wyzwanie. Sztywność i niestrukturalny charakter PDF-ów utrudniają szybkie analizy i odzyskiwanie informacji. Jest to szczególnie wyraźne w scenariuszach takich jak audyt frachtu i przepływy pracy w logistyce, gdzie niestandardowe układy i obszerne zestawy danych potęgują złożoność.
Audyt frachtu polega na analizie tysięcy faktur o niestandardowych układach. Przepływy pracy w logistyce wymagają dopasowania i centralizacji danych z różnych niestandardowych dokumentów, takich jak listy pakunkowe, faktury handlowe i listy przewozowe.
Znaczenie parsowania
Parsowanie odgrywa kluczową rolę w różnych dziedzinach, od rozwoju stron internetowych po przechwytywanie danych. Umożliwia firmom wyodrębnianie cennych informacji z niestrukturalnych źródeł danych, takich jak dokumenty PDF, pliki HTML i dane XML. Parsowanie ułatwia:
-
Poprawę podejmowania decyzji dzięki wnioskom opartym na danych.
-
Zwiększenie dokładności i spójności danych.
-
Usprawnienie przetwarzania i analizy danych.
-
Efektywne odzyskiwanie i przechowywanie informacji.
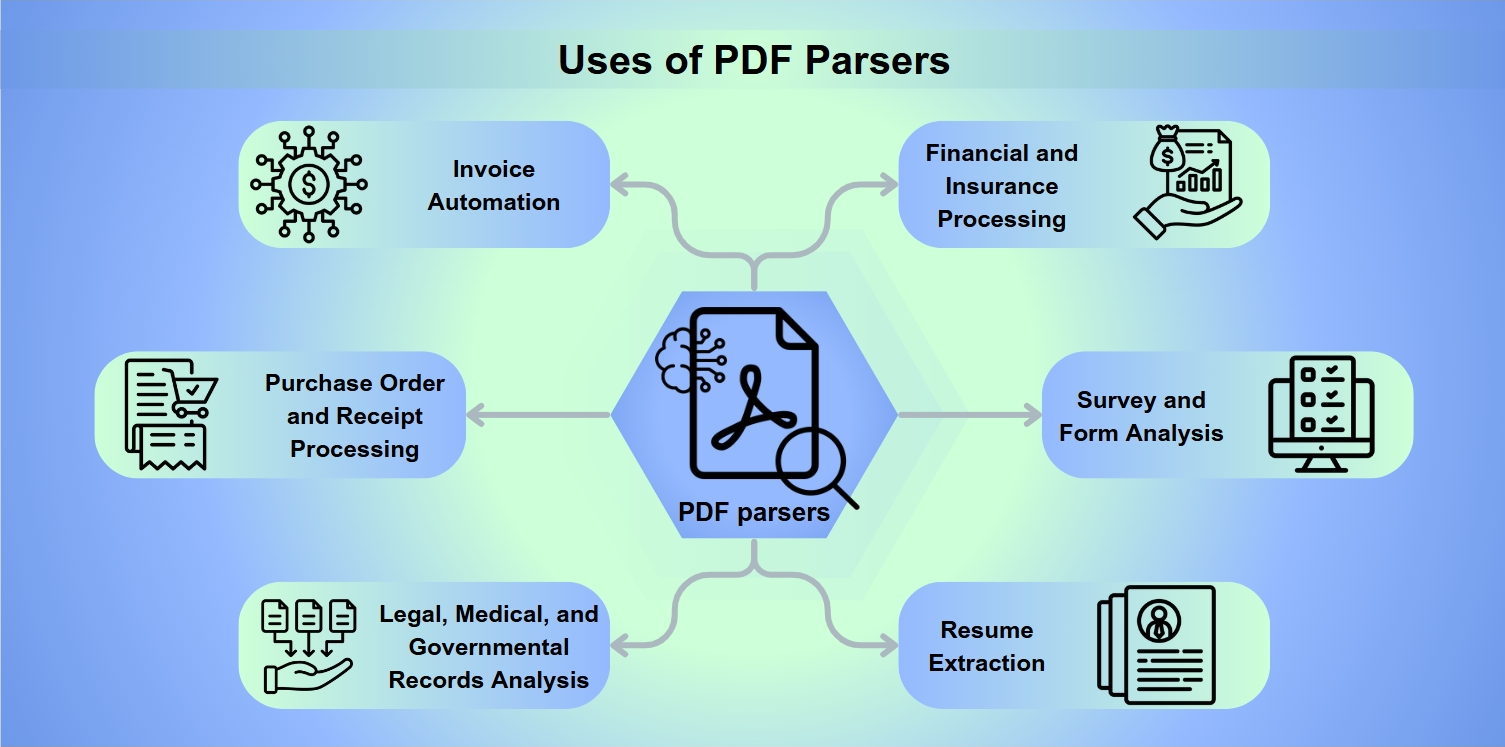
Zastosowania parserów PDF
Parsery PDF są niezbędnymi narzędziami w szeregu zastosowań, w tym:
-
Automatyzacja faktur: Usprawnienie przetwarzania i płatności faktur.
