Konwersja skomplikowanych plików PDF do Markdown może być wyzwaniem. Istnieje wiele bibliotek open-source dostępnych do ekstrakcji tekstu z PDF, ale w przypadku plików PDF zawierających złożone elementy, takie jak tabele i wykresy, wyniki często są niezadowalające. Popularne duże modele językowe, takie jak GPT czy Claude, mogą poradzić sobie z tymi zadaniami, ale zazwyczaj są wolne i czasami produkują niedokładne wyniki. Tradycyjne narzędzia OCR, chociaż skuteczne w przypadku prostszych dokumentów, często mają trudności z zachowaniem dokładnej struktury i znaczenia semantycznego oryginalnej treści. Z drugiej strony, modele językowe wizji czasami halucynują, prowadząc do błędnych wyników analizy. Ten blog wyjaśni, co oznacza analiza i szczegółowo przedstawi wyniki analizy porównawczej wielu modeli przy użyciu różnych mierników.
Co oznacza analiza?
W kontekście analizy PDF, "analiza" odnosi się do procesu ekstrakcji określonych danych z pliku PDF za pomocą specjalistycznego oprogramowania znanego jako parser PDF. Parser PDF analizuje zawartość dokumentu PDF i identyfikuje elementy, takie jak tekst, obrazy, czcionki, układy, a nawet metadane. Wyekstrahowane dane można następnie zorganizować i wyeksportować do różnych formatów, takich jak XML, JSON lub Excel/CSV, które mogą być używane do różnych celów, takich jak analiza danych, prowadzenie rejestrów czy automatyzacja procesów roboczych.
Zrozumienie, co oznacza analiza, jest kluczowe dla oceny skuteczności rozwiązania do analizy, szczególnie podczas porównywania różnych narzędzi do konwersji PDF do Markdown, ponieważ parser PDF obejmuje więcej niż tylko prostą ekstrakcję tekstu — wymaga rozpoznawania i zachowania semantycznej struktury dokumentu.
Jak mierzymy jakość tych rozwiązań do analizy?
Zdefiniowaliśmy szereg metryk na poziomie słów, aby ocenić wydajność różnych modeli, koncentrując się na kluczowych czynnikach, takich jak:
-
Precyzja, Przypomnienie i F-Miara: Ocena jakości i kompletności analizy.
-
Wynik BLEU i ANLS: Użyteczne do oceny struktury językowej i układu.
-
Odległość edycyjna, Divergencja Jenson-Shannon i Odległość Jaccarda: Metryki specyficzne dla domeny OCR, szczególnie pomocne w zrozumieniu dokładności reprodukcji treści.
Nasz model językowy wizji, AnyParser, wykazuje wyjątkową wydajność, łącząc szybkość i dokładność, szczególnie w przypadku złożonych układów z tabelami i elementami semantycznymi. AnyParser przewyższa inne rozwiązania, oferując 20-krotną poprawę szybkości w porównaniu do modeli takich jak GPT/Claude, osiągając jednocześnie wyższą dokładność.
Obszerne wyniki porównawcze w stosunku do wiodących modeli analizy
Obiekt statystyczny
Aby naprawdę zaprezentować możliwości AnyParser, przeprowadziliśmy obszerne porównanie z wiodącymi modelami analizy w branży oraz znanymi dużymi modelami językowymi (LLM). Nasza ocena obejmowała:
1. Duże modele językowe
- AnyParser
- GPT-4o OpenAI
- Gemini 1.5 Pro Google'a
- Claude 3.5 Sonnet Anthropic
2. Usługi oparte na OCR
- LlamaParse
- Amazon Textract
- Google Cloud Document AI
- Azure Document Intelligence
Prezentacja wyników i analiza
Eksperyment 1
Na początku przeprowadziliśmy szereg rygorystycznych porównań wydajności różnych modeli AI dokumentów w ponad 5 metrykach: BLEU, Precyzja i przypomnienie, F-Miara oraz ANLS. Możesz znaleźć matematyczną definicję tych metryk w aneksie.
Porównywane modele to: AnyParser-base, AnyParser-pro, Textract, Llama-Parse, GPT4o, Gemini-1.5-pro, GCP-DocAl i Azure-DocAl.
