W dzisiejszym świecie opartym na danych, konwersja złożonych dokumentów z formatu PDF na CSV jest kluczowym zadaniem dla wielu profesjonalistów. Jeśli zmagasz się z wyciągami bankowymi, raportami medycznymi lub zamówieniami wysyłkowymi w formacie PDF, prawdopodobnie szukasz efektywnego rozwiązania.
Wprowadzenie modeli językowych wizji (VLM), nowoczesnej technologii, która przewyższa tradycyjne metody OCR. Dzięki wykorzystaniu zarówno zrozumienia wizualnego, jak i kontekstowego, VLM oferują potężne narzędzie do przekształcania złożonych, strukturalnych dokumentów w formaty zrozumiałe dla maszyn.
Ten przewodnik przeprowadzi Cię przez proces wykorzystania VLM do konwersji PDF-ów na pliki CSV lub Excel za pomocą AnyParser, usprawniając Twój przepływ pracy i odblokowując cenne spostrzeżenia z danych. Dzięki AnyParser możesz łatwo konwertować PDF na CSV, PDF na Excel, a nawet konwertować Word na CSV za pomocą zaledwie kilku kliknięć w naszym Playground.
Silne potrzeby konwersji PDF na CSV oraz ograniczenia tradycyjnych modeli OCR
Rosnące zapotrzebowanie na konwersję PDF na CSV
W dzisiejszym świecie opartym na danych, potrzeba konwersji PDF na CSV stała się coraz bardziej kluczowa. Firmy i osoby prywatne poszukują efektywnych sposobów przekształcania statycznych dokumentów PDF w dynamiczne, analizowalne arkusze kalkulacyjne. Proces konwersji jest niezbędny do wydobywania cennych informacji z różnych dokumentów, takich jak wyciągi bankowe, raporty medyczne i zamówienia wysyłkowe. Możliwość konwersji Word na Excel lub użycia konwertera PDF na CSV może znacznie uprościć zarządzanie danymi i procesy analizy.
Niedociągnięcia konwencjonalnej technologii OCR
Chociaż tradycyjne modele rozpoznawania znaków optycznych (OCR) były od dawna używane do ekstrakcji tekstu, często zawodzą w przypadku złożonych dokumentów. Te ograniczenia stają się oczywiste, gdy próbujemy konwertować skomplikowane PDF-y na Google Sheets lub inne formaty arkuszy kalkulacyjnych. Systemy OCR mają trudności z:
- Dokładnym interpretowaniem niskiej jakości skanów lub obrazów
- Obsługiwaniem układów wielokolumnowych i tabel
- Rozpoznawaniem różnych czcionek i języków