-
Przetwarzanie zamówień i paragonów: Ułatwienie zwrotów i rekompensat.
-
Analiza dokumentów prawnych, medycznych i rządowych: Umożliwienie dogłębnego wyodrębniania danych do analizy.
-
Przetwarzanie finansowe i ubezpieczeniowe: Ocena ryzyka i analiza bilansów.
-
Analiza ankiet i formularzy: Zbieranie i interpretacja odpowiedzi z formularzy.
-
Wyodrębnianie życiorysów: Pomoc rekruterom w selekcji kandydatów.
Porównanie różnych metod parsowania
Metody parsowania danych znacznie ewoluowały w czasie. Tradycyjne podejścia do przechwytywania danych często opierają się na wyrażeniach regularnych (regex) do wyodrębniania konkretnych wzorców z tekstu. Choć potężne, regex może stać się skomplikowane i trudne do utrzymania w przypadku złożonych zadań parsowania. Inną powszechną techniką jest manipulacja ciągami, która polega na dzieleniu i przetwarzaniu tekstu na podstawie ograniczników lub konkretnych znaków. Metody te, choć nadal użyteczne w niektórych scenariuszach, mogą mieć trudności z niestrukturalnymi lub niespójnymi formatami danych.
Krajobraz parsowania PDF obsługiwany jest przez różnorodne metody, z których każda ma swoje unikalne zalety i wady:
-
Internetowe konwertery/parsery PDF: Takie jak Zamzar i Smallpdf, oferują wygodę i szybkość, ale są ograniczone funkcjonalnością i potencjalnie niebezpieczne.
-
Adobe Acrobat: Zachowuje strukturę i formatowanie, ale może wymagać ręcznych poprawek po konwersji.
-
Kopiowanie i wklejanie: Zapewnia pełną kontrolę, ale jest pracochłonne i podatne na błędy.
-
Zautomatyzowane platformy: Nowoczesne technologie parsowania, takie jak AnyParser, wykorzystują uczenie maszynowe i przetwarzanie języka naturalnego (NLP) do obsługi bardziej złożonych struktur danych.
Te podejścia oparte na AI mogą zrozumieć kontekst i semantykę, co czyni je szczególnie skutecznymi w parsowaniu niestrukturalnego tekstu lub dokumentów o różnych formatach. Niektóre zaawansowane parsery wykorzystują modele głębokiego uczenia do identyfikacji i wyodrębniania istotnych informacji z wysoką dokładnością, nawet z wcześniej nieznanych układów dokumentów.