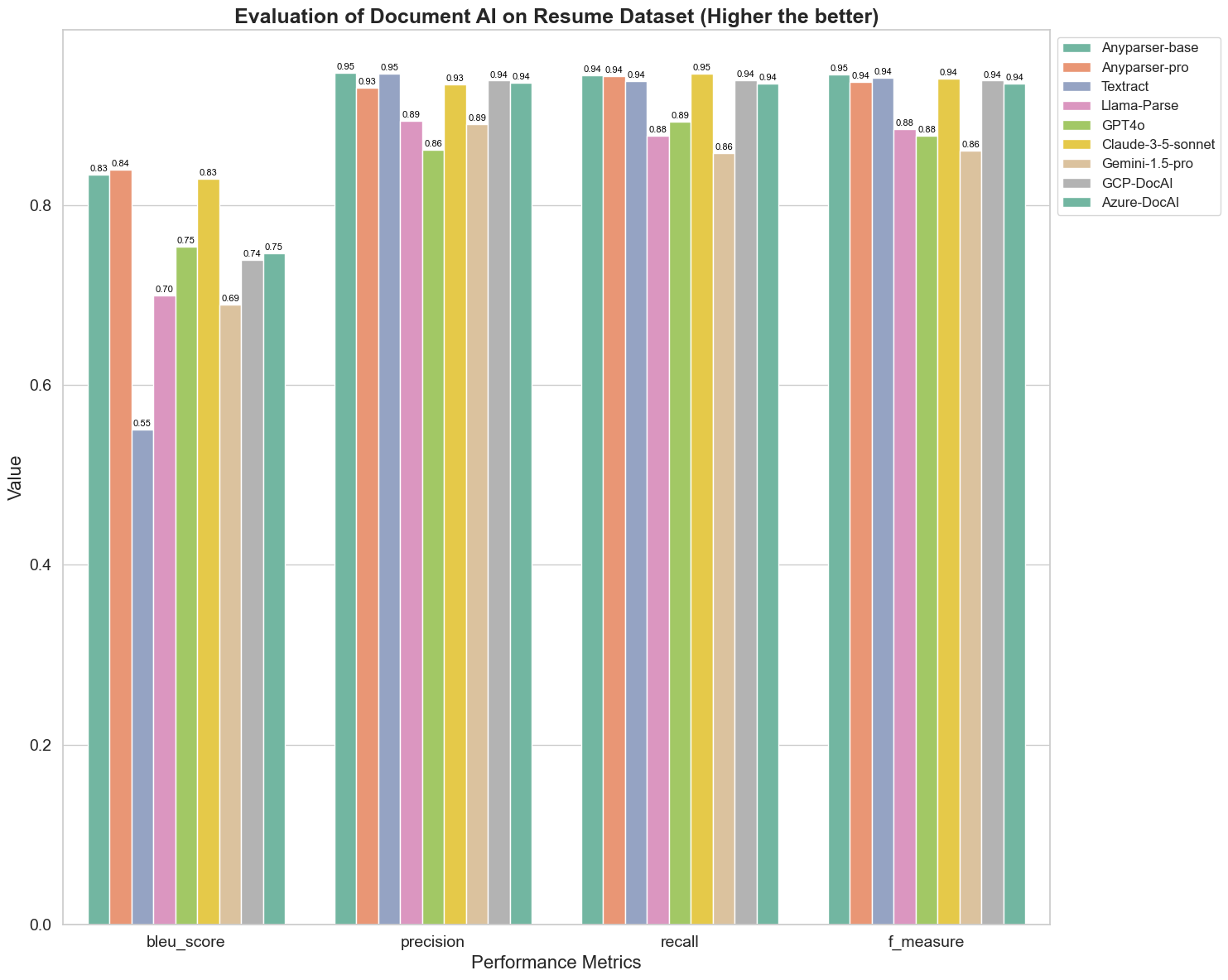
Wynik BLEU jest używany jako ocena jakości tłumaczenia dwujęzycznego, aby przetestować jakość modeli w przetwarzaniu wypowiedzi. Porównując wyniki tych modeli analizy w metodzie oceny BLEU, stwierdzamy, że: wyniki AnyParser-base i AnyParser-pro są znacznie wyższe niż wyniki innych modeli, a Amazon Textract uzyskuje najniższy wynik, a wyniki innych modeli znajdują się na średnim poziomie.