- Utrzymywaniem oryginalnej struktury dokumentu
Te wyzwania podkreślają potrzebę bardziej zaawansowanych rozwiązań, które mogą bezproblemowo obsługiwać proces konwersji PDF na CSV, zachowując zarówno treść, jak i kontekst oryginalnych dokumentów.
Przewodnik krok po kroku po konwersji dokumentów PDF za pomocą AnyParser
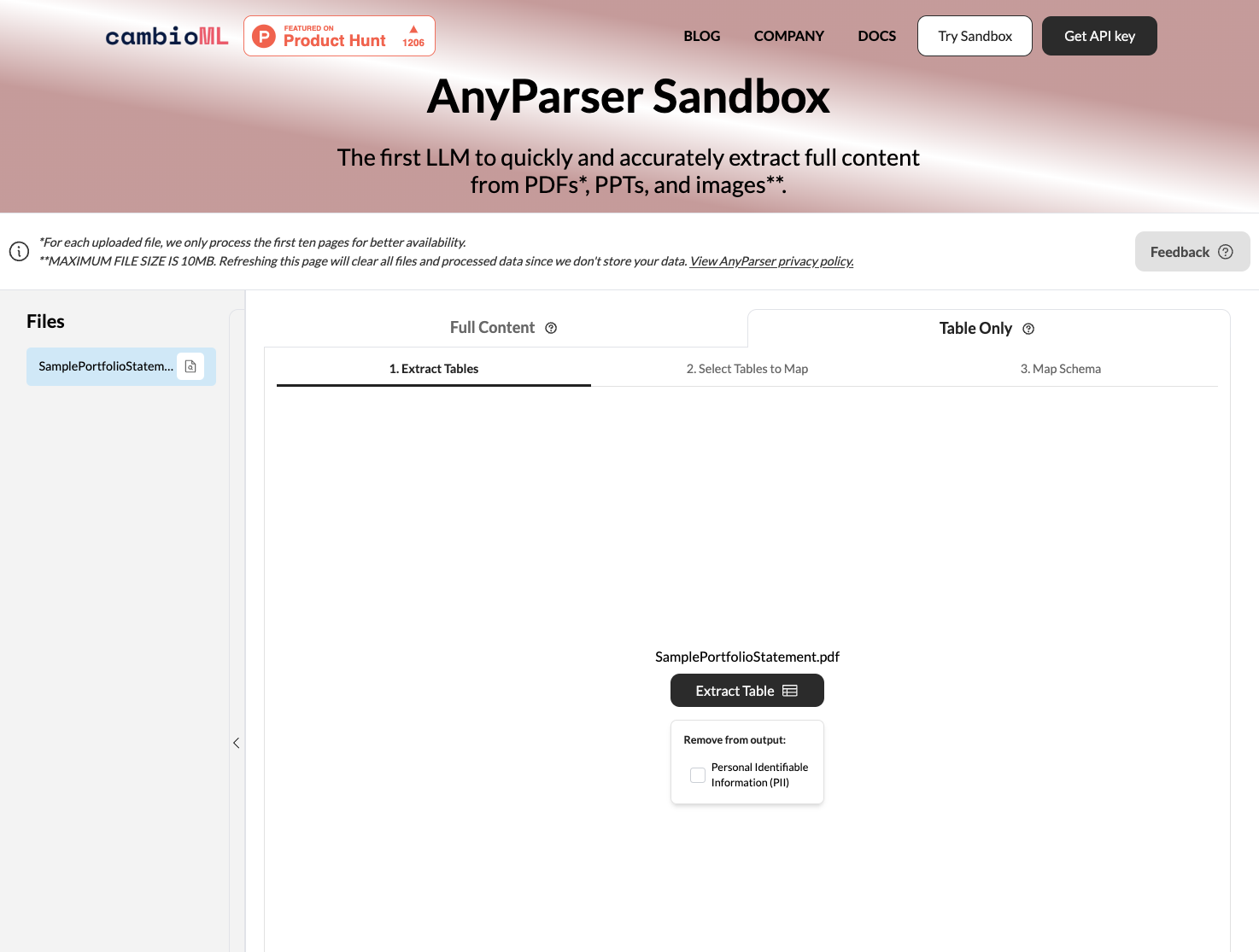
AnyParser to potężne narzędzie do konwersji PDF na CSV, które wykorzystuje zaawansowane modele językowe wizji do dokładnego wydobywania danych z złożonych dokumentów PDF. Oto podstawowe kroki, aby użyć AnyParser do konwersji plików PDF:
-
Prześlij swój PDF lub Word. Po prostu przeciągnij i upuść swoje dokumenty PDF do interfejsu internetowego AnyParser lub możesz wkleić zrzut ekranu PDF do interfejsu AnyParser.
-
Wybierz "Tylko tabela" i kliknij "Ekstrahuj". Silnik API AnyParser automatycznie wykryje tabele w PDF i wyekstrahuje je z wysoką dokładnością. Wyekstrahowane dane są przechowywane w pliku .csv, który możesz pobrać lub wyeksportować do Google Sheets za pomocą zaledwie jednego kliknięcia.
-
Podgląd i porównanie. Przejrzyj wyekstrahowane dane w podglądzie, aby upewnić się, że spełniają Twoje oczekiwania. Podgląd wstępnej ekstrakcji AnyParser i porównaj obok siebie w interfejsie.
-
Eksportuj do CSV lub Excel. Gdy będziesz zadowolony z ekstrakcji, pobierz plik .csv, aby użyć danych w swoich aplikacjach i systemach. Wyekstrahowane dane można łatwo zaimportować do arkuszy kalkulacyjnych i baz danych w celu dalszej analizy.
Postępując zgodnie z tymi prostymi krokami i wykorzystując moc modeli językowych wizji, AnyParser umożliwia efektywną konwersję nawet najbardziej złożonych dokumentów PDF w strukturalne, edytowalne pliki CSV, które możesz analizować i integrować w swoich przepływach pracy.
Zobacz ten film, aby zobaczyć krok po kroku demonstrację wideo!
Zastosowania modeli VLM w konwersji PDF na CSV/Excel w rzeczywistych zastosowaniach
Modele językowe wizji (VLM) rewolucjonizują sposób, w jaki konwertujemy PDF na CSV i formaty Excel, oferując potężne rozwiązania dla różnych branż. Wykorzystując te zaawansowane modele, możesz efektywnie przekształcać złożone dokumenty w strukturalne, zrozumiałe dla maszyn dane.