Jak przeprowadzić parsowanie PDF: Najlepszy darmowy parser PDF do wyodrębniania metadanych PDF
Zrozumienie metadanych PDF
Metadane PDF zawierają kluczowe informacje o dokumencie, w tym jego tytuł, autora, datę utworzenia i słowa kluczowe. Efektywne wyodrębnianie tych metadanych jest niezbędne do organizowania, wyszukiwania i zarządzania dużymi zbiorami plików PDF. Solidny parser PDF może uprościć ten proces, oszczędzając czas i poprawiając wydajność pracy.
Kluczowe cechy najlepszych parserów PDF
Najlepsze darmowe parsery PDF oferują połączenie dokładności, szybkości i wszechstronności. Powinny być w stanie obsługiwać różne formaty PDF, w tym zeskanowane dokumenty i te o złożonych układach. Szukaj parserów, które mogą wyodrębniać nie tylko podstawowe metadane, ale także pola niestandardowe i ukryte informacje. Dodatkowo, najlepsze parsery często oferują opcje dla ekstraktorów danych PDF do przetwarzania wsadowego i integracji z innymi systemami oprogramowania.
Cechy AnyParser
AnyParser, opracowany przez CambioML, jest szczególnie godny uwagi ze względu na swoją dokładność, prywatność i konfigurowalność. Zdolność AnyParser do obsługi wielu formatów plików, jego przyjazny interfejs oraz skalowalność czynią go doskonałym wyborem dla firm każdej wielkości. Co więcej, jego API umożliwia płynną integrację z istniejącymi przepływami pracy, zwiększając ogólną efektywność zarządzania dokumentami. Oto niektóre z kluczowych cech, które sprawiają, że AnyParser jest doskonałym wyborem do parsowania PDF:
-
Precyzja: AnyParser jest zaprojektowany do dokładnego wyodrębniania tekstu, liczb i symboli, zachowując oryginalny układ i format. Wykorzystuje zaawansowane modele językowe do poprawy zrozumienia dokumentów i wyodrębniania informacji, osiągając do 2x wyższą dokładność w porównaniu do tradycyjnych modeli OCR.
-
Prywatność: Obsługuje zarówno lokalne, jak i chmurowe parsowanie danych, zapewniając, że wrażliwe informacje pozostają prywatne i bezpieczne.
-
Konfigurowalność: Użytkownicy mogą dostosować zasady wyodrębniania i formaty wyjściowe do swoich specyficznych potrzeb.
-
Wsparcie dla wielu źródeł: AnyParser obsługuje różnorodne typy dokumentów, w tym PDF-y, obrazy i wykresy.
-
Strukturalne wyjście: Wyodrębnione informacje mogą być konwertowane na strukturalne formaty, takie jak Markdown, Excel lub JSON, co ułatwia dalsze przetwarzanie i analizę.
-
Opcje wdrożenia w chmurze: SDK AnyParser może być wdrażane w chmurze, centrach danych lub prywatnie, oferując elastyczność i skalowalność.
-
Przyjazny interfejs użytkownika: Narzędzie oferuje prostą API, które pozwala na realizację złożonych zadań parsowania dokumentów przy użyciu zaledwie kilku linii kodu.
-
Wysoka wydajność: Optymalizowane algorytmy zapewniają szybkie przetwarzanie dużej liczby dokumentów, 5x szybciej niż zgeneralizowane LLM, takie jak GPT4o.
-
Wsparcie społeczności: Jako projekt open-source, AnyParser korzysta z aktywnej społeczności i zaprasza do współpracy.
-
Darmowy limit użytkowania: AnyParser oferuje darmowy limit użytkowania dla każdego konta, umożliwiając użytkownikom przetestowanie możliwości narzędzia przed podjęciem decyzji o płatnym planie.
-
Opinie klientów: Użytkownicy chwalą AnyParser za wysoką dokładność, zachowanie prywatności i efektywność w wyodrębnianiu danych, a studia przypadków pokazują znaczne oszczędności czasu i poprawę jakości danych.