Dokładność rozpoznawania jest zazwyczaj reprezentowana przez precyzję i przypomnienie, gdzie precyzja reprezentuje procent rzeczywiście poprawnych wyników wśród wyników uznanych za poprawne przez model, a przypomnienie reprezentuje procent rzeczywiście poprawnie ocenionych wyników przez model wśród wszystkich rzeczywiście poprawnych wyników. Porównując precyzję i przypomnienie tych modeli analizy, stwierdzamy, że: z wyjątkiem Llama-Parse, GPT4o i Gemini-1.5-pro, wszystkie inne modele osiągają wysoki poziom. Wśród nich AnyParser i Amazon Textract wyróżniają się pod względem precyzji, a AnyParser-base i AnyParser-pro wyróżniają się pod względem przypomnienia. Wyższy wynik modelu w Precyzji wskazuje, że model generuje więcej poprawnych informacji w wynikach produkcji, a wyższy wynik w przypomnieniu wskazuje, że model jest bardziej zdolny do uzyskiwania poprawnych informacji z próbki. Wyniki pokazują, że AnyParser ma wyraźną przewagę pod względem dokładności rozpoznawania tekstu z PDF.
F-Miara jest kompleksowym wskaźnikiem oceny precyzji i przypomnienia w tych dwóch wskaźnikach. Porównując wyniki tych modeli analizy w kontekście F-Miara, możemy bardziej intuicyjnie zobaczyć, że pięć modeli, AnyParser-base, AnyParser-pro, Amazon Textract, GCP-DocAI i Azure-DocAI, mają lepszą siłę w zakresie dokładności rozpoznawania w porównaniu do innych modeli. Możemy bardziej intuicyjnie zobaczyć, że pięć modeli ma większą siłę w dokładności rozpoznawania niż inne modele, a AnyParser osiąga najwyższy wynik w F-Miara, co dodatkowo ilustruje oczywistą przewagę AnyParser w dokładności rozpoznawania tekstu z PDF.
ANLS, jako powszechnie stosowany wskaźnik oceny, gdy chodzi o mierzenie dokładności i podobieństwa między oryginalnym tekstem a tekstem docelowym na poziomie znaków, jest również bardzo informacyjny w kontekście mierzenia poziomu analizy modeli. Wyższe wyniki AnyParser-base, AnyParser-pro i Azure-DocAI odzwierciedlają wyższy poziom analizy tych modeli w porównaniu do innych modeli.
Ogólnie rzecz biorąc, AnyParser-base i AnyParser-pro przewyższają inne modele.
Eksperyment 2