Przetwarzanie dokumentów finansowych
W sektorze bankowym VLM doskonale radzą sobie z konwersją PDF na CSV dla wyciągów bankowych. Te modele mogą dokładnie wydobywać szczegóły transakcji, numery kont i informacje o saldach, nawet z dokumentów o skomplikowanych układach lub wielu walutach. Ta zdolność usprawnia procesy analizy finansowej i uzgadniania.
Zarządzanie dokumentacją medyczną
Dla pracowników służby zdrowia VLM stanowią nieocenione narzędzie do konwersji Word na Excel dla raportów medycznych. Dzięki dokładnemu interpretowaniu złożonej terminologii medycznej i zachowywaniu struktury wyników laboratoryjnych, VLM ułatwiają tworzenie kompleksowych baz danych pacjentów. Ta transformacja umożliwia łatwiejszą analizę trendów i poprawę opieki nad pacjentami.
Optymalizacja logistyki i łańcucha dostaw
W branży logistycznej VLM świetnie radzą sobie z konwersją zamówień wysyłkowych z PDF na Google Sheets. Te modele mogą wydobywać kluczowe informacje, takie jak adresy dostawy, opisy przedmiotów i numery śledzenia, zachowując integralność danych tabelarycznych. Ta konwersja umożliwia efektywne zarządzanie zapasami i optymalizację tras.
Wykorzystując konwerter PDF na CSV zasilany przez VLM, możesz znacznie zwiększyć efektywność przetwarzania danych w różnych sektorach. Te zaawansowane modele oferują niezrównaną dokładność w obsłudze dokumentów wielojęzycznych, złożonych układów, a nawet niskiej jakości skanów, co czyni je niezbędnym narzędziem dla nowoczesnych firm.
Jak modele językowe wizji radzą sobie z wyzwaniami OCR
Modele językowe wizji (VLM) rewolucjonizują sposób, w jaki konwertujemy PDF na CSV i przekształcamy złożone dokumenty w formaty zrozumiałe dla maszyn. W przeciwieństwie do tradycyjnego OCR, VLM wykorzystują zarówno zrozumienie wizualne, jak i językowe, aby poradzić sobie z najtrudniejszymi aspektami konwersji dokumentów.
Interpretacja złożonych układów
VLM doskonale radzą sobie z odszyfrowywaniem skomplikowanych struktur dokumentów, co czyni je idealnymi do konwersji Word na Excel lub obsługi wyciągów bankowych o różnych formatach. Analizując relacje przestrzenne między elementami tekstowymi, VLM mogą dokładnie rekonstruować tabele i zachowywać integralność układu. Na przykład, VLM mogą poprawnie interpretować PDF z fakturą zawierającą wiele tabel o różnej liczbie kolumn i wierszy, podczas gdy konwencjonalny OCR pomieszałby wiersze i kolumny.
Zrozumienie kontekstowe
Jedną z kluczowych zalet VLM jest ich zdolność do uchwycenia semantycznego znaczenia treści dokumentu. Ta świadomość kontekstowa umożliwia dokładniejszą ekstrakcję podczas korzystania z konwertera PDF na CSV, szczególnie w przypadku dokumentów specyficznych dla danej dziedziny, takich jak raporty CBC w medycynie czy zamówienia wysyłkowe w logistyce. Na przykład, VLM mogą poprawnie klasyfikować raporty medyczne według specjalizacji na podstawie ich treści, a nawet zrozumieć, że liczba "leukocytów" to liczba "białych krwinek (WBC)"!
Zdolność wielojęzyczna
VLM przełamują bariery językowe, bezproblemowo obsługując wiele skryptów i języków w jednym dokumencie. To czyni je szczególnie przydatnymi dla międzynarodowych firm zajmujących się różnorodnymi typami dokumentów. Na przykład, VLM mogą wydobywać dane z PDF zawierającego tekst zarówno w języku angielskim, jak i francuskim.
Redukcja szumów
Niskiej jakości skany lub obrazy często stanowią wyzwanie dla tradycyjnych systemów OCR. VLM mogą jednak skutecznie filtrować szumy i koncentrować się na istotnych informacjach, zapewniając wysoką jakość wyjścia podczas konwersji dokumentów do Google Sheets lub innych formatów. Na przykład, VLM mogą dokładnie wydobywać dane z rozmytego lub wyblakłego dokumentu PDF.