Te zalety sprawiają, że AnyParser jest cennym ekstraktorem danych PDF do parsowania dokumentów i wyodrębniania informacji, szczególnie dla użytkowników korporacyjnych, którzy wymagają wysokiej precyzji i bezpieczeństwa. Dzięki ciągłym postępom technologicznym i aktywnemu zaangażowaniu społeczności, AnyParser ma szansę odegrać coraz ważniejszą rolę w dziedzinie parsowania dokumentów i wyodrębniania informacji.
Techniczne wyjaśnienie parserów PDF
Parsowanie PDF dzieli koncepcyjne podstawy z web scrapingiem, jednak brakuje mu strukturalnej hierarchii HTML. Podczas gdy dokumenty internetowe są parsowane przez dostępne tagi HTML, PDF-y przedstawiają płaską tablicę znaków i pikseli, co wymaga bardziej zaawansowanych algorytmów i bibliotek do wyodrębniania danych.
Parser PDF vs parser PDF w Pythonie: Kluczowe różnice
Parser PDF jest często samodzielnym narzędziem jako ekstraktor danych PDF lub biblioteką zaprojektowaną specjalnie do wyodrębniania danych z plików PDF. Te parsery zazwyczaj oferują przyjazne interfejsy użytkownika i wymagają minimalnej wiedzy programistycznej. Z drugiej strony, parsery PDF w Pythonie to moduły lub biblioteki, które integrują się z skryptami Pythona, oferując większą elastyczność, ale wymagające wiedzy programistycznej.
Programiści mogą dostosować proces parsowania, wdrażać zaawansowaną analizę tekstu i płynnie integrować wyodrębnianie danych PDF w szersze aplikacje Pythona. Parsery PDF, chociaż bardziej ograniczone w dostosowywaniu niż parser PDF w Pythonie, często oferują wbudowane funkcje dla powszechnych zastosowań, co czyni je idealnymi dla użytkowników, którzy potrzebują szybkich wyników bez rozległego programowania.
Zalety AnyParser z VLM do parsowania danych
-
Wysoka precyzja: VLM AnyParser zapewnia, że wyodrębnianie danych zachowuje wysoką wierność, nawet w przypadku złożonych układów dokumentów.
-
Szybkość: Prowadzi w szybkości konwersji, zwiększając wydajność poprzez skrócenie czasu potrzebnego na przetwarzanie dokumentów.
-
Przyjazny użytkownikowi: AnyParser oferuje przejrzysty interfejs, co czyni go dostępnym dla użytkowników na każdym poziomie.
-
Wszechstronność: Poza PDF-ami, AnyParser jest potężnym konwerterem obrazów na Excel, obsługując różnorodne typy dokumentów.
Podsumowanie
Parsowanie PDF to coś więcej niż tylko proces techniczny; to brama do przekształcania sposobu, w jaki firmy zarządzają danymi. Pomimo wyzwań, ewolucja rozwiązań programowych uczyniła je bardziej dostępnymi niż kiedykolwiek. Niezależnie od tego, czy zajmujesz się przetwarzaniem faktur, czy złożoną analizą danych, wybór odpowiedniego parsera PDF jest kluczowy. Chodzi o znalezienie narzędzia, które oferuje idealną równowagę między dokładnością, bezpieczeństwem i wydajnością, aby wspierać Twoje inicjatywy oparte na danych.
Rozpocznij swoją darmową wersję próbną już dziś
Gotowy, aby zrewolucjonizować swoje przetwarzanie dokumentów? Wypróbuj AnyParser ZA DARMO, bez potrzeby podawania danych karty kredytowej, na https://www.cambioml.com/sandbox. Darmowa wersja próbna pozwala na przetwarzanie do 10 stron na dokument, z maksymalnym rozmiarem pliku wynoszącym 10 MB. Doświadcz na własnej skórze, jak parser PDF AnyParser może zmienić Twoje podejście do niestrukturalnych danych i wyodrębniania dokumentów. Nie przegap tej okazji, aby poprawić swoje możliwości analizy danych i uprościć przepływ pracy dzięki nowoczesnej technologii AI.