Porównaliśmy również wydajność różnych modeli AI dokumentów w trzech różnych metrykach: Odległość edycyjna, Divergencja Jenson-Shannon i Odległość Jaccarda. Metryki te służą do mierzenia podobieństwa między wynikami modeli a dokumentem referencyjnym. Niższe wartości wskazują na lepszą wydajność.
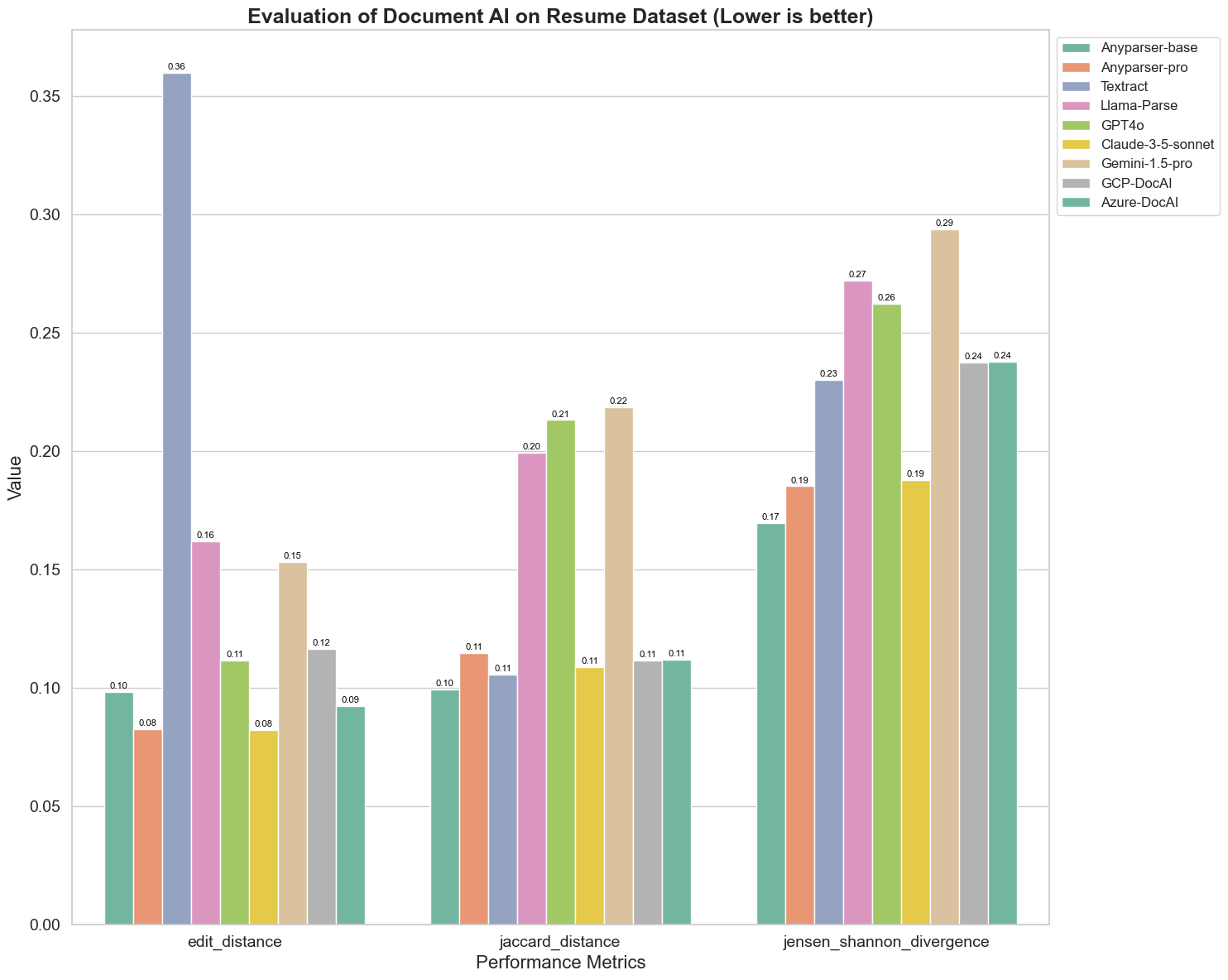
Oto kilka kluczowych obserwacji z wykresu:
-
Odległość edycyjna: Modele AnyParser-base i AnyParser-pro osiągają najlepsze wyniki z najniższą odległością edycyjną, co sugeruje, że ich wyniki były najbliższe dokumentowi referencyjnemu.
-
Divergencja Jenson-Shannon: Modele AnyParser-base i AnyParser-pro mają najniższą divergencję, co sugeruje, że ich wyniki są najbardziej podobne do dokumentu referencyjnego pod względem rozkładu słów.
-
Odległość Jaccarda: Poza Llama-parse, GPT4O, Gemini-1.5, wszystkie inne modele osiągają przyzwoite wyniki z najniższą odległością Jaccarda, co wskazuje, że ich wyniki mają najwyższe pokrycie z dokumentem referencyjnym pod względem użytych słów.
Wnioski
Ogólnie rzecz biorąc, nasze rygorystyczne testy sugerują, że AnyParser-base i AnyParser-pro generalnie dobrze wypadają w różnych metrykach, co wskazuje na ich potencjał do dokładnego przetwarzania dokumentów. Z wykresów możemy zobaczyć, że tradycyjne modele OCR, takie jak znany Amazon Textract, uzyskują znacznie niższe wyniki niż modele językowe wizji. Jednak wydajność różnych modeli różni się w zależności od użytej metryki, co podkreśla znaczenie rozważenia wielu kryteriów oceny podczas porównywania modeli AI.
Wprowadzenie naszego otwartego systemu oceny
Aby uprościć oceny, stworzyliśmy system oceny, który zapewnia standardową metodę porównywania modeli analizy. W naszym przykładzie demonstrujemy jego zastosowanie w dziedzinie HR, gdzie analiza CV jest powszechna. Zbudowaliśmy różnorodny syntetyczny zbiór danych złożony z 128 CV, wygenerowanych przy użyciu sparowanych plików obrazów-Markdown. Używając GPT-4, wygenerowaliśmy treść HTML, przekształciliśmy ją w obrazy i użyliśmy wyekstrahowanego tekstu jako prawdy podstawowej do porównania.