FAQ dotyczące konwersji PDF na CSV za pomocą modeli językowych wizji
Jak konwersja oparta na VLM różni się od tradycyjnego OCR?
Modele językowe wizji (VLM) oferują znaczące zalety w porównaniu do tradycyjnego OCR podczas konwersji PDF na CSV lub Excel. W przeciwieństwie do OCR, VLM mogą dokładnie interpretować złożone układy, rozumieć kontekst i obsługiwać wiele języków bezproblemowo. To czyni je idealnymi do konwersji wyciągów bankowych, raportów CBC w medycynie i zamówień wysyłkowych w logistyce na formaty zrozumiałe dla maszyn.
Jakie typy dokumentów najlepiej nadają się do konwersji VLM?
VLM doskonale radzą sobie z konwersją złożonych dokumentów z tabelami, wykresami i mieszanym contentem. Są szczególnie skuteczne w przypadku sprawozdań finansowych, raportów medycznych i manifestów wysyłkowych. Konwerter PDF na CSV zasilany przez VLM może zachować integralność tabeli i wydobywać dane nawet z niskiej jakości skanów lub złożonych dokumentów wielojęzycznych.
Jak dokładna jest konwersja oparta na VLM w porównaniu do ręcznego wprowadzania danych?
Rozwiązania oparte na VLM, takie jak AnyParser, mogą znacznie poprawić dokładność w porównaniu do ręcznego wprowadzania danych lub tradycyjnego OCR. Wykorzystując zarówno zrozumienie wizualne, jak i kontekstowe, te narzędzia mogą zmniejszyć błędy w konwersji Word na Excel lub PDF na Google Sheets o nawet 50%. Ta dokładność jest kluczowa dla utrzymania integralności danych w zastosowaniach finansowych, medycznych i logistycznych.
Czy VLM mogą obsługiwać różne formaty plików poza PDF?
Tak, zaawansowane narzędzia oparte na VLM mogą przetwarzać różne formaty plików. Chociaż konwersja PDF na CSV jest powszechna, te modele mogą również wydobywać dane z obrazów, dokumentów Word, prezentacji PowerPoint i zeskanowanych dokumentów. Ta wszechstronność czyni VLM potężnym rozwiązaniem dla kompleksowych potrzeb przetwarzania dokumentów w różnych branżach.
Podsumowanie
Rozpoczynając korzystanie z modeli językowych wizji do konwersji PDF na CSV, pamiętaj, że sukces tkwi w dobrze zorganizowanym podejściu. Wdrażając solidne wstępne przetwarzanie, dokładną klasyfikację dokumentów i dokładne przetwarzanie końcowe, możesz w pełni wykorzystać potencjał VLM do swoich potrzeb ekstrakcji danych. Niezależnie od tego, czy masz do czynienia z złożonymi wyciągami bankowymi, skomplikowanymi raportami medycznymi czy szczegółowymi zamówieniami wysyłkowymi, VLM oferują potężne rozwiązanie do przekształcania nieustrukturyzowanych danych w użyteczne spostrzeżenia. Wykorzystaj tę nowoczesną technologię, aby usprawnić swoje przepływy pracy, zwiększyć dokładność danych i odkryć nowe możliwości w przetwarzaniu dokumentów. Z VLM w swoim zasięgu ręki, jesteś dobrze przygotowany, aby skutecznie i efektywnie poradzić sobie z nawet najbardziej wymagającymi zadaniami konwersji PDF.
Wezwanie do działania
Przejdźmy dalej, wdrażając te spostrzeżenia. Rozważ skontaktowanie się z ekspertami w dziedzinie modeli językowych wizji, takimi jak zespół AnyParser, aby:
- Wypróbować AnyParser za darmo, aby przekonwertować swój PDF na CSV pod adresem https://www.cambioml.com/sandbox
- Jeśli wolisz doświadczenie bez kodu do konwersji dużej ilości plików PDF na Excel, sprawdź https://www.energent.ai
- Uzyskać bezpłatną konsultację na temat tego, jak VLM mogą poprawić Twój przepływ pracy związany z ekstrakcją danych
Wykorzystanie pełnej mocy modeli językowych wizji wymaga skorzystania z doświadczenia i najlepszych praktyk specjalistów ds. konwersji. Zrób następny krok, łącząc się z liderami branży, aby przyspieszyć swoją transformację w kierunku bardziej zautomatyzowanego, dokładnego i wnikliwego procesu ekstrakcji danych.