A oto najlepsza część: udostępniliśmy ten framework oceny na GitHubie! Niezależnie od tego, czy jesteś deweloperem, czy użytkownikiem biznesowym, nasz system umożliwia ocenę i porównanie jakości analizy różnych modeli na własnym zbiorze danych.
Znajdź przewodnik szybkiego startu w repozytorium Github i zobacz, jak różne modele analizy wypadają w porównaniu do siebie. Wierzymy, że pokazując siłę naszego modelu w otwartym dostępie, możemy przyciągnąć więcej użytkowników, którzy chcą niezawodnych, szybkich i dokładnych możliwości analizy.
Aneks - Metryki
1. Precyzja
Precyzja mierzy dokładność analizowanej treści, pokazując, ile z wyekstrahowanych elementów było poprawnych. W analizie jest to proporcja poprawnie wyekstrahowanych słów do wszystkich wyekstrahowanych słów.
Precyzja = Prawdziwe Pozytywy (TP) / (Prawdziwe Pozytywy (TP) + Fałszywe Pozytywy (FP))
- Prawdziwe Pozytywy (TP): Słowa poprawnie zidentyfikowane przez parser.
- Fałszywe Pozytywy (FP): Słowa błędnie zidentyfikowane przez parser.
2. Przypomnienie
Przypomnienie wskazuje na kompletność analizy, czyli ile istotnych słów z oryginalnego dokumentu zostało wyekstrahowanych.
Przypomnienie = Prawdziwe Pozytywy (TP) / (Prawdziwe Pozytywy (TP) + Fałszywe Negatywy (FN))
- Fałszywe Negatywy (FN): Słowa w oryginalnym dokumencie, które zostały pominięte przez parser.
3. F-Miara (Wynik F1)
Wynik F1 to średnia harmoniczna Precyzji i Przypomnienia, równoważąca oba wskaźniki, aby dać ogólną miarę jakości analizy.
Wynik F1 = 2 × (Precyzja × Przypomnienie) / (Precyzja + Przypomnienie)
4. Wynik BLEU (Bilingual Evaluation Understudy)
Wynik BLEU mierzy podobieństwo między analizowaną treścią a oryginalnym tekstem, kładąc szczególny nacisk na kolejność słów. Jest szczególnie przydatny do oceny spójności językowej i strukturalnej w analizowanych dokumentach, ponieważ karze wyniki, które różnią się sekwencją od oryginału.
5. ANLS (Średnia Znormalizowana Podobieństwo Levenshteina)
ANLS kwantyfikuje podobieństwo między analizowaną treścią a oryginałem, używając znormalizowanej odległości edycyjnej. Oblicza się go, uśredniając Znormalizowane Podobieństwo Levenshteina (NLS) dla każdej pary słów w analizowanym i referencyjnym tekście. NLS oblicza się w następujący sposób:
NLS = 1 - (Odległość Levenshteina (LD)(słowo analizowane, słowo oryginalne)) / max(Długość słowa analizowanego, Długość słowa oryginalnego)
Następnie ANLS to średnia NLS dla wszystkich par słów:
ANLS = (1/N) × Σ(NLS_i) dla i=1 do N
6. Odległość edycyjna
Odległość edycyjna oblicza liczbę operacji na poziomie słów (wstawień, usunięć, substytucji) wymaganych do przekształcenia analizowanego tekstu w oryginalny.
7. Divergencja Jenson-Shannon
Divergencja Jenson-Shannon mierzy podobieństwo między dyskretnymi rozkładami prawdopodobieństwa zliczeń słów analizowanych i oryginalnych, podkreślając różnice w częstotliwości słów.
JSD(P || Q) = (1/2) × KL(P || M) + (1/2) × KL(Q || M)
gdzie M = (1/2)(P + Q), a KL(P || Q) to divergencja Kullbacka-Leiblera
8. Odległość Jaccarda
Odległość Jaccarda mierzy różnice między zbiorami słów w analizowanej i oryginalnej treści, co jest przydatne do oceny pokrycia słów.
Odległość Jaccarda = 1 - |A ∩ B| / |A ∪ B|
gdzie |A ∩ B| to liczba wspólnych elementów między A i B,
a |A ∪ B| to całkowita liczba unikalnych elementów w obu zbiorach.